前提引入:
在高并发的场景下,大量的请求直接访问Mysql很容易造成性能问题。所以,我们都会用Redis来做数据的缓存,削减对数据库的请求。但是,Mysql和Redis是两种不同的数据库,如何保证不同数据库之间数据的一致性就非常关键了。
分析数据不一致的原因:
在高并发的业务场景下,数据库大多数情况都是用户并发访问最薄弱的环节。所以,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问MySQL等数据库。
读取缓存步骤一般没有什么问题,但是一旦涉及到数据更新:数据库和缓存更新,就容易出现缓存(Redis)和数据库(MySQL)间的数据一致性问题。
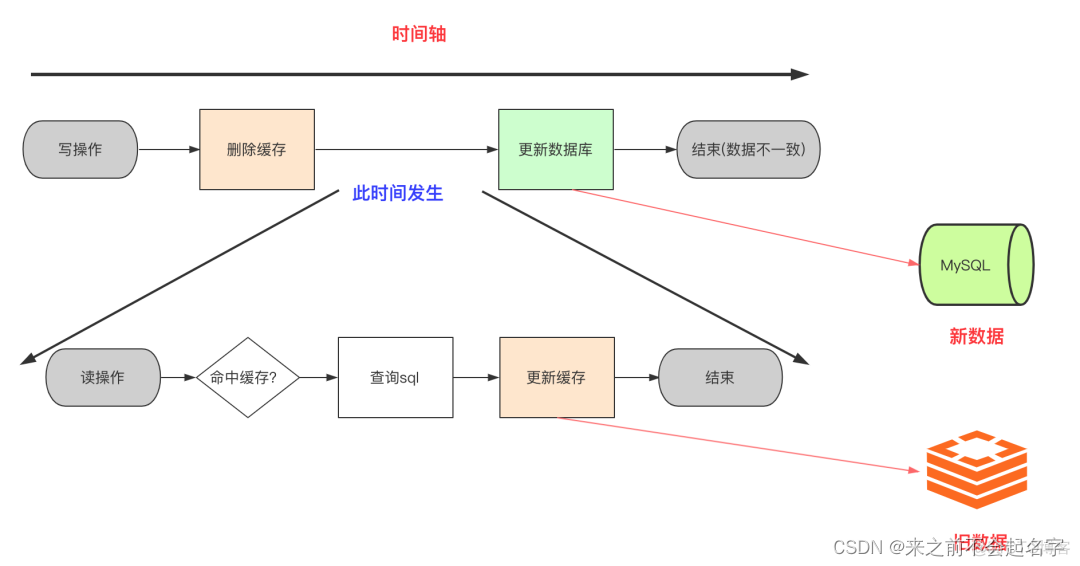
使用缓存的一般流程:

缓存先后删除问题?
-
我先删除缓存,再去更新数据库
在修改数据库中的信息前,我先把缓存中的数据给删除掉,删除成功后我再去修改数据库的信息! 问:高并发下会出现什么问题?
对,可能会出现缓存和数据库的数据不一致的问题。
分析:
如果先删除Redis缓存数据,然而还没有来得及写入MySQL,另一个线程就来读取。
这个时候发现缓存为空,则去Mysql数据库中读取旧数据 并把读取到的数据写入缓存,此时缓存中的数据还是之前的数据。
然后数据库更新后发现Redis和Mysql出现了数据不一致。
2.那我先更新数据库,再去删除缓存
不饶弯子,直接来分析;
如果先写了库,然后再删除缓存,不幸的是删缓存的线程挂了,导致了缓存没有删除
这个时候就会直接读取旧缓存,最终也导致了数据不一致情况(因为写和读是并发的,没法保证顺序,就会出现缓存和数据库的数据不一致的问题)
解决方案:
一、延时双删策略
为什么要双删呢!
基本思路:在写库前后都进行redis.del(key)操作,并且设定合理的超时时间。
具体步骤:
1、先删除缓存
2、再写数据库
3、休眠xxx毫秒(根据具体的业务时间来定)
4、再次删除缓存

问题:这个xxx毫秒怎么确定的,具体该休眠多久时间呢?
1、需要评估自己的项目的读数据业务逻辑的耗时。
2、这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
3、当然这种策略还要考虑redis和数据库主从同步的耗时。
4、最后的的写数据的休眠时间:则在读数据业务逻辑的耗时基础上,加几百ms即可。
比如:休眠1秒。


![[next.js] svgr/webpack](https://img-blog.csdnimg.cn/direct/d496cd86e8b741ce8f21bccb74950d42.png)