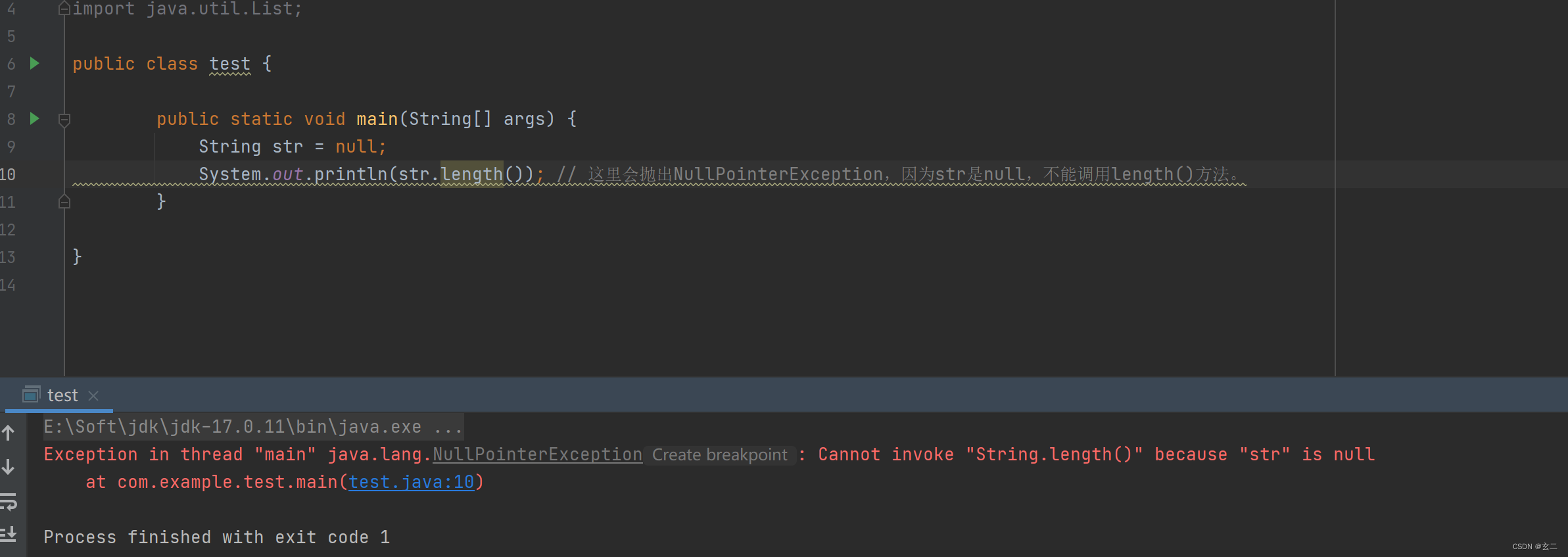
1. buddy system简介:
伙伴系统是内核中用来管理物理内存的一种算法,我们知道内存中有一些是被内核代码占用,还有一些是被特殊用途所保留,那么剩余的空闲内存都会交给内核内存管理系统来进行统一管理和分配。
内核中会把内存按照页来组织分配,随着进程的对内存的申请和释放,系统的内存会不断的区域碎片化,到最后会发现,明明系统还有很多空闲内存,却无法分配出一块连续的内存,这对于系统来说并不是好事。而伙伴系统算法就是为了缓解这种碎片化。
伙伴系统是一个结合了2的方幂个分配器和空闲缓冲区合并计技术的内存分配方案, 其基本思想很简单. 内存被分成含有很多页面的大块, 每一块都是2个页面大小的方幂. 如果找不到想要的块, 一个大块会被分成两部分, 这两部分彼此就成为伙伴. 其中一半被用来分配, 而另一半则空闲. 这些块在以后分配的过程中会继续被二分直至产生一个所需大小的块. 当一个块被最终释放时, 其伙伴将被检测出来, 如果伙伴也空闲则合并两者。
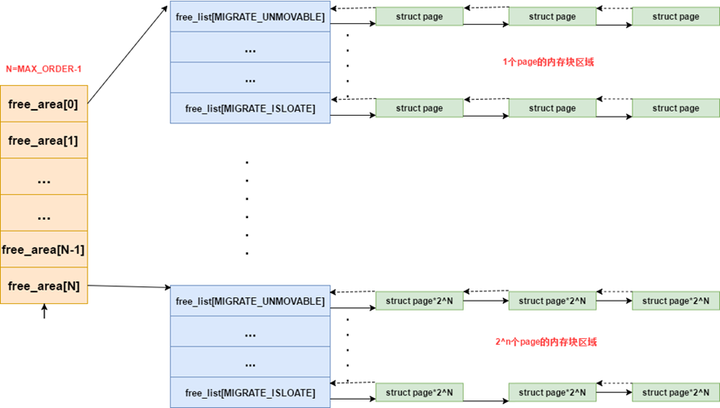
确切来说是分成了11个组,分别对应11种大小不同的连续内存块,每组中的内存块大小都相等,为2的幂次个物理页。那么系统中就存在2 ^ 0~2 ^ 10这么11种大小不同的内存块,对应内存块大小为4KB ~ 4KB * 2^10。也就是4KB ~ 4M。内核用11个链表来管理11种大小不同的内存块。
2. 伙伴系统:
2.1 初始化流程
在内核启动早期,memblock已经对内存进行一定的统计和预留。当执行到mm_init时,就是伙伴系统接管内存的时候。流程如下:
mm_init
--->mem_init
---|---> memblock_free_all (this will put all unused low memory onto the freelists)
---|---|--->free_low_memory_core_early
---|---|---|--->__free_memory_core(start, end)
---|---|---|---|--->__free_pages_memory(start_pfn, end_pfn)
---|---|---|---|---|---> memblock_free_pages (pfn_to_page(start), start, order)
---|---|---|---|---|---|---> __free_pages_core (page, order)
---|---|---|---|---|---|---|--->__free_pages_ok (page, order, fpi_flags)
---|---|---|---|---|---|---|---|--->free_one_page (page, order, fpi_flags)/**
* memblock_free_all - release free pages to the buddy allocator
*
* Return: the number of pages actually released.
*/
unsigned long __init memblock_free_all(void)
{
unsigned long pages;
/* 涉及到两个关键结构体:
struct pglist_data *pgdat (typedef pg_data_t);
struct zone *z;
*/
reset_all_zones_managed_pages();
pages = free_low_memory_core_early();
totalram_pages_add(pages);
return pages;
}在函数__free_pages_memory中,对memblock的free内存按照order进行释放
static void __init __free_pages_memory(unsigned long start, unsigned long end)
{
int order;
while (start < end) {
order = min(MAX_ORDER - 1UL, __ffs(start));
while (start + (1UL << order) > end)
order--;
memblock_free_pages(pfn_to_page(start), start, order);
start += (1UL << order);
}
}随后调用到函数__free_pages_core,将zone管理的页进行增加,执行页释放和页合并的过程,并最终通过__free_one_page将所释放出来的全部页按照order统合进伙伴系统中(使用函数add_to_free_list_tail,即将统合好的pages放进对应的free_list链表中)
void __free_pages_core(struct page *page, unsigned int order)
{
unsigned int nr_pages = 1 << order;
struct page *p = page;
unsigned int loop;
/* 部分删减 */
/* 对当前页对应的zone所管理的page大小进行设置(增加) */
atomic_long_add(nr_pages, &page_zone(page)->managed_pages);
/*
* Bypass PCP and place fresh pages right to the tail, primarily
* relevant for memory onlining.
*/
/* 这里涉及复杂的page合并和释放过程,下面具体分析 */
__free_pages_ok(page, order, FPI_TO_TAIL);
}
/* Used for pages not on another list */
static inline void add_to_free_list_tail(struct page *page, struct zone *zone, unsigned int order, int migratetype)
{
struct free_area *area = &zone->free_area[order];
list_add_tail(&page->lru, &area->free_list[migratetype]);
area->nr_free++; /* 维护当前order还有多少空余的计数器 */
}
__free_one_page的注释翻译:这是Buddy System分配器的释放函数。
Buddy System的概念是维护一种直接映射的表(包含位值),用于不同"次序"的存储块内存。底层表包含最小可分配的存储单元(在这里是页面)的映射,而每个上层级别则描述下层级别的两个存储单元,因此被称为"伙伴"。在高层次上,所发生的就是将底层表中的表项标记为可用,并根据需要向上传递更改,加上一些与VM系统的其他部分交互所需的账户。
在每个级别上,我们保留一个页面列表,这些页面是长度为 (1 << order) 的连续可用页面列表的头,并带有 PageBuddy 标志。页面的顺序存储在 page_private(page) 字段中。因此,当我们分配或释放一个页面时,我们可以推导出另一个页面的状态。也就是说,如果我们分配了一个小块,并且两个页面都是空闲的,那么剩余的区域必须被分割成块。如果释放了一个块,并且它的伙伴也是空闲的,那么这将触发合并成更大尺寸的块。
从上图也可以看出,本设备只有一个node和一个zone就是node0,zone_normal
2.2 关键数据或结构体
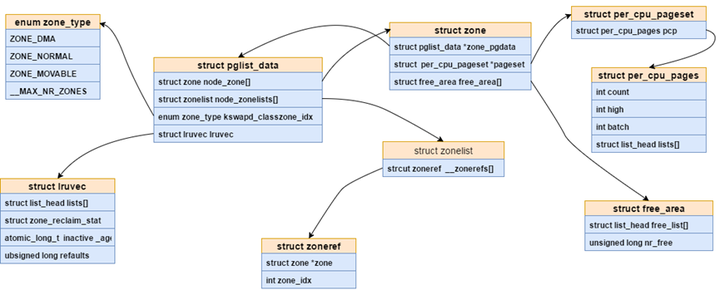
2.2.1 pglist_data(内存结点)
在 NUMA 机器上,每个 NUMA 节点都有一个 pg_data_t 描述其内存布局。在 UMA 机器上,存在一个单独的 pglist_data,它描述了整个内存。
而内存统计信息和页面替换数据结构是基于每个区域(zone)进行维护的
typedef struct pglist_data {
/* node_zones 仅包含此节点的区域(zone)。并非所有区域都可能已经被填充,
但它是完整的列表(比如我手中的设备只有zone normal)。
它被本节点或其他节点的 node_zonelists 引用 */
//包含节点中各内存域(ZONE_DMA, ZONE_DMA32, ZONE_NORMAL...)的数据结构
//详见enum zone_type 中的定义(include\linux\mmzone.h)
struct zone node_zones[MAX_NR_ZONES];
/* node_zonelists 包含对所有节点中所有区域(zone)的引用。
通常,前几个区域(zone)将引用本节点的 node_zones */
//对于非NUMA的设备而言,实际上只指向一个指定的zone
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones; /* 此节点中已填充区域(zone)的数量 */
/* 部分删除 */
unsigned long node_start_pfn; // 当前NUMA节点第一页帧逻辑编号。在UMA总是0.
unsigned long node_present_pages; /* 结点中页帧的数目 */
unsigned long node_spanned_pages; /* 结点以页帧为单位计算的长度,包含内存空洞 */
int node_id; //全局结点ID,系统中的NUMA结点都从0开始编号
wait_queue_head_t kswapd_wait; //交换守护进程的等待队列,在将页帧换出结点时会用到
wait_queue_head_t pfmemalloc_wait;
struct task_struct *kswapd; /* 指向负责该结点的交换守护进程的task_struc*/
int kswapd_order;// 定义需要释放的区域的长度。
/* 部分删除 */
struct lruvec __lruvec; // lru缓存链表,这个东西也非常复杂,以后有空再详细分析
} pg_data_t;2.2.2 zone(内存域)
struct zone {
/* Read-mostly fields */
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long _watermark[NR_WMARK]; //记录着oom的水位线
unsigned long watermark_boost; //水位线计算和该值相关
/* 部分删除 */
struct pglist_data *zone_pgdat; //指向该zone对应的内存节点
struct per_cpu_pageset __percpu *pageset; //PCP技术,这里先不分析
/*
* Flags for a pageblock_nr_pages block. See pageblock-flags.h.
* In SPARSEMEM, this map is stored in struct mem_section
*/
unsigned long *pageblock_flags; //管理着位图信息,祥见pageblock-flags.h
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn;
/* `spanned_pages`是该区域所涵盖的总页面数,包括空洞,其计算公式为:
* spanned_pages = zone_end_pfn - zone_start_pfn;
*
* `present_pages`是该区域内物理页面的数量,该数量不包括空洞,其计算公式为:
* present_pages = spanned_pages - absent_pages(空洞中的页面数);
*
* `managed_pages` 是 buddy system 管理的 `present_pages` 页的数量,其计算公式为
* (`reserved_pages` 包括由 bootmem 分配器分配的页面):
* managed_pages = present_pages - reserved_pages;
*
* 因此,`present_pages` 可由内存热插拔或内存电源管理逻辑使用,
* 通过检查(`present_pages - managed_pages`)来查找未管理的页面。
* `managed_pages` 应该由页分配器和VM扫描器用于计算各种水印和阈值。
*/
atomic_long_t managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
/* 部分删除 */
/* free areas of different sizes */
//用于管理该zone的伙伴系统信息。伙伴系统将基于这些信息管理该zone的物理内存。
//该数组中每个数组项用于管理一个空闲内存页块链表,同一个链表中的内存页块的大小相同,
//并且大小为2的数组下标次方页。MAX_ORDER定义了支持的最大的内存页块大小
struct free_area free_area[MAX_ORDER];
/* 部分删除 */
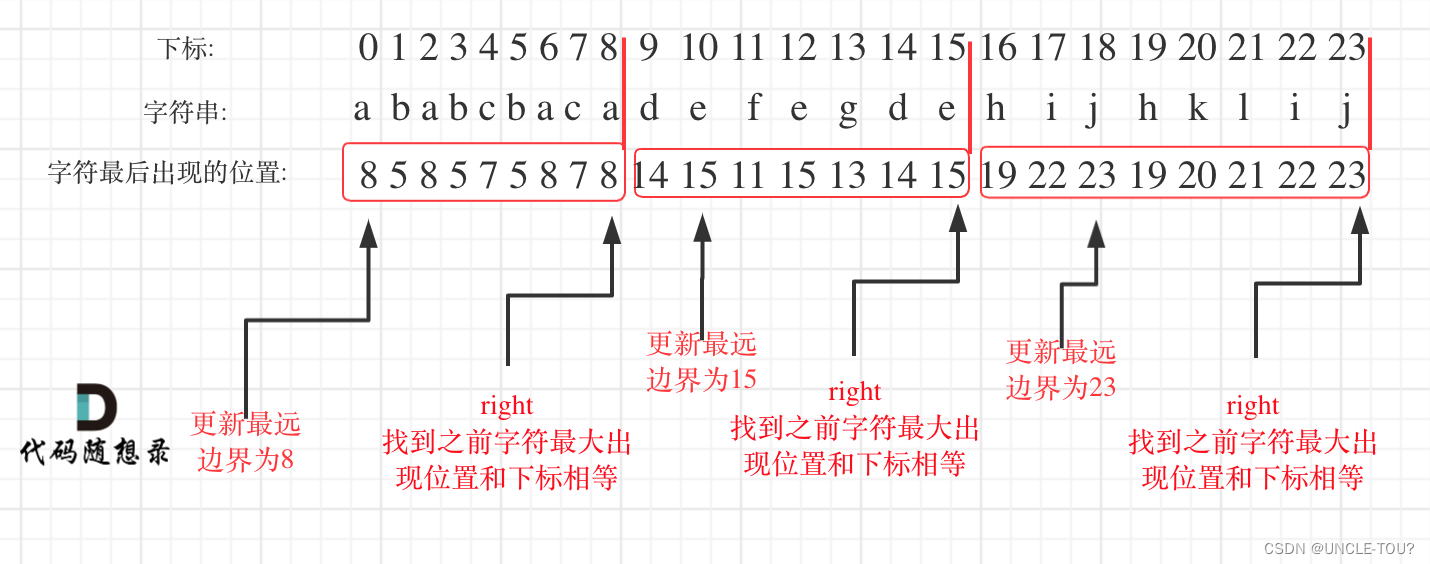
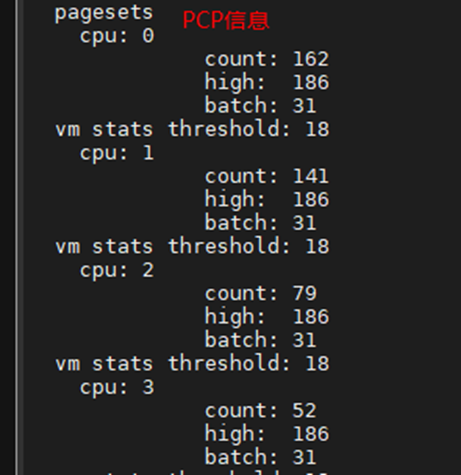
} ____cacheline_internodealigned_in_smp;关于zone,cat /proc/zoneinfo可以获得如下信息
min: wmark_low (水位线相关的具体看)
low: wmark_ low
high: wmark_ high
spanned: 该node的全部页,包括空洞
present:该node的实际内存页,去掉空洞
managed:实际管理的内存,去掉了预留
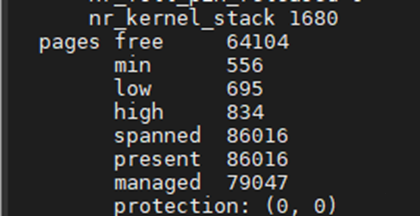
当我们修min_free_kbytes:zoneinfo对应的水位也同步修改了
这里给大家推荐一个小课,linux内核内存管理实战案例分析,帮助你更好的学习linux内核内存管理模块

学习地址:https://xxetb.xetslk.com/s/YH3lb(含完整视频教程+项目全套源码,还有老师答疑。)
2.2.3 free_area
struct free_area {
//用于将具有该大小的内存页块连接起来。由于内存页块表示的是连续的物理页,
//因而对于加入到链表中的每个内存页块来说,只需要将内存页块中的第一个页加入该链表即可。
//因此这些链表连接的是每个内存页块中第一个内存页,使用了struct page中的
//struct list_head成员lru。free_list数组元素的每一个对应一种属性的类型,
//可用于不同的目地,但是它们的大小和组织方式相同
struct list_head free_list[MIGRATE_TYPES];
//内存页块的数目,对于0阶的表示以1页为单位计算,
//对于1阶的以2页为单位计算,n阶的以2的n次方为单位计算
unsigned long nr_free;
};其中migreatetype定义如下
enum migratetype {
// 在内存中有固定位置, 不能移动到其他地方。核心内核分配的大多数内存属于该类别
MIGRATE_UNMOVABLE,
// 可以随意地移动 属于用户空间应用程序的页属于该类别.
// 它们是通过页表映射的,如果它们复制到新位置,
//页表项可以相应地更新,应用程序不会注意到任何事
MIGRATE_MOVABLE,
//不能直接移动, 但可以删除, 其内容可以从某些源重新生成。
//例如,映射自文件的数据属于该类别。kwapd守护进程会根据可回收页访问的频繁程度,
//周期性释放此类内存.页面回收本身就是一个复杂的过程.
//内核会在可回收页占据了太多内存时进行回收,在内存短缺(即分配失败)时也可以发起页面回收
MIGRATE_RECLAIMABLE,
//the number of types on the pcp lists
//用来表示每CPU页框高速缓存的数据结构中的链表的迁移类型数目
MIGRATE_PCPTYPES,
//在罕见的情况下,内核需要分配一个高阶的页面块而不能休眠.
//如果向具有特定可移动性的列表请求分配内存失败,
//这种紧急情况下可从MIGRATE_HIGHATOMIC中分配内存
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,
#ifdef CONFIG_CMA
/*
* MIGRATE_CMA migration type is designed to mimic the way
* ZONE_MOVABLE works. Only movable pages can be allocated
* from MIGRATE_CMA pageblocks and page allocator never
* implicitly change migration type of MIGRATE_CMA pageblock.
*
* The way to use it is to change migratetype of a range of
* pageblocks to MIGRATE_CMA which can be done by
* __free_pageblock_cma() function. What is important though
* is that a range of pageblocks must be aligned to
* MAX_ORDER_NR_PAGES should biggest page be bigger then
* a single pageblock. Linux内核最新的连续内存分配器(CMA),
* 用于避免预留大块内存导致系统可用内存减少而实现的,即当驱动不使用内存时,
* 将其分配给用户使用,而需要时则通过回收或者迁移的方式将内存腾出来
*/
MIGRATE_CMA,
#endif
#ifdef CONFIG_MEMORY_ISOLATION
/* can't allocate from here 是一个特殊的虚拟区域, 用于跨越NUMA结点移动物理内存页.
在大型系统上, 它有益于将物理内存页移动到接近于使用该页最频繁的CPU */
MIGRATE_ISOLATE,
#endif
MIGRATE_TYPES
};在分配内存时,都会带分配参数比如GPF_KERNEL等等,那么,一次内存分配从哪个zone分配了?这里就必需把mask转换成zone,gfp_mask(下面会简单介绍)低4位用于表示分配的zone
#define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS)
/* Convert GFP flags to their corresponding migrate type */
#define GFP_MOVABLE_MASK (__GFP_RECLAIMABLE|__GFP_MOVABLE) =0x18
#define GFP_MOVABLE_SHIFT 3 //低4位决定了使用哪一种migratetype
/* 该函数就是gfp转migratetype */
static inline int gfp_migratetype(const gfp_t gfp_flags)
{
/* 部分删除 */
/* Group based on mobility */
(gfp_flags & 0x18) >> 3
return (gfp_flags & GFP_MOVABLE_MASK) >> GFP_MOVABLE_SHIFT;
以GFP_KERNEL为例 值为0x400|0x800|0x40|0x80 & 0x18 =0
也就是说 GFP_KERNEL 就是使用的 MIGRATE_UNMOVABLE
}2.2.4 gfp_mask
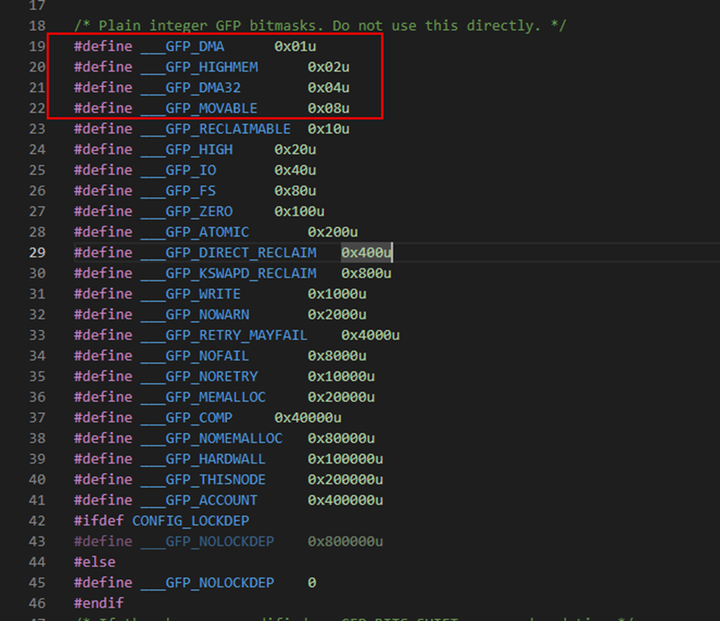
GFP是get free page的缩写, 分配掩码包括两部分,内存域修饰符(占低4位)和内存分配标志(从第5位开始),如下图所示

内存域zone的几种类型:ZONE_DMA、ZONE_DMA32、ZONE_NORMAL、ZONE_HIGHMEM、ZONE_MOVABLE。与类型不同,内存域的修饰符只有___GFP_DMA、___GFP_HIGHMEM、___GFP_DMA32、___GFP_MOVABLE 4种,没有ZONE_NORMAL对应的修饰符,因为ZONE_NORMAL是默认的内存申请类型。如下所示,为内存修饰符的定义,划款的4个为内存域修饰符
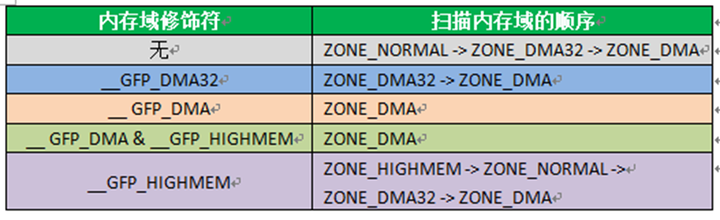
内存域修饰符与伙伴系统分配器扫描内存域的顺序的关系,如下所示:
2.2.5 图示
2.3 伙伴系统内存释放(伙伴整合)
具体分析__free_pages_ok,函数__free_pages_ok位于mm\page_alloc.c,源码如下:
static void __free_pages_ok(struct page *page, unsigned int order,
fpi_t fpi_flags)
{
unsigned long flags;
int migratetype;
unsigned long pfn = page_to_pfn(page); //页转为页框号
//这里最终会调用clear_page(汇编)
if (!free_pages_prepare(page, order, true))
return;
//获取对应页框的migratetype
//该值会在memmap_init -> memmap_init_zone_range -> memmap_init_zone 的时候
//初始化为 MIGRATE_MOVABLE
migratetype = get_pfnblock_migratetype(page, pfn);
local_irq_save(flags);
__count_vm_events(PGFREE, 1 << order);
//对应调用 __free_one_page
free_one_page(page_zone(page), page, pfn, order, migratetype,
fpi_flags);
local_irq_restore(flags);
}伙伴系统维护了直接映射表,其中包含各种“级别”的内存块(包含位值)。底层表包含内存可分配的最小单元(page)的位图,它的每个上层(父级)描述下层的一对单元(一对伙伴),因此是“buddies”的概念。在每个级别上,我们保留页面列表,其中包含长度为 (1<<order) 的连续空闲页面的头部,并标记为 PageBuddy。 Page 的阶数记录在 page_private(page) 字段中。因此,当我们正在分配或释放页面时,我们可以推导出其它页面的状态。也就是说,如果我们分配一个小块,并且两个页面都是空闲的,则该区域的剩余部分必须被拆分成块。如果释放一个块,并且它的 buddy 也是空闲的,则会触发合并成较大块的操作。
static inline void __free_one_page(struct page *page,
unsigned long pfn,
struct zone *zone, unsigned int order,
int migratetype, fpi_t fpi_flags)
{
/* 部分变量删减 */
unsigned long buddy_pfn;
unsigned long combined_pfn;
unsigned int max_order;
struct page *buddy;
max_order = min_t(unsigned int, MAX_ORDER - 1, pageblock_order);
/* 部分删减(BUG_ON判断) */
continue_merging:
while (order < max_order) {
/* 部分删减 */
/* 到这里已经开始涉及到伙伴算法,下面会简单说明 */
buddy_pfn = __find_buddy_pfn(pfn, order); //寻找当前页框对应order阶的伙伴页框
//buddy页,就是当前page加上对应偏移,因为arm64全是线性映射
buddy = page + (buddy_pfn - pfn);
if (!pfn_valid_within(buddy_pfn)) //确保伙伴页不在内存空洞中
goto done_merging;
/*
这个函数检查一个页面是否是空闲的 && 是否是要合并的伙伴。如果:
(a)伙伴不在间隙中(在调用之前检查!)&&
(b)该伙伴在伙伴系统中 &&
(c)页面和它的伙伴具有相同的阶数 &&
(d)页面和它的伙伴在同一区域。
为了记录一个页面是否在 buddy 系统中,我们设置 PageBuddy 标记。
设置、清除和测试 PageBuddy 标记由 zone->lock 加锁保护。
为了记录页面的阶数,我们使用 page_private(page)。
*/
if (!page_is_buddy(page, buddy, order)) //确保是伙伴系统页
goto done_merging;
/*
* Our buddy is free or it is CONFIG_DEBUG_PAGEALLOC guard page,
* merge with it and move up one order.
*/
if (page_is_guard(buddy))
clear_page_guard(zone, buddy, order, migratetype);
else
//对应内存域的对应order的free页自减
del_page_from_free_list(buddy, zone, order);
// 两个伙伴页框合并假设页框地址6的0阶伙伴是 6^(1<<0) = 7 那么 6&7 = 6
combined_pfn = buddy_pfn & pfn;
page = page + (combined_pfn - pfn); //合并之后的页地址是当前页+页框偏移
pfn = combined_pfn; //页框赋值为当前合并后的页框
order++; //阶++
}
/* 删除部分代码 */
done_merging:
set_buddy_order(page, order);
/* 删除部分代码 */
// 这里伙伴页合并完了之后,在对应zone的对应order的free页++
add_to_free_list(page, zone, order, migratetype);
/* 删除部分代码 */
}2.3.1 伙伴算法:
假设:*_mem_map 是至少连续到 MAX_ORDER 的。为了找到伙伴分配中匹配 buddy 和被组合成的页面 page 的 struct page 结构体。
任何伙伴 B1 都有一个与之成对的 O 阶伙伴 B2 ,满足以下等式:
B2 = B1 ^ (1<<O)
例如,如果起始伙伴 (buddy2) 是#8,它的 1 阶伙伴是#10:
B2 = 8 ^ (1<<1) = 8 ^ 2 = 10
任何伙伴 B 都有一个阶 O+1 的父级 P,满足以下等式:
P = B &~(1<<O)
2.4 伙伴系统内存申请
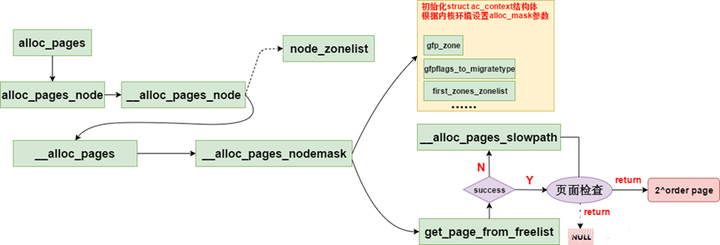
2.4.1 __alloc_pages_nodemask
_alloc_pages_nodemask是伙伴系统的心脏,处理实质的内存分配工作。
-
先进行参数初始化:alloc_mask, alloc_flags和struct alloc_context ac,用于决定内存块的分配配条件。
-
get_page_from_freelist:内核内存环境良好,直接进行快速分配,若成功返回获取free内存块
-
__alloc_pages_slowpath:当前内存环境恶劣时,进入慢分配流程,若成功返回free内存块
-
获取空间内存块后对内存块和系统环境做检查,满足预定要求则返回申请的内存给内核使用
函数位于mm\page_alloc.c,一般调用路径为:alloc_pages -> alloc_pages_node -> __alloc_pages_node -> __alloc_pages -> __alloc_pages_nodemask 源码如下:
static inline struct page *
__alloc_pages(gfp_t gfp_mask, unsigned int order, int preferred_nid)
{
preferred_nid -> 对应nid 如果是UMA 则 nid只能是0
return __alloc_pages_nodemask(gfp_mask, order, preferred_nid, NULL);
}
/*
* gfp_allowed_mask is set to GFP_BOOT_MASK during early boot to restrict what
* GFP flags are used before interrupts are enabled. Once interrupts are
* enabled, it is set to __GFP_BITS_MASK while the system is running. During
* hibernation, it is used by PM to avoid I/O during memory allocation while
* devices are suspended.
*/
//gfp_allowed_mask在早期引导期间设置为GFP_BOOT_MASK,以限制在中断启用之前使用哪些GFP标志。
//一旦启用中断,它将设置为__GFP_BITS_MASK,而系统正在运行。
//在休眠期间,它被用于PM,以避免在设备挂起期间的内存分配期间进行I / O操作。
extern gfp_t gfp_allowed_mask;
/*
* This is the 'heart' of the zoned buddy allocator.
* (这是buddy 分配器的“核心”) kmalloc跟到最后 实际使用的也是该函数
*/
struct page * __alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order,
int preferred_nid, nodemask_t *nodemask)
{
struct page *page;
unsigned int alloc_flags = ALLOC_WMARK_LOW; //快速路径的水位基准是low
gfp_t alloc_mask; /* The gfp_t that was actually used for allocation */
struct alloc_context ac = { };
/* 删除部分数值检查 */
gfp_mask &= gfp_allowed_mask; //gfp掩码检测
alloc_mask = gfp_mask;
/* 对关键参数进行检查,如果检查通过,则选定首选内存申请的zone */
if (!prepare_alloc_pages(gfp_mask, order, preferred_nid, nodemask,
&ac, &alloc_mask, &alloc_flags))
return NULL;
/* 删除部分*/
/* First allocation attempt 函数详细分析见下面*/
page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac);
if (likely(page))
goto out;
/*
* Apply scoped allocation constraints. This is mainly about GFP_NOFS
* resp. GFP_NOIO which has to be inherited for all allocation requests
* from a particular context which has been marked by
* memalloc_no{fs,io}_{save,restore}.
*/
alloc_mask = current_gfp_context(gfp_mask);
ac.spread_dirty_pages = false;
/*
* Restore the original nodemask if it was potentially replaced with
* &cpuset_current_mems_allowed to optimize the fast-path attempt.
*/
ac.nodemask = nodemask;
/* 详细分析见下面 */
page = __alloc_pages_slowpath(alloc_mask, order, &ac);
out:
if (memcg_kmem_enabled() && (gfp_mask & __GFP_ACCOUNT) && page &&
unlikely(__memcg_kmem_charge_page(page, gfp_mask, order) != 0)) {
__free_pages(page, order);
page = NULL;
}
trace_mm_page_alloc(page, order, alloc_mask, ac.migratetype);
return page;
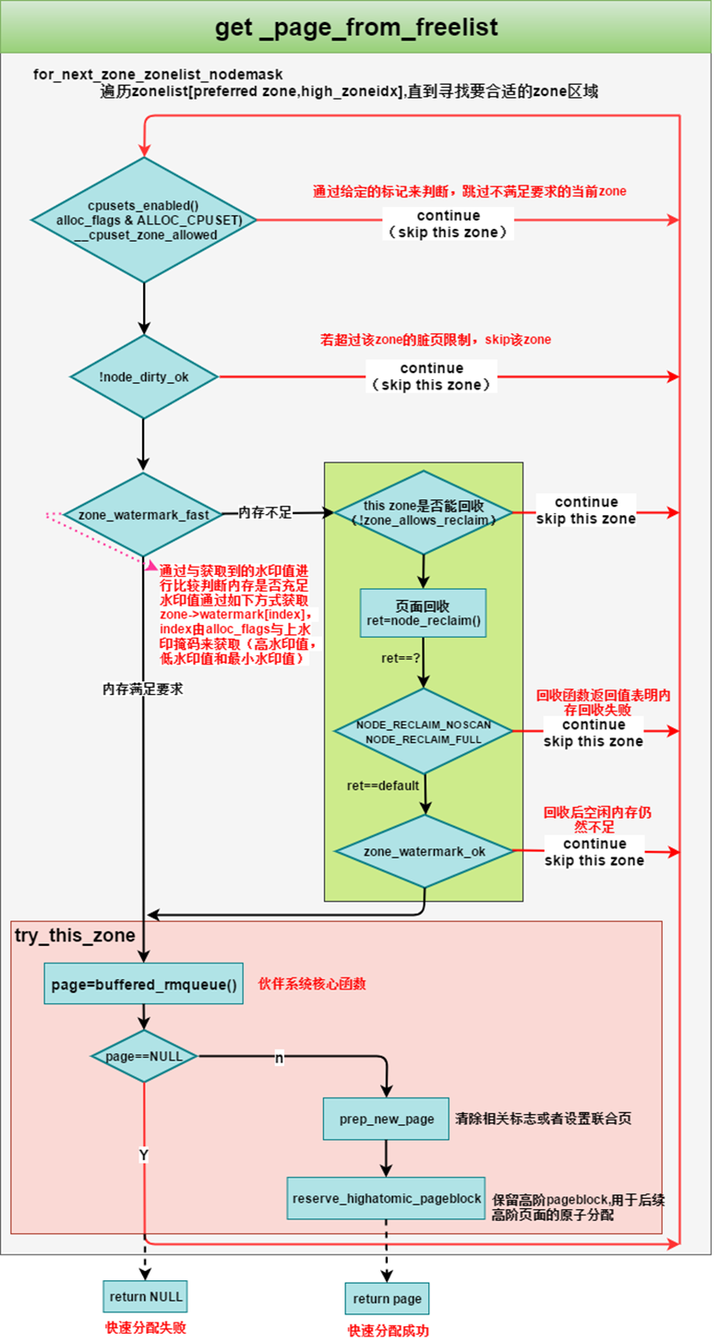
}2.4.2 get_page_from_freelist
伙伴系统内存申请优先使用该函数,尝试获取一个指定order的内存块
/*
* get_page_from_freelist goes through the zonelist trying to allocate
* a page.
*/
static struct page *
get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags,
const struct alloc_context *ac)
{
struct zoneref *z;
struct zone *zone;
struct pglist_data *last_pgdat_dirty_limit = NULL;
bool no_fallback; //如果需要避免内存碎片,则 no_fallback = true
retry:
/*
* Scan zonelist, looking for a zone with enough free.
* See also __cpuset_node_allowed() comment in kernel/cpuset.c.
*/
no_fallback = alloc_flags & ALLOC_NOFRAGMENT; //是否需要避免内存碎片
z = ac->preferred_zoneref;
//开始遍历 zonelist,查找可以满足本次内存分配的物理内存区域 zone
for_next_zone_zonelist_nodemask(zone, z, ac->highest_zoneidx,
ac->nodemask) {
struct page *page; //指向分配成功之后的内存
unsigned long mark; //内存分配过程中设定的水位线
/* 删除部分代码,zone节点查找和各种校验 */
// 获取本次内存分配需要考虑到的内存水位线,
// 快速路径下是 WMARK_LOW, 慢速路径下是 WMARK_MIN
mark = wmark_pages(zone, alloc_flags & ALLOC_WMARK_MASK);
/* 内存是否有剩余,水位线判断,后面进行分析 */
if (!zone_watermark_fast(zone, order, mark,
ac->highest_zoneidx, alloc_flags,
gfp_mask)) {
int ret;
/* Checked here to keep the fast path fast */
BUILD_BUG_ON(ALLOC_NO_WATERMARKS < NR_WMARK);
/* 如果是可以不校验水位线的,就选择这个zone进行page申请 */
if (alloc_flags & ALLOC_NO_WATERMARKS)
goto try_this_zone;
/* 删除部分代码 */
continue; /* 否则在找其他zone */
}
try_this_zone:
//这里就是伙伴系统的入口,rmqueue 函数中封装的就是伙伴系统的核心逻辑
page = rmqueue(ac->preferred_zoneref->zone, zone, order,
gfp_mask, alloc_flags, ac->migratetype);
if (page) {
/* 伙伴系统找到了一个page,对这个page执行一些其他操作,
比如kasan标记,poison该page,如果开启了CONFIG_PAGE_OWNER 还可以设置owner */
prep_new_page(page, order, gfp_mask, alloc_flags);
/*
* If this is a high-order atomic allocation then check
* if the pageblock should be reserved for the future
*/
if (unlikely(order && (alloc_flags & ALLOC_HARDER)))
reserve_highatomic_pageblock(page, zone, order);
return page;
} /* else删除 */
}
/* 删除 */
return NULL;
}虽然 get_page_from_freelist 函数的代码比较冗长,但是其核心逻辑比较简单,主干框架就是通过 for_next_zone_zonelist_nodemask 来遍历当前 NUMA 节点以及备用节点的所有内存区域(zonelist),然后逐个通过 zone_watermark_fast 检查这些内存区域 zone 中的剩余空闲内存容量是否在指定的水位线 mark 之上。如果满足水位线的要求则直接调用 rmqueue 进入伙伴系统分配内存,分配成功之后通过 prep_new_page 初始化分配好的内存页 page。
如果当前正在遍历的 zone 中剩余空闲内存容量在指定的水位线 mark 之下,就需要通过 node_reclaim 触发内存回收,随后通过 zone_watermark_ok 检查经过内存回收之后,内核是否回收到了足够的内存以满足本次内存分配的需要。如果内存回收到了足够的内存则 zone_watermark_ok = true 随后跳转到 try_this_zone 分支在本内存区域 zone 中分配内存。否则继续遍历下一个 zone。
2.4.2.1 水位线检查
static inline bool zone_watermark_fast(struct zone *z, unsigned int order,
unsigned long mark, int highest_zoneidx,
unsigned int alloc_flags, gfp_t gfp_mask)
{
long free_pages;
// 获取当前内存区域中所有空闲的物理内存页
free_pages = zone_page_state(z, NR_FREE_PAGES);
// 快速检查分配阶 order = 0 情况下相关水位线,
// 空闲内存需要刨除掉为 highatomic 预留的紧急内存
if (!order) {
long fast_free;
/* 可供本次内存分配使用的符合要求的真实可用内存,
初始为 free_pages,free_pages 为空闲内存页的全集其中
也包括了不能为本次内存分配提供内存的空闲内存 */
fast_free = free_pages;
//计算真正可供内存分配的空闲页数量:空闲内存页全集 - 不能使用的空闲页
fast_free -= __zone_watermark_unusable_free(z, 0, alloc_flags);
/* 如果可用的空闲内存页数量大于内存水位线与预留内存之和
那么表示物理内存区域中的可用空闲内存能够满足本次内存分配的需要 */
if (fast_free > mark + z->lowmem_reserve[highest_zoneidx])
return true;
}
// 近一步检查内存区域伙伴系统中是否有足够的 order 阶的内存块可供分配
if (__zone_watermark_ok(z, order, mark, highest_zoneidx, alloc_flags, free_pages))
return true;
/* 部分删除 */
return false;
}如果本次内存分配申请的是高阶内存块(order > 0),则会进入 __zone_watermark_ok 函数中,近一步判断伙伴系统中是否有足够的高阶内存块能够满足 order 阶的内存分配:
bool __zone_watermark_ok(struct zone *z, unsigned int order, unsigned long mark,
int highest_zoneidx, unsigned int alloc_flags,long free_pages)
{
// 保证内存分配顺利进行的最低水位线
long min = mark;
int o;
const bool alloc_harder = (alloc_flags & (ALLOC_HARDER|ALLOC_OOM));
/* free_pages may go negative - that's OK */
// 获取真正可用的剩余空闲内存页数量,需要把CMA(若非CMA内存申请)和HIGH预留的减掉
free_pages -= __zone_watermark_unusable_free(z, order, alloc_flags);
// 如果设置了 ALLOC_HIGH 则水位线降低二分之一,使内存分配更加激进一些
if (alloc_flags & ALLOC_HIGH)
min -= min / 2;
if (unlikely(alloc_harder)) {
// 在要进行 OOM 的情况下内存分配会比普通的 ALLOC_HARDER 策略更加激进一些,
// 所以这里水位线会降低二分之一
if (alloc_flags & ALLOC_OOM)
min -= min / 2;
else
min -= min / 4;
}
// 检查当前可用剩余内存是否在指定水位线之上。
// 内存的分配必须保证可用剩余内存容量在指定水位线之上,否则不能进行内存分配
if (free_pages <= min + z->lowmem_reserve[highest_zoneidx])
return false;
// 流程走到这里,对应内存分配阶 order = 0 的情况下就已经 OK 了,
// 剩余空闲内存在水位线之上,那么肯定能够分配一页出来
if (!order)
return true;
// 但是对于 high-order 的内存分配,这里还需要近一步检查伙伴系统,
// 根据伙伴系统内存分配的原理,这里需要检查高阶 free_list
// 中是否有足够的空闲内存块可供分配
for (o = order; o < MAX_ORDER; o++) {
// 从当前分配阶 order 对应的 free_area 中检查是否有足够的内存块
struct free_area *area = &z->free_area[o];
int mt;
// 如果当前 free_area 中的 nr_free = 0 表示对应 free_list
// 中没有合适的空闲内存块,那么继续到高阶 free_area 中查找
if (!area->nr_free)
continue;
// 检查 free_area 中UME 3种迁移类型 free_list 是否有足够的内存块
for (mt = 0; mt < MIGRATE_PCPTYPES; mt++) {
if (!free_area_empty(area, mt))
return true; //非空,代表有足够的内存块
}
/* 删除部分 */
// 如果设置了 ALLOC_HARDER,则表示可以从 HIGHATOMIC
// 区中的紧急预留内存中分配,检查对应 free_list
if (alloc_harder && !free_area_empty(area, MIGRATE_HIGHATOMIC))
return true;
}
return false;
}当内存分配策略 alloc_flags 设置了 ALLOC_HARDER 时,水位线的要求会降低原来的四分之一,相当于放宽了内存分配的限制。比原来更加努力使内存分配成功。
当内存分配策略 alloc_flags 设置了 ALLOC_HIGH 时,水位线的要求会降低原来的二分之一,相当于更近一步放宽了内存分配的限制。比原来更加激进些
2.4.2.2 rmqueue
快速分配:通过__rmqueue_smallest函数在指定的migratetype类型链表上进行扫描分配内存,成功则返回page
慢速分配:如果(1)分配失败,就调用__rmqueue_fallback尝试在其他类型的链表进行分配(注意:若指定分配类型是MIGRATE_MOVABLE,当进入慢分配流程时要先调用__rmqueue_smallest在MIGRATE_CMA类型列表上进行分配,成功返回;若再失败最后才调用__rmqueue_fallback函数进行分配).
/*
* Allocate a page from the given zone. Use pcplists for order-0 allocations.
*/
static inline
struct page *rmqueue(struct zone *preferred_zone,
struct zone *zone, unsigned int order,
gfp_t gfp_flags, unsigned int alloc_flags,
int migratetype)
{
unsigned long flags;
struct page *page;
/* 如果order == 0 意味着只申请一个page,那么优先从pcp中申请该page */
if (likely(order == 0)) {
/*
* MIGRATE_MOVABLE pcplist could have the pages on CMA area and
* we need to skip it when CMA area isn't allowed.
*/
if (!IS_ENABLED(CONFIG_CMA) || alloc_flags & ALLOC_CMA ||
migratetype != MIGRATE_MOVABLE) {
/* 在pcp中申请不详细研究,本文不分析pcp */
page = rmqueue_pcplist(preferred_zone, zone, gfp_flags,
migratetype, alloc_flags);
goto out;
}
}
/*
* We most definitely don't want callers attempting to
* allocate greater than order-1 page units with __GFP_NOFAIL.
*/
WARN_ON_ONCE((gfp_flags & __GFP_NOFAIL) && (order > 1));
spin_lock_irqsave(&zone->lock, flags);
do {
page = NULL;
/*
* order-0 request can reach here when the pcplist is skipped
* due to non-CMA allocation context. HIGHATOMIC area is
* reserved for high-order atomic allocation, so order-0
* request should skip it.
*/
if (order > 0 && alloc_flags & ALLOC_HARDER) {
/* 优先使用MIGRATE_HIGHATOMIC(实际=PCP)去申请看看 */
page = __rmqueue_smallest(zone, order, MIGRATE_HIGHATOMIC);
if (page)
trace_mm_page_alloc_zone_locked(page, order, migratetype);
}
if (!page)
page = __rmqueue(zone, order, migratetype, alloc_flags);
/* 如果PCP的没申请到,使用正常的migratetype,
该函数最后也是调用的__rmqueue_smallest
只不过在该函数中还涉及更多的申请路线*/
} while (page && check_new_pages(page, order));
/* 这里对找到的page flag进行检查(page->flags & __PG_HWPOISON) */
spin_unlock(&zone->lock);
if (!page)
goto failed;
/* 删除部分代码 */
out:
/* Separate test+clear to avoid unnecessary atomics */
/* 是否需要唤醒kswapd进行内存回收 函数__rmqueue的子函数会触发置位。
可以看出来,在快速路径会优先申请内存,
然后才根据情况唤醒kswapd执行内存回收 */
if (test_bit(ZONE_BOOSTED_WATERMARK, &zone->flags)) {
clear_bit(ZONE_BOOSTED_WATERMARK, &zone->flags);
wakeup_kswapd(zone, 0, 0, zone_idx(zone));
}
VM_BUG_ON_PAGE(page && bad_range(zone, page), page);
return page;
failed:
local_irq_restore(flags);
return NULL;
}
/*
* Do the hard work of removing an element from the buddy allocator.
* Call me with the zone->lock already held.
*/
static __always_inline struct page *
__rmqueue(struct zone *zone, unsigned int order, int migratetype,
unsigned int alloc_flags)
{
struct page *page;
/* 删除部分 CMA相关的 */
retry:
/*
*上面分配失败,那么就调用__rmqueue_fallback尝试从
其他类型的链表分配(MIGRATE_MOVABLE例外):
*(1)若指定的迁移类型是MIGRATE_MOVABLE,先调用 __rmqueue_smallest
直接快速在MIGRATE_CMA类型列表中去查找,成功直接返回,
失败则调用__rmqueue_fallback在慢速的进行内存块分配
*(2)根据static int fallbacks[MIRGRATE_TYPES][MIGRATE_TYPES-1]
这个fallback(退路)数据来顺序查找
*/
page = __rmqueue_smallest(zone, order, migratetype);
if (unlikely(!page)) {
if (alloc_flags & ALLOC_CMA)
page = __rmqueue_cma_fallback(zone, order);
if (!page && __rmqueue_fallback(zone, order, migratetype,
alloc_flags))
goto retry;
}
out:
if (page)
trace_mm_page_alloc_zone_locked(page, order, migratetype);
return page;
}__rmqueue_smallest
/*
* 遍历指定迁移类型的伙伴系统链表,从链表中移动最小数量的页面返回给调用者.
* 这是伙伴系统的快速处理流程.
*@zone: 在该管理区的伙伴系统中分配页面
*@order: 要分配的页面数量阶.
*@migratetype: 在该迁移类型的链表中获取页面
*/
static __always_inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order,
int migratetype)
{
unsigned int current_order;
struct free_area *area;
struct page *page;
/* Find a page of the appropriate size in the preferred list */
//从指定的阶到最大阶进行遍历,直到找到一个可以分配的链表
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
//找到该阶对应的空闲页面链表
area = &(zone->free_area[current_order]);
// 搜索该阶的空闲链中是否有指定迁移类型的空闲页块,
// 没有就搜索下一阶链表(page是链表的第一个元素)
page = get_page_from_free_area(area, migratetype);
if (!page)
continue;
/* 如果找到了,就从当前order的链表中删除一个元素 */
del_page_from_free_list(page, zone, current_order);
/* 如果cur_order已经大于最开始传入的order,
就是说明已经有一个更大的伙伴被拆分开了,
那么就在后续层级的所有order中增加一个free值 */
expand(zone, page, order, current_order, migratetype);
set_pcppage_migratetype(page, migratetype);
return page;
}
return NULL;
}__rmqueue_fallback
尝试从fallbacks备选迁移列表中搜索出一块大小为2^order个页的连续空闲页块,也就是说按照备选方案,U(UNMOVABLE) M(MOVABLE) E(RECLAIMABLE)之间是可以相互转换的
/*
* This array describes the order lists are fallen back to when
* the free lists for the desirable migrate type are depleted
*/
static int fallbacks[MIGRATE_TYPES][3] = {
//UNMOVEABLE的次选为可回收的和MOVABLE
[MIGRATE_UNMOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
//MOVABLE的次选为可回收的和UNMOVEABLE
[MIGRATE_MOVABLE] = { MIGRATE_RECLAIMABLE, MIGRATE_UNMOVABLE, MIGRATE_TYPES },
[MIGRATE_RECLAIMABLE] = { MIGRATE_UNMOVABLE, MIGRATE_MOVABLE, MIGRATE_TYPES },
#ifdef CONFIG_CMA
[MIGRATE_CMA] = { MIGRATE_TYPES }, /* Never used */
#endif
#ifdef CONFIG_MEMORY_ISOLATION
[MIGRATE_ISOLATE] = { MIGRATE_TYPES }, /* Never used */
#endif
};
static __always_inline bool
__rmqueue_fallback(struct zone *zone, int order, int start_migratetype,
unsigned int alloc_flags)
{
struct free_area *area;
int current_order;
int min_order = order;
struct page *page;
int fallback_mt;
bool can_steal;
/*
* Do not steal pages from freelists belonging to other pageblocks
* i.e. orders < pageblock_order. If there are no local zones free,
* the zonelists will be reiterated without ALLOC_NOFRAGMENT.
*/
if (alloc_flags & ALLOC_NOFRAGMENT)
min_order = pageblock_order;
/*
*从最高阶搜索,这样可以尽量的将其他迁移列表中的大块分割,避免形成过多的碎片
*/
for (current_order = MAX_ORDER - 1; current_order >= min_order;
--current_order) {
area = &(zone->free_area[current_order]);
/*
*在area内存区域中,遍历start_migratetype对应的备用数组,
看是否能在备选迁移类型的列表中找到一块满足要求的内存块
(阶大于等于current_order小于等于Max_ORDER-1)
*(1)函数返回-1表示未找到满足要求的内存块
*(2)*can_steal为True表示需要先把该函数找到的后补空闲内存块
先迁移到指定的迁移类型列表上去(避免碎片化)
*/
fallback_mt = find_suitable_fallback(area, current_order,
start_migratetype, false, &can_steal);
if (fallback_mt == -1)
continue;
/* 我们无法从页面块中窃取所有可用页面,并且请求的migrateype是可移动的。
在这种情况下,最好窃取并拆分最小的可用页面,而不是最大的可用页面。
因为即使下一个可移动分配落回与此不同的页面块,也不会导致永久碎片。*/
if (!can_steal && start_migratetype == MIGRATE_MOVABLE
&& current_order > order)
goto find_smallest;
goto do_steal;
}
return false;
find_smallest:
/* 使用当前小阶位在尝试找一下有没有可以作为退路的迁移类型 */
for (current_order = order; current_order < MAX_ORDER;
current_order++) {
area = &(zone->free_area[current_order]);
fallback_mt = find_suitable_fallback(area, current_order,
start_migratetype, false, &can_steal);
if (fallback_mt != -1)
break;
}
/*
* This should not happen - we already found a suitable fallback
* when looking for the largest page.
*/
VM_BUG_ON(current_order == MAX_ORDER);
do_steal:
page = get_page_from_free_area(area, fallback_mt);
steal_suitable_fallback(zone, page, alloc_flags, start_migratetype,
can_steal);
trace_mm_page_alloc_extfrag(page, order, current_order,
start_migratetype, fallback_mt);
return true;
}
/*
此功能实现实际的”盗窃”行为。如果订单足够大,我们可以偷走整个页面块。
如果没有,我们首先将该页面块中的空闲页面移动到我们的migrateype,
并确定在具有兼容migrateype的页面块中有多少已经分配的页面。
如果至少有一半的页面是free的或compatible(兼容)的,
我们可以更改页面块本身的migrateype,这样将来释放的页面将被放在正确的free_list中。 */
static void steal_suitable_fallback(struct zone *zone, struct page *page,
unsigned int alloc_flags, int start_type, bool whole_block)
{
unsigned int current_order = buddy_order(page);
int free_pages, movable_pages, alike_pages;
int old_block_type;
// 记录该page块当前的migrate type
old_block_type = get_pageblock_migratetype(page);
/*
* This can happen due to races and we want to prevent broken
* highatomic accounting.
*/
if (is_migrate_highatomic(old_block_type))
goto single_page;
/* Take ownership for orders >= pageblock_order */
//当要迁移的页被内核认定为大页,内核会将将超出的部分的迁移类型设为指定迁移类型
if (current_order >= pageblock_order) {
change_pageblock_range(page, current_order, start_type);
goto single_page;
}
/*
* 提高水印以增加回收压力,从而降低未来出现倒退的可能性。
* 现在唤醒kswapd,因为节点可能会整体平衡,kswapd不会自然唤醒。 */
if (boost_watermark(zone) && (alloc_flags & ALLOC_KSWAPD))
set_bit(ZONE_BOOSTED_WATERMARK, &zone->flags);
/* We are not allowed to try stealing from the whole block */
// 也就是传入的can_steal如果是1,就把整块都拿走(这样就避免了碎片化)
if (!whole_block)
goto single_page;
//按照新的迁移类型做页块迁移
free_pages = move_freepages_block(zone, page, start_type,
&movable_pages);
/*
* Determine how many pages are compatible with our allocation.
* For movable allocation, it's the number of movable pages which
* we just obtained. For other types it's a bit more tricky.
*/
if (start_type == MIGRATE_MOVABLE) {
alike_pages = movable_pages;
} else {
/*
* If we are falling back a RECLAIMABLE or UNMOVABLE allocation
* to MOVABLE pageblock, consider all non-movable pages as
* compatible. If it's UNMOVABLE falling back to RECLAIMABLE or
* vice versa, be conservative since we can't distinguish the
* exact migratetype of non-movable pages.
*/
if (old_block_type == MIGRATE_MOVABLE)
alike_pages = pageblock_nr_pages
- (free_pages + movable_pages);
else
alike_pages = 0;
}
/* moving whole block can fail due to zone boundary conditions */
if (!free_pages)
goto single_page;
/*
* If a sufficient number of pages in the block are either free or of
* comparable migratability as our allocation, claim the whole block.
*/
if (free_pages + alike_pages >= (1 << (pageblock_order-1)) ||
page_group_by_mobility_disabled)
//对整块的page设置迁移类型
set_pageblock_migratetype(page, start_type);
return;
single_page:
//将“偷”过来的对应order的页加入到对应的迁移类型中
move_to_free_list(page, zone, current_order, start_type);
}我们可以通过 cat /proc/pagetypeinfo 命令可以查看当前各个内存区域中的伙伴系统中不同页面迁移类型以及不同 order 尺寸的内存块个数

从这里也可以看出一个设备初始状态的内存大部分都是Movable,当某种迁移类型内存不足时,都是以内存块的方式,从Movable中“偷”出内存
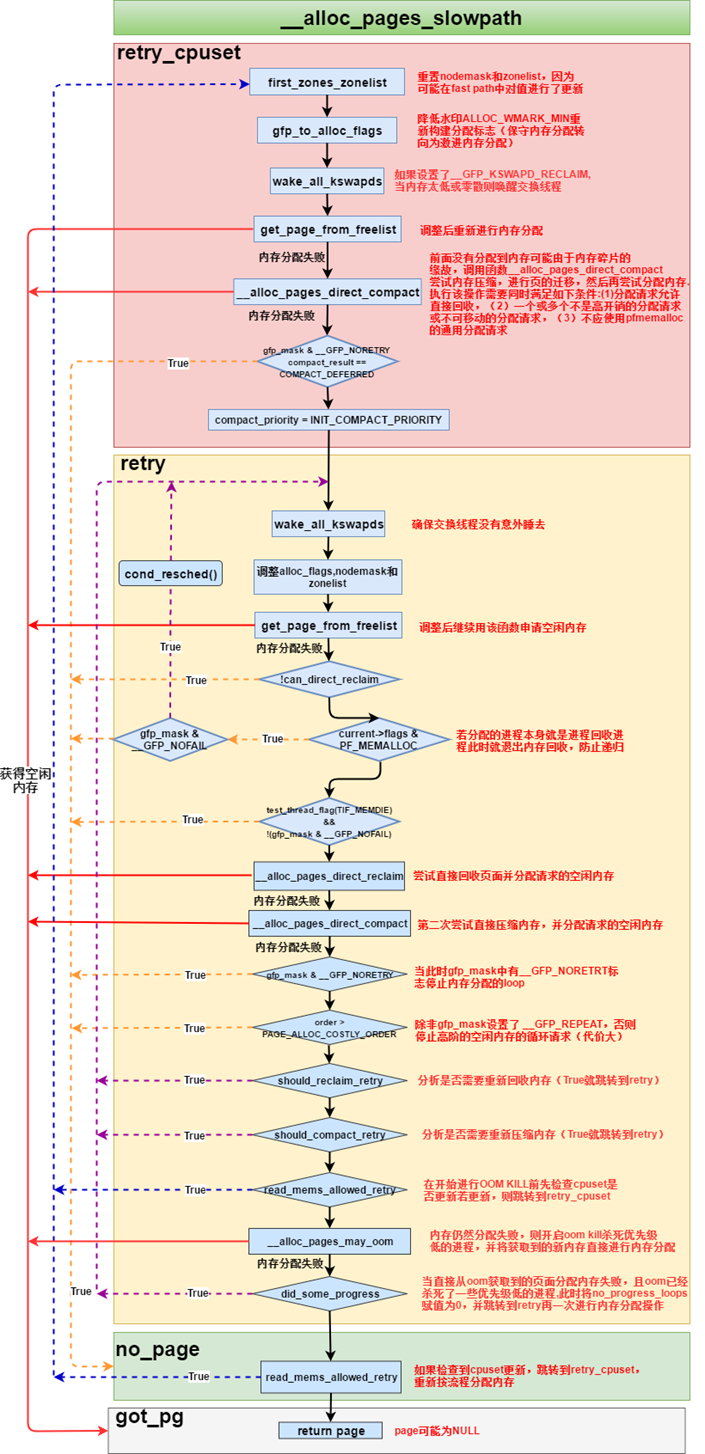
2.4.3 __alloc_pages_slowpath
__alloc_pages_slowpath()是用于慢速页面分配,允许等待,内存压缩和内存回收等.需要注意的是慢速分配仍然要调用到get_page_from_freelist函数来进行内存的获取,慢速分配的大致过程概况如下:
-
降低水印ALLOC_WMARK_MIN,如果设置了GFP_KSWAPD_RECLAIM就唤醒交换线程
-
调用get_page_from_freelist尝试重新分配
-
如果分配的页阶大于0尝试内存规整操作,通过内存迁移合并出较大的内存块,然后尝试内存分配
-
如果设置了GFP_KSWAPD_RECLAIM再次唤醒交换线程,确保交换线程不会意外睡去
-
直接进行内存回收之后尝试分配
-
如果内存回收没有分配到所需内存,就再次进行内存规整之后尝试分配内存
-
如果当前内存获取仍然失败就尝试杀死一些进程后再尝试分配内存
-
(内存获取还未成功)检查分配标志是否存在一些潜在可调的空间,然后再次调用get_page_from_freelist尝试份分配
-
最后若获取到需要的内存空间返回空闲内存,若系统尽了最大努力仍然无法提供需要的空闲内存则返回NULL
static inline struct page *
__alloc_pages_slowpath(gfp_t gfp_mask, unsigned int order,
struct alloc_context *ac)
{
bool can_direct_reclaim = gfp_mask & __GFP_DIRECT_RECLAIM;
const bool costly_order = order > PAGE_ALLOC_COSTLY_ORDER;
struct page *page = NULL;
unsigned int alloc_flags;
unsigned long did_some_progress;
enum compact_priority compact_priority;
enum compact_result compact_result;
int compaction_retries;
int no_progress_loops;
unsigned int cpuset_mems_cookie;
int reserve_flags;
/*
* We also sanity check to catch abuse of atomic reserves being used by
* callers that are not in atomic context.
*/
if (WARN_ON_ONCE((gfp_mask & (__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)) ==
(__GFP_ATOMIC|__GFP_DIRECT_RECLAIM)))
gfp_mask &= ~__GFP_ATOMIC;
retry_cpuset:
compaction_retries = 0;
no_progress_loops = 0;
compact_priority = DEF_COMPACT_PRIORITY;
cpuset_mems_cookie = read_mems_allowed_begin();
/*
* 快速路径下,内存申请是延后执行kswapd的,但是在慢速路径,
* 会先判断alloc_flag 是否需要执行内存回收,然后后面执行回收再申请page,
* 该函数中会对flag置位ALLOC_WMARK_MIN标志(保守内存分配转向为激进内存分配)
*/
alloc_flags = gfp_to_alloc_flags(gfp_mask);
/*
重置nodemask和zonelist,因为可能在fast path中对值进行了更新
*/
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->highest_zoneidx, ac->nodemask);
if (!ac->preferred_zoneref->zone)
goto nopage;
/* 基本内核里申请内存的标志都会有内存回收。
ALLOC_KSWAPD 的值和 __GFP_KSWAPD_RECLAIM相等 */
if (alloc_flags & ALLOC_KSWAPD)
wake_all_kswapds(order, gfp_mask, ac); /* 唤醒内核线程kswapd,后面分析 */
/*
调整后重新利用get_page_from_freelist在重新进行内存分配
*/
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
/*
*前面没有分配到内存可能由于内存碎片的缘故,
调用函数__alloc_pages_direct_compact,尝试内存规整操作,
进行页的迁移,然后再尝试分配执行该操作需要同时满足如下条件:
*(1)分配请求允许直接回收(gfp_mask & __GFP_DIRECT_RECLAI为真)
*(2)内存分配的阶要大于3(PAGE_ALLOC_COSTLY_ORDER):
因为低阶内存块受内存碎片化影响较小,内存规整不能解决问题。
或者order>0,移动类型是不可移动的
*(3)本次内存分配不能是无水线限制的内存分配,
函数gfp_pfmemalloc_allowed(gfp_mask)返回false
*/
if (can_direct_reclaim &&
(costly_order ||
(order > 0 && ac->migratetype != MIGRATE_MOVABLE))
&& !gfp_pfmemalloc_allowed(gfp_mask)) {
/* 这里有一套很复杂的页移动,压缩机制,先不具体分析 */
page = __alloc_pages_direct_compact(gfp_mask, order,
alloc_flags, ac,
INIT_COMPACT_PRIORITY,
&compact_result);
if (page)
goto got_pg;
if (costly_order && (gfp_mask & __GFP_NORETRY)) {
if (compact_result == COMPACT_SKIPPED ||
compact_result == COMPACT_DEFERRED)
goto nopage;
compact_priority = INIT_COMPACT_PRIORITY;
}
}
retry:
/* Ensure kswapd doesn't accidentally go to sleep as long as we loop
确保交换线程没有意外睡去 */
if (alloc_flags & ALLOC_KSWAPD)
wake_all_kswapds(order, gfp_mask, ac);
/* 对gfp_mask进行分析看是否可以不受水线限制进行内存分配 */
reserve_flags = __gfp_pfmemalloc_flags(gfp_mask);
if (reserve_flags)
alloc_flags = current_alloc_flags(gfp_mask, reserve_flags);
/*
* 如果可以忽略内存策略,则重置nodemask和zonelist。
* 这些分配是高优先级的,针对系统而不是针对用户。
*/
if (!(alloc_flags & ALLOC_CPUSET) || reserve_flags) {
ac->nodemask = NULL;
ac->preferred_zoneref = first_zones_zonelist(ac->zonelist,
ac->highest_zoneidx, ac->nodemask);
}
/* 尝试使用可能已调整的zonelist和alloc_flags 在进行快速页申请 */
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
if (page)
goto got_pg;
/* 如果调用者不愿意回收,我们无法平衡任何东西。那到这里就没办法申请了 */
if (!can_direct_reclaim)
goto nopage;
/* Avoid recursion of direct reclaim */
/* 如果当前进程不能使用紧急内存,内存回收很可能会失败,容易造成递归调用 */
if (current->flags & PF_MEMALLOC)
goto nopage;
/* 尝试直接回收,然后分配,主要是执行内存回收(先不具体分析),
然后执行get_page_from_freelist */
page = __alloc_pages_direct_reclaim(gfp_mask, order,
alloc_flags, ac, &did_some_progress);
if (page)
goto got_pg;
/* 尝试直接压缩(物理内存页的再排序,以合并多个空闲页成为更大的连续块),然后分配内存 */
page = __alloc_pages_direct_compact(gfp_mask, order, alloc_flags, ac,
compact_priority, &compact_result);
if (page)
goto got_pg;
/* Do not loop if specifically requested */
if (gfp_mask & __GFP_NORETRY)
goto nopage;
/* 除非gfp_mask设置了__GFP_REPEAT标志,否则退出高阶的空闲内存的循环申请(costly)*/
if (costly_order && !(gfp_mask & __GFP_RETRY_MAYFAIL))
goto nopage;
/* 检查回收重试是否继续进行。当我们连续 MAX_RECLAIM_RETRIES
次尝试回收仍然无法回收到页面,或者即使回收LRU列表上其余所有页面仍然无法满足水位线要求时,
我们会放弃。如果重试是可行的,返回true,否则返回false以进入OOM路径(内存用尽) */
if (should_reclaim_retry(gfp_mask, order, ac, alloc_flags,
did_some_progress > 0, &no_progress_loops))
goto retry;
/* 如果零阶回收无法取得任何进展,重试压缩是没有意义的,
因为当前的压缩实现取决于足够的空闲内存(请参见__compaction_suitable的实现)*/
if (did_some_progress > 0 &&
should_compact_retry(ac, order, alloc_flags,
compact_result, &compact_priority,
&compaction_retries))
goto retry;
/* 在我们开始进行OOM杀进程之前,处理可能存在的cpuset更新竞争情况。 */
if (check_retry_cpuset(cpuset_mems_cookie, ac))
goto retry_cpuset;
/* 内存压缩和回收都不行了,开始oom */
page = __alloc_pages_may_oom(gfp_mask, order, ac, &did_some_progress);
if (page)
goto got_pg;
/* 避免在没有任何水位的情况下进行无止境的分配,
意思是如果已经oom过了还没获取到有效大小的page,那就不搞了 */
if (tsk_is_oom_victim(current) &&
(alloc_flags & ALLOC_OOM ||
(gfp_mask & __GFP_NOMEMALLOC)))
goto nopage;
/* 当直接从oom获取到的页面分配内存失败,且oom已经杀死了一些优先级低的进程,
此时将no_progress_loops赋值为0,并跳转到retry再一次进行内存分配操作 */
if (did_some_progress) {
no_progress_loops = 0;
goto retry;
}
nopage:
/* Deal with possible cpuset update races before we fail */
if (check_retry_cpuset(cpuset_mems_cookie, ac))
goto retry_cpuset;
/* 删除部分 */
fail:
warn_alloc(gfp_mask, ac->nodemask,
"page allocation failure: order:%u", order);
got_pg:
return page;
}2.4.4 GFP的几种标志翻译(gpt)
2.4.4.1 关于回收相关的标志
#define __GFP_IO ((__force gfp_t)___GFP_IO)
#define __GFP_FS ((__force gfp_t)___GFP_FS)
#define __GFP_DIRECT_RECLAIM ((__force gfp_t)___GFP_DIRECT_RECLAIM) /* Caller can reclaim */
#define __GFP_KSWAPD_RECLAIM ((__force gfp_t)___GFP_KSWAPD_RECLAIM) /* kswapd can wake */
#define __GFP_RECLAIM ((__force gfp_t)(___GFP_DIRECT_RECLAIM|___GFP_KSWAPD_RECLAIM))
#define __GFP_RETRY_MAYFAIL ((__force gfp_t)___GFP_RETRY_MAYFAIL)
#define __GFP_NOFAIL ((__force gfp_t)___GFP_NOFAIL)
#define __GFP_NORETRY ((__force gfp_t)___GFP_NORETRY)__GFP_IO
%__GFP_IO标志表示在分配内存时可能会启动物理I/O操作,导致页面换入/换出。在使用%__GFP_IO标志进行内存分配时,可能会发生阻塞操作,因为内部算法可以通过调用页回写守护程序或者启动数据交换操作(swapping)来执行I/O操作。
__GFP_FS
%__GFP_FS标志表示分配的内存可能会用于文件系统(FS)层,可以调用到底层文件系统操作。使用%__GFP_FS标志来进行内存分配时,可能会出现阻塞的情况。如果我们需要对于文件系统进行操作,则需要使用%__GFP_FS标志。但是,因为这会导致内存分配器递归进入文件系统,而文件系统可能已经持有锁,因此在某些情况下,需要清除该标志,以避免此类递归调用。
__GFP_DIRECT_RECLAIM
%__GFP_DIRECT_RECLAIM标志表示调用者可能会进入直接回收(direct reclaim)的状态。进行内存分配时使用该标志,可能会导致阻塞,因为这会触发回收操作以释放更多的空闲内存。但是,如果我们已经有了备选项,则可以清除此标志,以避免不必要的延迟。这意味着如果可以从另一个位置获取可用的内存,则不需要进行回收操作。
__GFP_KSWAPD_RECLAIM
%__GFP_KSWAPD_RECLAIM标志表示当内存低水位标记(low watermark)被触及时,调用者希望唤醒kswapd并进行内存回收,直到高水位标记(high watermark)被触及为止。当需要进行内存回收操作时,使用该标志进行内存分配可能会导致系统阻塞。如果有备选项,则调用者可能希望清除此标志,以避免系统中断事件的发生。其中一个常见的例子是THP(Transparent Huge Pages)的分配,其中回退选项很便宜,但回收/整理会导致系统发生间接停顿。
__GFP_RECLAIM
%__GFP_RECLAIM标志是指同时允许/禁止直接回收(direct reclaim)和kswapd回收(kswapd reclaim),是这两个标志的简写。在进行内存分配时,使用它可以同时控制两个标志,有效地管理内存回收的行为。具体来说,如果我们想要在内存紧缩时通过kswapd回收内存并使用备选方案来避免直接回收,则可以使用该标志。
__GFP_NORETRY
%__GFP_NORETRY:分配器将仅尝试轻量级内存直接回收,以在内存有压力的情况下获得一些内存(因此可能会休眠)。但是它将避免像OOM killer这样的不必要行为。在重度内存压力下,调用者必须处理失败的情况,这种情况很有可能发生。当失败可以很容易地以小成本进行处理时,比如降低吞吐量时,可以使用该标志。
__GFP_RETRY_MAYFAIL
%__GFP_RETRY_MAYFAIL: 分配器将在先前失败的内存回收过程中重试,如果有一定迹象表明在其他地方已经取得了进展,则等待其他任务尝试释放内存的高级方法,例如收缩(移除碎片化)和页面回收。仍然存在确定性的重试次数限制,但是与%__GFP_NORETRY相比,限制更大。带有此标志的分配可能会失败,但只有可用内存是极少时才会失败。尽管这些分配不会直接触发OOM killer,但它们的失败表明系统很快可能需要使用OOM killer。调用者必须处理失败,但可以通过失败一个更高级别的请求或以更低效的方式完成来合理地处理失败。如果分配失败,并且调用者具备释放一些非必要内存的能力,那么这样做可能有利于整个系统。
__GFP_NOFAIL
%__GFP_NOFAIL表示分配器必须无限重试:调用程序无法处理分配失败。分配可能会无限期阻塞,永远不会返回失败状态。测试失败是毫无意义的。新用户应该经过仔细评估(并且只有在没有合理失败策略的情况下才使用该标志),但绝对比使用开放式无限循环分配器来说更可取。强烈不建议将此标志用于昂贵的分配。
2.4.4.2 一些常用的标志
#define GFP_ATOMIC (__GFP_HIGH|__GFP_ATOMIC|__GFP_KSWAPD_RECLAIM)
#define GFP_KERNEL (__GFP_RECLAIM | __GFP_IO | __GFP_FS)
#define GFP_NOWAIT (__GFP_KSWAPD_RECLAIM)
#define GFP_USER (__GFP_RECLAIM | __GFP_IO | __GFP_FS | __GFP_HARDWALL)GFP_ATOMIC
%GFP_ATOMIC用户不能睡眠,并需要分配成功。应用了较低的内存水印,以允许访问“原子保留”(atomic reserve)。但是当前实现不支持NMI和其他严格的不可抢占上下文(例如raw_spin_lock)。这同样适用于%GFP_NOWAIT。
GFP_KERNEL
内核级别的普通分配,只在进程的内核部分中使用,调用者要求%ZONE_NORMAL或更低的区域进行直接访问,可以进行直接回收(direct reclaim)
GFP_NOWAIT
%GFP_NOWAIT用于内核分配,不会因为直接回收(direct reclaim)而阻塞。即所分配的内存不会让系统进程睡眠和等待。
GFP_USER
%GFP_USER用于用户空间的分配,并需要内核或硬件直接访问,典型的是文件系统中超级块的申请。
2.4.5 图示
2.5 内存申请释放图示
2.5.1 伙伴系统内存申请
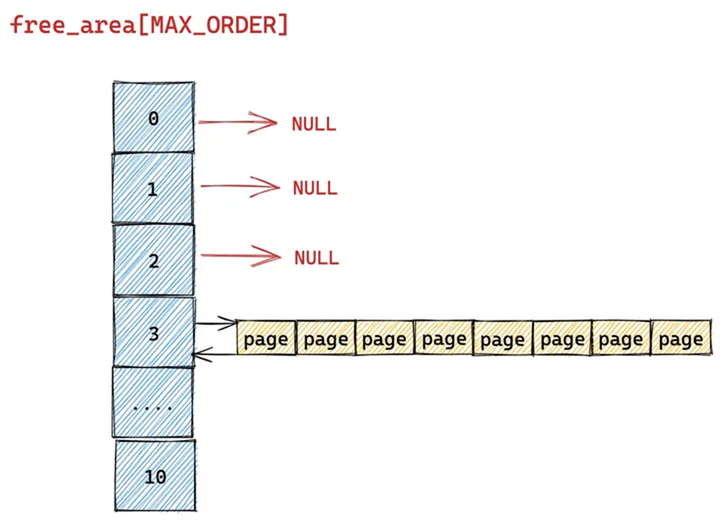
我们假设当前伙伴系统中只有 order = 3 的空闲链表 free_area[3],其余剩下的分配阶 order 对应的空闲链表中均是空的。 free_area[3] 中仅有一个空闲的内存块,其中包含了连续的 8 个 page。
现在我们向伙伴系统申请一个 page 大小的内存(对应的分配阶 order = 0),那么内核会在伙伴系统中首先查看 order = 0 对应的空闲链表 free_area[0] 中是否有空闲内存块可供分配。
随后内核会根据前边解析的内存分配逻辑,继续升级到 free_area[1] , free_area[2] 链表中寻找空闲内存块,直到查找到 free_area[3] 发现有一个可供分配的内存块。这个内存块中包含了 8 个 连续的空闲 page,但是我们只要一个 page 就够了,那该怎么办呢?
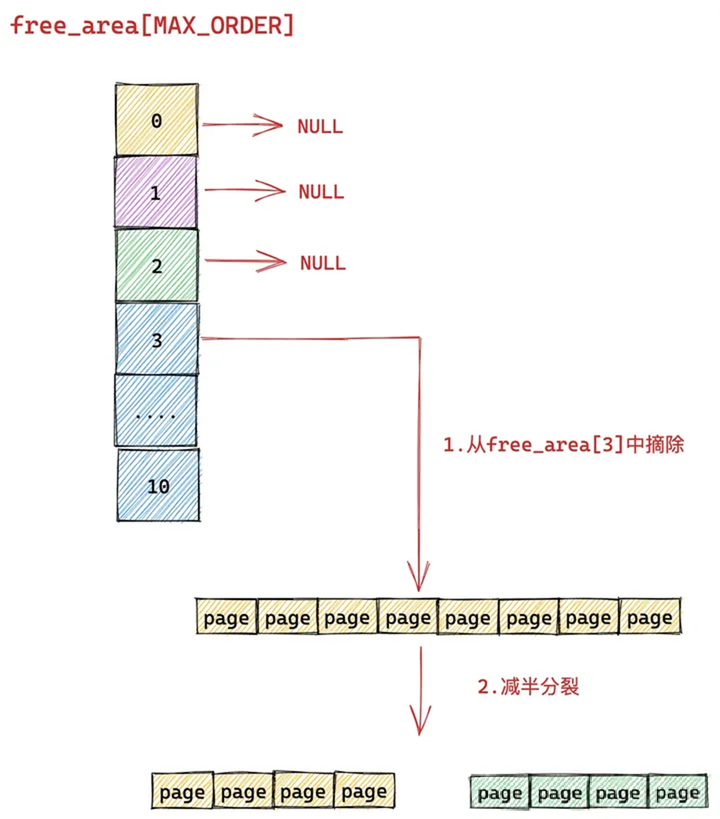
于是内核先将 free_area[3] 中的这个空闲内存块从链表中摘下,然后减半分裂成两个内存块,分裂出来的这两个内存块分别包含 4 个 page(分配阶 order = 2)。
随后内核会将分裂出的后半部分(图中绿色部分,order = 2),插入到 free_rea[2] 链表中。
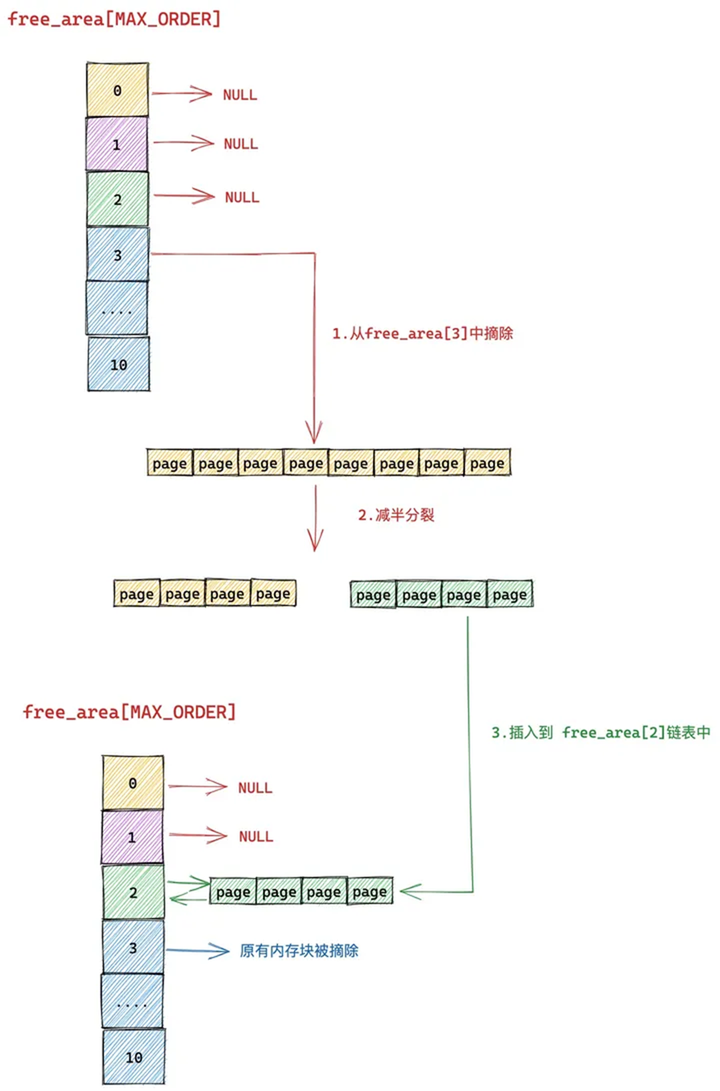
前半部分(图中黄色部分,order = 2)继续减半分裂,分裂出来的这两个内存块分别包含 2 个 page(分配阶 order = 1)。如下图中第 4 步所示,前半部分为黄色,后半部分为紫色。同理按照前边的分裂逻辑,内核会将后半部分内存块(紫色部分,分配阶 order = 1)插入到 free_area[1] 链表中。
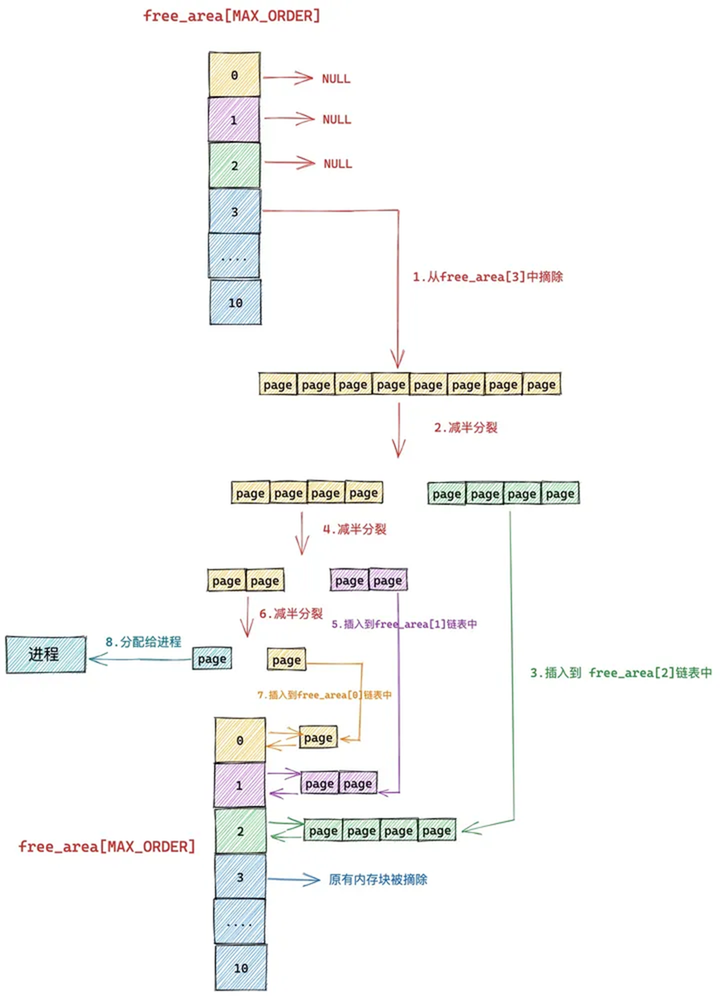
前半部分(图中黄色部分,order = 1)在上图中的第 6 步继续减半分裂,分裂出来的这两个内存块分别包含 1 个 page(分配阶 order = 0),前半部分为青色,后半部分为黄色。
后半部分插入到 frea_area[0] 链表中,前半部分返回给进程,这时内存分配成功,流程结束
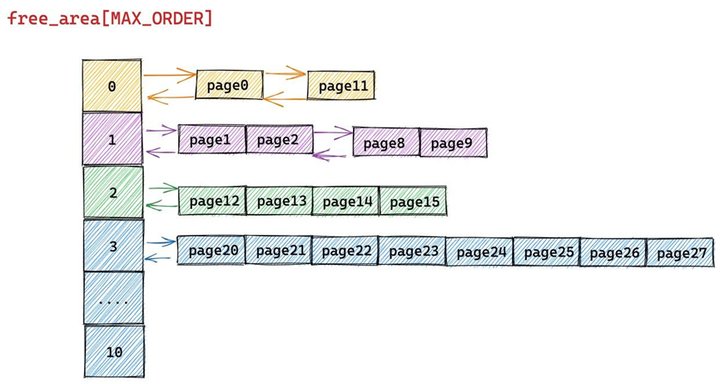
2.5.2 伙伴系统内存释放
伙伴系统中的内存回收刚好和内存分配的过程相反,核心则是从低阶 free_list 中寻找释放内存块的伙伴,如果没有伙伴则将要释放的内存块插入到对应分配阶 order 的 free_list中。如果存在伙伴,则将释放内存块与它的伙伴合并,作为一个新的内存块继续到更高阶的 free_list 中循环重复上述过程,直到不能合并为止。
下面是物理内存页在物理内存上的真实视图(page10将要被释放)
![]()
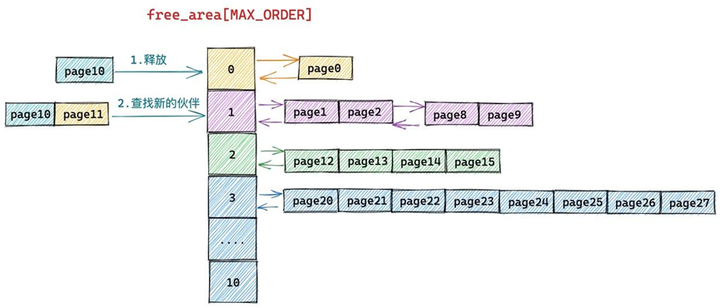
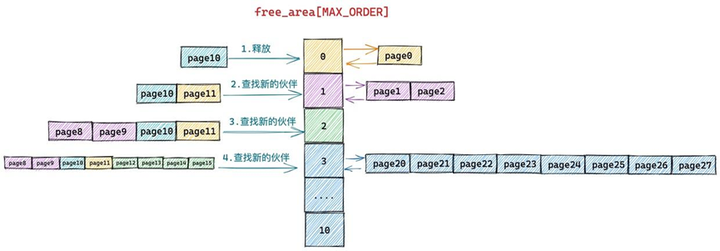
假设当前伙伴系统的状态如上图所示,现在我们需要向伙伴系统释放一个内存页(order = 0),编号为10。
由于我们要释放的内存块只包含了一个物理内存页 page10,所以它的分配阶 order = 0,首先内核需要在伙伴系统 free_area[0] 中查找与 page10 大小相等并且连续的内存块(伙伴)。
而page11 是 page10 (10^(1<0) = 11)的伙伴,于是将 page11 从 free_area[0] 上摘下并与 page10 合并组成一个新的内存块(分配阶 order = 1)。随后内核会在 free_area[1] 中查找新内存块的伙伴:
现在 free_area[1] 中 page8 和 page9 组成的内存块与 page10 和 page11 组成的内存块是伙伴(10^(1<1) = 8),于是继续将这两个内存块(分配阶 order = 1)继续合并成一个新的内存块(分配阶 order = 2)。随后内核会在 free_area[2] 中查找新内存块的伙伴:
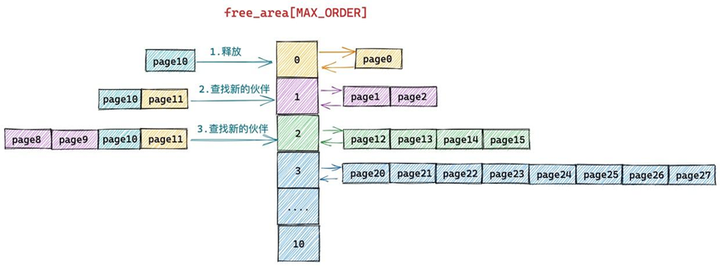
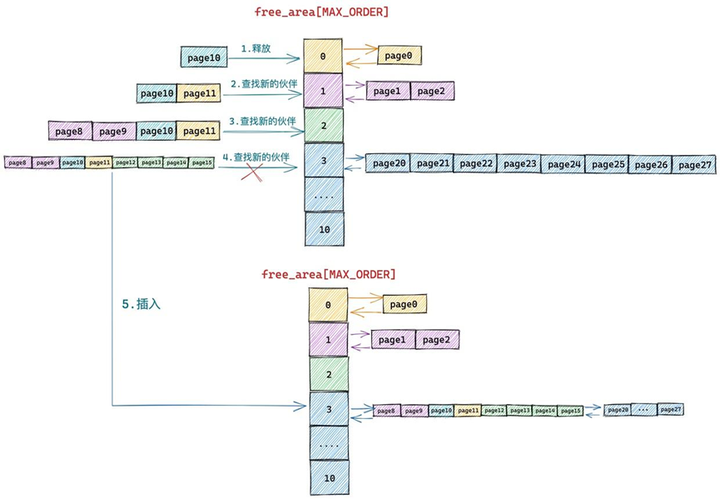
现在 free_area[2] 中 page12,page13,page14,page15 组成的内存块与 page8,page9,page10,page11 组成的新内存块是伙伴(8^(1<2)=12),于是将它们从 free_area[2] 上摘下继续合并成一个新的内存块(分配阶 order = 3),随后内核会在 free_area[3] 中查找新内存块的伙伴:
free_area[3] 中的内存块(page20 到 page 27)与新合并的内存块(page8 到 page15)虽然大小相同但是物理上并不连续,所以它们不是伙伴,不能在继续向上合并了。于是内核将 page8 到 pag15 组成的内存块(分配阶 order = 3)插入到 free_area[3] 中,至此内存释放过程结束。
3. 内存回收
3.1 内存回收的目标
对于内核并不是所有的物理内存都可以参与回收,比如内核的代码段,如果被内核回收了,系统就无法正常运行了,所以一般内核代码段、数据段、内核申请的内存、内核线程占用的内存等都是不可以回收的,除此之外的内存都可以是我们要回收的目标。
内核空间是所有进程公用的,内核中使用的页通常是伴随整个系统运行周期的,频繁的页换入和换出是非常影响性能的,所以内核中的页基本上不能回收,不是技术上实现不了而是这样做得不偿失。
同时,另外一种是应用程序主动申请锁定的页,它的实时性要求比较高,频繁的换入换出和缺页异常处理无法满足它对于时间上的要求,所以这部分程序可能使用mlock api将页主动锁定,不允许它进行回收。
那么我们就比较明确了,并非内存中的所有页面都是可以交换出去的。事实上,只有与用户空间建立了映射关系的物理页面才会被换出去,而内核空间中内核所占的页面则常驻内存。我们下面对用户空间中的页面和内核空间中的页面给出进一步的分类讨论。可以把用户空间中的页面按其内容和性质分为以下几种:
-
进程映像所占的页面,包括进程的代码段、数据段、堆栈段以及动态分配的“存储堆,进程的代码段和数据段所占用的内存页面是可以被换入换出的
-
通过系统调用mmap()把文件的内容映射到用户空间,这些页面所使用的交换区就是被映射的文件本身
-
进程间共享内存区
除此之外,内核在执行过程中使用的页面要经过动态分配,但永驻内存,此类页面根据其内容和性质可以分为两类:
-
内核调用kmalloc()或vmalloc()为内核中临时使用的数据结构而分配的页只要free可以立即释放。但是,由于一个页面中存放有多个同种类型的数据结构,所以要到整个页面都空闲时才把该页面释放。
-
内核中通过调用alloc_pages(),为某些临时使用和管理目的而分配的页面,例如,每个进程的内核栈所占的两个页面、从内核空间复制参数时所使用的页面等等。这些页面也是一旦使用完毕便无保存价值,所以立即释放。
在内核中还有一种页面,虽然使用完毕,但其内容仍有保存价值,因此,并不立即释放。这类页面“释放”之后进入一个LRU队列,经过一段时间的缓冲让其“老 化”。如果在此期间又要用到其内容了,就又将其投入使用,否则便继续让其老化,直到条件不再允许时才加以回收。这种用途的内核页面大致有以下这些:
-
文件系统中用来缓冲存储一些文件目录结构dentry的空间
-
文件系统中用来缓冲存储一些索引节点inode的空间
-
用于文件系统读/写操作的缓冲区
按照以上所述,对于内存回收,大致可以分为以下两类:
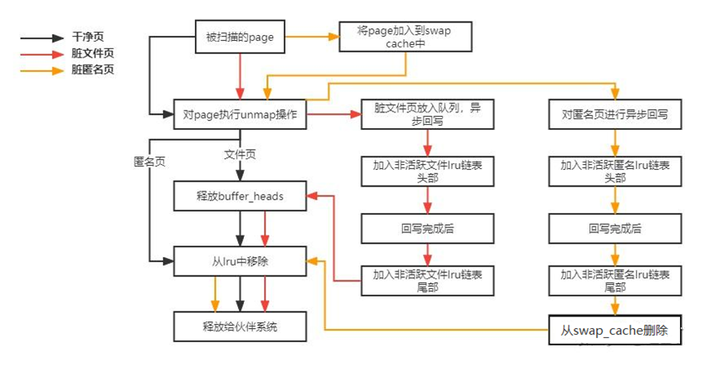
-
文件映射的页,包括page cache、slab中的dcache、icache、用户进程的可执行程序的代码段,文件映射页面。其中page cache包括文件系统的page,还包括块设备的buffer cache,万物皆文件,block也是一种文件,它也有关联的file、inode等。另外根据页是否是脏的,在回收的时候处理有所不同,脏页需要先回写到磁盘再回收,干净的页可以直接释放。
-
匿名页,括进程使用各种api(malloc,mmap,brk/sbrk)申请到的物理内存(这些api通常只是申请虚拟地址,真实的页分配发生在page fault中),包括堆、栈,进程间通信中的共享内存,pipe,bss段,数据段,tmpfs的页。这部分没有办法直接回写,为他们创建swap区域,这些页也转化成了文件映射的页,可以回写到磁盘。
3.2 内存回收机制
内核之所以要进行内存回收,主要原因有两个:
-
内核需要为任何时刻突发到来的内存申请提供足够的内存,以便cache的使用和其他相关内存的使用不至于让系统的剩余内存长期处于很少的状态。
-
内核使用内存中的page cache对部分文件进行缓存,以便提升文件的读写效率。所以内核有必要设计一个周期性回收内存的机制,以便cache的使用和其他相关内存的使用不至于让系统的剩余内存长期处于很少的状态。
当真的有大于空闲内存的申请到来的时候,会触发强制内存回收。我们只讨论针对zone的内存回收,对于内存回收讨论以下三种方式
-
快速内存回收: 处于get_page_from_freelist()函数中,在遍历zonelist过程中,对每个zone都在分配前进行判断,如果分配后zone的空闲内存数量 < 阀值 + 保留页框数量,那么此zone就会进行快速内存回收,即使分配前此zone空闲页框数量都没有达到阀值,都会进行此zone的快速内存回收。注意阀值可能是min/low/high的任何一种,因为在快速内存分配,慢速内存分配和oom分配过程中如果回收的页框足够,都会调用到get_page_from_freelist()函数,所以快速内存回收不仅仅发生在快速内存分配中,在慢速内存分配过程中也会发生。
-
直接内存回收: 处于慢速分配过程中,直接内存回收只有一种情况下会使用,在慢速分配中无法从zonelist的所有zone中以min阀值分配页框,并且进行异步内存压缩后,还是无法分配到页框的时候,就对zonelist中的所有zone进行一次直接内存回收。注意,直接内存回收是针对zonelist中的所有zone的,它并不像快速内存回收和kswapd内存回收,只会对zonelist中空闲页框不达标的zone进行内存回收。并且在直接内存回收中,有可能唤醒flush内核线程。
-
Kswapd(异步)内存回收: 发生在kswapd内核线程中,每个node有一个swapd内核线程,也就是kswapd内核线程中的内存回收,是只针对所在node的,并且只会对 分配了order页框数量后空闲页框数量 < 此zone的high阀值 + 保留页框数量 的zone进行内存回收,并不会对此node的所有zone进行内存回收。
3.2.1 水位线和min_free_kbytes
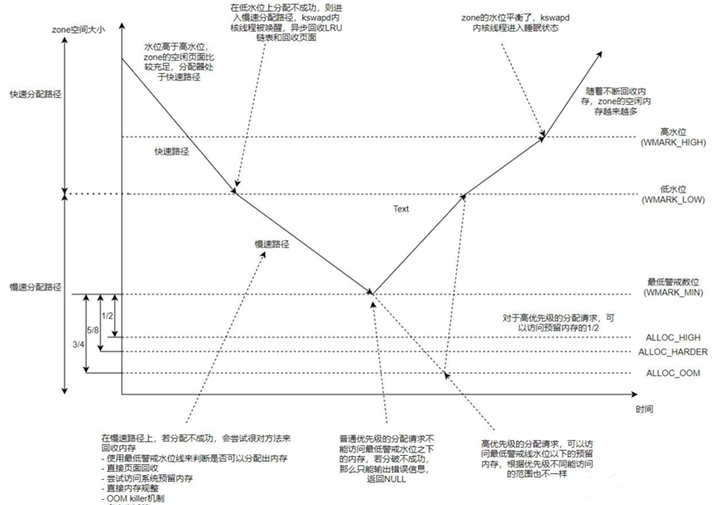
达到 low 水位的时候,kswapd 开始异步回收内存;达到 min 水位的时候,进程被堵住进行 direct reclamation 同步回收内存
水线关系图如下:
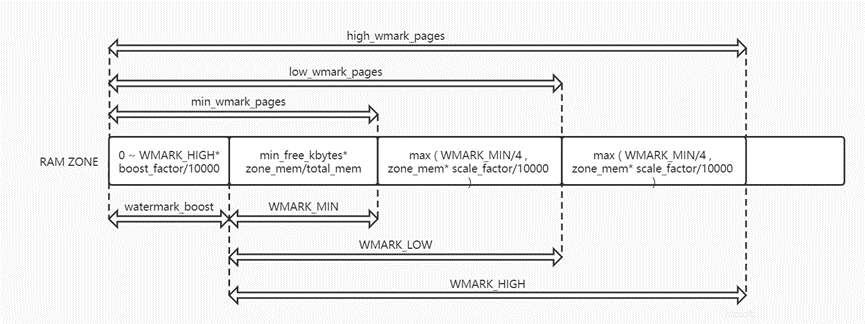
#define min_wmark_pages(z) (z->_watermark[WMARK_MIN] + z->watermark_boost)
#define low_wmark_pages(z) (z->_watermark[WMARK_LOW] + z->watermark_boost)
#define high_wmark_pages(z) (z->_watermark[WMARK_HIGH] + z->watermark_boost)
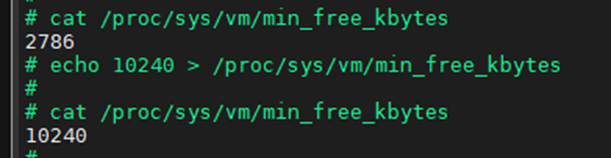
#define wmark_pages(z, i) (z->_watermark[i] + z->watermark_boost)因此以如下截图的实际水线值为:

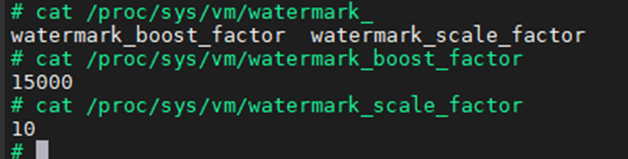
static inline bool boost_watermark(struct zone *zone)
{
unsigned long max_boost;
if (!watermark_boost_factor)
return false;
if ((pageblock_nr_pages * 4) > zone_managed_pages(zone))
return false;
//默认的 boost_factor=15000 故max_boost 是water[high] 的 1.5倍
max_boost = mult_frac(zone->_watermark[WMARK_HIGH],
watermark_boost_factor, 10000);
if (!max_boost)
return false;
#define MAX_ORDER 11
#define pageblock_order (MAX_ORDER-1) //10
#define pageblock_nr_pages (1UL << pageblock_order) //1024(单位page)
max_boost = max(pageblock_nr_pages, max_boost);
//取4M和max_boost的最小值
zone->watermark_boost = min(zone->watermark_boost + pageblock_nr_pages, max_boost);
return true;
}当然触发boost的必要条件是产生过内存碎片化。
其中关于min_free_kbytes有推荐值如下
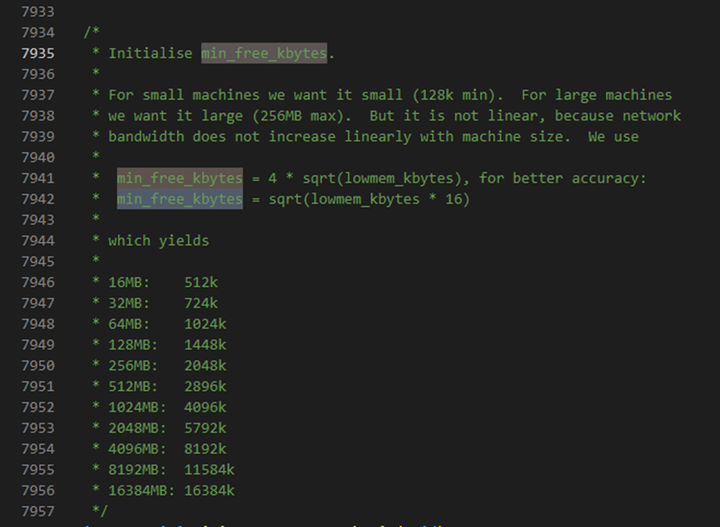
水位线的计算源码如下
static void __setup_per_zone_wmarks(void)
{
unsigned long pages_min = min_free_kbytes >> (PAGE_SHIFT - 10);
unsigned long lowmem_pages = 0;
struct zone *zone;
unsigned long flags;
/* Calculate total number of !ZONE_HIGHMEM pages */
for_each_zone(zone) {
if (!is_highmem(zone))
lowmem_pages += zone_managed_pages(zone);
}
for_each_zone(zone) {
u64 tmp;
spin_lock_irqsave(&zone->lock, flags);
tmp = (u64)pages_min * zone_managed_pages(zone);
do_div(tmp, lowmem_pages);
/* 删除部分 */
// 对于非NUMA而言就是min_free_kbytes >> 2
zone->_watermark[WMARK_MIN] = tmp;
/*
* Set the kswapd watermarks distance according to the
* scale factor in proportion to available memory, but
* ensure a minimum size on small systems.
*/
tmp = max_t(u64, tmp >> 2,
mult_frac(zone_managed_pages(zone),
watermark_scale_factor, 10000));
zone->watermark_boost = 0;
zone->_watermark[WMARK_LOW] = min_wmark_pages(zone) + tmp;
zone->_watermark[WMARK_HIGH] = min_wmark_pages(zone) + tmp * 2;
spin_unlock_irqrestore(&zone->lock, flags);
}
/* update totalreserve_pages */
calculate_totalreserve_pages();
}3.2.2 关键结构体
内存回收过程中有一个扫描控制结构体,用于控制这个回收过程。既然是回收内存,就需要明确要回收多少内存,在哪里回收,以及回收时的操作权限等,我们看下这个控制结构struct scan_control主要的一些变量
struct scan_control {
/* How many pages shrink_list() should reclaim */
unsigned long nr_to_reclaim; //shrink_list()需要回收的页面数量
/*
* Nodemask of nodes allowed by the caller. If NULL, all nodes
* are scanned.
*/
nodemask_t *nodemask; //指定可以在那个node回收内存
/*
* The memory cgroup that hit its limit and as a result is the
* primary target of this reclaim invocation.
*/
struct mem_cgroup *target_mem_cgroup; //是否针对某个cgroup扫描回收内存
/*
* Scan pressure balancing between anon and file LRUs
*/
unsigned long anon_cost;
unsigned long file_cost;
/* Can active pages be deactivated as part of reclaim? */
#define DEACTIVATE_ANON 1
#define DEACTIVATE_FILE 2
unsigned int may_deactivate:2;
unsigned int force_deactivate:1;
unsigned int skipped_deactivate:1;
/* Writepage batching in laptop mode; RECLAIM_WRITE */
unsigned int may_writepage:1; //是否可以回写
/* Can mapped pages be reclaimed? */
unsigned int may_unmap:1; //是否可以执行unmap
/* Can pages be swapped as part of reclaim? */
unsigned int may_swap:1; //是否可以将页面交换
/*
* Cgroup memory below memory.low is protected as long as we
* don't threaten to OOM. If any cgroup is reclaimed at
* reduced force or passed over entirely due to its memory.low
* setting (memcg_low_skipped), and nothing is reclaimed as a
* result, then go back for one more cycle that reclaims the protected
* memory (memcg_low_reclaim) to avert OOM.
*/
unsigned int memcg_low_reclaim:1;
unsigned int memcg_low_skipped:1;
unsigned int hibernation_mode:1;
/* One of the zones is ready for compaction */
unsigned int compaction_ready:1; //是否可以进行内存压缩,即碎片整理
/* There is easily reclaimable cold cache in the current node */
unsigned int cache_trim_mode:1;
/* The file pages on the current node are dangerously low */
unsigned int file_is_tiny:1;
/* Allocation order */
s8 order; //进程内存分配页面数量,从分配器传递过来的参数
/* Scan (total_size >> priority) pages at once */
s8 priority; //控制每次扫描数量,默认是总页数的1/4096
/* The highest zone to isolate pages for reclaim from */
s8 reclaim_idx; //进行页面回收的最大zone id
/* This context's GFP mask */
gfp_t gfp_mask; //分配掩码
/* Incremented by the number of inactive pages that were scanned */
unsigned long nr_scanned; //已扫描的非活动页面数量
/* Number of pages freed so far during a call to shrink_zones() */
unsigned long nr_reclaimed; //shrink_zones()中已回收页面数量
struct {
unsigned int dirty;
unsigned int unqueued_dirty;
unsigned int congested;
unsigned int writeback;
unsigned int immediate;
unsigned int file_taken;
unsigned int taken;
} nr;
/* for recording the reclaimed slab by now */
struct reclaim_state reclaim_state;
};3.2.3 快速内存回收
快速回收的函数执行主体为:node_reclaim,该函数在非CONFIG_NUMA架构下不生效。zone_watermark_fast判断如果此次快速内存申请已经触及到水位线时,可以执行node_reclaim-> __node_reclaim
快速内存回收,指定每轮进行回收的页面最大值为取需要回收的页面数和32的最大值,快速回收不能进行unmap,writeback操作,回收priority为4,即最多尝试调用shrink_node进行回收的次数为priority值,直到回收到的页数达到需要分配的内存页数或者完成4次循环为止,也就是最多能够回收128页
/*
* Try to free up some pages from this node through reclaim.
*/
static int __node_reclaim(struct pglist_data *pgdat, gfp_t gfp_mask, unsigned int order)
{
/* Minimum pages needed in order to stay on node */
const unsigned long nr_pages = 1 << order; //需要释放的页数
struct task_struct *p = current;
unsigned int noreclaim_flag;
#define node_reclaim_mode 0
struct scan_control sc = { //内存回收的条件
.nr_to_reclaim = max(nr_pages, SWAP_CLUSTER_MAX), //最大回收32页
.gfp_mask = current_gfp_context(gfp_mask),
.order = order,
.priority = NODE_RECLAIM_PRIORITY, //优先级为4
.may_writepage = !!(node_reclaim_mode & RECLAIM_WRITE),
.may_unmap = !!(node_reclaim_mode & RECLAIM_UNMAP),
.may_swap = 1,
.reclaim_idx = gfp_zone(gfp_mask),
};
/* 删除部分代码 */
if (node_pagecache_reclaimable(pgdat) > pgdat->min_unmapped_pages) {
/*
* Free memory by calling shrink node with increasing
* priorities until we have enough memory freed.
*/
do {
shrink_node(pgdat, &sc); //内存回收的核心函数,后面重点分析
} while (sc.nr_reclaimed < nr_pages && --sc.priority >= 0);
// 最多执行4次或者释放的页数已经满足条件
}
/* 删除部分代码 */
return sc.nr_reclaimed >= nr_pages;
}3.2.4 直接内存回收
函数入口为__alloc_pages_direct_reclaim,函数位于mm/page_alloc.c文件中
/* The really slow allocator path where we enter direct reclaim */
static inline struct page *
__alloc_pages_direct_reclaim(gfp_t gfp_mask, unsigned int order,
unsigned int alloc_flags, const struct alloc_context *ac,
unsigned long *did_some_progress)
{
struct page *page = NULL;
bool drained = false;
//直接同步页面回收的执行主体
// __perform_reclaim ->
// try_to_free_pages(回收最大32页) ->
// do_try_to_free_pages
*did_some_progress = __perform_reclaim(gfp_mask, order, ac);
if (unlikely(!(*did_some_progress)))
return NULL;
retry:
// 内存快速分配
page = get_page_from_freelist(gfp_mask, order, alloc_flags, ac);
/*
* 如果在直接回收之后分配失败,可能是因为页面固定在每个
* cpu列表上或处于高分配预留中
* Shrink them and try again
*/
if (!page && !drained) {
unreserve_highatomic_pageblock(ac, false);
// 释放固定在每个cpu列表上页面,这里最终调用flush_work即进行脏页的回写,
// 当IO性能不是很好的时候会造成系统严重卡顿
drain_all_pages(NULL);
drained = true;
goto retry;
}
return page;
}
/*
这是一个直接页面回收的主入口点。如果非活动页面链表的完整扫描无法释放足够的内存,
则表示“内存不足”,则需要杀死某些进程以释放内存。
如果调用者是! __GFP_FS,则失败的概率相当高-
区域可能充满了脏页面或正在写回的页面,而此调用方无能为力。
我们唤醒写回线程并明确地休眠,希望一些这些页面可以写入。
但是,如果分配任务持有防止写出的文件系统锁,则可能无法工作,分配尝试将失败。
返回值:如果没有回收页面,则为0,否则为回收的页面数。
*/
static unsigned long do_try_to_free_pages(struct zonelist *zonelist,
struct scan_control *sc)
{
int initial_priority = sc->priority;
pg_data_t *last_pgdat;
struct zoneref *z;
struct zone *zone;
retry:
/* 删除部分 */
do {
/* 删除部分 */
sc->nr_scanned = 0;
shrink_zones(zonelist, sc); //直接回收的核心,最终调用shrink_node
//回收到了需要的page数
if (sc->nr_reclaimed >= sc->nr_to_reclaim)
break;
//这个标志意味着一个可压缩的内存区域已经被识别出来了,
//可以先执行内存压缩
if (sc->compaction_ready)
break;
/*
* If we're getting trouble reclaiming, start doing
* writepage even in laptop mode.
*/
//回收过程中遇到了麻烦,则需要回写。
if (sc->priority < DEF_PRIORITY - 2)
sc->may_writepage = 1;
} while (--sc->priority >= 0);
/* 删除部分 */
if (sc->nr_reclaimed) //回收到了的page数
return sc->nr_reclaimed;
/* Aborted reclaim to try compaction? don't OOM, then */
if (sc->compaction_ready)
return 1;
/* 删除部分 */
return 0;
}3.2.5 kswapd
为了避免总在CPU忙碌时也就是缺页异常发生时,临时再来搜寻空页面换出的页面进行换出,内核将定期检查并预先将若干页面换出以腾出空间,维持系统空闲内存的的保有量,以减轻系统在缺页异常发生时的负担。为此内核设置了一个专司页面换出的守护神kswapd进程。
kswapd内核线程初始化时会为系统每个NUMA内存节点创建一个名为“kswapd%d”的内核线程,kswapd进程创建的代码如下:mm\vmscan.c
static int __init kswapd_init(void)
{
int nid;
// swap_setup函数根据物理内存大小设定全局变量page_cluster,
// 当megs小于16时候,page_cluster为2,否则为3
swap_setup();
for_each_node_state(nid, N_MEMORY)
kswapd_run(nid);
return 0;
}
void __init swap_setup(void)
{
unsigned long megs = totalram_pages() >> (20 - PAGE_SHIFT);
/* Use a smaller cluster for small-memory machines */
// page_cluster为每次swap in或者swap out操作多少内存页 为2的指数,
// 通过/proc/sys/vm/page-cluster 查看
if (megs < 16)
page_cluster = 2;
else
page_cluster = 3;
/*
* Right now other parts of the system means that we
* _really_ don't want to cluster much more
*/
}/*
* The background pageout daemon, started as a kernel thread
* from the init process.
*
* This basically trickles out pages so that we have _some_
* free memory available even if there is no other activity
* that frees anything up. This is needed for things like routing
* etc, where we otherwise might have all activity going on in
* asynchronous contexts that cannot page things out.
*
* If there are applications that are active memory-allocators
* (most normal use), this basically shouldn't matter.
*/
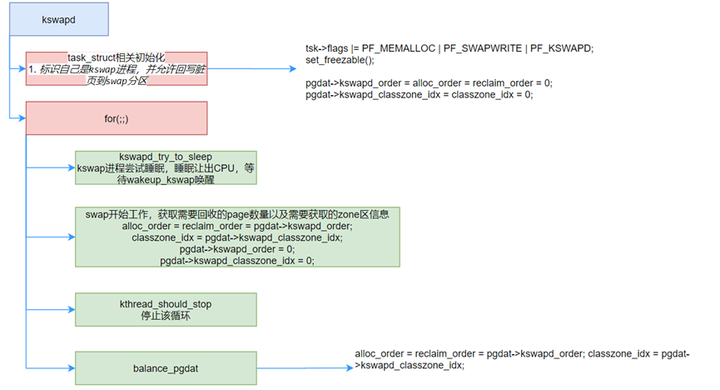
static int kswapd(void *p)
{
unsigned int alloc_order, reclaim_order;
unsigned int highest_zoneidx = MAX_NR_ZONES - 1;
pg_data_t *pgdat = (pg_data_t*)p;
struct task_struct *tsk = current;
const struct cpumask *cpumask = cpumask_of_node(pgdat->node_id);
if (!cpumask_empty(cpumask))
set_cpus_allowed_ptr(tsk, cpumask);
/*
告诉内存管理我们是一个“内存分配器”,并且如果我们需要更多内存,
我们应该无论如何都能够访问它(请参阅“__alloc_pages()”)。
“kswapd”不应该被正常的页面释放逻辑所捕获。
(Kswapd通常不需要内存,但有时您需要一小部分内存,以便能够分页出其他内容,
并且这个标志本质上可以保护我们免受在尝试释放第一个内存块时递归地尝试释放
更多内存的限制的影响)。 */
//标识自己是kswap进程,并允许回写脏页到swap分区
tsk->flags |= PF_MEMALLOC | PF_SWAPWRITE | PF_KSWAPD;
set_freezable();
WRITE_ONCE(pgdat->kswapd_order, 0);
WRITE_ONCE(pgdat->kswapd_highest_zoneidx, MAX_NR_ZONES);
for ( ; ; ) {
bool ret;
alloc_order = reclaim_order = READ_ONCE(pgdat->kswapd_order);
highest_zoneidx = kswapd_highest_zoneidx(pgdat,
highest_zoneidx);
kswapd_try_sleep: // kswap进程尝试睡眠
kswapd_try_to_sleep(pgdat, alloc_order, reclaim_order,
highest_zoneidx);
// 核心处理1,实质就是判断各个zone是否为balanced,
// 是否balanced即判断zone内可申请的mem数量是否在watermark[high] 之上;
/* Read the new order and highest_zoneidx */
alloc_order = reclaim_order = READ_ONCE(pgdat->kswapd_order);
highest_zoneidx = kswapd_highest_zoneidx(pgdat,
highest_zoneidx);
WRITE_ONCE(pgdat->kswapd_order, 0);
WRITE_ONCE(pgdat->kswapd_highest_zoneidx, MAX_NR_ZONES);
ret = try_to_freeze();//判断下当前是否是休眠操作
//是否有人调用thread_stop,正常情况下就是在module_exit时候调用;
if (kthread_should_stop())
break;
/*
* We can speed up thawing tasks if we don't call balance_pgdat
* after returning from the refrigerator
*/
if (ret) //如果是suspend状态的话,就啥也不干,继续循环
continue;
/* 重新获取从请求的阶数开始,但如果高阶重新获取失败,
则kswapd会回退到为阶数0重新获取。如果发生这种情况,
kswapd将考虑在完成重新获取时(重新获取顺序)睡眠,
但会唤醒kcompactd来紧缩原始请求(分配顺序)的空间。 */
trace_mm_vmscan_kswapd_wake(pgdat->node_id, highest_zoneidx,
alloc_order);
核心处理2,进行实质回收操作
reclaim_order = balance_pgdat(pgdat, alloc_order,
highest_zoneidx);
if (reclaim_order < alloc_order) //回收数量不够,则再来一次;
goto kswapd_try_sleep;
}
tsk->flags &= ~(PF_MEMALLOC | PF_SWAPWRITE | PF_KSWAPD);
return 0;
}这个主循环实际上干了两件事:
-
判断当前是否可以sleep,如果可以就让出了CPU(kswapd_try_to_sleep);
-
被唤醒后调用balance_pgdat 进行mem 回收操作;
3.2.5.1 kswapd_try_to_sleep
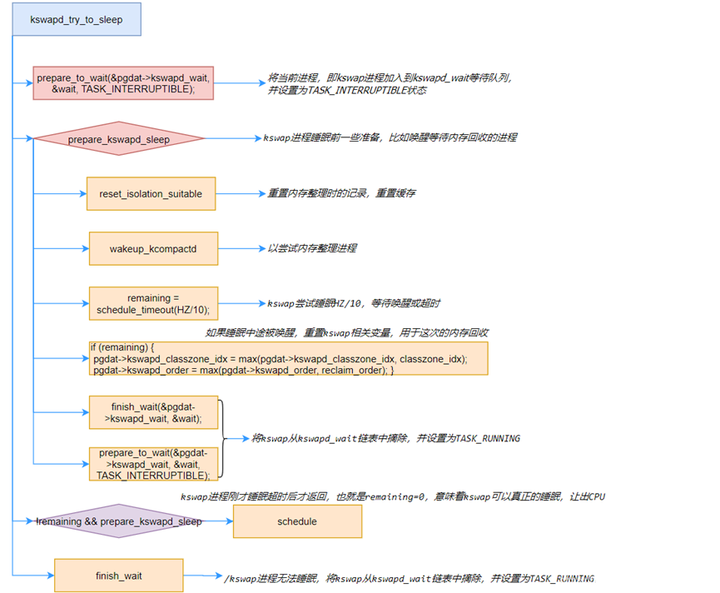
static void kswapd_try_to_sleep(pg_data_t *pgdat, int alloc_order,
int reclaim_order, unsigned int highest_zoneidx)
{
long remaining = 0;
DEFINE_WAIT(wait);
//如果需要退出,则直接返回
if (freezing(current) || kthread_should_stop())
return;
// wait加入kswap_wait queue中,即等待被唤醒,注意此时没有让出CPU
prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE);
// 核心处理1:执行 pgdat_balanced(实际就是判断水位是否达到high)
// 判断是否各个zone都是balanced
if (prepare_kswapd_sleep(pgdat, reclaim_order, highest_zoneidx)) {
// 能平衡了
/* 删除部分 */
//唤醒compact线程处理,这个是压缩内存
wakeup_kcompactd(pgdat, alloc_order, highest_zoneidx);
remaining = schedule_timeout(HZ/10); //sleep 100ms
/* 如果被提前唤醒,则重置kswapd_highest_zoneidx和order。
这些值将来自唤醒请求或先前因为提前唤醒而休眠的请求 */
if (remaining) {//remaining > 0说明被唤醒而非100ms结束
WRITE_ONCE(pgdat->kswapd_highest_zoneidx,
kswapd_highest_zoneidx(pgdat,
highest_zoneidx));
if (READ_ONCE(pgdat->kswapd_order) < reclaim_order)
WRITE_ONCE(pgdat->kswapd_order, reclaim_order);
}
//将wait从kswapd_wait queue中移除,并将当前状态配置为running
finish_wait(&pgdat->kswapd_wait, &wait);
//将wait在加入kswapd wait queue,确保queue中只有一个等待事件;
prepare_to_wait(&pgdat->kswapd_wait, &wait, TASK_INTERRUPTIBLE);
}
//到这里确实没有被唤醒的话
if (!remaining &&
prepare_kswapd_sleep(pgdat, reclaim_order, highest_zoneidx)) {
/* 删除部分 */
//没有需要退出thread,则真正的进入睡眠,主动调用schedule调度
if (!kthread_should_stop())
schedule();
/* 删除部分 */
}
/* 删除部分 */
finish_wait(&pgdat->kswapd_wait, &wait); //唤醒
}其主要的流程为:
-
定义一个wait在kswapd_wait上等待,设置进程状态为TASK_INTERRUPTIBLE,通过prepare_kswapd_sleep判断kswapd是否准好睡眠
-
可以尝试睡眠HZ/10,若返回不为0,则说明没有HZ/10内没有被唤醒了,HZ一般定义为1000,则是100ms
-
如果中途没有被唤醒,说明kswap可以睡眠,让出CPU,schedule出去如果中途被唤醒则返回上层函数,执行内存回收
3.2.5.2 balance_pgdat
从该函数的注释可以看出kswapd按高端内存->标准内存->DMA方向进行扫描,其次平衡的标准为free_pages > high_wmark_pages。
/*
* For kswapd, balance_pgdat() will reclaim pages across a node from zones
* that are eligible for use by the caller until at least one zone is
* balanced.
*
* Returns the order kswapd finished reclaiming at.
*
* kswapd scans the zones in the highmem->normal->dma direction. It skips
* zones which have free_pages > high_wmark_pages(zone), but once a zone is
* found to have free_pages <= high_wmark_pages(zone), any page in that zone
* or lower is eligible for reclaim until at least one usable zone is
* balanced.
*/
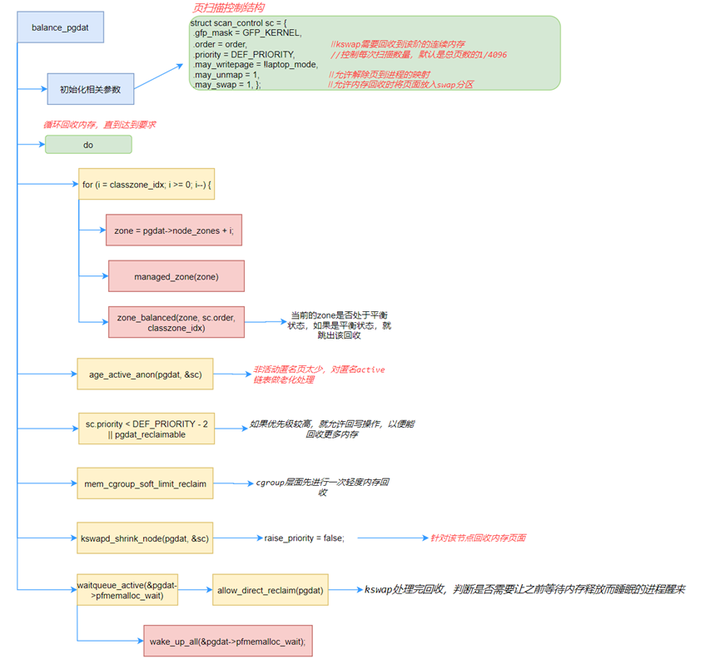
static int balance_pgdat(pg_data_t *pgdat, int order, int highest_zoneidx)
{
int i;
unsigned long nr_soft_reclaimed;
unsigned long nr_soft_scanned;
unsigned long pflags;
unsigned long nr_boost_reclaim;
unsigned long zone_boosts[MAX_NR_ZONES] = { 0, };
bool boosted;
struct zone *zone;
struct scan_control sc = {
.gfp_mask = GFP_KERNEL,
.order = order,
.may_unmap = 1,
};
/* 删除部分 */
nr_boost_reclaim = 0;
for (i = 0; i <= highest_zoneidx; i++) {
zone = pgdat->node_zones + i;
if (!managed_zone(zone))
continue;
nr_boost_reclaim += zone->watermark_boost;
zone_boosts[i] = zone->watermark_boost; //记录该zone被抬升的水位
}
boosted = nr_boost_reclaim; //水位是否有被抬升
#define DEF_PRIORITY 12
restart:
sc.priority = DEF_PRIORITY;
do {
unsigned long nr_reclaimed = sc.nr_reclaimed;
bool raise_priority = true;
bool balanced;
bool ret;
sc.reclaim_idx = highest_zoneidx;
if (buffer_heads_over_limit) {
//如果 buffer_heads 超过限制,尝试释放buffer_heads 的 page
for (i = MAX_NR_ZONES - 1; i >= 0; i--) {
zone = pgdat->node_zones + i;
if (!managed_zone(zone))
continue;
sc.reclaim_idx = i;
break;
}
}
// 如果当前order处于不平衡的状态,就忽略水线抬高,并重新开始
balanced = pgdat_balanced(pgdat, sc.order, highest_zoneidx);
if (!balanced && nr_boost_reclaim) {
nr_boost_reclaim = 0;
goto restart;
}
// 如果是平衡状态并且非水线太高,直接out
if (!nr_boost_reclaim && balanced)
goto out;
/* Limit the priority of boosting to avoid reclaim writeback */
if (nr_boost_reclaim && sc.priority == DEF_PRIORITY - 2)
raise_priority = false;
// 对于水线抬升的回收,不写回,也不swap
sc.may_writepage = !laptop_mode && !nr_boost_reclaim;
sc.may_swap = !nr_boost_reclaim;
//走到这里说明将各个zone都判断过之后,回收内存仍不够用,所以对anon 进行老化处理
age_active_anon(pgdat, &sc);
/*
* If we're getting trouble reclaiming, start doing writepage
* even in laptop mode.
*/
//优先级小于10还没有搞到足够内存的时候,需要打开writepage
if (sc.priority < DEF_PRIORITY - 2)
sc.may_writepage = 1;
/* Call soft limit reclaim before calling shrink_node. */
sc.nr_scanned = 0;
nr_soft_scanned = 0;
nr_soft_reclaimed = mem_cgroup_soft_limit_reclaim(pgdat, sc.order, sc.gfp_mask, &nr_soft_scanned);
sc.nr_reclaimed += nr_soft_reclaimed;
/*
* There should be no need to raise the scanning priority if
* enough pages are already being scanned that that high
* watermark would be met at 100% efficiency.
*/
// 进行shrink_node回收
if (kswapd_shrink_node(pgdat, &sc))
raise_priority = false;
/*
* If the low watermark is met there is no need for processes
* to be throttled on pfmemalloc_wait as they should not be
* able to safely make forward progress. Wake them
*/
if (waitqueue_active(&pgdat->pfmemalloc_wait) &&
allow_direct_reclaim(pgdat))
wake_up_all(&pgdat->pfmemalloc_wait);
/* Check if kswapd should be suspending */
__fs_reclaim_release();
ret = try_to_freeze();
__fs_reclaim_acquire();
//suspend或者退出的话,这里直接跳出去;
if (ret || kthread_should_stop())
break;
/*
* Raise priority if scanning rate is too low or there was no
* progress in reclaiming pages
*/
nr_reclaimed = sc.nr_reclaimed - nr_reclaimed;
nr_boost_reclaim -= min(nr_boost_reclaim, nr_reclaimed);
/*
* If reclaim made no progress for a boost, stop reclaim as
* IO cannot be queued and it could be an infinite loop in
* extreme circumstances.
*/
if (nr_boost_reclaim && !nr_reclaimed)
break;
if (raise_priority || !nr_reclaimed)
sc.priority--; //没回收够,则priority--
} while (sc.priority >= 1);
if (!sc.nr_reclaimed) //没回收完,失败次数++
pgdat->kswapd_failures++;
out:
/* If reclaim was boosted, account for the reclaim done in this pass */
if (boosted) {
unsigned long flags;
for (i = 0; i <= highest_zoneidx; i++) {
if (!zone_boosts[i])
continue;
/* Increments are under the zone lock */
zone = pgdat->node_zones + i;
spin_lock_irqsave(&zone->lock, flags);
//如果是被抬升过的,需要计算重新计算抬升水线,减回去
zone->watermark_boost -= min(zone->watermark_boost, zone_boosts[i]);
spin_unlock_irqrestore(&zone->lock, flags);
}
/*
* As there is now likely space, wakeup kcompact to defragment
* pageblocks.
*/
wakeup_kcompactd(pgdat, pageblock_order, highest_zoneidx);
}
snapshot_refaults(NULL, pgdat);
__fs_reclaim_release();
psi_memstall_leave(&pflags);
set_task_reclaim_state(current, NULL);
/*
* Return the order kswapd stopped reclaiming at as
* prepare_kswapd_sleep() takes it into account. If another caller
* entered the allocator slow path while kswapd was awake, order will
* remain at the higher level.
*/
return sc.order;
}
3.2.6 shrink_node
shrink_node是内存回收的核心函数,用于扫参数pgdat内存节点中所有的可回收页面,并进行回收处理。上述的三种回收方式,其核心实现都是shrink_node函数,不同的是准备动作和扫描控制器。下面将着重分析一下shrink_node的实现
static void shrink_node(pg_data_t *pgdat, struct scan_control *sc)
{
struct reclaim_state *reclaim_state = current->reclaim_state;
unsigned long nr_reclaimed, nr_scanned;
struct lruvec *target_lruvec;
bool reclaimable = false;
unsigned long file;
// 获得目标lruvec,lruvec包含5个lru链表,分别是活跃/非活跃匿名页,
// 活跃/非活跃文件页,不可回收链表
target_lruvec = mem_cgroup_lruvec(sc->target_mem_cgroup, pgdat);
again:
// nr是记录扫描过程中,各类页框的数量
memset(&sc->nr, 0, sizeof(sc->nr));
// 获取已经扫描的可回收和可扫描页数
nr_reclaimed = sc->nr_reclaimed;
nr_scanned = sc->nr_scanned;
/*
* Determine the scan balance between anon and file LRUs.
*/
spin_lock_irq(&pgdat->lru_lock);
// 用于匿名页和文件页lru链表平衡
sc->anon_cost = target_lruvec->anon_cost;
sc->file_cost = target_lruvec->file_cost;
spin_unlock_irq(&pgdat->lru_lock);
/*
* Target desirable inactive:active list ratios for the anon
* and file LRU lists.
*/
// 调整扫描匿名页和文件页的比率
if (!sc->force_deactivate) {
unsigned long refaults;
refaults = lruvec_page_state(target_lruvec,
WORKINGSET_ACTIVATE_ANON);
// 如果工作匿名页相比上一次循环已经有了变化,
// 或者当前非活跃匿名页链表数量过少,则需要扫描匿名页
if (refaults != target_lruvec->refaults[0] ||
inactive_is_low(target_lruvec, LRU_INACTIVE_ANON))
// 扫描匿名页
sc->may_deactivate |= DEACTIVATE_ANON;
else
// 不扫描匿名页
sc->may_deactivate &= ~DEACTIVATE_ANON;
/*
* When refaults are being observed, it means a new
* workingset is being established. Deactivate to get
* rid of any stale active pages quickly.
*/
// 如果工作文件页相比上一次循环已经有了变化,
// 或者当前非活跃文件页链表数量过少,则需要扫描文件页
refaults = lruvec_page_state(target_lruvec,
WORKINGSET_ACTIVATE_FILE);
if (refaults != target_lruvec->refaults[1] ||
inactive_is_low(target_lruvec, LRU_INACTIVE_FILE))
// 扫描文件页
sc->may_deactivate |= DEACTIVATE_FILE;
else
// 不扫描文件页
sc->may_deactivate &= ~DEACTIVATE_FILE;
} else
// 匿名和文件页都扫描
sc->may_deactivate = DEACTIVATE_ANON | DEACTIVATE_FILE;
/*
* If we have plenty of inactive file pages that aren't
* thrashing, try to reclaim those first before touching
* anonymous pages.
*/
// 如果不活跃的文件页框数量很多并且本次不扫描文件页,则做扫描平衡时,优先扫描文件页
file = lruvec_page_state(target_lruvec, NR_INACTIVE_FILE);
if (file >> sc->priority && !(sc->may_deactivate & DEACTIVATE_FILE))
sc->cache_trim_mode = 1;
else
sc->cache_trim_mode = 0;
/*
* Prevent the reclaimer from falling into the cache trap: as
* cache pages start out inactive, every cache fault will tip
* the scan balance towards the file LRU. And as the file LRU
* shrinks, so does the window for rotation from references.
* This means we have a runaway feedback loop where a tiny
* thrashing file LRU becomes infinitely more attractive than
* anon pages. Try to detect this based on file LRU size.
*/
if (!cgroup_reclaim(sc)) {
// 不支持mem_cgroup配置场景
unsigned long total_high_wmark = 0;
unsigned long free, anon;
int z;
// 计算node中所有zone的空闲页面数
free = sum_zone_node_page_state(pgdat->node_id, NR_FREE_PAGES);
// 计算node中所有文件页内存页数
file = node_page_state(pgdat, NR_ACTIVE_FILE) +
node_page_state(pgdat, NR_INACTIVE_FILE);
for (z = 0; z < MAX_NR_ZONES; z++) {
struct zone *zone = &pgdat->node_zones[z];
if (!managed_zone(zone))
continue;
// 统计node中所有zone的高水位保留值
total_high_wmark += high_wmark_pages(zone);
}
/*
* Consider anon: if that's low too, this isn't a
* runaway file reclaim problem, but rather just
* extreme pressure. Reclaim as per usual then.
*/
// node的匿名页数
anon = node_page_state(pgdat, NR_INACTIVE_ANON);
// 如果该node文件页框数量很少,则做扫描平衡时,选择匿名页
sc->file_is_tiny =
file + free <= total_high_wmark &&
!(sc->may_deactivate & DEACTIVATE_ANON) &&
anon >> sc->priority;
}
// 根据memcg配置进行页面回收,执行的主体为:
// 对lru链表进行回收
shrink_lruvec(lruvec, sc);
// 对slab进行回收
shrink_slab(sc->gfp_mask, pgdat->node_id, memcg,
sc->priority);
shrink_node_memcgs(pgdat, sc);
// slab的扫描到的页框数也计算上
if (reclaim_state) {
sc->nr_reclaimed += reclaim_state->reclaimed_slab;
reclaim_state->reclaimed_slab = 0;
}
/* Record the subtree's reclaim efficiency */
vmpressure(sc->gfp_mask, sc->target_mem_cgroup, true,
sc->nr_scanned - nr_scanned,
sc->nr_reclaimed - nr_reclaimed);
// 如果本次内存回收扫描到页框,则重设kswapd失败计数器,避免kswapd任务运行过于频繁
if (sc->nr_reclaimed - nr_reclaimed)
reclaimable = true;
if (current_is_kswapd()) {
// 如果node中有很多页面正在被回写,则设置PGDAT_WRITEBACK标志
if (sc->nr.writeback && sc->nr.writeback == sc->nr.taken)
set_bit(PGDAT_WRITEBACK, &pgdat->flags);
/* Allow kswapd to start writing pages during reclaim.*/
// 在lru的尾部发现很多脏页,则设置PGDAT_DIRTY标志
if (sc->nr.unqueued_dirty == sc->nr.file_taken)
set_bit(PGDAT_DIRTY, &pgdat->flags);
/*
* If kswapd scans pages marked for immediate
* reclaim and under writeback (nr_immediate), it
* implies that pages are cycling through the LRU
* faster than they are written so also forcibly stall.
*/
// 等待页面回写完成
if (sc->nr.immediate)
congestion_wait(BLK_RW_ASYNC, HZ/10);
}
// 如果lru中有很多脏页,需要置上LRUVEC_CONGESTED标记
if ((current_is_kswapd() ||
(cgroup_reclaim(sc) && writeback_throttling_sane(sc))) &&
sc->nr.dirty && sc->nr.dirty == sc->nr.congested)
set_bit(LRUVEC_CONGESTED, &target_lruvec->flags);
// 如果是直接回收,当node变得很拥挤(脏页过多),
// 则阻塞等待一段时间,等一些页面回写完成后,才继续进行回收操作。但kswapd中此处不会阻塞
if (!current_is_kswapd() && current_may_throttle() &&
!sc->hibernation_mode &&
test_bit(LRUVEC_CONGESTED, &target_lruvec->flags))
wait_iff_congested(BLK_RW_ASYNC, HZ/10);
// 判断是否需继续回收,继续回收的条件是该node中所有zone都不满足压缩条件
if (should_continue_reclaim(pgdat, sc->nr_reclaimed - nr_reclaimed,
sc))
goto again;
// 如果回收通过,则重设kswapd失败计数器,该计数器可以延缓直接内存回收的启动时机
if (reclaimable)
pgdat->kswapd_failures = 0;
}下面简单总结下核心流程:
-
内存回收是针对lru链表的,所以第一步需要获取到目标lru链表。
-
根据当前node的情况,调整匿名页和文件页的扫描比率。如果当前非活跃匿名页过少,则本次需要扫描匿名页;同样文件页也是同样的处理
-
如果当前文件页数量过多,则做扫描平衡时,优先扫描文件页。相反,如果文件页框数量很少,则优先扫描匿名页
-
根据扫描控制器对node进行扫描与回收
-
如果当前是kswapd任务,根据node页回写和脏页情况,需要设置node对应的标记,这是为了减轻系统的负担。当系统大量页在回写,则考虑跳过或者等待回写完成后,再进行回收处理;如果lru尾部已经有大量脏页,则后续就不再将脏页加入到lru尾部
-
判断该node是否已经可以结束回收,结束判断条件是:系统没有开启可压缩配置项,或本次申请1个页框,又或者本次申请少于等于8个页框并且当前优先级大于等于10
-
如果本次回收没有真正回收到页面,则结束
-
如果node中某个zone已经满足内存碎片整理的条件,则尝试内存碎片整理的方式分配内存,不再继续进行内存回收
-
该node中非活跃页框无法达到内存碎片整理的差距,则结束
3.2.6.1 shrink_lruvec
static void shrink_lruvec(struct lruvec *lruvec, struct scan_control *sc)
{
unsigned long nr[NR_LRU_LISTS];
unsigned long targets[NR_LRU_LISTS];
unsigned long nr_to_scan;
enum lru_list lru;
unsigned long nr_reclaimed = 0;
unsigned long nr_to_reclaim = sc->nr_to_reclaim;
struct blk_plug plug;
bool scan_adjusted;
// 计算本次内存回收每个lru链表扫描的页面数,存放到nr数组中
// 两个因素会影响扫描页面数:
// 1、优先级,优先级越高扫描页面越少,优先级是0是,扫描全部链表
// 2、swappiness,可以配置匿名页和文件页的扫描比率
get_scan_count(lruvec, sc, nr);
/* Record the original scan target for proportional adjustments later */
// 将nr数组临时保存到targets数组中
memcpy(targets, nr, sizeof(nr));
scan_adjusted = (!cgroup_reclaim(sc) && !current_is_kswapd() &&
sc->priority == DEF_PRIORITY);
blk_start_plug(&plug);
// 如果LRU_INACTIVE_ANON、LRU_ACTIVE_FILE、LRU_INACTIVE_FILE
// 中任意一个没有回收完,都会继续回收
while (nr[LRU_INACTIVE_ANON] || nr[LRU_ACTIVE_FILE] ||
nr[LRU_INACTIVE_FILE]) {
unsigned long nr_anon, nr_file, percentage;
unsigned long nr_scanned;
for_each_evictable_lru(lru) {
if (nr[lru]) {
// 一次最多扫描32个页面
nr_to_scan = min(nr[lru], SWAP_CLUSTER_MAX);
nr[lru] -= nr_to_scan;
// 从lru中回收nr_to_scan个页面,执行主体
nr_reclaimed += shrink_list(lru, nr_to_scan,
lruvec, sc);
}
}
cond_resched();
// 如果已经扫描到足够的空闲页,并且无需全部扫描nr中的页面,则停止扫描
if (nr_reclaimed < nr_to_reclaim || scan_adjusted)
continue;
// 计算剩余的页面数
nr_file = nr[LRU_INACTIVE_FILE] + nr[LRU_ACTIVE_FILE];
nr_anon = nr[LRU_INACTIVE_ANON] + nr[LRU_ACTIVE_ANON];
// 如果文件页或者匿名页已经回收完,则直接停止
if (!nr_file || !nr_anon)
break;
// 计算哪种类型的页面还剩比较少,停止对剩余较少的lru进行扫描
if (nr_file > nr_anon) {
unsigned long scan_target = targets[LRU_INACTIVE_ANON] +
targets[LRU_ACTIVE_ANON] + 1;
lru = LRU_BASE;
// 剩余需要扫描页面占比
percentage = nr_anon * 100 / scan_target;
} else {
unsigned long scan_target = targets[LRU_INACTIVE_FILE] +
targets[LRU_ACTIVE_FILE] + 1;
lru = LRU_FILE;
percentage = nr_file * 100 / scan_target;
}
/* Stop scanning the smaller of the LRU */
nr[lru] = 0;
nr[lru + LRU_ACTIVE] = 0;
/*
* Recalculate the other LRU scan count based on its original
* scan target and the percentage scanning already complete
*/
lru = (lru == LRU_FILE) ? LRU_BASE : LRU_FILE;
nr_scanned = targets[lru] - nr[lru];
nr[lru] = targets[lru] * (100 - percentage) / 100;
nr[lru] -= min(nr[lru], nr_scanned);
lru += LRU_ACTIVE;
nr_scanned = targets[lru] - nr[lru];
nr[lru] = targets[lru] * (100 - percentage) / 100;
nr[lru] -= min(nr[lru], nr_scanned);
scan_adjusted = true;
}
blk_finish_plug(&plug);
// 累加总回收页面数
sc->nr_reclaimed += nr_reclaimed;
/*
* Even if we did not try to evict anon pages at all, we want to
* rebalance the anon lru active/inactive ratio.
*/
// 非活动匿名页太少,从活动匿名页移动一部分到非活动匿名页中
if (total_swap_pages && inactive_is_low(lruvec, LRU_INACTIVE_ANON))
shrink_active_list(SWAP_CLUSTER_MAX, lruvec,
sc, LRU_ACTIVE_ANON);
}在开启扫描之前,需要根据当前node的情况计算出匿名页和文件页的扫描比例。计算方式如下:
-
如果没有swap空间了,则不进行匿名页扫描。
-
/proc/sys/vm/swapiness配置,范围是0 ~ 200,其意义是扫描匿名页和文件页的比率。如果是接近0,则更多扫描文件页;如果是接近200,则更多扫描匿名页。
-
如果当前特权级是0,并且swapiness非0,则均等扫描。
-
如果node几乎没有文件页了,则只扫描匿名页。
-
如果node有足够多的非活跃文件页,则只扫描文件页。
-
按比率的方式,根据swapiness、anon_cost和file_cost三个值计算。
3.2.6.2 shrink_list
计算出各种类型的页框扫描的数量,每次去对应lru链表尾部取出一定数量的页框(一次最多32[nr_to_scan]个),但需要注意两点:1. 只有非活跃链表中的页框才能被回收,活跃链表可能会被放入到非活跃链表中。2.就算是非活跃链表中的页框,也不是全部都能回收,还需要根据该页最近是否被访问过来确定。
static unsigned long shrink_list(enum lru_list lru, unsigned long nr_to_scan, struct lruvec *lruvec, struct scan_control *sc)
{
// 如果活动页不需要进行回收,但是需要考虑当非活动页数量不足时,从活动页移动到非活动页中
if (is_active_lru(lru)) {
// 如果是本次允许处理类型,才考虑放入到非活跃链表中,否则标记跳过
if (sc->may_deactivate & (1 << is_file_lru(lru)))
// 将页框从活动lru中隔离出来,然后加入到非活动lru中
shrink_active_list(nr_to_scan, lruvec, sc, lru);
else
sc->skipped_deactivate = 1;
return 0;
}
// 对非活动页进行回收
return shrink_inactive_list(nr_to_scan, lruvec, sc, lru);
}3.2.6.3 shrink_inactive_list
shrink_list已经确定要进行内存回收的lru链表(只能是非活跃链表)以及需处理的page个数(nr_to_scan),接下来需要做以下几点事情:
-
在非kswapd中,如果node被隔离的页框多余非活跃的页框,则会等待100ms(下面源码中删除)。
-
将lru缓存刷入到lru链表中。
-
从目标lru链表尾部隔离出页框,放入到临时链表中,没有隔离到页框则结束。
-
将隔离出来的页框进行回收,最终返回回收成功的页框数。
-
没有被回收的页框,会重新放回到lru_pvecs.lru_add链表缓存中,等合适的时间再刷入lru链表中。
-
如果扫描到的脏页没有在IO队列中等待回写,则说明flusher任务没有在工作,需要唤醒其将脏页回写
static noinline_for_stack unsigned long
shrink_inactive_list(unsigned long nr_to_scan, struct lruvec *lruvec,
struct scan_control *sc, enum lru_list lru)
{
LIST_HEAD(page_list);
unsigned long nr_scanned;
unsigned int nr_reclaimed = 0;
unsigned long nr_taken;
struct reclaim_stat stat;
bool file = is_file_lru(lru);
enum vm_event_item item;
struct pglist_data *pgdat = lruvec_pgdat(lruvec);
bool stalled = false;
/* 删除部分 */
// 将lru缓存刷入到lru链表中
lru_add_drain();
spin_lock_irq(&pgdat->lru_lock);
// 从lru(非活动链表)尾部开始隔离一些page到page_list链表中,
// 最终成功隔离的真实页框数量是nr_taken
nr_taken = isolate_lru_pages(nr_to_scan, lruvec, &page_list,
&nr_scanned, sc, lru);
__mod_node_page_state(pgdat, NR_ISOLATED_ANON + file, nr_taken);
/* 删除部分 */
spin_unlock_irq(&pgdat->lru_lock);
// 没有隔离到页面,则返回0
if (nr_taken == 0)
return 0;
// page_list中已经隔离出可回收的页,在这里进行回收,但不是所有都能回收掉
nr_reclaimed = shrink_page_list(&page_list, pgdat, sc, &stat, false);
spin_lock_irq(&pgdat->lru_lock);
// page_list可能还有本次无法最终完成回收的page,需要重新放回到lru链表中
move_pages_to_lru(lruvec, &page_list);
__mod_node_page_state(pgdat, NR_ISOLATED_ANON + file, -nr_taken);
lru_note_cost(lruvec, file, stat.nr_pageout);
/* 删除部分 */
spin_unlock_irq(&pgdat->lru_lock);
// 最终将剩下的隔离出来页面都释放掉
mem_cgroup_uncharge_list(&page_list);
free_unref_page_list(&page_list);
// 如果扫描到的脏页没有在IO队列中等待,则唤醒flusher任务进行回写
if (stat.nr_unqueued_dirty == nr_taken)
wakeup_flusher_threads(WB_REASON_VMSCAN);
// 记录页面回收的情况
sc->nr.dirty += stat.nr_dirty;
sc->nr.congested += stat.nr_congested;
sc->nr.unqueued_dirty += stat.nr_unqueued_dirty;
sc->nr.writeback += stat.nr_writeback;
sc->nr.immediate += stat.nr_immediate;
sc->nr.taken += nr_taken;
if (file)
sc->nr.file_taken += nr_taken;
trace_mm_vmscan_lru_shrink_inactive(pgdat->node_id,
nr_scanned, nr_reclaimed, &stat, sc->priority, file);
return nr_reclaimed;
}3.2.6.4 shrink_page_list
/*
* shrink_page_list() returns the number of reclaimed pages
*/
static unsigned int shrink_page_list(struct list_head *page_list,
struct pglist_data *pgdat,
struct scan_control *sc,
struct reclaim_stat *stat,
bool ignore_references)
{
LIST_HEAD(ret_pages);
LIST_HEAD(free_pages);
unsigned int nr_reclaimed = 0;
unsigned int pgactivate = 0;
memset(stat, 0, sizeof(*stat));
cond_resched();
// 遍历所有page_list中的page,但并非所有都可以顺利释放掉
while (!list_empty(page_list)) {
struct address_space *mapping;
struct page *page;
enum page_references references = PAGEREF_RECLAIM;
bool dirty, writeback, may_enter_fs;
unsigned int nr_pages;
cond_resched();
// 从lru链表(非活跃链表)中获取一个page
page = lru_to_page(page_list);
// 从lru链表中删除该page节点
list_del(&page->lru);
// 尝试对page进行上锁操作,如果上锁失败,表示页面还在被占用,
// 则将page添加到ret_pages中,后续统一处理
if (!trylock_page(page))
goto keep;
VM_BUG_ON_PAGE(PageActive(page), page);
// 获取page真实对应的页框数
nr_pages = compound_nr(page);
/* Account the number of base pages even though THP */
sc->nr_scanned += nr_pages;
// 如果page是不可回收页,则放置到ret_pages中统一处理
if (unlikely(!page_evictable(page)))
goto activate_locked;
// 若当前回收不允许回收被映射了的页,剔除被映射了的页面(跳转到keep_locked)
// 1.sc->may_unmap==1 表示允许回收映射的页面
// 2.page_mapped(page)使用于判断page->_mapcount是否大于0.
// 大于0表示有一个或多个用户PTE映射到该页
// 3.此处if表明当不允许回收映射的页面,且此时有用户PTE映射到该页面,
// 则直接跳转到keep_locked.
if (!sc->may_unmap && page_mapped(page))
goto keep_locked;
may_enter_fs = (sc->gfp_mask & __GFP_FS) ||
(PageSwapCache(page) && (sc->gfp_mask & __GFP_IO));
// 检查page是否是脏页或者正在回写的页
page_check_dirty_writeback(page, &dirty, &writeback);
if (dirty || writeback)
stat->nr_dirty++;
// 如果是脏页但是不是正在回写的页,相应的没有回写的标记加1
if (dirty && !writeback)
stat->nr_unqueued_dirty++;
/* 删除部分 */
//若该页正处于回写状态,需要考虑下面3中场景:
/*(1) 如果当前页面正处于回写状态且属于可回收页类型,
那么当当前页面回收者是kswapd线程且此时当前页对应的内存节点中有大量正在回写的页面时,
linux os此时会增加nr_immediate计数,然后跳转到keep_locked标签处执行完当前页的
后续安置操作,接着继续扫描page_list链表,而不是睡眠等待当前页的回写完成
(若等待回写完成,可能kswapd线程会导致无限期等待,
因为在页面回写时可能会出现磁盘I/O错误或者磁盘连接错误)*/
/*(2) 若当前页面不是可回收页(无回收标记,通过PageReclaim判断)
或者是当前页面分配器的调用者并未使用__GFP_FS或__GFP_IO分配标志。
那么给当前页设置PG_PageReclaim标志位,并增加nr_writeback计数,
然后跳转到keep_locked标签处,继续对page_list链表进行扫描*/
//(3) 除了上面两种情况外,若当前页正在回写,那么当前进程会睡眠等待当前页的回写完成
if (PageWriteback(page)) {
/* Case 1 above */
if (current_is_kswapd() &&
PageReclaim(page) &&
test_bit(PGDAT_WRITEBACK, &pgdat->flags)) {
stat->nr_immediate++;
goto activate_locked;
/* Case 2 above */
} else if (writeback_throttling_sane(sc) ||
!PageReclaim(page) || !may_enter_fs) {
// 将page标记为需要回收,并且放置到lru的尾部,尽快回收
SetPageReclaim(page);
stat->nr_writeback++;
goto activate_locked;
/* Case 3 above */
} else {
unlock_page(page);
//等待当前页回写完成
wait_on_page_writeback(page);
/* then go back and try same page again */
// 当前页回写完成后,将当前页加入page_list链表尾,
// continue后while循环又会扫到刚回写完成的当前页进行回收处理
list_add_tail(&page->lru, page_list);
continue;
}
}
/* 删除部分 */
/*
* Anonymous process memory has backing store?
* Try to allocate it some swap space here.
* Lazyfree page could be freed directly
*/
// 如果page是匿名页
if (PageAnon(page) && PageSwapBacked(page)) {
// 没有加入到swapcache中,则加入到swapcache。
// 匿名页在没有最终写入到swap区时,页面都会
// 一直停留在swapcache中,只有最终写入到swap区
// 后,才最终从swapcache中删除。
if (!PageSwapCache(page)) {
// 如果本次内存申请不支持IO操作,
// 则继续将page放置在原lru链表中
if (!(sc->gfp_mask & __GFP_IO))
goto keep_locked;
if (page_maybe_dma_pinned(page))
goto keep_locked;
if (PageTransHuge(page)) {
/* cannot split THP, skip it */
if (!can_split_huge_page(page, NULL))
goto activate_locked;
/*
* Split pages without a PMD map right
* away. Chances are some or all of the
* tail pages can be freed without IO.
*/
if (!compound_mapcount(page) &&
split_huge_page_to_list(page,
page_list))
goto activate_locked;
}
// 将page加入到swap分区,此时可以理解为在swap分区(实质是磁盘)中
// 创建一个“文件”;并且将page标记为dirty,让page被回写到“文件”中。
// 但由于回写是一个IO过程,此时对该page的访问其实是访问到page cache。
if (!add_to_swap(page)) {
if (!PageTransHuge(page))
goto activate_locked_split;
/* Fallback to swap normal pages */
if (split_huge_page_to_list(page,
page_list))
goto activate_locked;
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
count_vm_event(THP_SWPOUT_FALLBACK);
#endif
if (!add_to_swap(page))
goto activate_locked_split;
}
// 后续可能会发生文件系统的相关操作
may_enter_fs = true;
/* Adding to swap updated mapping */
// 获取此匿名页在swap cache中的address space
mapping = page_mapping(page);
}
} else if (unlikely(PageTransHuge(page))) {
/* Split file THP */
if (split_huge_page_to_list(page, page_list))
goto keep_locked;
}
/*
* THP may get split above, need minus tail pages and update
* nr_pages to avoid accounting tail pages twice.
*
* The tail pages that are added into swap cache successfully
* reach here.
*/
if ((nr_pages > 1) && !PageTransHuge(page)) {
sc->nr_scanned -= (nr_pages - 1);
nr_pages = 1;
}
/*
* The page is mapped into the page tables of one or more
* processes. Try to unmap it here.
*/
// 由于该page要被回收,所以所有映射了该页的进程都需要做unmap操作
if (page_mapped(page)) {
enum ttu_flags flags = TTU_BATCH_FLUSH;
bool was_swapbacked = PageSwapBacked(page);
if (unlikely(PageTransHuge(page)))
flags |= TTU_SPLIT_HUGE_PMD;
// 对所有映射了该page的进程做unmap操作
/*1、如果page是匿名页,则将进程页表项改成swap cache中的偏移量swp_entry_t
,这时候如果有进程继续访问页表,则访问的是swap cache,
并且停止将该page继续写入swap中,因为该页还在被使用。*/
// 2、如果是文件页,清空对应的页表项即可。
if (!try_to_unmap(page, flags)) {
stat->nr_unmap_fail += nr_pages;
if (!was_swapbacked && PageSwapBacked(page))
stat->nr_lazyfree_fail += nr_pages;
goto activate_locked;
}
}
// 如果当前页是脏页(脏文件页或者上面添加到swap的匿名页)
if (PageDirty(page)) {
// 如果是脏文件页,并且不是在kswap(非kswap进程不能对文件页回写)
// 中和不在内存回收流程中,则将page设置PG_reclaim标记,
// 并放置到活动链表中,待回写到磁盘后,将其回收。
if (page_is_file_lru(page) &&
(!current_is_kswapd() || !PageReclaim(page) ||
!test_bit(PGDAT_DIRTY, &pgdat->flags))) {
/*
* Immediately reclaim when written back.
* Similar in principal to deactivate_page()
* except we already have the page isolated
* and know it's dirty
*/
inc_node_page_state(page, NR_VMSCAN_IMMEDIATE);
SetPageReclaim(page);
goto activate_locked;
}
if (references == PAGEREF_RECLAIM_CLEAN)
goto keep_locked;
if (!may_enter_fs)
goto keep_locked;
if (!sc->may_writepage)
goto keep_locked;
/*
* Page is dirty. Flush the TLB if a writable entry
* potentially exists to avoid CPU writes after IO
* starts and then write it out here.
*/
try_to_unmap_flush_dirty();
// 运行到这里,说明的确是在回收流程中出现的脏页,尝试将脏页换出
// 这里也只是将页写入到块中,并不是真正的写入到文件系统
// pageout执行成功会标记PG_reclaim和PG_wirteable,并且清空PG_dirty标志
// 当页回写完成,PG_reclaim和PG_wirteable标记都会被清除
switch (pageout(page, mapping)) {
case PAGE_KEEP:
goto keep_locked;
case PAGE_ACTIVATE:
goto activate_locked;
case PAGE_SUCCESS:
stat->nr_pageout += thp_nr_pages(page);
// 如果页还没有回写完成,则将该page继续放在该lru中(异步场景)
if (PageWriteback(page))
goto keep;
// 正常来说pageout成功后,应该清除PG_dirty属性,
// 如果此处还是有PG_dirty属性即保留该page
if (PageDirty(page))
goto keep;
/*
* A synchronous write - probably a ramdisk. Go
* ahead and try to reclaim the page.
*/
if (!trylock_page(page))
goto keep;
if (PageDirty(page) || PageWriteback(page))
goto keep_locked;
mapping = page_mapping(page);
case PAGE_CLEAN:
; /* try to free the page below */
}
}
// 运行到这里说明页已经回写完成(异步场景,如果没有回写完成,则上面已经调到keep流程了)
// 如果是文件页(如果private域设置了PAGE_FLAGS_PRIVATE),还需要考虑释放buffer_head
if (page_has_private(page)) {
// 释放该page
if (!try_to_release_page(page, sc->gfp_mask))
goto activate_locked;
if (!mapping && page_count(page) == 1) {
unlock_page(page);
if (put_page_testzero(page))
goto free_it;
else {
/*
* rare race with speculative reference.
* the speculative reference will free
* this page shortly, so we may
* increment nr_reclaimed here (and
* leave it off the LRU).
*/
nr_reclaimed++;
continue;
}
}
}
// 如果是匿名页并且没有被交换到swap区中,page的refcount应该是1
if (PageAnon(page) && !PageSwapBacked(page)) {
/* follow __remove_mapping for reference */
if (!page_ref_freeze(page, 1))
goto keep_locked;
if (PageDirty(page)) {
page_ref_unfreeze(page, 1);
goto keep_locked;
}
count_vm_event(PGLAZYFREED);
count_memcg_page_event(page, PGLAZYFREED);
} else if (!mapping || !__remove_mapping(mapping, page, true,
sc->target_mem_cgroup))
// __remove_mapping负责将page从基树中移除,并且将page的refcount减2,如果
// refcount最终是0,则表示该page可以回收了;但如果不是0,表示还有其他地方
// 引用,则继续保留在lru中,不能回收。还有一种情况也不能释放,就是虽然refcount
// 是0了,但是页面还是脏页,表示又有进程对页面进行了访问并且unmap操作,如果
// 这种场景页释放了,那么数据就会丢失
goto keep_locked;
unlock_page(page);
free_it:
/*
* THP may get swapped out in a whole, need account
* all base pages.
*/
nr_reclaimed += nr_pages;
/*
* Is there need to periodically free_page_list? It would
* appear not as the counts should be low
*/
// 到这里的page都是可以被回收的,有三种情况:
// 1、无需回写的页(refcount为0的非脏页)
// 2、本次同步回写的页
// 3、本次或者上次异步回写完成的页(上一次异步写的页可能在本次回收才最终完成)
if (unlikely(PageTransHuge(page)))
destroy_compound_page(page);
else
// 将page添加到free_pages链表等待回收
list_add(&page->lru, &free_pages);
continue;
activate_locked_split:
/*
* The tail pages that are failed to add into swap cache
* reach here. Fixup nr_scanned and nr_pages.
*/
if (nr_pages > 1) {
sc->nr_scanned -= (nr_pages - 1);
nr_pages = 1;
}
activate_locked:
// page被“锁”在内存中,不允许回收。
/* Not a candidate for swapping, so reclaim swap space. */
// 如果page已经被放置到swap区中,则尝试在swapcache中释放本页
if (PageSwapCache(page) && (mem_cgroup_swap_full(page) ||
PageMlocked(page)))
try_to_free_swap(page);
VM_BUG_ON_PAGE(PageActive(page), page);
// 如果该page最近被访问过,则将其设置成active,后续会放到活动链表中
if (!PageMlocked(page)) {
int type = page_is_file_lru(page);
SetPageActive(page);
stat->nr_activate[type] += nr_pages;
count_memcg_page_event(page, PGACTIVATE);
}
keep_locked:
unlock_page(page);
keep:
// 将page添加到ret_pages链表中
list_add(&page->lru, &ret_pages);
VM_BUG_ON_PAGE(PageLRU(page) || PageUnevictable(page), page);
}
pgactivate = stat->nr_activate[0] + stat->nr_activate[1];
mem_cgroup_uncharge_list(&free_pages);
try_to_unmap_flush();
// 将所有page释放给伙伴系统的pcplist(order为0)中
free_unref_page_list(&free_pages);
// 将ret_pages和page_list链表合并,也就是本次无法回收的页面,需要继续
// 放回到lru链表中。
list_splice(&ret_pages, page_list);
count_vm_events(PGACTIVATE, pgactivate);
// 返回最终成功回收的页面数
return nr_reclaimed;
}lru页框回收的核心函数,流程非常复杂,下面总结下关键流程:
-
遍历上一步骤中的临时隔离链表,每次从尾部取出一个page,并尝试上锁,如果上锁失败,则将page放入到另一个临时链表,等到最后统一处理。
-
如果上锁成功,则计算page对应的真实页框数,扫描控制器记录以扫描的真实页框数。
-
如果page不是可回收的类型,则解锁该page,并放入到临时链表,表示要跳过该页的回收。如果page已经被放置到swap缓存区,则取出;如果该page最近被访问过,则标记其为active。
-
如果当前不允许对page进行unmap操作,而page被进程映射了,则对page进行解锁,并放入临时隔离链表,后续同一处理。
-
如果page当前正在做回写操作,则有以下3中情况:
-
当前在kswapd中,并且当前page正在回收,而且该node最近许多页在回写,则本次不对该page进行回收了。
-
此页正在进行回写,但不是因为内存回收导致的。这种情况还是需要将此页标记为需要回收并且放置到lru的尾部,尽快回收。
-
其他情况则同步等待回写完成,并且将page重新放置到回收链表尾部,下次循环继续处理该page。
-
如果page是匿名页,并且正在回写到swap分区,这时候有两种情况:
-
page已经在swapcache中,则无需操作,等待回写完成即可。
-
page没有在swapcache中,则需要加入到swapcache中,否则匿名页无法被写入swap分区。
-
如果page已经被映射了,则需要通过反向映射,则对page进行unmap操作。这里区分两种情况:
-
如果page是匿名页,则将进程页表项改成swap cache中的偏移量swp_entry_t,这时候如果有进程继续访问页表,则访问的是swap cache,并且停止将该page继续写入swap中,因为该页还在被使用。
-
如果是文件页,清空对应的页表项即可。
-
如果page是脏页,有如下几种情况:
-
如果是脏文件页,并且当前不在kswapd任务中,则将page标记为PG_reclaim,并放置到活动链表中,待kswapd任务将其回写后,再将其回收。
-
如果在kswapd任务或者非脏文件页,则将page换出。注意这里的换出,只是将页写入到块中,并不是真正的写入到文件系统。换出执行成功后,会标记PG_reclaim和PG_wirteable,并且清空PG_dirty标志。当页回写完成,PG_reclaim和PG_wirteable标记都会被清除。
-
页回写完成后,如果是文件页,还需要释放buffer_head内容。