文章目录
- 任务&数据集
- 一、基算法
- 1.1 决策树(Decision Tree)
- 1.2 逻辑回归(Logistic Regression)
- 1.3 支持向量机(Support Vector Machine, SVM)
- 二、集成算法
- 2.1 随机森林(Random Forest)
- 2.2 AdaBoost(Adaptive Boosting)
- 2.3 GBDT(Gradient Boosting Decision Tree)
- 2.4 XGBoost(eXtreme Gradient Boosting)
- 2.5 LightGBM(Light Gradient Boosting Machine)
- 参考资料
任务&数据集
【任务描述】:基于鸢尾花数据集训练相应的分类器,实现分类。
【数据集】:鸢尾花数据集最初由Edgar Anderson 测量得到,而后在著名的统计学家和生物学家R.A Fisher于1936年发表的文章「The use of multiple measurements in taxonomic problems」中被使用,用它作为线性判别分析(Linear Discriminant Analysis)的一个例子,证明分类的统计方法。该数据集是在机器学习领域一个常用的数据集。
数据集地址:http://archive.ics.uci.edu/ml/datasets/Iris
一、基算法
1.1 决策树(Decision Tree)
(1)算法原理:决策树根据样本数据集的数据特征对数据集进行划分,直到针对所有特征都划分过,或者划分的数据子集的所有数据的类别标签相同。
(2)核心代码:
这里,我们给出完整的实现代码,其中一部分代码可复用(如数据加载、划分训练集测试集等),后面不再重复给出。
from sklearn import tree
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, mean_squared_error
import matplotlib.pyplot as plt
from sklearn2pmml import sklearn2pmml, PMMLPipeline # 调用生成pmml文件方法
# 导入数据
iris = load_iris()
x = iris.data
y = iris.target
print(x.shape, y.shape)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25, random_state=40) # 划分训练集和验证集, random_state即随机种子设定为固定的值后,每次数据集的拆分结果一致,确保实验可重复性
# 训练模型
dc_tree = tree.DecisionTreeClassifier(criterion='entropy', min_samples_leaf=5)
dc_tree.fit(x_train, y_train)
# 测试模型
y_pred = dc_tree.predict(x_test)
acc = accuracy_score(y_test, y_pred)
print("acc:", acc)
mse = mean_squared_error(y_test, y_pred) ** 0.5
print("mse:", mse)
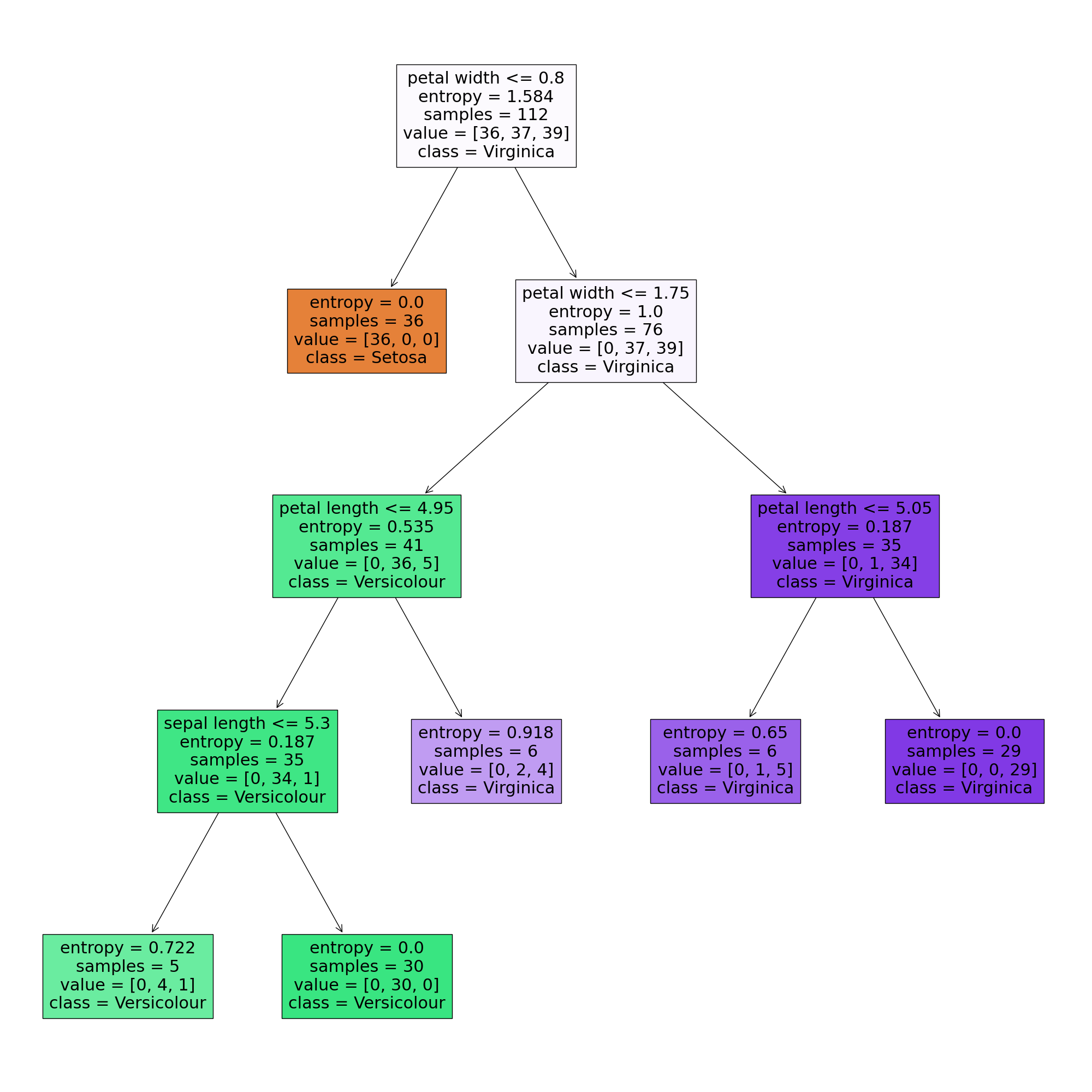
# 决策树可以可视化
fig = plt.figure(figsize=(20, 20))
tree.plot_tree(dc_tree, filled=True,
feature_names=['sepal length', 'sepal width', 'petal length', 'petal width'],
class_names=['Setosa', 'Versicolour', 'Virginica']) # 山鸢尾、杂色鸢尾、维吉尼亚鸢尾
plt.savefig("./outputs/dt_iris.png", bbox_inches='tight', pad_inches=0.0)
plt.show()
# 生成PMML文件,方便通过多种工具查看、导出、调用等
pipeline = PMMLPipeline([("classifier", dc_tree)])
pipeline.fit(x_train, y_train)
sklearn2pmml(pipeline, "./outputs/dt_iris.pmml")
决策树可视化:
1.2 逻辑回归(Logistic Regression)
(1)算法原理:逻辑回归是一种线性分类器,通过logistic函数,将特征映射成一个概率值,来判断输入数据的类别。
(2)核心代码:
from sklearn.linear_model import LogisticRegression
# 训练模型
lr = LogisticRegression()
lr.fit(x_train, y_train)
1.3 支持向量机(Support Vector Machine, SVM)
(1)算法原理:寻找一个能够正确划分训练数据集并且几何间隔最大的分离超平面。
(2)核心代码:
from sklearn import svm
# 训练模型
svm = svm.SVC(C = 1.0, kernel = 'rbf', degree = 3, gamma = 'scale', coef0 = 0.0, shrinking = True, probability = False, tol = 0.001, cache_size = 200, class_weight = None, verbose = False, max_iter = -1, decision_function_shape = 'ovr', break_ties = False, random_state = None)
svm.fit(x_train, y_train)
二、集成算法
2.1 随机森林(Random Forest)
(1)算法原理:使用CART树作为弱分类器,将多个不同的决策树进行组合,利用这种组合来降低单棵决策树的可能带来的片面性和判断不准确性。
(2)核心代码:
from sklearn.ensemble import RandomForestClassifier
# 训练模型
clf = RandomForestClassifier(n_estimators = 100, criterion = 'gini', max_depth = None, min_samples_split = 2, min_samples_leaf = 1, min_weight_fraction_leaf = 0.0, max_features = 'auto', max_leaf_nodes = None, min_impurity_decrease = 0.0, min_impurity_split = None, bootstrap = True, oob_score = False, n_jobs = None, random_state = None, verbose = 0, warm_start = False, class_weight = None, ccp_alpha = 0.0, max_samples = None)
clf.fit(x_train, y_train)
2.2 AdaBoost(Adaptive Boosting)
(1)算法原理:AdaBoost算法中,前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数。
(2)核心代码:
from sklearn.ensemble import AdaBoostClassifier
# 训练模型
clf = AdaBoostClassifier(base_estimator = None, n_estimators = 50, learning_rate = 1.0, algorithm = 'SAMME.R', random_state = None)
clf.fit(x_train, y_train)
2.3 GBDT(Gradient Boosting Decision Tree)
(1)算法原理:GBDT是每次建立单个分类器时,是在之前建立的模型的损失函数的梯度下降方向。GBDT的核心在于每一棵树学的是之前所有树结论和的残差,残差就是真实值与预测值的差值,所以为了得到残差,GBDT中的树全部是回归树,之所以不用分类树,是因为分类的结果相减是没有意义的。
(2)核心代码:
from sklearn.ensemble import GradientBoostingClassifier
# 训练模型
clf = GradientBoostingClassifier(loss = 'deviance', learning_rate = 0.1, n_estimators = 100, subsample = 1.0, criterion = 'friedman_mse', min_samples_split = 2, min_samples_leaf = 1, min_weight_fraction_leaf = 0.0, max_depth = 3, min_impurity_decrease = 0.0, min_impurity_split = None, init = None, random_state = None, max_features = None, verbose = 0, max_leaf_nodes = None, warm_start = False, presort = 'deprecated', validation_fraction = 0.1, n_iter_no_change = None, tol = 0.0001, ccp_alpha = 0.0)
clf.fit(x_train, y_train)
2.4 XGBoost(eXtreme Gradient Boosting)
(1)算法原理:XGBoost的原理与GBDT基本相同,但XGB是在GBDT基础上的优化。相比而言,XGB主要有2点优化:
- XGB支持并行,速度快;
- 损失函数加入了正则项,防止过拟合。
(2)核心代码:
from xgboost import XGBClassifier
# 训练模型
xgb = XGBClassifier(max_depth=3, learning_rate=0.1, n_estimators=100, verbosity=1, silent=None, objective='binary:logistic', booster='gbtree', n_jobs=1, nthread=None, gamma=0, min_child_weight=1, max_delta_step=0, subsample=1, colsample_bytree=1, colsample_bylevel=1, colsample_bynode=1, reg_alpha=0, reg_lambda=1, scale_pos_weight=1, base_score=0.5, random_state=0, seed=None, missing=None)
xgb.fit(x_train, y_train)
# 特征重要性
print("Feature importances: ", list(xgb.feature_importances_))
这里,XGBoost模型的
list(xgb.feature_importances_)可以输出各个分类特征对于分类的重要程度,可以帮助我们筛选出对分类任务较为重要的特征。
这里,XGBoost本身带有许多参数,我们可以采用网格搜索法 或者 Optuna 框架 实现调参:
- 基于GridSearch网格搜索法调参
当需要调整的参数量较少时,我们可以直接使用sklearn 中的 GridSearchCV 实现调参:
from sklearn.model_selection import GridSearchCV
# GridSearch网格搜索法调参
xgb = XGBClassifier(max_depth=3)
param_grid = {
"learning_rate": [0.01, 0.1, 1],
"n_estimators": [20, 40]
}
xgb = GridSearchCV(xgb, param_grid)
# 训练模型
xgb.fit(x_train, y_train)
# 输出最优参数
print("Best parameters found by grid search are: ", xgb.best_params_)
- 基于Optuna框架调参
Optuna是一个开源的超参数优化(HPO)框架,用于自动执行超参数的搜索空间。 为了找到最佳的超参数集,Optuna使用贝叶斯方法。 它支持下面列出的各种类型的采样器:
- GridSampler (使用网格搜索)
- RandomSampler (使用随机采样)
- TPESampler (使用树结构的Parzen估计器算法)
- CmaEsSampler (使用CMA-ES算法)
具体实现可参考博客:基于 Optuna 的模型超参数优化
2.5 LightGBM(Light Gradient Boosting Machine)
(1)算法原理:LightGBM是在XGB基础上的优化,主要优化点在于速度更快、占用内存更小、精确度更高、支持类别变量。
(2)核心代码:
import lightgbm as lgb
from sklearn.model_selection import train_test_split
#3、训练、验证模型
gbm = lgb.LGBMRegressor(boosting_type = 'gbdt', num_leaves = 31, max_depth = -1, learning_rate = 0.05, n_estimators = 100, subsample_for_bin = 200000, objective = 'regression', class_weight = None, min_split_gain = 0.0, min_child_weight = 0.001, min_child_samples = 20, subsample = 1.0, subsample_freq = 0, colsample_bytree = 1.0, reg_alpha = 0.0, reg_lambda = 0.0, random_state = None, n_jobs = -1, silent = True, importance_type = 'split')
gbm.fit(X_train, y_train, eval_set = [(X_test, y_test)], eval_metric = 'l1', early_stopping_rounds = 10)
gbm.fit(X_train, y_train)
LightGBM中也涉及参数的调整,调参方式和XGBoost类似,此处不再赘述。
参考资料
几种风控算法的原理和代码实现