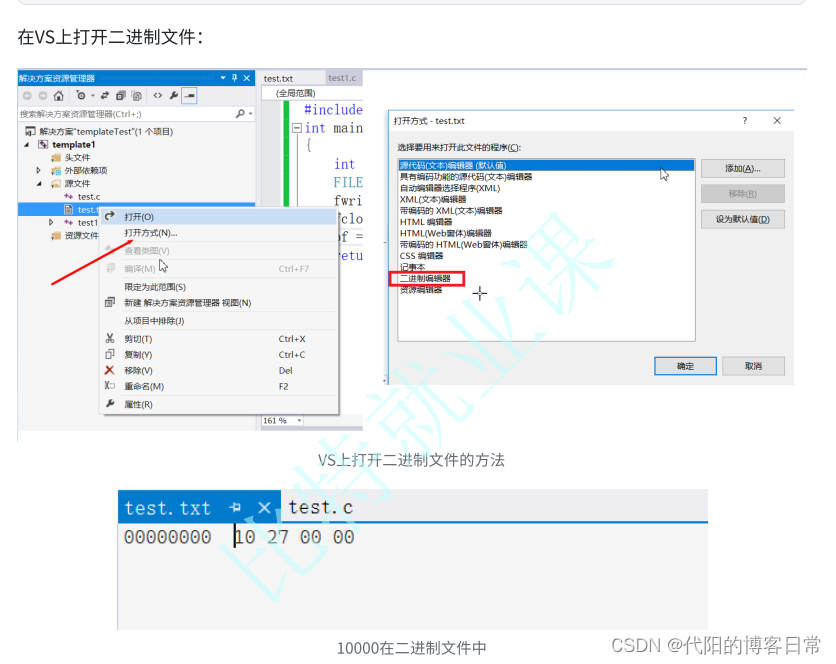
在机器学习和深度学习的训练过程中,不确定性高的点通常代表模型在这些点上的预测不够可靠或有较高的误差。因此,关注这些不确定性高的点,通过计算这些点的损失并进行梯度更新,可以有效地提高模型的整体性能。确定性高的点预测结果已经比较准确,相应地对模型的训练贡献较小,所以可以减少对这些点的关注或完全忽略它们的损失计算。
代码复现参考仓库:https://github.com/NielsRogge/Transformers-Tutorials
在这篇博客中,我们将详细解释 mask2former 中的一段代码,该代码通过不确定性采样点来选择重要点,并探讨其在模型训练中的重要性。mask2former原文描述比较简单,如下:

代码源自transformers库中的modeling_mask2former.py,主要讲解如下代码:
def sample_points_using_uncertainty(
self,
logits: torch.Tensor,
uncertainty_function,
num_points: int,
oversample_ratio: int,
importance_sample_ratio: float,
) -> torch.Tensor:
"""
This function is meant for sampling points in [0, 1] * [0, 1] coordinate space based on their uncertainty. The
uncertainty is calculated for each point using the passed `uncertainty function` that takes points logit
prediction as input.
Args:
logits (`float`):
Logit predictions for P points.
uncertainty_function:
A function that takes logit predictions for P points and returns their uncertainties.
num_points (`int`):
The number of points P to sample.
oversample_ratio (`int`):
Oversampling parameter.
importance_sample_ratio (`float`):
Ratio of points that are sampled via importance sampling.
Returns:
point_coordinates (`torch.Tensor`):
Coordinates for P sampled points.
"""
num_boxes = logits.shape[0]
num_points_sampled = int(num_points * oversample_ratio)
# Get random point coordinates
point_coordinates = torch.rand(num_boxes, num_points_sampled, 2, device=logits.device)
# Get sampled prediction value for the point coordinates
point_logits = sample_point(logits, point_coordinates, align_corners=False)
# Calculate the uncertainties based on the sampled prediction values of the points
point_uncertainties = uncertainty_function(point_logits)#[n1+n2, 1, 37632],理解为,值越大,不确定性越高
num_uncertain_points = int(importance_sample_ratio * num_points)#9408
num_random_points = num_points - num_uncertain_points#3136
idx = torch.topk(point_uncertainties[:, 0, :], k=num_uncertain_points, dim=1)[1]#[n1+n2, 9408]这行代码的作用是从每个 num_boxes 的不确定性值中选择 num_uncertain_points 个最大值的索引。这些索引将用于从原始的点坐标张量 point_coordinates 中选择相应的点,这些点将被认为是基于不确定性的重要性采样点。
shift = num_points_sampled * torch.arange(num_boxes, dtype=torch.long, device=logits.device)#这两行代码的主要目的是确保在从 point_coordinates 中选择点时,能够正确地访问全局索引,使得每个 box 的采样点能够准确地映射到整个张量中的位置。
idx += shift[:, None]
point_coordinates = point_coordinates.view(-1, 2)[idx.view(-1), :].view(num_boxes, num_uncertain_points, 2)#[n1+n2, 9408, 2]
if num_random_points > 0:
point_coordinates = torch.cat(
[point_coordinates, torch.rand(num_boxes, num_random_points, 2, device=logits.device)],
dim=1,
)
return point_coordinates
以下是 sample_points_using_uncertainty 函数的参数解释:
- logits (
torch.Tensor): P 个点的 logit 预测值。 - uncertainty_function: 一个函数,接受 P 个点的 logit 预测值并返回它们的不确定性。
- num_points (
int): 需要采样的点的数量 P。 - oversample_ratio (
int): 过采样参数,用于增加采样点的数量,以确保能在不确定性采样中选到合适的点。 - importance_sample_ratio (
float): 使用重要性采样选出的点的比例。
函数步骤解释
-
计算总采样点数
num_boxes = logits.shape[0] num_points_sampled = int(num_points * oversample_ratio)num_boxes是指预测的盒子数量,num_points_sampled是经过过采样之后的总采样点数。 -
生成随机点的坐标
point_coordinates = torch.rand(num_boxes, num_points_sampled, 2, device=logits.device)在 [0, 1] * [0, 1] 空间内生成随机点的坐标。
-
获取这些随机点的预测值
point_logits = sample_point(logits, point_coordinates, align_corners=False)对随机点的坐标进行采样,获取它们的预测 logit 值。
-
计算这些点的不确定性
point_uncertainties = uncertainty_function(point_logits)使用
uncertainty_function计算这些点的不确定性。 -
确定不确定性采样和随机采样的点数
num_uncertain_points = int(importance_sample_ratio * num_points) num_random_points = num_points - num_uncertain_points根据
importance_sample_ratio确定通过不确定性采样的点数num_uncertain_points,以及剩余的随机采样点数num_random_points。 -
选择不确定性最高的点
idx = torch.topk(point_uncertainties[:, 0, :], k=num_uncertain_points, dim=1)[1] shift = num_points_sampled * torch.arange(num_boxes, dtype=torch.long, device=logits.device) idx += shift[:, None] point_coordinates = point_coordinates.view(-1, 2)[idx.view(-1), :].view(num_boxes, num_uncertain_points, 2)使用
torch.topk函数选择每个盒子中不确定性最高的num_uncertain_points个点,并获取它们的坐标。 -
添加随机点
if num_random_points > 0: point_coordinates = torch.cat( [point_coordinates, torch.rand(num_boxes, num_random_points, 2, device=logits.device)], dim=1, )如果需要添加随机采样点,将它们与不确定性采样点合并。
-
返回采样点的坐标
return point_coordinates最终返回所有采样点的坐标。
关键代码解读
1. 偏移量的生成
shift = num_points_sampled * torch.arange(num_boxes, dtype=torch.long, device=logits.device)
这行代码的目的是为每个 box 生成一个偏移量(shift),用于转换局部索引为全局索引。
torch.arange(num_boxes, dtype=torch.long, device=logits.device)生成一个从 0 到num_boxes-1的张量。num_points_sampled是每个 box 中采样的点的数量。- 乘法操作
num_points_sampled * torch.arange(num_boxes, dtype=torch.long, device=logits.device)为每个 box 生成一个偏移量。例如,假设num_points_sampled为 100,那么生成的偏移量张量为[0, 100, 200, 300, ...]。
这些偏移量将用于将局部索引(即每个 box 内的索引)转换为全局索引(即在整个 point_coordinates 中的索引)。
2. 局部索引转换为全局索引
idx += shift[:, None]
这行代码将局部索引转换为全局索引。
idx是torch.topk返回的不确定性最高的点的局部索引,形状为[num_boxes, num_uncertain_points]。shift[:, None]的形状是[num_boxes, 1],通过这种方式将每个 box 的偏移量广播到与idx的形状匹配。
通过将 shift 加到 idx 上,每个 box 的局部索引将变成全局索引。例如,如果第一个 box 的偏移量为 100,那么第一个 box 内的局部索引 [0, 1, 2, ...] 将变为 [100, 101, 102, ...]。
总结
通过 sample_points_using_uncertainty 函数,我们可以有效地选择不确定性高的点进行训练,提高模型在这些关键点上的表现,同时减少确定性高的点的计算开销。这种不确定性采样方法结合了重要性采样和随机采样,确保了模型训练的高效性和鲁棒性。