文章目录
- 相关资料
- 摘要
- 引言
- 对抗性鲁棒性的文本提示
- CLIP回顾
- 方法
- 提示参数化
- 提示优化
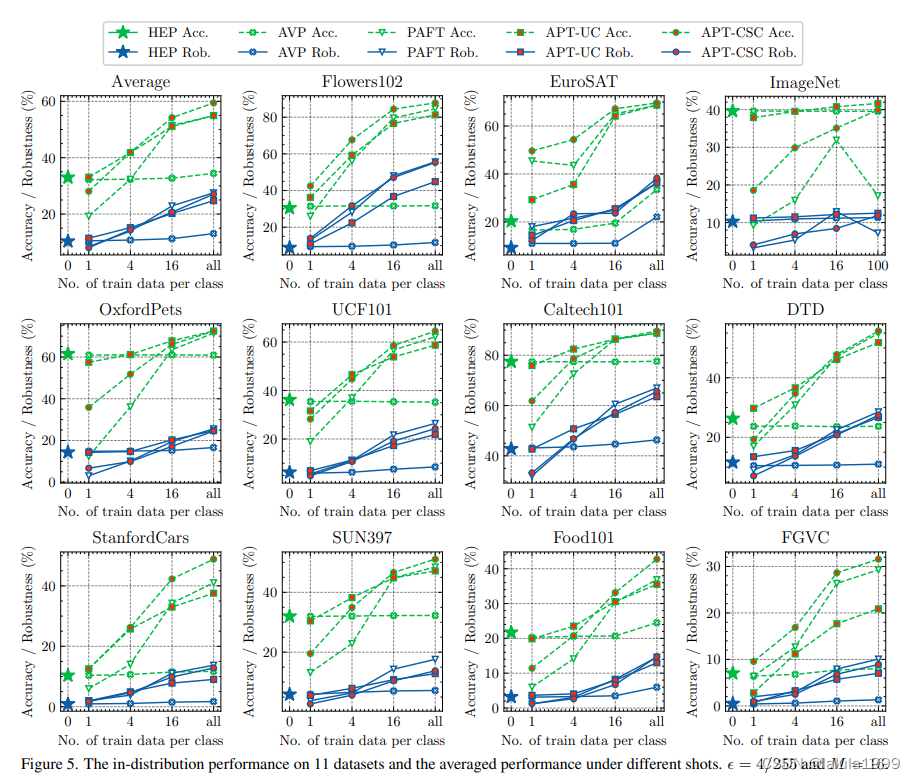
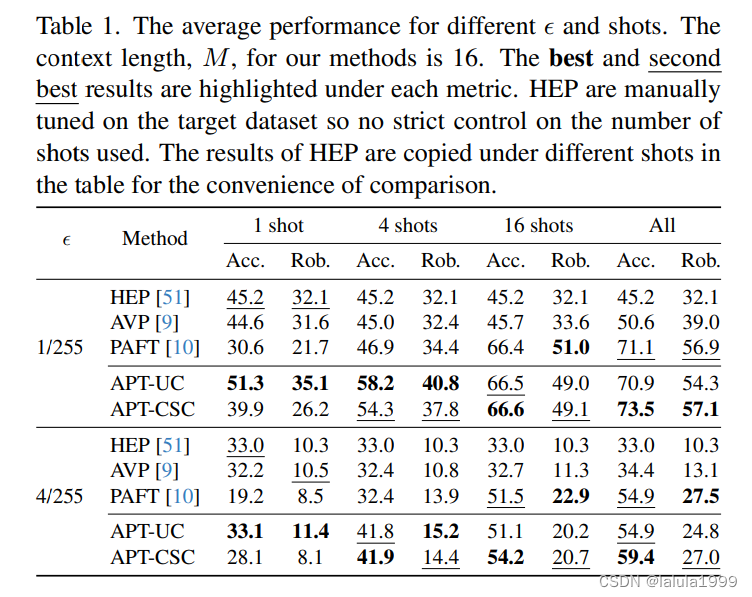
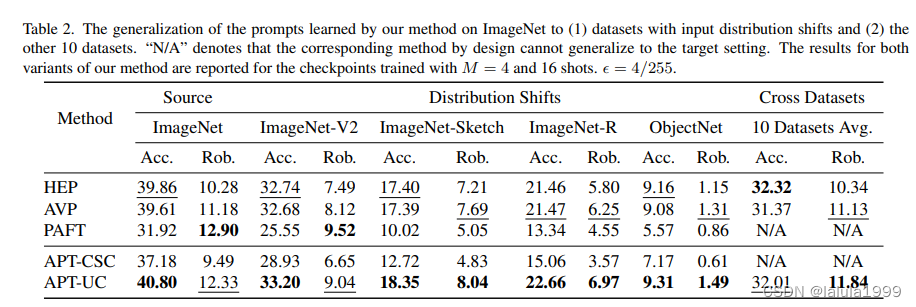
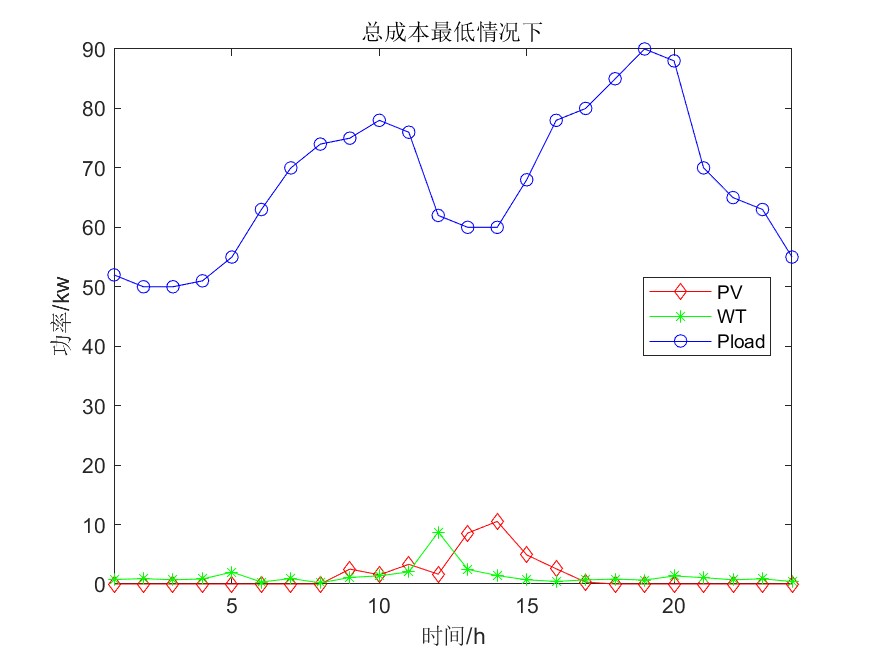
- 实验
相关资料
论文:[2403.01849] One Prompt Word is Enough to Boost Adversarial Robustness for Pre-trained Vision-Language Models (arxiv.org)
代码:TreeLLi/APT: One Prompt Word is Enough to Boost Adversarial Robustness for Pre-trained Vision-Language Models (github.com)
摘要
大型预训练视觉-语言模型(VLMs),如CLIP,尽管具有显著的泛化能力,但极易受到对抗性样本的攻击。本研究从文本提示这一新颖角度出发,而不是广泛研究的模型权重(在本研究中固定不变),来研究VLMs的对抗性鲁棒性。我们首先展示了对抗性攻击和防御的有效性都对所使用的文本提示非常敏感。受此启发,我们提出了一种通过为VLMs学习鲁棒文本提示来提高对对抗性攻击的抵抗力的方法。我们提出的方法,名为对抗性提示微调(APT),在计算和数据效率方面都非常有效。我们进行了广泛的实验,涵盖了15个数据集和4种数据稀疏性方案(从1-shot到完整训练数据设置),以展示APT相较于手工设计的提示和其他最先进的适应方法的优越性。APT在分布内性能以及在输入分布偏移和跨数据集下的泛化能力方面表现出色。令人惊讶的是,通过简单地向提示中添加一个学习到的词,APT可以显著提高准确性和鲁棒性(ϵ = 4/255),与手工设计的提示相比分别平均提高了+13%和+8.5%。在我们的最有效设置中,改进进一步提高,分别达到了+26.4%的准确性和+16.7%的鲁棒性。
引言
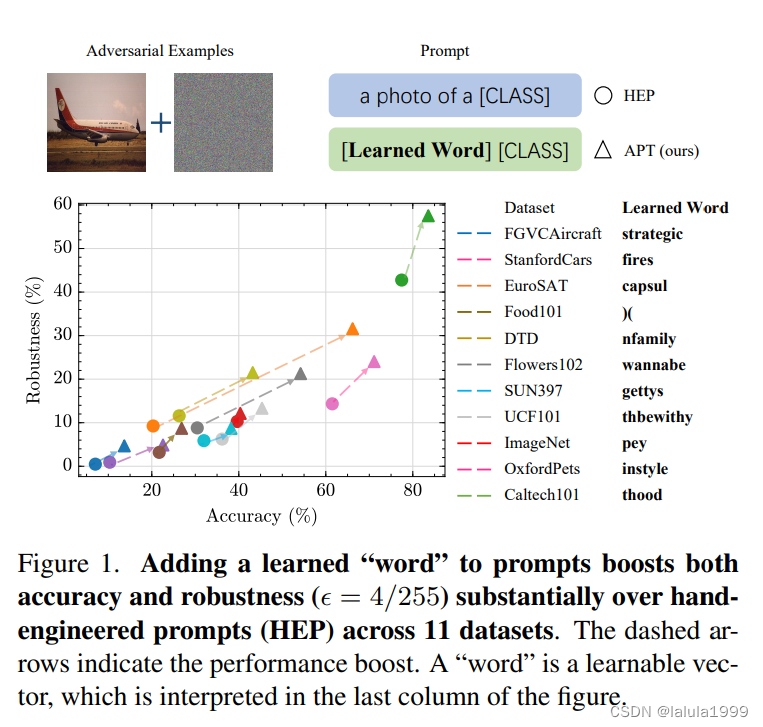
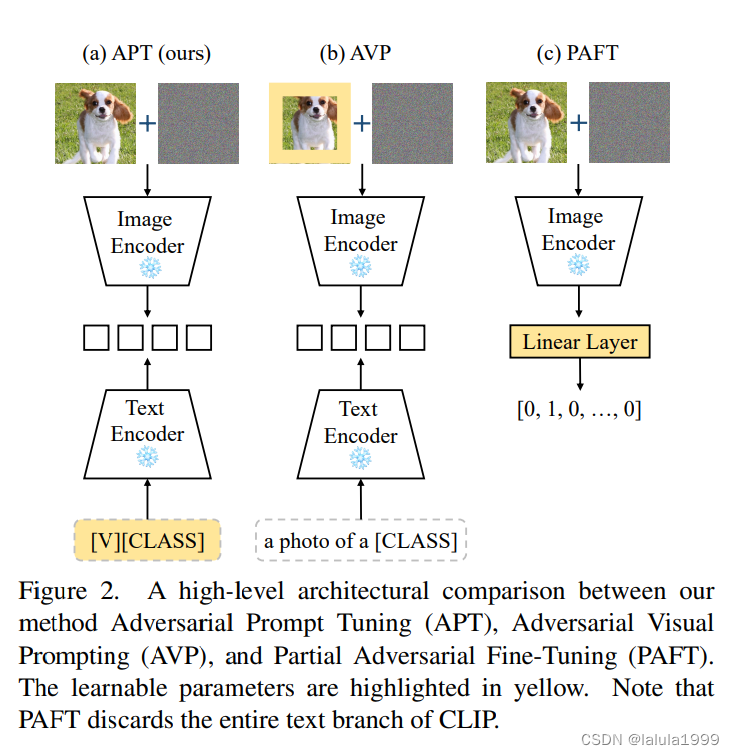
当前对抗性鲁棒性的适应方法集中在模型权重上,即对抗性微调或图像像素上,即对抗性视觉提示。尽管文本输入对VLMs的准确性有显著影响,并且具有如VLMs简单支持(因此不需要修改架构)、参数效率高等优点,但以前很少研究文本提示在对抗性鲁棒性方面的应用。本工作旨在通过研究文本提示在对抗性鲁棒性中的作用,提出一种新的方法来调整文本提示以提高对抗性鲁棒性(见图2)。
文本提示如何影响CLIP的对抗性攻击和防御。我们的主要发现包括:
- 对抗性攻击的强度对生成对抗性示例时使用的提示很敏感;
- 当用于攻击的提示与受害者模型在推理中使用的提示相同时,几乎所有最强的对抗性示例都是生成的;
- CLIP的对抗性鲁棒性对用于推理的提示很敏感。
前两个发现为如何提示强大的对抗性攻击提供了启示。最后一个发现促使我们提出对抗性提示微调(APT)来学习基于对抗性示例的鲁棒文本提示,以提高其对抗性鲁棒性。APT以软提示的形式参数化提示,即将类别嵌入与一系列可学习的向量连接起来(如图3所示)。这些向量构成了数据和类别的上下文描述。它们可以统一为所有类别共享,或者特定于每个类别。然后提出了三种不同的提示策略,以生成训练对抗性示例,可学习的向量被优化以最小化预测损失,如交叉熵。
对抗性鲁棒性的文本提示
CLIP回顾

算法1是一个伪代码,描述了对CLIP模型进行ℓ∞范数下的对抗性攻击的过程。这个过程包括了对图像和文本的扰动,以生成对抗性样本。
算法1 伪代码 for ℓ∞ adversarial attack on CLIP. 如果 perturb t 为真,则扰动文本。K 是步数。α (α′) 是图像 (文本) 扰动的步长。
1: function ATTACK(x, y, t, perturb t)
2: δ = uniform(−ϵ, ϵ) // 在图像像素上初始化扰动,范围在 -ϵ 到 ϵ 之间
3: δ′ = 0 // 文本扰动初始化为 0
4: for 1 → K do
5: x′ = min(0, max(x + δ, 1)) // 将扰动后的像素值限制在 [0, 1] 范围内
6: L = L(x′, t + δ′, y; θv, θt) // 计算损失函数,包括图像、文本和真实标签
7: δ = min(−ϵ, max(δ + α · SIGN(∇xL), ϵ)) // 更新图像扰动 δ 以最大化损失函数
8: if perturb t then // 如果需要扰动文本
9: δ′ = δ′ + α′ · ∇tL // 更新文本扰动 δ′ 以最大化损失函数
10: end if
11: end for
12: return min(0, max(x + δ, 1)) // 返回最终扰动后的图像,确保像素值在 [0, 1] 范围内
13: end function
这个算法的目的是通过逐步增加图像和文本的扰动来找到能够让模型做出错误预测的对抗性样本,同时确保这些扰动足够小,以至于对人类观察者来说几乎是不可察觉的。
方法
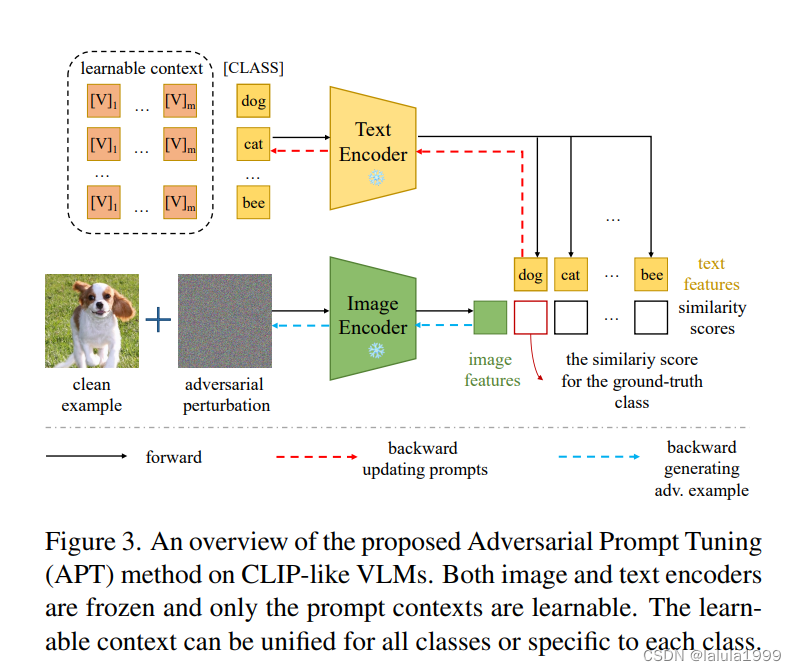
提示参数化
我们首先将文本提示中的上下文参数化为可学习的。类别 C j C_j Cj可以放置在上下文向量序列内的任意位置。为了简单起见,我们仅测试了三个位置:前、中、后。实证结果显示,这三个位置的结果没有区别,因此默认使用后端。
我们采用了两种上下文参数化的变体:统一上下文(UC)和类别特定上下文(CSC)。在UC中,所有类别共享相同的上下文向量序列,因此无论使用多少类别,都只有一个上下文向量序列。相比之下,CSC为每个类别分配单独的上下文向量,允许不同类别拥有不同的、定制的上下文。总的来说,当训练数据有限时(如1-shot和4-shot),UC更有效;当训练数据相对丰富时(如16-shot和使用全部数据),CSC变体更有效。
提示优化
为了提高对抗性鲁棒性,我们使用对抗性训练来训练提示上下文:
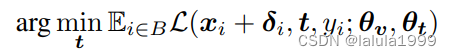
其中,扰动 δ i δ_i δi是由训练中的对抗方实时生成的,如算法2所示。在提示 t t t内部,只有上下文向量具有可学习参数,而类别嵌入是恒定的,因此优化提示本质上是优化上下文向量。

算法2是一个伪代码,用于描述Adversarial Prompt Tuning (APT) 方法中的训练过程。APT方法旨在通过对抗性训练来优化文本提示,以提高模型的对抗性鲁棒性。
算法2 伪代码 of APT
1: 函数 TRAIN_ONE_ITERATION(x, y)
2: t = G("[CLASS]") // 将类别名转换为词嵌入
3: t = [v, t] // 将上下文向量和类别嵌入连接起来
4: 如果 constant 为真
5: t' = G("a photo of a [CLASS]")
6: x = ATTACK(x, y, t', false) // 使用固定的提示进行对抗性攻击,不扰动文本
7: 否则如果 on-the-fly 为真
8: x = ATTACK(x, y, t, false) // 使用最新更新的提示进行对抗性攻击,不扰动文本
9: 否则如果 perturbed 为真
10: x = ATTACK(x, y, t, true) // 使用最新更新的提示进行对抗性攻击,并扰动文本
11: 结束如果
12: L = L(x, t, y; θv, θt) // 计算损失函数
13: v = v - λ · ∇vL // 更新上下文向量 v,λ 是学习率
14: 结束函数
这个算法的目的是通过对抗性训练来调整文本提示,使其能够在对抗性攻击下提高模型的鲁棒性。通过在每次迭代中更新文本提示的上下文向量,模型学习如何更好地抵抗对抗性扰动。
关键设计选择是生成 δ i δ_i δi的算法。 δ i δ_i δi依赖于用于攻击的文本提示 t ′ t′ t′,它可以与公式中的 t t t不同。我们提出了三种可能的提示策略,用于生成训练对抗性示例,分别如下:
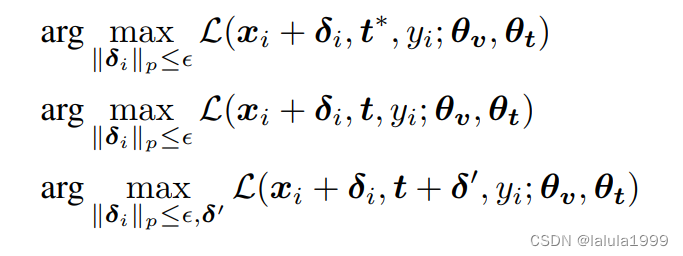
策略constant将攻击的提示固定为预定义的一个,“a photo of a [CLASS]”。此策略为每张图片生成的扰动在训练期间是恒定的,无论推理提示如何,因为模型权重和攻击提示都是固定的。这使得对抗性图像特征可以重用,从而加速了提示调整过程。然而,它可能不会带来好处,甚至可能损害性能,因为扰动现在不再是动态对抗性的。
相比之下,策略on-the-fly基于最新更新的文本提示t从公式生成对抗性示例。
最后,策略perturbed,也称为多模态对抗性攻击,在策略on-the-fly的基础上,同时扰动图像和文本提示,以进一步扩大对抗性损失,并希望生成更强的对抗性示例。
实验