前言
计算机视觉,作为人工智能领域的一个重要分支,近年来在图像识别、物体检测、图像生成等应用上取得了显著的进步。PyTorch,作为一款灵活且强大的深度学习框架,为开发者提供了便捷的工具来构建和训练计算机视觉模型。本文将指导您如何使用PyTorch,从零开始,使用自定义数据集训练一个简单的图像分类神经网络模型。
1、准备数据集: 参考:
2、数据集加载:
train_dataset = CustomImageDataset(data_path="./data/", model= "train", transform = transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_dataset = CustomImageDataset(data_path="./data/", model= "test", transform = transform)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=True)3、数据预处理: 我们需要对图像进行预处理,例如缩放、裁剪、归一化等。这里我们使用torchvision的transforms进行图像预处理。
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))])4、构建神经网络
接下来,我们将构建一个简单的卷积神经网络(CNN)模型用于图像分类。
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
# batch*1*28*28(每次会送入batch个样本,输入通道数1(黑白图像),图像分辨率是28x28)
# 下面的卷积层Conv2d的第一个参数指输入通道数,第二个参数指输出通道数,第三个参数指卷积核的大小
self.conv1 = nn.Conv2d(1, 10, 5) # 输入通道数1,输出通道数10,核的大小5
self.conv2 = nn.Conv2d(10, 20, 3) # 输入通道数10,输出通道数20,核的大小3
# 下面的全连接层Linear的第一个参数指输入通道数,第二个参数指输出通道数
self.fc1 = nn.Linear(20*10*10, 500) # 输入通道数是2000,输出通道数是500
self.fc2 = nn.Linear(500, 10) # 输入通道数是500,输出通道数是10,即10分类
def forward(self,x):
in_size = x.size(0) # 在本例中in_size=512,也就是BATCH_SIZE的值。输入的x可以看成是512*1*28*28的张量。
out = self.conv1(x) # batch*1*28*28 -> batch*10*24*24(28x28的图像经过一次核为5x5的卷积,输出变为24x24)
out = F.relu(out) # batch*10*24*24(激活函数ReLU不改变形状))
out = F.max_pool2d(out, 2, 2) # batch*10*24*24 -> batch*10*12*12(2*2的池化层会减半)
out = self.conv2(out) # batch*10*12*12 -> batch*20*10*10(再卷积一次,核的大小是3)
out = F.relu(out) # batch*20*10*10
out = out.view(in_size, -1) # batch*20*10*10 -> batch*2000(out的第二维是-1,说明是自动推算,本例中第二维是20*10*10)
out = self.fc1(out) # batch*2000 -> batch*500
out = F.relu(out) # batch*500
out = self.fc2(out) # batch*500 -> batch*10
out = F.log_softmax(out, dim=1) # 计算log(softmax(x))
return out使用torchinfo打印模型信息
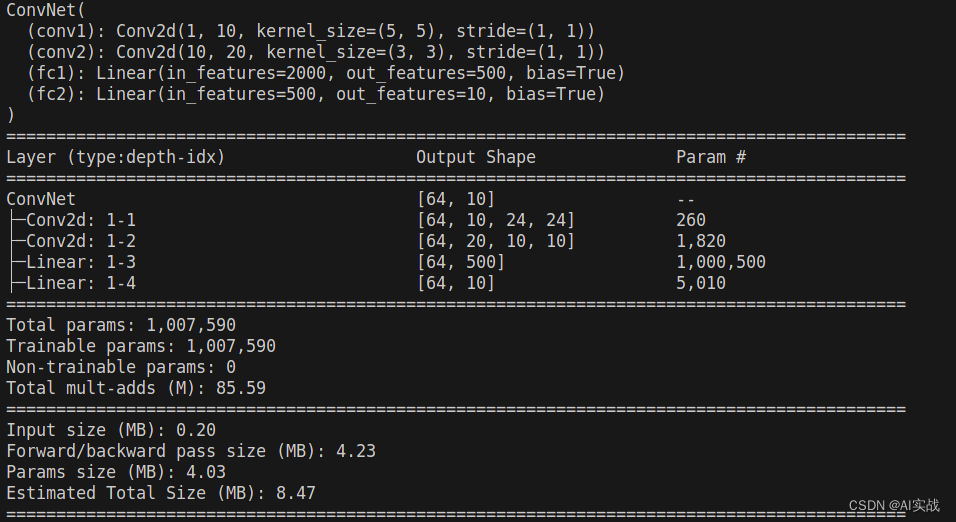
5、训练模型
定义损失函数和优化器,然后开始训练模型。
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001)
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for i, (images, labels) in enumerate(train_loader, 0):
optimizer.zero_grad()
#print(images.shape)
images = images.to(device)
labels = labels.to(device)
output = model(images)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
running_loss /= len(train_loader)
print("epoch ", epoch, running_loss)
torch.save(model, "model.pth")模型训练效果
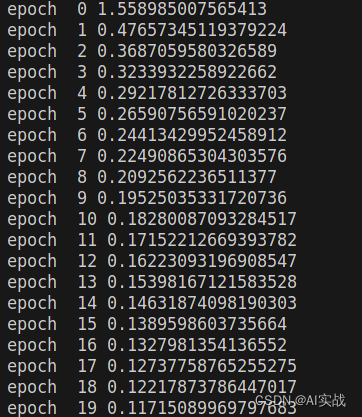
通过以上步骤,你可以使用PyTorch来训练自己的数据集并构建神经网络模型。
关注我的公众号Ai fighting, 第一时间获取更新内容。

![如何在 Windows 10/11 上编辑 PDF [4 种简单方法]](https://img-blog.csdnimg.cn/img_convert/e4fc60e323ac71d24478db56b296dc13.jpeg)