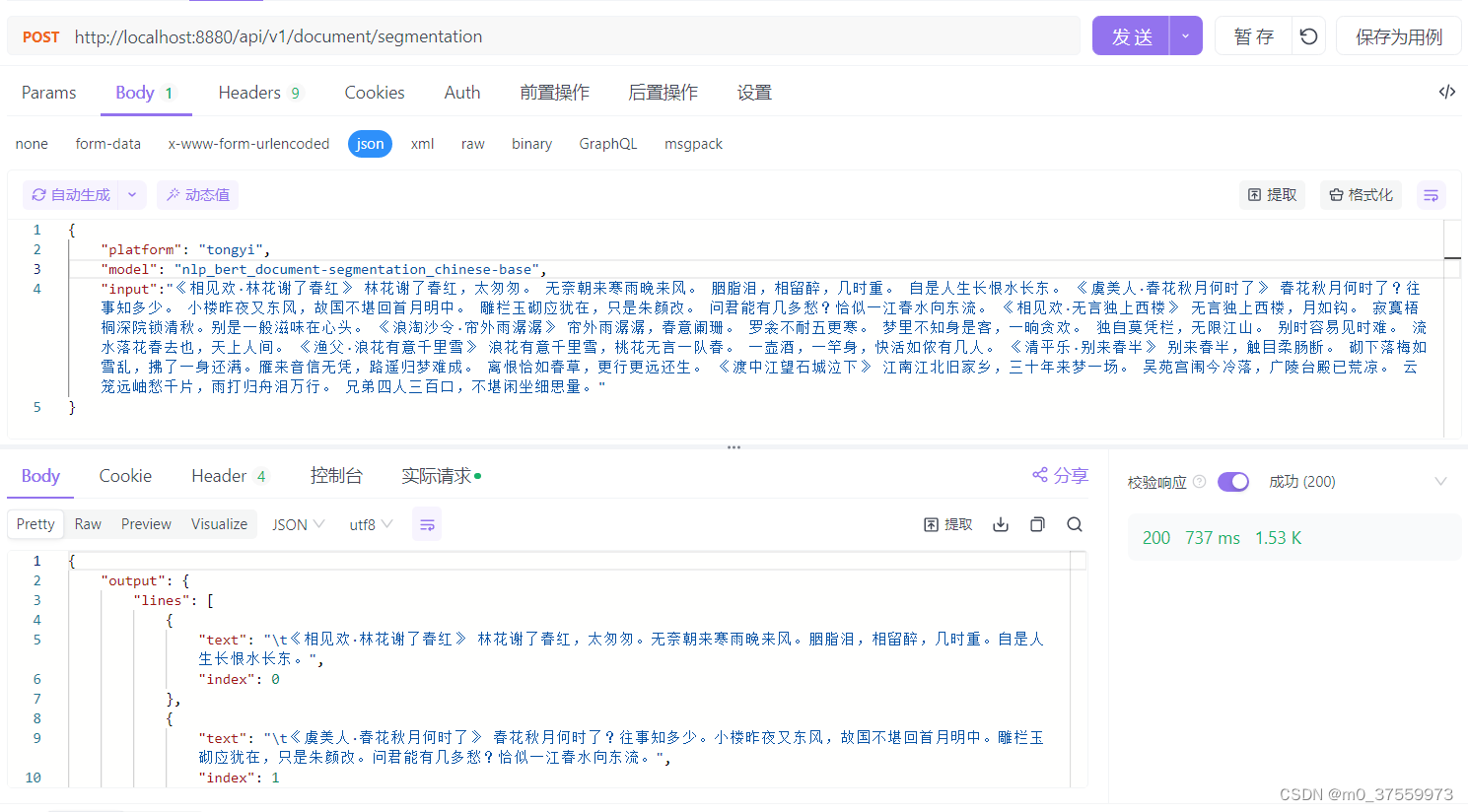
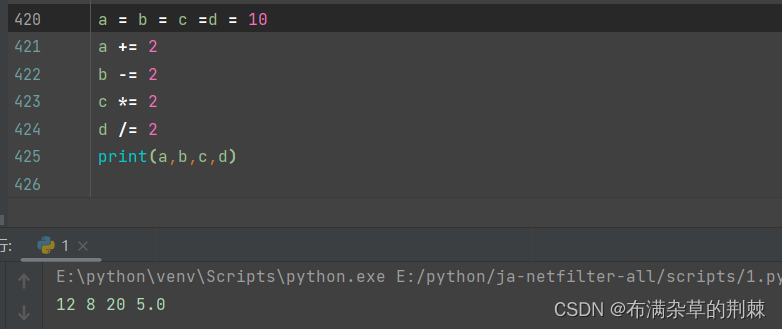
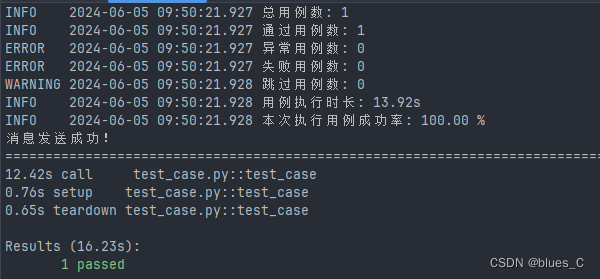
UDTF与UDAF的应用案例:
UDTF:一进多出
UDTF是一对多的输入输出,实现UDTF需要完成下面步骤
M1001#xiaohu#S324231212,lkd#M1002#S2543412432,S21312312412#M1003#bfy
1001 xiaohu 324231212
1002 lkd 2543412432
1003 bfy 21312312412
继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF,
重写initlizer()、process()、close()。
执行流程如下:UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息(返回个数,类型)。
初始化完成后,会调用process方法,真正的处理过程在process函数中,在process中,每一次forward()调用产生一行;如果产生多列可以将多个列的值放在一个数组中,然后将该数组传入到forward()函数。
最后close()方法调用,对需要清理的方法进行清理。
“key1:value1,key2:value2,key3:value3”
key1 value1
key2 value2
key3 value3
方法:自定UDTF
字段:id,col1,col2,col3,col4,col5,col6,col7,col8,col9,col10,col11,col12 共13列
数据:
a,1,2,3,4,5,6,7,8,9,10,11,12
b,11,12,13,14,15,16,17,18,19,20,21,22
c,21,22,23,24,25,26,27,28,29,30,31,32
转成3列:id,hours,value
例如:
a,1,2,3,4,5,6,7,8,9,10,11,12
a,0时,1
a,2时,2
a,4时,3
a,6时,4
…
create table udtfData(
id string
,col1 string
,col2 string
,col3 string
,col4 string
,col5 string
,col6 string
,col7 string
,col8 string
,col9 string
,col10 string
,col11 string
,col12 string
)row format delimited fields terminated by ',';
代码:
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
public class MyUDTFDemo2 extends GenericUDTF {
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {
//创建两个集合,这两个集合是一一对应的关系
//一个是列名的集合
// 注意集合的泛型
ArrayList<String> colNameList = new ArrayList<>();
colNameList.add("id");
colNameList.add("time");
colNameList.add("value");
//另一个是列数据类型的集合
// 注意集合的泛型
ArrayList<ObjectInspector> colTypeList = new ArrayList<>();
colTypeList.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
colTypeList.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
colTypeList.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
//将列名集合和列数据类型集合对应返回
return ObjectInspectorFactory.getStandardStructObjectInspector(colNameList, colTypeList);
}
@Override
public void process(Object[] args) throws HiveException {
String[] infos = new String[3];
//a,1,2,3,4,5,6,7,8,9,10,11,12
//输出:
// a 0时 1
String id = args[0].toString();
infos[0] = id;
int t = 0;
for (int i = 1; i < args.length; i++) {
infos[1] = t + "时";
infos[2] = args[i].toString();
forward(infos);
t += 2;
}
}
@Override
public void close() throws HiveException {
}
}
添加jar资源:
load data local inpath '/usr/local/soft/bigdata30/udtfData.txt' into table udtfData;
add jar /usr/local/soft/bigdata30/data_jars/hive-1.0-jar-with-dependencies.jar;
注册udtf函数:
create temporary function shujia2 as 'com.shujia.custom.udtf.MyUDTFDemo2';
SQL:
select shujia2(*) from udtfData;

UDAF:多进一出
连续登陆问题
在电商、物流和银行可能经常会遇到这样的需求:统计用户连续交易的总额、连续登陆天数、连续登陆开始和结束时间、间隔天数等
数据:
注意:每个用户每天可能会有多条记录
id datestr amount
1,2019-02-08,6214.23
1,2019-02-08,6247.32
1,2019-02-09,85.63
1,2019-02-09,967.36
1,2019-02-10,85.69
1,2019-02-12,769.85
1,2019-02-13,943.86
1,2019-02-14,538.42
1,2019-02-15,369.76
1,2019-02-16,369.76
1,2019-02-18,795.15
1,2019-02-19,715.65
1,2019-02-21,537.71
2,2019-02-08,6214.23
2,2019-02-08,6247.32
2,2019-02-09,85.63
2,2019-02-09,967.36
2,2019-02-10,85.69
2,2019-02-12,769.85
2,2019-02-13,943.86
2,2019-02-14,943.18
2,2019-02-15,369.76
2,2019-02-18,795.15
2,2019-02-19,715.65
2,2019-02-21,537.71
3,2019-02-08,6214.23
3,2019-02-08,6247.32
3,2019-02-09,85.63
3,2019-02-09,967.36
3,2019-02-10,85.69
3,2019-02-12,769.85
3,2019-02-13,943.86
3,2019-02-14,276.81
3,2019-02-15,369.76
3,2019-02-16,369.76
3,2019-02-18,795.15
3,2019-02-19,715.65
3,2019-02-21,537.71
建表语句
create table deal_tb(
id string
,datestr string
,amount string
)row format delimited fields terminated by ',';
load data local inpath '/usr/local/soft/bigdata30/deal_tb.txt' into table deal_tb;
计算逻辑
- 先按用户和日期分组求和,使每个用户每天只有一条数据
select id,datestr,sum(amount) as amount from deal_tb group by id,datestr;
-
根据用户ID分组按日期排序,将日期和分组序号相减得到连续登陆的开始日期,如果开始日期相同说明连续登陆
-
统计用户连续交易的总额、连续登陆天数、连续登陆开始和结束时间、间隔天数
-- 步骤1 开窗,增添一个按id分组的递增序号列,为后续将日期和分组序号相减得到连续登陆的开始日期做准备
select
t.*,
row_number() over(partition by t.id order by t.datestr) as rn
from
(select id,datestr,sum(amount) as amount from deal_tb group by id,datestr) t;
-- 步骤2 根据用户ID分组按日期排序,将日期和分组序号相减得到连续登陆的开始日期,如果开始日期相同说明连续登陆
select
t2.*,
date_sub(t2.datestr,t2.rn) as grp
from(
select
t1.*,
row_number() over(partition by t1.id order by t1.datestr) as rn
from
(select id,datestr,sum(amount) as amount from deal_tb group by id,datestr) t1
) t2;
-- 可以使用开窗函数得出最终结果: 统计用户连续交易的总额、连续登陆天数、连续登陆开始和结束时间、间隔天数
-- 步骤3 直接对t3进行分组:统计用户连续交易的总额、连续登陆天数、连续登陆开始和结束时间
select
t3.id as id,
min(t3.datestr) as start_date,
max(t3.datestr) as end_date,
sum(t3.amount) as amounts,
count(1) as days
from
(
select
t2.*,
date_sub(t2.datestr,t2.rn) as grp
from(
select
t1.*,
row_number() over(partition by t1.id order by t1.datestr) as rn
from
(select id,datestr,sum(amount) as amount from deal_tb group by id,datestr) t1
) t2
)t3 group by t3.id,t3.grp;
-- 步骤4 求出间隔天数及最终结果
-- LAG(col,n,default_val):**往前第n行数据,col是列名,n是往上的行数,当第n行为null的时候取default_val
select
t4.*,
-- 使用当前行的start_date - 上一行的end_date -1,得出所需要的间隔天数
nvl(datediff(start_date,lag(end_date,1) over(partition by id order by start_date))-1,0) as gap_days
from
(
select
t3.id as id,
min(t3.datestr) as start_date,
max(t3.datestr) as end_date,
sum(t3.amount) as amounts,
count(1) as days
from
(
select
t2.*,
date_sub(t2.datestr,t2.rn) as grp
from(
select
t1.*,
row_number() over(partition by t1.id order by t1.datestr) as rn
from
(select id,datestr,sum(amount) as amount from deal_tb group by id,datestr) t1
) t2
) t3 group by t3.id,t3.grp
) t4;
- 结果