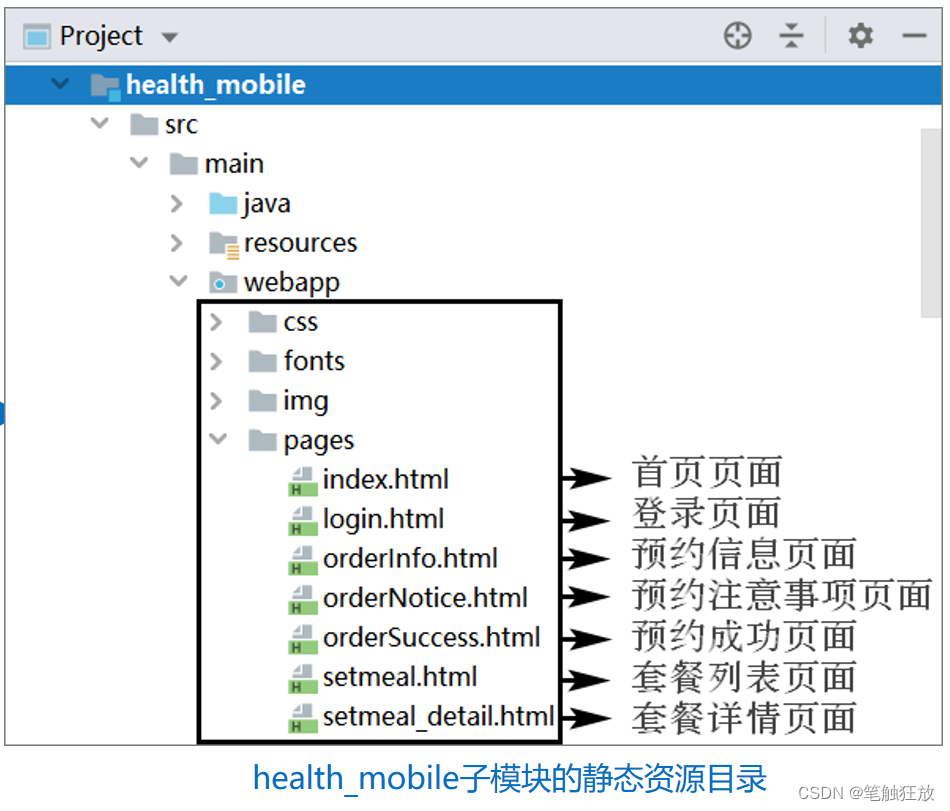
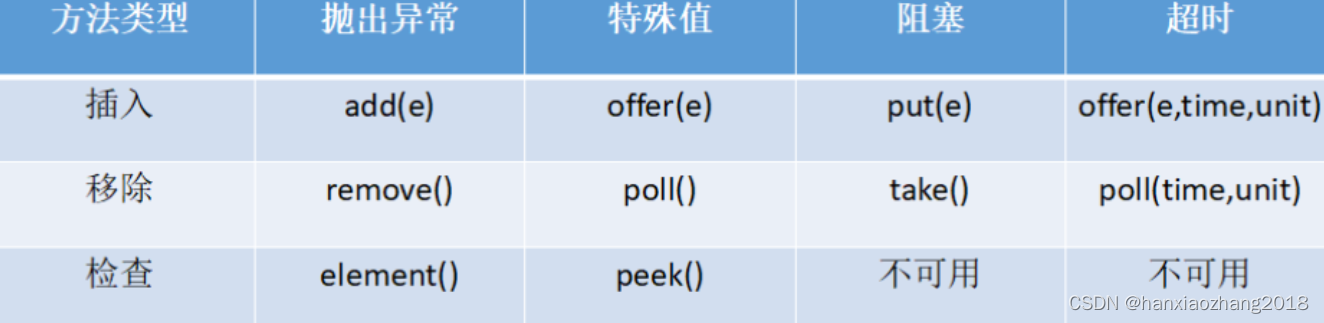
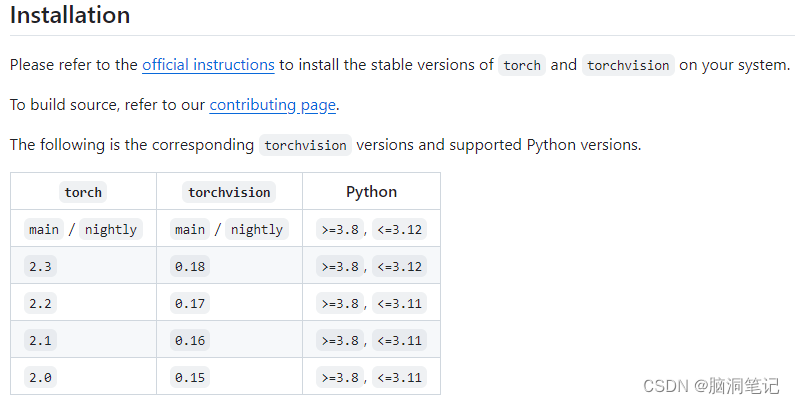
Introduction 介绍
本文档旨在作为学习现代人工智能系统背后的关键概念的手册。考虑到人工智能最近的发展速度,确实没有一个好的教科书式的资源来快速了解 LLMs 或其他生成模型的最新和最伟大的创新,但互联网上有大量关于这些主题的优秀解释资源(博客文章、视频等)。我的目标是将这些资源中的“最好的”组织成教科书式的演示文稿,它可以作为满足个人人工智能相关学习目标的先决条件的路线图。我希望这将是一份“活文件”,随着新的创新和范式不可避免地出现而进行更新,并且理想情况下也是一份可以从社区投入和贡献中受益的文件。本指南针对的是那些具有某种技术背景、出于好奇或潜在职业而有兴趣深入研究人工智能的人。我假设您有一些编码和高中数学水平的经验,但否则将提供填写任何其他先决条件的指导。如果您认为有什么需要补充的,请告诉我!

The AI Landscape 人工智能前景
截至 2024 年 6 月,自 OpenAI 发布 ChatGPT 以来已经过去了大约 18 个月,世界开始更多地谈论人工智能。此后发生了很多事情:Meta 和 Google 等科技巨头发布了自己的大型语言模型,Mistral 和 Anthropic 等较新的组织也被证明是有力的竞争者,无数初创公司开始在他们的 API 基础上构建,每个人都在争夺强大的 Nvidia GPU、论文以极快的速度出现在 ArXiv 上、由 LLMs 驱动的物理机器人和人工程序员的演示在流传,聊天机器人似乎正在寻找进入在线生活的各个方面的方法(在不同程度上)的成功)。与LLM竞赛同时进行的,通过扩散模型生成图像也取得了快速发展; DALL-E 和 Midjourney 正在展示越来越令人印象深刻的结果,这些结果常常在社交媒体上难倒人们,随着 Sora、Runway 和 Pika 的进步,高质量视频生成似乎也指日可待。关于“AGI”何时到来、“AGI”到底意味着什么、开放模型与封闭模型的优点、价值一致性、超级智能、存在风险、假新闻和经济的未来,一直存在争论。许多人担心自动化会导致工作岗位流失,或者对自动化可能推动的进步感到兴奋。世界在不断发展:芯片变得更快,数据中心变得更大,模型变得更智能,上下文变得更长,能力通过工具和愿景得到增强,但目前尚不完全清楚这一切的发展方向。如果您在 2024 年关注“人工智能新闻”,您通常会感觉几乎每天都会发生某种重大的新突破。有很多事情需要跟上,尤其是当你刚刚开始收听时。
随着进展如此之快,那些寻求“参与行动”的人自然倾向于选择最新最好的可用工具(截至撰写本文时,可能是 GPT-4o、Gemini 1.5 Pro 或 Claude 3 Opus) ,取决于你问的是谁)并尝试在它们之上构建一个网站或应用程序。当然还有很大的空间,但这些工具会很快发生变化,对底层基础知识有深入的了解将使您更容易地充分利用您的工具,并在新工具推出时快速使用它们,并评估成本、性能、速度、模块化和灵活性等方面的权衡。此外,创新不仅仅发生在应用层,Hugging Face、Scale AI 和 Together AI 等公司通过专注于开放权重模型的推理、训练和工具(等等)而站稳了脚跟。无论您是想参与开源开发、从事基础研究,还是在因成本或隐私问题而无法使用外部 API 的环境中利用 LLMs,了解这些事情在hood,以便根据需要调试或修改它们。从更广泛的职业角度来看,当前的许多“AI/ML 工程师”角色除了高级框架之外还将重视具体知识,就像“数据科学家”角色通常寻求对理论和基础知识的牢固掌握一样对当前的 ML 框架过于熟练。深入研究是一条更艰难的道路,但我认为这是一条值得的道路。但随着过去几年创新的步伐,您应该从哪里开始呢?哪些主题是必不可少的,您应该按什么顺序学习它们,以及您可以浏览或跳过哪些主题?
The Content Landscape 内容格局
教科书非常适合提供一系列领域的高级路线图,其中“关键思想”集更加稳定,但据我所知,确实没有公开的 ChatGPT 后“人工智能指南”和教科书-风格的全面性或组织性。目前还不清楚有人编写一本涵盖人工智能当前状况的传统教科书是否有意义;许多关键想法(例如 QLoRA、DPO、vLLM)都还不到一年的时间,到印刷时该领域可能已经发生了巨大变化。经常引用的《Deep Learning》一书(Goodfellow 等人)已经有近十年的历史了,并且只粗略地提到了通过 RNN 进行语言建模。较新的《Dive into Deep Learning》一书涵盖了 Transformer 架构和 BERT 模型的微调,但 RLHF 和 RAG 等主题(按照我们将要涉及的一些更前沿主题的标准来看,这些主题已经“过时”) ) 缺失。即将出版的《Hands-On Large Language Models》一书可能很不错,但它尚未正式出版(现在可以通过付费专区在线获取),并且可能不会免费。如果您是斯坦福大学的学生,CS224n 课程似乎很棒,但如果没有登录,您只能使用幻灯片和主要由密集的学术论文组成的阅读列表。微软的“Generative AI for Beginners面向初学者的生成式人工智能”指南相当可靠,可以帮助您熟悉流行的框架,但它更侧重于应用程序而不是理解基础知识。
据我所知,与我的想法最接近的资源是 Github 上 Maxime Labonne 的 LLM 课程。它具有许多交互式代码笔记本,以及用于学习基本概念的资源链接,其中一些与我将在此处包含的内容重叠。我建议您在阅读本手册时将其作为主要配套指南,特别是如果您对应用程序感兴趣的话;本文档不包括笔记本,但我涵盖的主题范围更广泛,包括一些不太“标准”的研究线程以及多模式模型。
尽管如此,还有大量其他高质量且易于访问的内容涵盖了人工智能的最新进展——只是不是全部都井井有条。快速了解新创新的最佳资源通常是一次性博客文章或 YouTube 视频(以及 Twitter/X 线程、Discord 服务器以及 Reddit 和 LessWrong 上的讨论)。我编写本文档的目标是提供一个导航所有这些内容的路线图,将其组织成教科书式的演示文稿,而无需重新设计各个解释器。在整个过程中,我将尽可能包含多种风格的内容(例如视频、博客和论文),以及我对目标相关知识优先顺序的看法以及我在第一次遇到这些主题时发现有用的“心理模型”注释。
我并不是以“生成式人工智能专家”的身份来创建这份文档,而是以最近有过在短时间内熟悉这些主题的经验的人的身份来创建这份文档。虽然我从 2016 年左右就开始从事人工智能相关工作(如果我们将运行视觉模型评估的实习项目算作“开始”),但我只是在 18 个月后才开始密切关注 LLM 的发展之前,随着 ChatGPT 的发布。大约 12 个月前,我第一次开始使用开放重量 LLMs。因此,过去一年我花了很多时间筛选博客文章、论文和视频,以寻找其中的精华;希望本文档是该路径的更直接版本。它也是我与朋友进行的许多对话的精华,我们试图找到并分享处理复杂主题的有用直觉,以加快彼此的学习速度。编译这篇文章对于填补我自己的理解空白也是一个很大的推动作用。直到几周前我才知道 FlashAttention 是如何工作的,而且我仍然认为我还没有真正理解状态空间模型。但我比刚开始的时候知道了很多。
Resources 资源
我们将借鉴的一些来源是:
Blogs: 博客:
- Hugging Face blog posts 拥抱脸博客文章
- Chip Huyen’s blog 博客
- Lilian Weng’s blog 博客
- Tim Dettmers’ blog 博客
- Towards Data Science 走向数据科学
- Andrej Karpathy’s blog 博客
- Sebastian Raschka’s “Ahead of AI” blog 博客
YouTube: YouTube:
- Andrej Karpathy’s “Zero to Hero” videos “从零到英雄”视频
- 3Blue1Brown videos 3Blue1Brown 视频
- Mutual Information 互信息
- StatQuest 统计任务
Textbooks 教科书
- The d2l.ai interactive textbook d2l.ai 互动教科书
- The Deep Learning textbook 深度学习教科书
Web courses: 网络课程:
- Maxime Labonne’s LLM Course
- Microsoft’s “Generative AI for Beginners” 微软的“面向初学者的生成式人工智能”
- Fast.AI’s “Practical Deep Learning for Coders” Fast.AI 的“程序员实用深度学习”
- Assorted university lecture notes 各种大学讲义
- Original research papers (sparingly) 原创研究论文(少量)
我经常会参考原始论文的关键思想,但我们的重点将是更简洁和概念性的说明性内容,针对的是学生或从业者,而不是经验丰富的人工智能研究人员(尽管希望进行人工智能研究的前景会更好)当您在这些来源中取得进展时,就会变得不那么令人畏惧)。如果可能的话,将给出多种资源和媒体格式的指示,并对其相对优点进行一些讨论。
Chapter 1: Preliminaries 第一章:预备知识
Math 数学
如果你想了解现代深度学习,微积分和线性代数几乎是不可避免的,现代深度学习很大程度上是由矩阵乘法和梯度反向传播驱动的。许多技术人员围绕多元微积分或入门线性代数结束了他们的正式数学教育,并且由于必须记住一套不直观的恒等式或手动求逆矩阵而感到口酸,这似乎很常见,这可能会阻碍你的学习。进一步深入数学教育的前景。幸运的是,我们不需要自己进行这些计算——编程库将为我们处理它们——相反,掌握以下概念的实用知识更为重要:
- Gradients and their relation to local minima/maxima 梯度及其与局部最小值/最大值的关系
- The chain rule for differentiation 微分的链式法则
- Matrices as linear transformations for vectors 矩阵作为向量的线性变换
- Notions of basis/rank/span/independence/etc. 基础/等级/跨度/独立性/等等的概念。
良好的可视化确实可以帮助这些想法深入人心,我认为没有比 3Blue1Brown 的这两个 YouTube 系列更好的资源了:
- Essence of calculus 微积分的本质
- Essence of linear algebra 线性代数本质
如果你的数学很生疏,我当然鼓励你在深入研究之前(重新)观看这些内容。为了测试您的理解程度,或者作为我们前进方向的预览,同一频道上较短的神经网络 Neural networks视频系列也非常好,该系列中的最新几个视频对用于语言建模的 Transformer 网络进行了很好的概述。
滑铁卢Waterloo的这些讲义 对与优化相关的多变量微积分进行了一些有用的介绍,Sheldon Axler 的《Linear Algebra Done Right”线性代数》是线性代数的一本很好的参考书。 Boyd 和 Vandenberghe 的“凸优化Convex Optimization”展示了这些主题如何为机器学习中面临的各种优化问题奠定基础,但请注意,它确实具有相当的技术性,如果您最感兴趣的是应用程序,则可能不是必需的。
线性规划当然值得理解,并且基本上是您将遇到的最简单的高维优化问题(但仍然非常实用);这个视频应该为您提供大部分核心思想,如果您想更深入地了解数学,Ryan O’Donnell 的视频(本系列中的 17a-19c,取决于您想要深入的程度)非常好。 Tim Roughgarden 的这些讲座(#10、#11)还展示了线性编程和我们稍后将讨论的“在线学习”方法之间的一些有趣的联系,这将构成 GAN(以及许多其他事物)的概念基础。
Programming 编程
如今,大多数机器学习代码都是用 Python 编写的,这里的一些参考文献将包括用于说明所讨论主题的 Python 示例。如果您不熟悉 Python 或一般编程,推荐 Replit’s 100 Days of Python。一些系统级主题还将涉及 C++ 或 CUDA 中的实现 - 诚然,我在这方面都不是专家,并且将更多地关注可以通过 Python 库访问的更高级别的抽象,但我会尽管如此,在相关部分中仍包含这些语言的潜在有用参考。
Organization 组织
本文档分为几个部分和章节,如下和侧栏中所列。我们鼓励您跳到对您的个人学习目标最有用的部分。总的来说,我建议首先浏览许多链接的资源,而不是逐字阅读(或观看)。希望这至少能让您了解在任何特定学习目标的依赖性方面您的知识差距在哪里,这将有助于指导更有针对性的第二遍。
Section I: Foundations of Sequential Prediction 第一节:序列预测的基础
Goal: Recap machine learning basics + survey (non-DL) methods for tasks under the umbrella of “sequential prediction”.
目标:回顾“序列预测”下任务的机器学习基础知识 + 调查(非深度学习)方法。
Section II: Neural Sequential Prediction 第二节:神经序列预测
Goal: Survey deep learning methods + applications to sequential and language modeling, up to basic Transformers.
目标:调查深度学习方法以及顺序和语言建模的应用,直至基本的 Transformer。
Section III: Foundations for Modern Language Modeling 第三节:现代语言建模的基础
Goal: Survey central topics related to training LLMs, with an emphasis on conceptual primitives.
目标:调查与培训LLMs相关的中心主题,重点是概念原语。
Section IV: Finetuning Methods for LLMs 第四节:LLMs的微调方法
Goal: Survey techniques used for improving and “aligning” the quality of LLM outputs after pretraining.
目标:用于改进和“调整”预训练后 LLM 输出质量的调查技术。
Section V: LLM Evaluations and Applications 第五节:LLM评估和应用
Goal: Survey how LLMs are used and evaluated in practice, beyond just “chatbots”.
目标:调查 LLMs 在实践中的使用和评估方式,而不仅仅是“聊天机器人”。
Section VI: Performance Optimizations for Efficient Inference 第六节:高效推理的性能优化
Goal: Survey architecture choices and lower-level techniques for improving resource utilization (time, compute, memory).
目标:调查用于提高资源利用率(时间、计算、内存)的架构选择和底层技术。
Section VII: Sub-Quadratic Context Scaling 第七节:次二次上下文缩放
Goal: Survey approaches for avoiding the “quadratic scaling problem” faced by self-attention in Transformers.
目标:避免 Transformers 中自注意力所面临的“二次缩放问题”的调查方法。
Section VIII: Generative Modeling Beyond Sequences 第八节:超越序列的生成建模
Goal: Survey topics building towards generation of non-sequential content like images, from GANs to diffusion models.
目标:调查主题旨在生成非序列内容,如图像,从 GAN 到扩散模型。
Section IX: Multimodal Models 第九节:多式联运模型
Goal: Survey how models can use multiple modalities of input and output (text, audio, images) simultaneously.
目标:调查模型如何同时使用多种输入和输出模式(文本、音频、图像)。
一群人走得远

参考
https://genai-handbook.github.io/









![[13] CUDA_Opencv联合编译过程](https://img-blog.csdnimg.cn/direct/181d878eacf54eb2aa45b02abd8dd7bf.png)