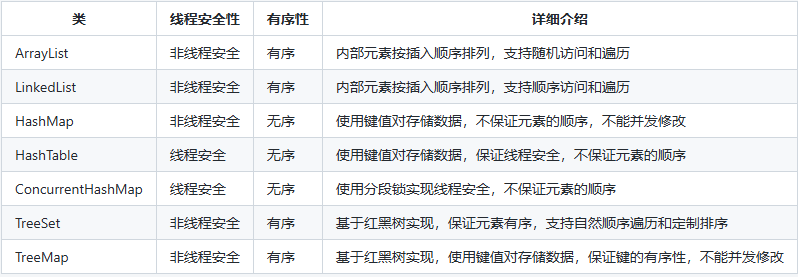
一、本文介绍
本文给大家带来的是分类损失 SlideLoss损失函数,我们之前看那的那些IoU都是边界框回归损失,和本文的修改内容并不冲突,所以大家可以知道损失函数分为两种一种是分类损失另一种是边界框回归损失,上一篇文章里面我们总结了过去百分之九十的边界框回归损失的使用方法,本文我们就来介绍几种市面上流行的和最新的分类损失函数,同时在开始讲解之前推荐一下我的专栏,本专栏的内容支持(分类、检测、分割、追踪、关键点检测),专栏目前为限时折扣,欢迎大家订阅本专栏,本专栏每周更新3-5篇最新机制,更有包含我所有改进的文件和交流群提供给大家,本文支持的损失函数共有如下图片所示
欢迎大家订阅我的专栏一起学习YOLO!

专栏地址:YOLOv9有效涨点专栏-持续复现各种顶会内容-有效涨点-全网改进最全的专栏
目录
一、本文介绍
二、原理介绍
三、核心代码
三、使用方式
四 、本文总结
二、原理介绍
其中绝大多数损失在前面我们都讲过了本文主要讲一下SlidLoss的原理,SlideLoss的损失首先是由YOLO-FaceV2提出来的。

官方论文地址: 官方论文地址点击即可跳转
官方代码地址: 官方代码地址点击即可跳转
从摘要上我们可以看出SLideLoss的出现是通过权重函数来解决简单和困难样本之间的不平衡问题题,什么是简单样本和困难样本?
样本不平衡问题是一个常见的问题,尤其是在分类和目标检测任务中。它通常指的是训练数据集中不同类别的样本数量差异很大。对于人脸检测这样的任务来说,简单样本和困难样本之间的不平衡问题可以具体描述如下:
简单样本:
- 容易被模型正确识别的样本。
- 通常出现在数据集中的数量较多。
- 特征明显,分类或检测边界清晰。
- 在训练中,这些样本会给出较低的损失值,因为模型可以轻易地正确预测它们。
困难样本:
- 模型难以正确识别的样本。
- 在数据集中相对较少,但对模型性能的提升至关重要。
- 可能由于多种原因变得难以识别,如遮挡、变形、模糊、光照变化、小尺寸或者与背景的低对比度。
- 在训练中,这些样本会产生较高的损失值,因为模型很难对它们给出准确的预测。
解决样本不平衡的问题是提高模型泛化能力的关键。如果模型大部分只见过简单样本,它可能在实际应用中遇到困难样本时性能下降。因此采用各种策略来解决这个问题,例如重采样(对困难样本进行过采样或对简单样本进行欠采样)、修改损失函数(给困难样本更高的权重),或者是设计新的模型结构来专门关注困难样本。在YOLO-FaceV2中,作者通过Slide Loss这样的权重函数来让模型在训练过程中更关注那些困难样本(这也是本文的修改内容)。
三、核心代码
使用方式看章节
import math
class SlideLoss(nn.Module):
def __init__(self, loss_fcn):
super(SlideLoss, self).__init__()
self.loss_fcn = loss_fcn
self.reduction = loss_fcn.reduction
self.loss_fcn.reduction = 'none' # required to apply SL to each element
def forward(self, pred, true, auto_iou=0.5):
loss = self.loss_fcn(pred, true)
if auto_iou < 0.2:
auto_iou = 0.2
b1 = true <= auto_iou - 0.1
a1 = 1.0
b2 = (true > (auto_iou - 0.1)) & (true < auto_iou)
a2 = math.exp(1.0 - auto_iou)
b3 = true >= auto_iou
a3 = torch.exp(-(true - 1.0))
modulating_weight = a1 * b1 + a2 * b2 + a3 * b3
loss *= modulating_weight
if self.reduction == 'mean':
return loss.mean()
elif self.reduction == 'sum':
return loss.sum()
else: # 'none'
return loss三、使用方式
根据我下面的图片进行修改即可。
3.1 修改一
我们将上面的核心代码,我们找到如下的文件'utils/loss_tal_dual.py'文件,然后将我们上面的核心代码复制粘贴到文件的开头,注意是文件导入之后!
3.2 修改二
同一个文件我门下拉,按照下面的图片进行修改即可!

我把代码给copy下来了大家可以复制替换可以! 这个函数修改看不到显示,但是可以debug大家看看执行到没有就行!
class ComputeLoss:
# Compute losses
def __init__(self, model, use_dfl=True):
device = next(model.parameters()).device # get model device
h = model.hyp # hyperparameters
# Define criteria
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([h["cls_pw"]], device=device), reduction='none')
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3
self.cp, self.cn = smooth_BCE(eps=h.get("label_smoothing", 0.0)) # positive, negative BCE targets
# Focal loss
g = h["fl_gamma"] # focal loss gamma
if g > 0:
BCEcls = FocalLoss(BCEcls, g)
BCEcls = SlideLoss(BCEcls) # 添加这一行代码代表打开了SlideLoss
m = de_parallel(model).model[-1] # Detect() module
self.balance = {3: [4.0, 1.0, 0.4]}.get(m.nl, [4.0, 1.0, 0.25, 0.06, 0.02]) # P3-P7
self.BCEcls = BCEcls
self.hyp = h
self.stride = m.stride # model strides
self.nc = m.nc # number of classes
self.nl = m.nl # number of layers
self.no = m.no
self.reg_max = m.reg_max
self.device = device
self.assigner = TaskAlignedAssigner(topk=int(os.getenv('YOLOM', 10)),
num_classes=self.nc,
alpha=float(os.getenv('YOLOA', 0.5)),
beta=float(os.getenv('YOLOB', 6.0)))
self.assigner2 = TaskAlignedAssigner(topk=int(os.getenv('YOLOM', 10)),
num_classes=self.nc,
alpha=float(os.getenv('YOLOA', 0.5)),
beta=float(os.getenv('YOLOB', 6.0)))
self.bbox_loss = BboxLoss(m.reg_max - 1, use_dfl=use_dfl).to(device)
self.bbox_loss2 = BboxLoss(m.reg_max - 1, use_dfl=use_dfl).to(device)
self.proj = torch.arange(m.reg_max).float().to(device) # / 120.0
self.use_dfl = use_dfl
def preprocess(self, targets, batch_size, scale_tensor):
if targets.shape[0] == 0:
out = torch.zeros(batch_size, 0, 5, device=self.device)
else:
i = targets[:, 0] # image index
_, counts = i.unique(return_counts=True)
out = torch.zeros(batch_size, counts.max(), 5, device=self.device)
for j in range(batch_size):
matches = i == j
n = matches.sum()
if n:
out[j, :n] = targets[matches, 1:]
out[..., 1:5] = xywh2xyxy(out[..., 1:5].mul_(scale_tensor))
return out
def bbox_decode(self, anchor_points, pred_dist):
if self.use_dfl:
b, a, c = pred_dist.shape # batch, anchors, channels
pred_dist = pred_dist.view(b, a, 4, c // 4).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = pred_dist.view(b, a, c // 4, 4).transpose(2,3).softmax(3).matmul(self.proj.type(pred_dist.dtype))
# pred_dist = (pred_dist.view(b, a, c // 4, 4).softmax(2) * self.proj.type(pred_dist.dtype).view(1, 1, -1, 1)).sum(2)
return dist2bbox(pred_dist, anchor_points, xywh=False)
def __call__(self, p, targets, img=None, epoch=0):
loss = torch.zeros(3, device=self.device) # box, cls, dfl
feats = p[1][0] if isinstance(p, tuple) else p[0]
feats2 = p[1][1] if isinstance(p, tuple) else p[1]
pred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split(
(self.reg_max * 4, self.nc), 1)
pred_scores = pred_scores.permute(0, 2, 1).contiguous()
pred_distri = pred_distri.permute(0, 2, 1).contiguous()
pred_distri2, pred_scores2 = torch.cat([xi.view(feats2[0].shape[0], self.no, -1) for xi in feats2], 2).split(
(self.reg_max * 4, self.nc), 1)
pred_scores2 = pred_scores2.permute(0, 2, 1).contiguous()
pred_distri2 = pred_distri2.permute(0, 2, 1).contiguous()
dtype = pred_scores.dtype
batch_size, grid_size = pred_scores.shape[:2]
imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)
anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)
# targets
targets = self.preprocess(targets, batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])
gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxy
mask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0)
# pboxes
pred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)
pred_bboxes2 = self.bbox_decode(anchor_points, pred_distri2) # xyxy, (b, h*w, 4)
target_labels, target_bboxes, target_scores, fg_mask = self.assigner(
pred_scores.detach().sigmoid(),
(pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),
anchor_points * stride_tensor,
gt_labels,
gt_bboxes,
mask_gt)
target_labels2, target_bboxes2, target_scores2, fg_mask2 = self.assigner2(
pred_scores2.detach().sigmoid(),
(pred_bboxes2.detach() * stride_tensor).type(gt_bboxes.dtype),
anchor_points * stride_tensor,
gt_labels,
gt_bboxes,
mask_gt)
target_bboxes /= stride_tensor
target_scores_sum = max(target_scores.sum(), 1)
target_bboxes2 /= stride_tensor
target_scores_sum2 = max(target_scores2.sum(), 1)
# cls loss
# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL way
loss[1] = self.BCEcls(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE
loss[1] *= 0.25
loss[1] += self.BCEcls(pred_scores2, target_scores2.to(dtype)).sum() / target_scores_sum2 # BCE
# bbox loss
if fg_mask.sum():
loss[0], loss[2], iou = self.bbox_loss(pred_distri,
pred_bboxes,
anchor_points,
target_bboxes,
target_scores,
target_scores_sum,
fg_mask)
loss[0] *= 0.25
loss[2] *= 0.25
if fg_mask2.sum():
loss0_, loss2_, iou2 = self.bbox_loss2(pred_distri2,
pred_bboxes2,
anchor_points,
target_bboxes2,
target_scores2,
target_scores_sum2,
fg_mask2)
loss[0] += loss0_
loss[2] += loss2_
loss[0] *= 7.5 # box gain
loss[1] *= 0.5 # cls gain
loss[2] *= 1.5 # dfl gain
return loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)四 、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv9改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
希望大家阅读完以后可以给文章点点赞和评论支持一下这样购买专栏的人越多群内人越多大家交流的机会就更多了。
专栏地址:YOLOv9有效涨点专栏-持续复现各种顶会内容-有效涨点-全网改进最全的专栏