简介
借助 Azure AI 文档智能中的预生成模型,无需自行训练模型,即可从常见表单和文档中提取数据。
公司中,表单种类繁多,如发票、收据、调查表等。你可能想知道,从这些文档中提取姓名、地址、金额等信息需要多少工作量。
什么是预生成模型?
通常,AI 需要大量示例数据来训练模型,但 Microsoft 提供了一些已经训练好的模型。你可以直接使用这些预生成模型来处理常见表单,如发票和收据,而无需训练自己的模型。
预生成模型包括:
- 发票模型。 提取发票中的常见字段和数值。
- 收据模型。 提取收据中的常见字段和数值。
- W2 模型。 提取美国 W-2 纳税申报表中的常见字段和数值。
- ID 文档模型。 提取美国驾照和国际护照中的常见字段和数值。
- 名片模型。 提取名片中的常见字段和数值。
- 医疗保险卡模型。 提取医疗保险卡中的常见字段和数值。
其他模型用于处理结构不明确的文档:
- 读取模型。 提取文档中的文本和语言。
- 通用文档模型。 提取文档中的文本、键值对、实体和选择标记。
- 布局模型。 提取文档中的文本和结构信息。
预生成模型的功能
预生成模型可以从文档和表单中提取各种数据。主要功能包括:
- 文本提取。 提取手写和印刷文本。
- 键值对。 提取标签及其对应的值(如 “Weight: 31 kg”)。
- 实体。 提取复杂数据结构(如人员、位置、日期)。
- 选择标记。 提取单选按钮和复选框的选中状态。
- 表。 提取表格数据,包括单元格内容、列和行信息。
- 字段。 提取特定表单类型的固定字段(如发票中的 CustomerName 和 InvoiceTotal)。
输入要求
为获得最佳效果,确保提交的文档清晰且高质量。具体要求包括:
- 文件格式:JPEG、PNG、BMP、TIFF 或 PDF;读取模型也支持 Microsoft Office 文件。
- 文件大小:标准层小于 500 MB,免费层小于 4 MB。
- 图像尺寸:50 x 50 到 10,000 x 10,000 像素。
- PDF 尺寸:小于 17 x 17 英寸或 A3 纸张大小。
- PDF 文档不得受密码保护。
使用 API 调用预生成模型
Azure AI 文档智能提供 RESTful API,支持多种编程语言(如 C#、Java、Python、JavaScript)。调用 API 时需要:
- 服务终结点。 服务的 URL。
- API 密钥。 授予访问权限的唯一密钥。
这些信息可以从 Azure 门户获取。为了提高效率,建议使用异步调用方式提交表单,并从分析中获取结果:
poller = document_analysis_client.begin_analyze_document_from_url("prebuilt-document", docUrl)
result = poller.result()
提取的详细信息将根据所使用的模型而有所不同。
分类
使用常规文档、读取和布局模型
在公司中,客户和合作伙伴经常发送各种规范、招标书、工作陈述等具有不确定结构的文档。你想知道 Azure AI 文档智能是否能分析和提取这些文档中的信息。
使用读取模型
Azure AI 文档智能读取模型可以从文档和图像中提取印刷和手写文本。这是所有其他预生成模型的基础,用于提供文本提取功能。
使用常规文档模型
常规文档模型扩展了读取模型的功能,能够提取键值对、实体、选择标记和表格数据。它适用于结构化、半结构化和非结构化文档。
- 实体提取。 常规文档模型可以识别并提取人员、组织和日期等实体。即使文档结构复杂,也能有效提取有用信息。可识别的实体类型包括:
Person:人员姓名PersonType:职务或角色Location:地址或地理位置Organization:公司或机构Event:事件或活动Product:产品Skill:技能Address:邮寄地址Phone number:电话号码Email:电子邮件地址URL:网址IP Address:IP 地址DateTime:日期和时间Quantity:数量和单位
使用布局模型
布局模型不仅提取文本,还能返回图像或 PDF 文件中的选择标记和表格信息。适用于需要详细文档结构信息的情况。
- 表格提取。 提取表格中的每个单元格的内容、位置、是否为标题等信息。
- 选择标记提取。 提取单选按钮和复选框的选中状态和置信度。
使用财务、ID 和税务模型
Azure AI 文档智能提供了多种预生成模型,专门用于处理常见表单类型,能从发票、收据、名片等文档中提取常见字段的信息。
使用发票模型
你的公司既开具发票,也接收发票。发票可能格式多样,有时由于扫描角度或纸张损坏而导致效果不佳。发票模型可以处理这些问题,提取如下信息:
- 客户名称和引用 ID
- 采购订单编号
- 发票和截止日期
- 供应商和客户的详细信息
- 账单和送货地址
- 税款总额、发票总额和到期金额
- 发票行信息,包括产品描述、单价、数量和总价
使用收据模型
收据模型与发票模型类似,提取支付金额的详细信息。即使扫描效果不佳,模型也能识别以下字段:
- 商家信息(名称、电话、地址)
- 收据总额、税款和小费
- 交易日期和时间
- 项目表信息,包括购买的产品名称、数量和总价
使用 ID 文档模型
ID 文档模型可分析和提取以下类型的身份文档信息:
- 美国驾照
- 国际护照
使用名片模型
名片通常包含品牌、特殊字体和设计元素。名片模型可以提取以下字段:
- 姓名
- 邮寄地址
- 电子邮件和网站地址
- 各种电话号码
使用 W-2 模型
W-2 表单由美国国内税收署 (IRS) 颁发,用于报告员工的工资和税款。W-2 模型经过训练,可以从表单中提取以下字段:
- 雇主信息(姓名、地址)
- 员工信息(姓名、地址、社会安全号码)
- 员工支付的税款信息
Azure AI 文档智能通过这些预生成模型,能够高效、准确地处理各种常见文档类型,减少手动数据输入的工作量。
从表单中提取数据
各行各业每天都会使用表单来交换信息。传统上,人们需要手动整理表单文档,识别重要信息,然后手动输入数据进行记录。有时,这些任务甚至需要实时与客户一起完成。
Azure 文档智能服务通过智能自动化来解决这些问题,准确地大规模提取数据。Azure 文档智能是一个视觉 API,能够从表单文档中提取键值对和表格数据。
Azure 文档智能
Azure 文档智能是 Azure AI 服务之一,是基于云的人工智能 (AI) 服务,提供 REST API 和客户端库 SDK,帮助在应用程序中构建智能功能。
- 文本:包括手写和印刷的文本内容。
- 键值对:如“名称: John Doe”这样的标签和值。
- 选择标记:如单选按钮和复选框的选中状态。
- 表格:提取表格中的数据,包括单元格内容、位置、行列信息等。
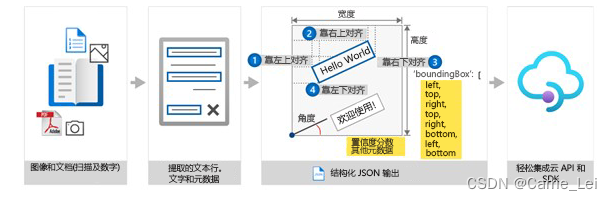
边界框捕获
OCR 通过在图像中检测到的对象周围创建边界框来捕获文档结构。边界框的位置记录为相对于页面其余部分的坐标。
结构化数据返回
Azure 文档智能服务以包含关系的结构化形式返回来自原始文件的边界框数据和其他信息。这意味着每个文本块、表格或选择标记的边界框数据和内容都会被详细记录,便于进一步处理和分析。

优势
- 自动化:无需手动整理和输入数据,减少工作量和出错率。
- 高效:能够处理大量文档,适合大规模使用。
- 准确:使用先进的 AI 技术,确保提取的数据准确可靠。
通过 Azure 文档智能,企业可以大幅提升数据处理的效率,减少手动操作带来的不便和错误。
Azure 文档智能服务组件
Azure 文档智能由以下服务组成:
- 文档分析模型:采用 JPEG、PNG、PDF 和 TIFF 文件格式输入,并返回一个 JSON 文件,其中包含文本在边界框、文本内容、表、选择标记(也称为复选框或单选按钮)和文档结构中的位置。
- 预生成模型:该模型从文档图像中检测并提取信息,并在结构化 JSON 输出中返回提取的数据。 目前,Azure 文档智能支持以下几个表单的预生成模型,包括:
- W-2 表单
- 发票
- Receipts
- ID 文档
- 名片
- 自定义模型:自定义模型从特定于业务的表单中提取数据。 可以通过 Azure 文档智能工作室训练自定义模型。
使用客户端库 SDK 或 REST API 访问服务
使用 REST API、客户端库 SDK 或通过 Azure 文档智能工作室,可以访问 Azure 文档智能服务,以将这些服务集成到工作流或应用程序中。
操作
要使用 Azure 文档智能服务来启动项目,需要准备以下项目:
- Azure 资源订阅
- 一些用于数据提取的表单文件
订阅某个资源
可以通过以下方式访问 Azure 文档智能服务:
-
Azure AI 服务资源:多服务订阅密钥(在多个 Azure AI 服务中使用)
-
Azure 文档智能资源:单服务订阅密钥(仅用于特定的 Azure AI 服务)
Azure 文档智能文件输入要求
Azure 文档智能可以处理符合以下要求的输入文档:
- 格式必须为 JPG、PNG、BMP、PDF(文本或扫描件)或 TIFF。
- 文件大小必须小于 500 MB(对于付费 (S0) 层)和 4 MB(对于免费 (F0) 层)。
- 图像尺寸必须介于 50 x 50 像素与 10000 x 10000 像素之间。
- 训练数据集的总大小不得超过 500 页。
确定要使用的 Azure 文档智能组件
在收集了文件后,请决定需要完成的操作。
- 若要使用 OCR 功能捕获文档分析,请使用布局模型、读取模型或常规文档模型。
- 若要创建从 W-2、发票、回执、ID 文档、医疗保险、疫苗接种和名片中提取数据的应用程序,请使用预生成模型。 无需训练这些模型。 Azure 文档智能服务可分析文档并返回 JSON 输出。
- 若要创建从行业特定的表单中提取数据的应用程序,请创建自定义模型。 此模型需要针对文档样本进行训练。 在训练后,该自定义模型可以分析新文档并返回 JSON 输出。
训练自定义模型
Azure 的 Azure 文档智能服务支持监督式机器学习。 可以训练自定义模型,并通过包含标记字段的表单文档和 JSON 文档创建复合模型。

若要训练自定义模型,请执行以下操作:
- 在 Azure Blob 容器中,将表单样本与包含布局和标签字段信息的 JSON 文件存储在一起。
- 可以使用 Azure 文档智能的分析文档函数为每个示例表单生成一个 ocr.json 文件。 另外,还需要一个描述待提取字段的 fields.json 文件,并且每个表单样本需要一个 labels.json文件,用于将这些字段映射到它们在该表单中的位置。
- 为该容器生成共享访问安全 (SAS) URL。
- 使用生成模型 REST API 函数(或等效的 SDK 方法)。
- 使用获取模型 REST API 函数(或等效的 SDK 方法),以获取经过训练的模型 ID。
OR
- 使用 Azure 文档智能工作室进行标记和训练。 自定义表单有两种类型的基础模型:“自定义模板模型”或“自定义神经网络模型”
- 自定义模板类型可准确提取文档中标记的键值对、选择标记、表、区域以及签名。 训练仅需几分钟,支持 100 多种语言。
- 自定义神经网络模型是深入学习的模型,它结合了布局和语言特征,以便从文档中准确提取标记的字段。此模型最适合用于半结构化或非结构化文档。
使用 Azure 文档智能模型
使用 API
要使用自定义模型提取表单数据,请使用支持的 SDK 的分析文档函数或 REST API,同时提供模型 ID(在模型训练期间生成)。 此函数会启动表单分析。 然后,可以请求结果来获取分析。
调用模型的示例代码:
Python
endpoint = "YOUR_DOC_INTELLIGENCE_ENDPOINT"
key = "YOUR_DOC_INTELLIGENCE_KEY"
model_id = "YOUR_CUSTOM_BUILT_MODEL_ID"
formUrl = "YOUR_DOCUMENT"
document_analysis_client = DocumentAnalysisClient(
endpoint=endpoint, credential=AzureKeyCredential(key)
)
# Make sure your document's type is included in the list of document types the custom model can analyze
task = document_analysis_client.begin_analyze_document_from_url(model_id, formUrl)
result = task.result()
成功的 JSON 响应包含 analyzeResult,其中包含提取的内容和一组包含文档内容信息的页面。
了解置信度分数
如果 analyzeResult 的置信度值较低,请尝试提升输入文档的质量。
如果置信度值较低,则还需确保分析的表单与训练集中的表单外观类似。 如果表单外观不同,请考虑训练多个模型,每个模型侧重于一种表单格式。
你可能会发现低风险应用程序可以接受 80% 或更高的置信度分数,具体取决于用例。 对于更敏感的情况,如读取医疗记录或账单,建议将分数设置为 100%。
使用 Azure 文档智能工作室
除了 SDK 和 REST API 外,还可以通过称为 Azure 文档智能工作室(预览版)的用户界面访问 Azure 文档智能服务,这是一个在线工具,用于直观地探索、理解和集成 Azure 文档智能服务中的功能。 该工作室可用于分析表单布局、从预生成模型中提取数据,以及训练自定义模型。
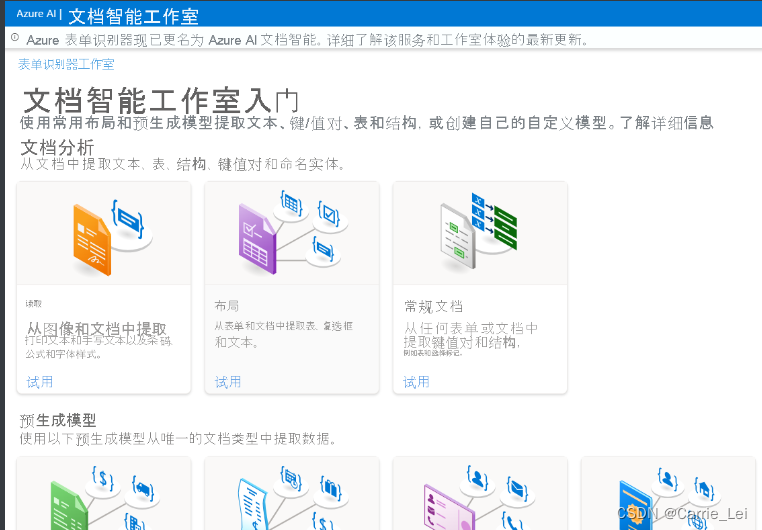
Azure 文档智能工作室目前支持以下项目:
- 文档分析模型
- 读取:从文档和图像中提取打印和手写文本行、单词、位置和检测到的语言。
- 布局:从文档(PDF 和 TIFF)和图像(JPG、PNG 和 BMP)提取文本、表、选择标记和结构信息。
- 常规文档:从文档中提取键值对、选择标记和实体。
- 预生成的模型
- 自定义模式
生成文档分析模型项目
若要使用文档分析模型提取文本、表、结构、键值对和命名实体,请执行以下操作:
- 创建 Azure 文档智能或 Azure AI 服务资源
- 在“文档分析模型”类别下选择“读取”、“布局”或“常规文档”
- 分析文档。 需要 Azure 文档智能或 Azure AI 服务终结点和密钥。
生成预生成模型项目
若要使用预生成模型从常用表单中提取数据,请执行以下操作:
- 创建 Azure 文档智能或 Azure AI 服务资源
- 选择其中一种“预生成模型”,包括 W-2、发票、收据、ID 文档、医疗保险、疫苗接种和名片。
- 分析文档。 需要 Azure 文档智能或 Azure AI 服务终结点和密钥。
生成自定义模型项目
可以在训练和测试自定义模型的整个过程中使用 Azure 文档智能工作室的自定义服务。
当你使用 Azure 文档智能生成自定义模型时,系统会自动创建训练所需的 ocr.json 文件、labels.json 文件和 fields.json 文件并将其存储在存储帐户中。
若要通过自定义模型训练自定义模型并使用该模型提取数据,请执行以下操作:
- 创建 Azure 文档智能或 Azure AI 服务资源
- 收集至少 5-6 个用于训练的表单样本,并将它们上传到存储帐户容器。
- 配置跨域资源共享 (CORS)。 利用 CORS,Azure 文档智能工作室可以将标记的文件存储在存储容器中。
- 在 Azure 文档智能工作室中创建自定义模型项目。 需要提供将存储容器和 Azure 文档智能或 Azure AI 服务资源链接到项目的配置。
- 使用 Azure 文档智能工作室将标签应用于文本。
- 训练模型。 在训练模型后,你会收到用于标记的模型 ID 和平均准确度。
- 通过分析未在训练中使用过的新表单来测试模型。
创建组合型文档智能模型
Azure AI 文档智能中的组合模型使用户能够在不知道使用哪个模型最合适时提交表单。
在你的调查公司,你经常更改用于向受访者收集数据的表单版本。 当你的用户提交这些表单以供分析时,他们有时会选择错误的自定义模型。 你希望找到一种方法来让他们无需指定模型版本即可提交表单。
在这里,你将了解组合模型如何帮助将表单自动发送给正确的自定义模型。
什么是组合模型?
如果你的表单具有不太寻常或独特的格式,你可以在 Azure AI 文档智能中创建和训练自己的自定义模型。 自定义模型可以为表单特有的数据提供字段提取功能,并生成针对特有商务应用程序的数据。
可以创建两种类型的自定义模型:
- 自定义模板模型。 如果表单具有一致的视觉对象模板,请使用自定义模板模型。 在表单的所有已完成示例中,格式设置和布局应保持一致。
- 自定义神经网络模型。 如果表单不太一致或属于半结构化/非结构化表单,请使用自定义神经网络模型。
可以在单个 Azure AI 文档智能资源中创建数百个自定义模型。 发送要分析的表单时,必须指定要在请求中使用的模型标识:
如果有很多自定义模型,则很难跟踪它们,也很难在请求中指定正确的模型。 你可能还使用了许多略微不同的表单来收集数据。
例如,假设你去年每周对选民进行一次调查。 在此期间,你已使用新布局修改了两次表单,并为每个版本训练了单独的自定义模板模型。 但有时并不能很快地将新表单分发给所有调查员,因此在每周的调查中都有多种表单版本。
在这种情况下,组合模型可能会有所帮助。 组合模型由多个自定义模型组成。 当提交表单进行分析时,Azure AI 文档智能会对其进行分类,然后选择最佳的自定义模型来进行分析。 这种分类意味着你不必自行跟踪正确的自定义模型,也无需在请求中指定它。
使用组合模型
创建一组自定义模型后,必须将它们组合到一个组合模型中。 你可以使用 Azure AI 文档智能工作室或自定义代码中的 StartCreateComposedModelAsync() 方法在图形用户界面 (GUI) 中执行此操作。
采用你对单个自定义模型使用的方法来提交表单进行分析。 请记住指定组合模型的模型 ID。
在组合模型的结果中,可以通过检查 docType 字段来确定已用于分析的自定义模型。
可以在 Azure AI 文档智能资源中创建的自定义模型数取决于你使用的自定义表单的类型和你的层级:
展开表
| 模型类型 | 免费 (F0) 层的最大数量 | 标准 (S0) 层的最大数量 |
|---|---|---|
| 自定义模板 | 500 | 5000 |
| 自定义神经 | 100 | 500 |
| 组合 | 5 | 200 |
可添加到单个组合模型的自定义模型数量上限为 100。
自定义模型兼容性
对于可以添加到同一组合模型的模型,存在一些限制:
- 自定义模板模型可与 3.0 到 2.1 API 版本中的其他自定义模板模型组合。
- 自定义神经网络模型可与其他自定义神经网络模型组合。
- 自定义神经网络模型不可与自定义模板模型组合
组装组合模型
可以通过在 Azure AI 文档智能或你自己的代码中组装自定义模型来创建组合模型。
在民意调查公司中,你希望创建一个组合模型,该模型将分类并正确分析主要政治性民意调查表格的所有版本。 你需要知道如何组合模型。
在文档智能工作室中创建组合模型
在开始创建组合模型之前,需要:
- Azure 订阅中的 Azure AI 文档智能资源。
- 要添加到组合模型中的一组经过训练和标记的自定义模型。
如果想要使用图形用户界面 (GUI),可以在 Azure AI 文档智能工作室中创建组合模型:
-
在 Azure AI 文档智能工作室的主页上,选择“自定义模型”。
-
在“我的项目”下,选择其中一个自定义模型,然后在左侧导航中选择“模型”。
-
在“模型”列表中,选择要包含在新组合模型中的所有模型,然后选择“组合”。
-
在“组合新模型”对话框中,输入组合模型的“模型 ID”和“说明”,然后选择“组合”。
在代码中创建组合模型
如果使用 Azure AI 文档智能 SDK 之一通过执行代码来创建组合模型,则必须首先创建 DocumentModelAdministrationClient 对象的实例,并使用其终结点和 API 密钥将其连接到 Azure AI 文档智能
创建组合模型后,可以使用用于将表单发送到任何其他自定义模型的相同代码将表单发送给模型以进行分析。 请记住在调用中指定组合模型的模型 ID。
练习
用 Azure AI Document Intelligence 标注文档分析
首先到 Azure 中,搜索所给出的资源组,选择 RG1开头的资源组,如下图所示

在搜索框中输入document intelligence 。

创建create document intelligence

创建完毕后,在页面中点击 Go to resource 按钮

进入到服务页面后,下滑页面,点击 Invoices 的 Try it out。
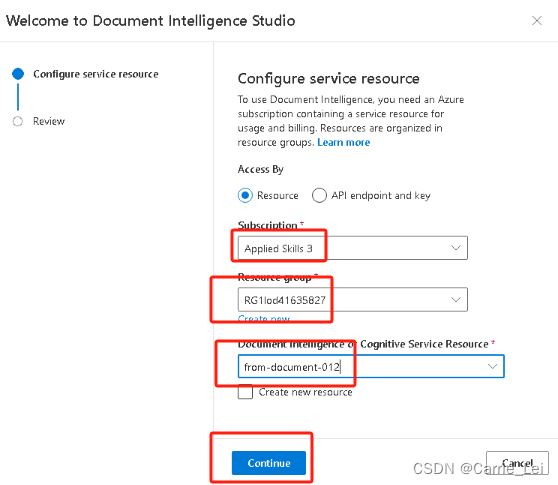
在服务的填写表格页面,默认的订阅和资源组选择下拉按钮
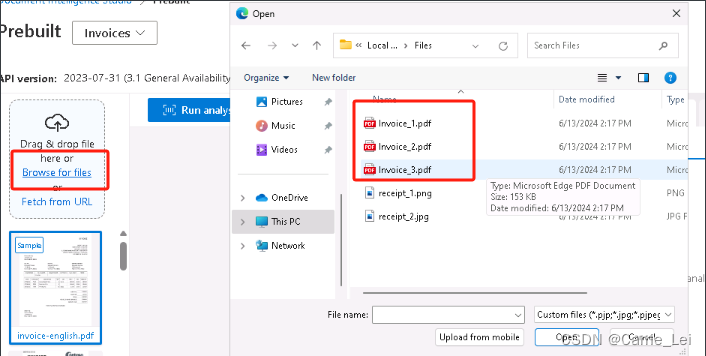
在上述步骤完成后,点击左侧的上传区域,点击选择文件按钮,在新弹出的选择文件筐,找到文件,之后选择发票pdf,点击 Open 如下图所示。
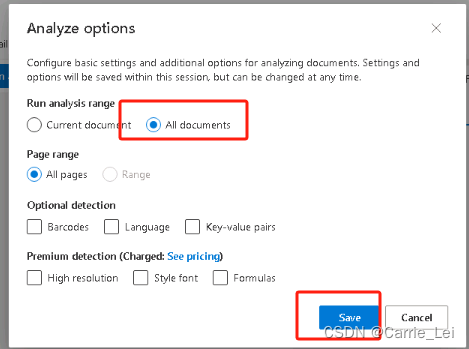
选择玩文件后,点击 Analyze options 选项,之后选择 all documents,之后点击保存按钮。
配置完分析选项后,点击直接点击运行分析按钮,运行完后,找到右侧的 Result按钮,可以看到我们所需要的 JSON 文件。
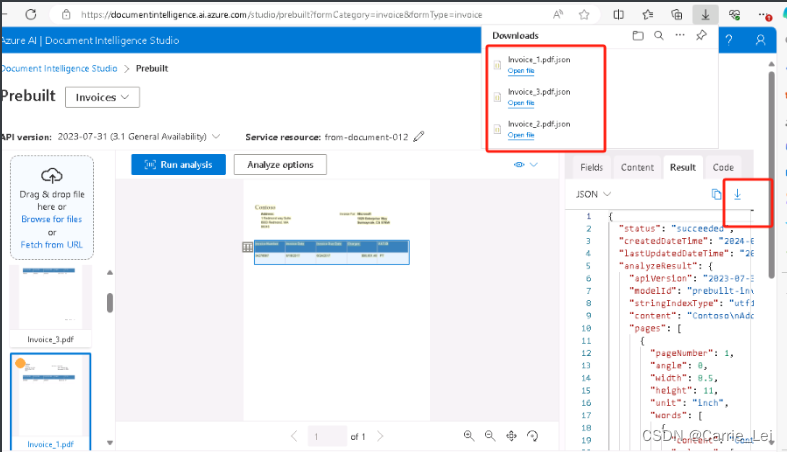
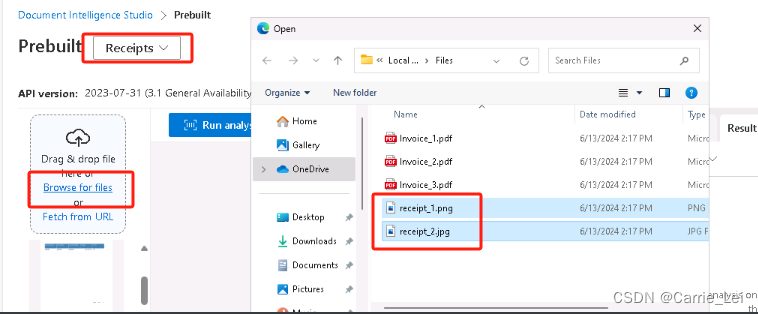
重复操作,将所有的receipt文件上传,同样操作一遍。
创建一个智能文档分析服务,并且进行相关的训练
门户页面选择服务:Custom extraction model。
点击项目选项中的 创建一个项目按钮

输入下面图片信息
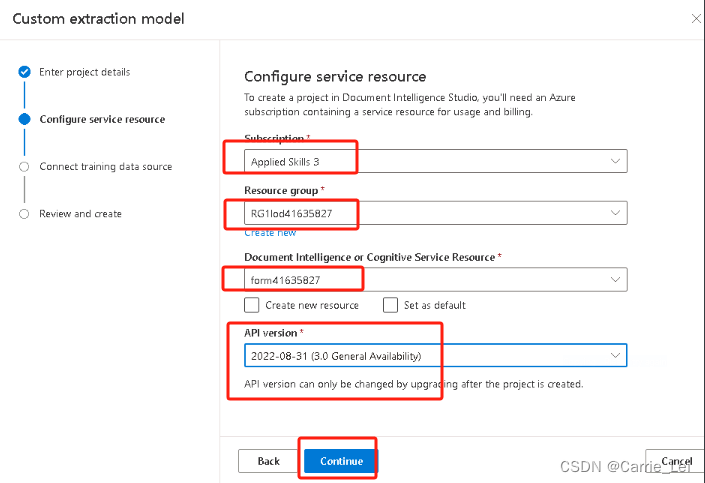
继续输入下面图片信息
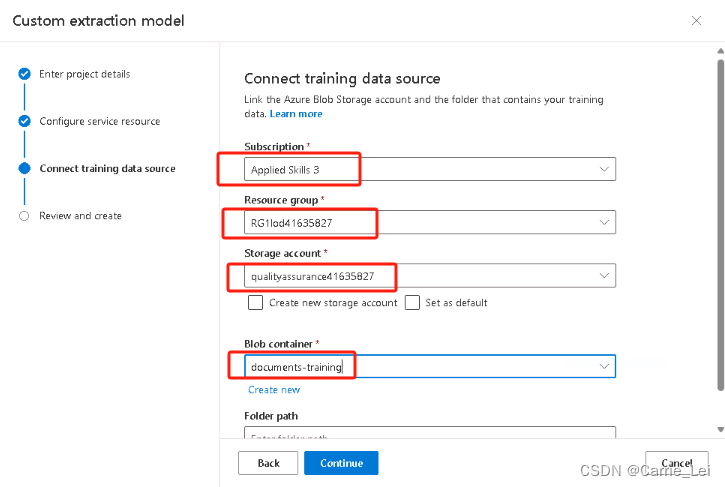
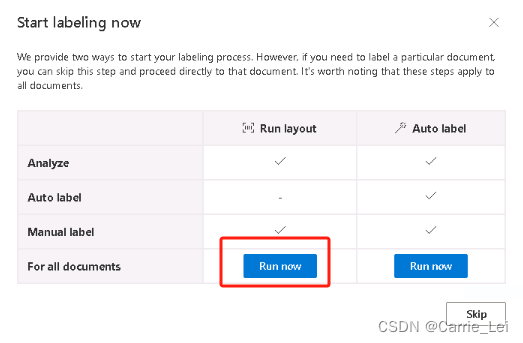
创建成功后,等待一会后,在弹出的页面直接点击 Run now 按钮
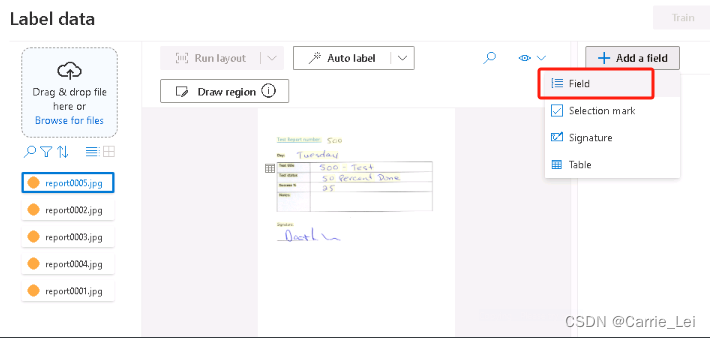
在新页面中,选择一个jpg文件后,点击右侧的添加字段选项
在右边的field里面添加了如下字段,Number/Day/Title/Status/Success
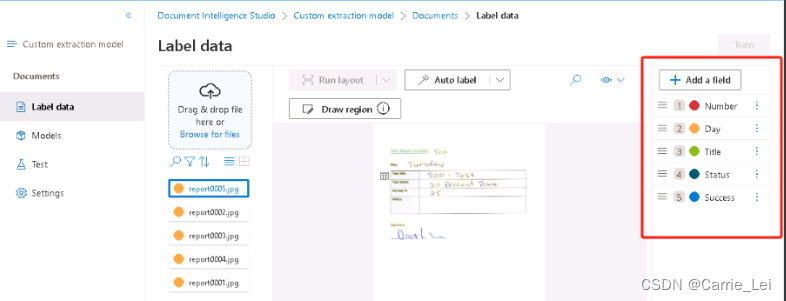
在相应的图片上进行标注
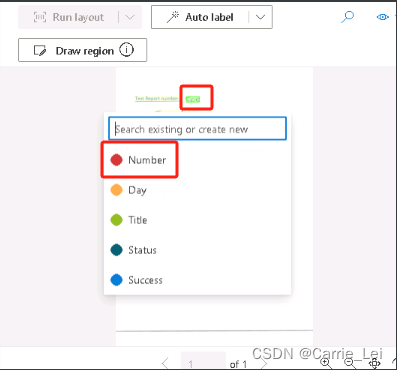
同样的把所有的字段都在图片中选择打上标签
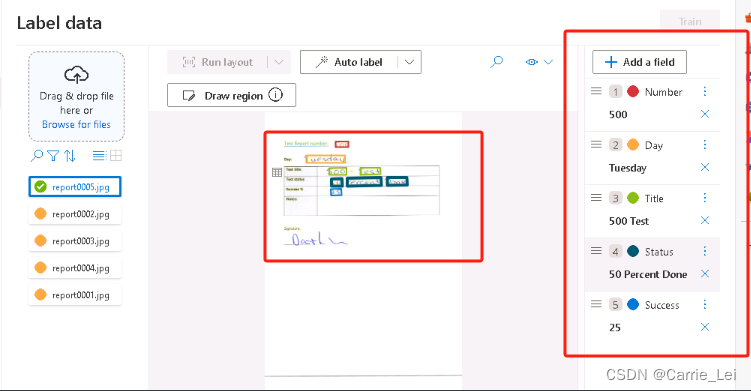
之后点击训练按钮
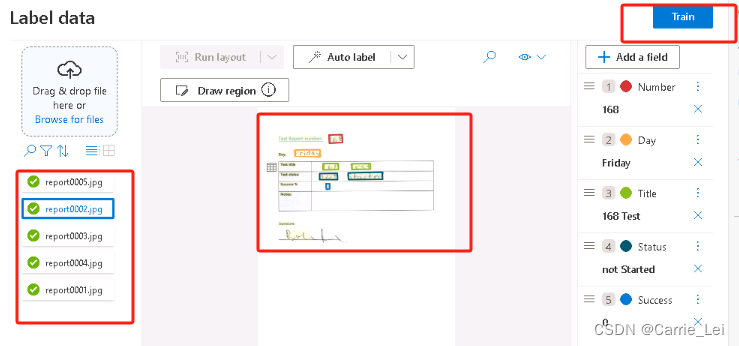
选择训练模型

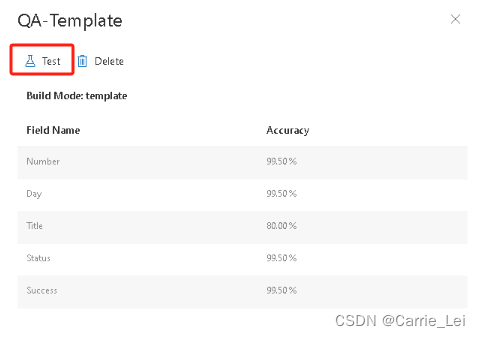
这里已经创建了训练,点击QA-Template
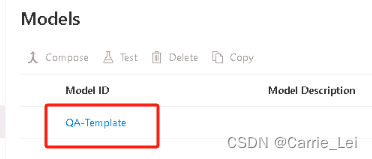
进行测试
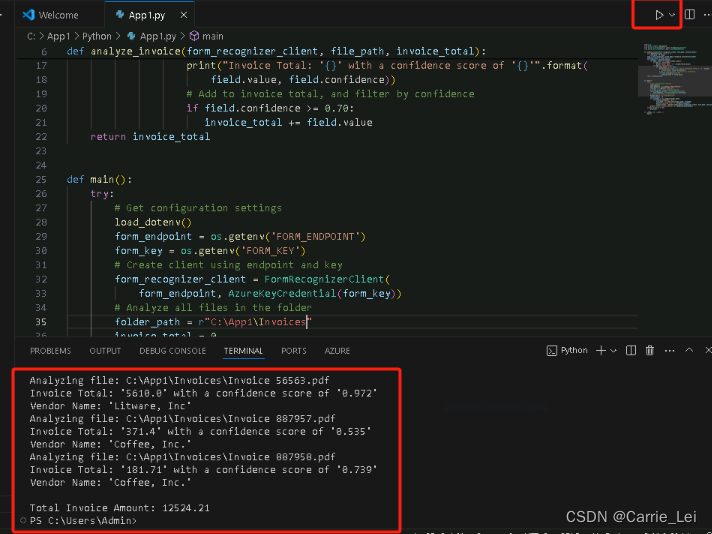
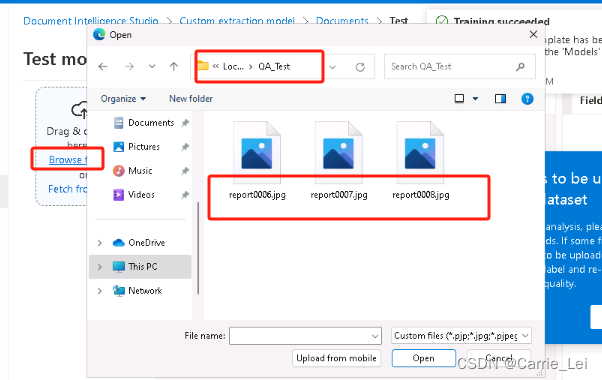
上传需要分析的 文件夹内的文件。
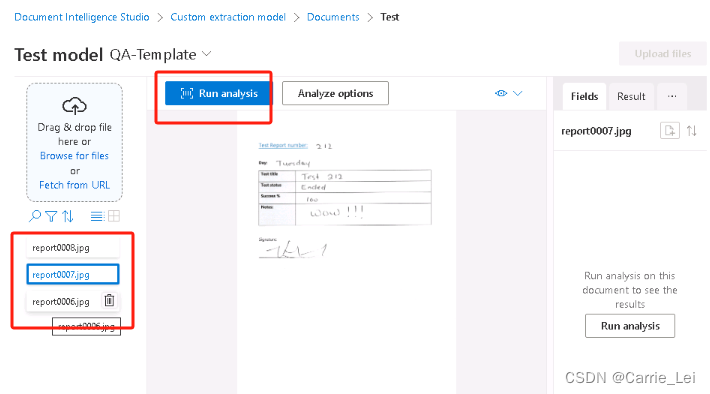
点击运行分析按钮
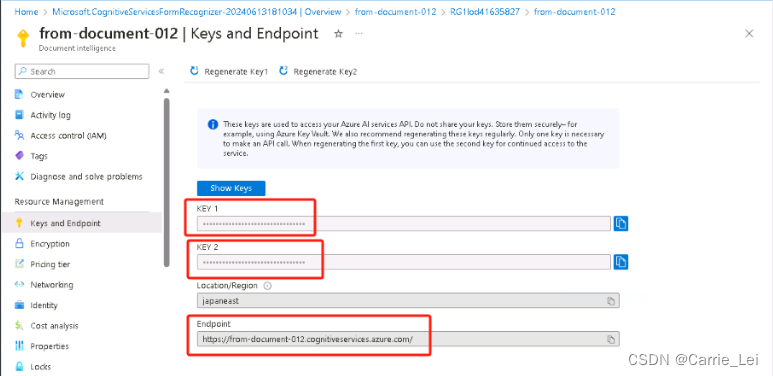
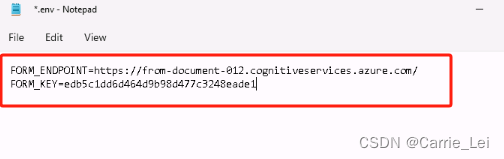
在创建的资源里面from-document-012里面找到endpoint和key
在.env文件中配置环境key和endpoint代码。
运行分析。