什么是大模型推理
**大模型推理其实就是大模型如何输出,怎么输出,输出什么的过程。**在人工智能的基础模型下,各种推理任务涵盖了多个领域,包括常识推理、数学推理、逻辑推理、因果推理、视觉推理、听觉推理、多模态推理和代理推理等等。
比如chatgpt最常被用到的常识推理,就是要求模型掌握人类认为显而易见的直观知识,基于对世界的日常了解进行推断,像地球引力、人需要遵守交通法规,让模型能够解释、预测并按照人类期望行事。
还有一些更高阶的数学推理、逻辑推理、因果推理等,这些任务往往用于让人工智能解决数学问题,理解复杂的逻辑和因果,基于不同行动可能造成的影响给出分析,并从中推导出相对正确的结论并给出合理建议。
还有toB端应用最广泛,也是各个公司和组织关注最大的方向–代理推理,也就是某种程度上,大模型可以自主地在动态环境中制定决策、规划和学习。代理推理对于机器人或自主车辆等应用至关重要,因为人工智能需要在实时中导航、与环境互动并做出决策。
除了硬件层面提升,利用并行分布计算来加速外,目前业内主要研究的技术路线重点还是在:
- 模型结构化
- 软件框架和库优化
模型结构优化
模型结构优化就是通过对神经网络的架构进行调整和改进来提高模型的性能、效率和适应性的过程。
比如现在大规模数据集上进行预训练(Pre-training),然后针对特定任务进行微调。通常涉及使用大量的文本、图像或其他数据类型的语料库。
然后与训练之后,就涉及到了大模型结构的微调(Fine-turing)。即在较小的特定数据集上进行推理,将与训练期间获得的通用知识调整到特定应用的细微差别和需求上,提高在特长学科上的学习能力。
当然,除了能力教育,“人性教育”也是非常重要的,这就要对大模型进行所谓的对齐训练(Alignment Training),让模型的输出与目标所说的价值观保持一致,尤其是一些人类道德标准或训练者偏好的价值观。也是这一部分通常会引发人们的讨论,包括机器伦理、道德边界等等,其实都是对齐训练需要解决的问题。
就像每个人都要做生活的多面手一样,大模型推理也要面对属于自己的专家混合模型(MoE),也就是专注于不同任务或数据类型,让该处理这个方面数据的“专家”专门去处理这一部分数据,来提高性能和计算效率。
再之后,就是培养举一反三能力的“上下文学习(Contextual Learning)”,意为在很少的样本甚至零样本的情况下,模型也具备足够高的灵活性和适应性,让模型可以从输入的新信息中学习适应,而不用每次都进行重复训练。而足够聪明,更天才的孩子,甚至还会自主学习,也就是所谓的自主代理,实时与环境互动并从中学习、自主决策、采取行动,并根据经验进行调整,模拟在动态和复杂环境中的人类智能行为。
框架优化
而软件框架和库优化则像培养孩子的各种条件,其中最重要的几个逻辑栈比如大模型调度引擎、神经网络执行引擎、线性代数数据库之类的。
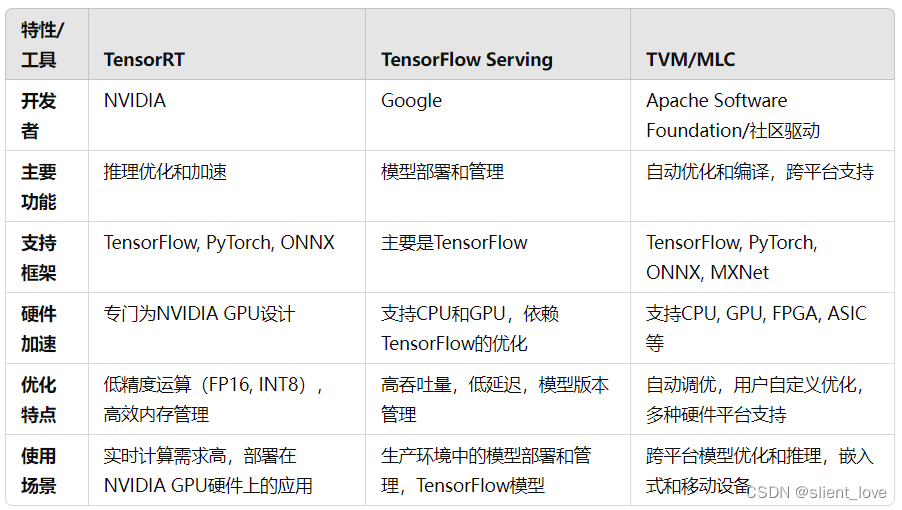
| 大模型调度引擎 | vLLM、Orca、TensorRT-LLM、llama.cpp、MLC-LLM等 |
|---|---|
| 神经网络执行引擎 | TensorRT、Tensorflow Serving、TVM、SNPE等 |
| 线性代数计算库 | cuBLAS、Eigen、Intel MKL、ARM Compute Library等 |
说到具体的优化策略,首先有一个叫做KV Cache的好方法,就是提前把transformer attention计算中的Key和Value张量搞个缓存,就像fairseq系统早期就开始使用的那样。这样一来,每输出一个token时就不用一遍又一遍地重复计算了,效率就提高了。
还有一种叫做Iteration-level scheduling,就是在2022年才被引入的。推理引擎都是按请求批量化的,但是对于哪些需要多次迭代进行自回归计算的LLM推理,我们可以按‘迭代’为单位进行批量化,这样一来就能提高并行度和性能。
还有一种叫做PagedAttention,也是在今年vLLM新引入的。其实是关于上面提到的KV Cache占用大量GPU内存的问题,一个13B模型每个输出token对应的KV张量需要800KB,最长输出长度2048个token的话,一个请求就需要1.6GB显存。所以vLLM引入了类似操作系统中的分页机制,大幅度减少了KV cache的碎片化,性能提高了不少。
还有一种是GPTQ量化,llama.cpp就支持了最近发表的GPTQ,把模型量化到4比特,性能提升很多而准确率下降却很小。
最后一种就是Fused kernels等各类手工优化,有时候就是得亲自下场优化一下,llama.cpp的作者就是这么干的,不怕麻烦,迅速累积了大量手工小优化,最终形成了领先的综合性能。
而神经网络执行引擎,就像是机器学习特别是神经网络领域里的一个老法师,包括像TensorRT、Tensorflow Serving、TVM/MLC等这样的服务,甚至在手机上,高通的SNPE也以其图计算的特性,被认为是一个相对简便的执行引擎。与线性代数层的优化不同,执行引擎具备一种独特的超能力,可以看到整个神经网络的结构,同时处理多个来自客户端的请求,因此能够通过涉及多个算子、整个模型以及多个请求间的优化来提高执行效率。
首先,有一种叫做算子融合(Operator Fusion),通过找准机会将多个相邻的算子合并起来计算,从而减少对数据的扫描,大幅提升性能。
还有一种叫作量化(Quantization)。随着GPU对数据结构支持的多元化,现在推理的基线数据类型已经是FP16,比几年前的FP32提高了不少速度。然而,将模型量化为INT8进行推理,仍然可以带来更快的速度。
还有一种叫做分布式(Distribution)。使用多卡推理和通信加速,可以提升能够推理的模型规模和速度。多卡联动,就像是一支强大的团队,能够共同完成推理任务。
最后,还有一招叫做批量化(Batching)。这是一项高级的战术,通过将多个请求合并处理,能够大幅提高性能。原因有两点:一是合并请求可以增大代数运算的矩阵规模,下层代数库处理越大的矩阵规模,性能越高;二是合并请求可以减少对静态的模型参数矩阵的扫描次数,降低内存带宽的消耗。
而线性代数加速,就像是为机器学习和科学计算注入了强力的引擎。这项技术的发端可以追溯到上世纪70年代的Fortran语言BLAS库,它定义了一系列基础运算,包括矩阵乘法和矩阵与向量的乘法等。
除此之外,Tiling分块技术是线性代数加速领域的一项经典优化。特别是在矩阵乘法这一关键操作中,通过巧妙的分块方法,可以显著减少内存带宽的需求,从而提高计算速度。
自动调优(Autotuning)也是一个不可忽视的利器。通过参数空间搜索,系统可以自动选择最适合当前硬件环境的优化策略,使线性代数运算更为高效。
专有名词解释
fused kernels(融合核)
在高性能计算和深度学习中,fused kernels(融合核)是一种优化技术,旨在提高计算效率和内存带宽利用率。这个技术广泛应用于GPU编程,特别是CUDA编程,以减少内存访问的开销和提高计算吞吐量。
Fused kernels 是指将多个计算操作合并到一个单独的CUDA kernel中执行,而不是分开执行多个独立的kernels。这种技术可以显著减少内存读取和写入操作,从而提高整体的计算效率。内存访问往往是性能瓶颈,通过融合计算操作,可以更好地利用缓存,减少内存带宽的消耗。
在深度学习框架(如TensorFlow、PyTorch)和库(如cuDNN)常常使用fused kernels来优化以下操作:
- 卷积操作与激活函数:将卷积操作与激活函数(如ReLU)的计算融合在一起。
- Batch Normalization:将均值、方差计算与标准化和缩放操作融合在一起。
- 元素级操作:将多个连续的元素级操作(如加法、乘法)融合在一个kernel中。
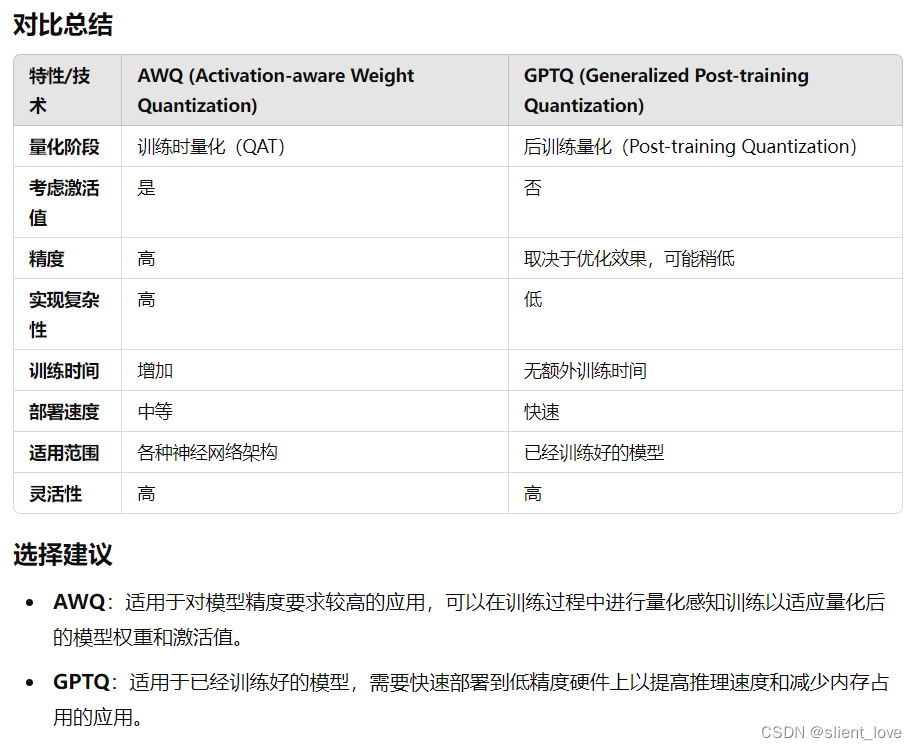
AWQ(Adaptive Weight Quantization)
AWQ是一种权重量化方法,它通过将神经网络中的权重从浮点数转换为低比特宽度的整数来减少模型的大小。这种方法的核心思想是对每个权重进行重要性评估,并据此决定应该分配给它的比特数。重要的权重会被分配更多的比特,而不那么重要的权重则可以使用较少的比特。这样可以在保证模型性能的同时减少整体的比特数使用。
AWQ通常包括以下几个步骤:
- 对权重进行聚类,将相似的权重值归为一类。
- 根据每个聚类的重要性分配不同的比特宽度。
- 将每个聚类的中心值转换为整数,并用这些整数值表示该聚类中的所有权重。
GPTQ(Gradients-Projected Quantization)
GPTQ是一种量化方法,它专注于在量化过程中保持梯度的一致性。在量化神经网络时,一个关键挑战是保持量化后的网络在训练时梯度的一致性,以便可以继续微调网络。GPTQ通过在量化过程中考虑梯度信息来实现这一点。
GPTQ的主要步骤包括:
- 在训练过程中收集权重和对应的梯度信息。
- 使用梯度信息来优化权重的量化表示,以便在量化后保持梯度的一致性。
- 通过
投影梯度的方法来调整量化级别,使得量化误差对梯度的影响最小化。
参考链接:AI技术革命:如何通过推理加速优化你的大模型?