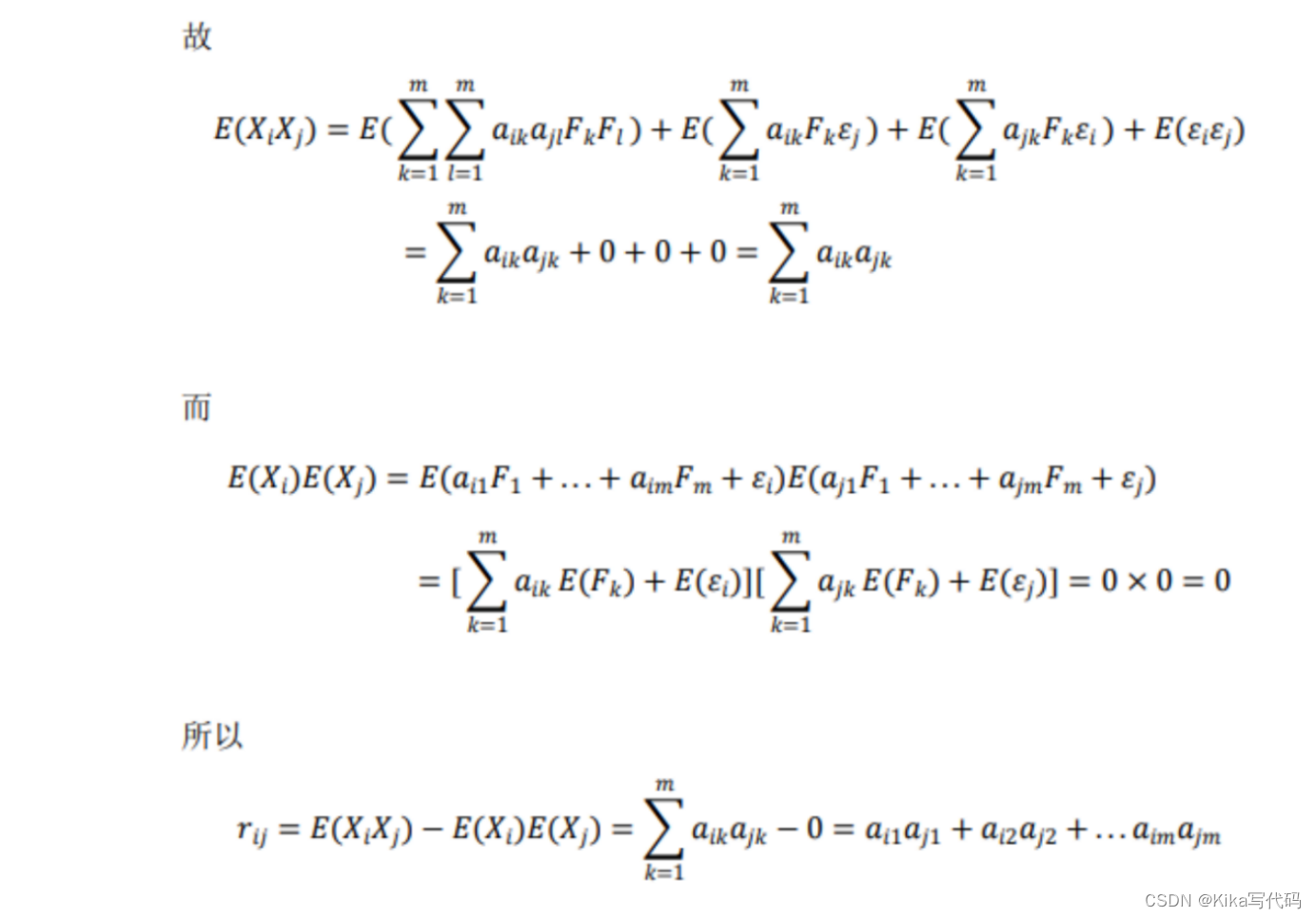✍🏻记录学习过程中的输出,坚持每天学习一点点~
❤️希望能给大家提供帮助~欢迎点赞👍🏻+收藏⭐+评论✍🏻+指点🙏

文本提取技术中用到的算法
TF-IDF(Term Frequency-Inverse Document Frequency)
TF-IDF是一种统计方法,用以评估一个词语对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TFIDF实际上是:TF * IDF
TF词频(Term Frequency)指的是某一个给定的词语在该文件中出现的频率,对于某一特定文件里的词语来说,它的重要性可表示为:
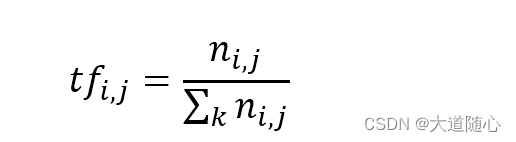
以上式子中分子式该词在文件中的出现次数,而分母则是在文件中所有字词的出现次数之和。IDF逆向文件频率(Inverse Document Frequency)是一个词语普遍重要性的度量,某一特定词语的IDF,可以由总文件数据除以包含该词语之文件的数目,再将得到的商取以10为底的对数得到:
![[图片]](https://img-blog.csdnimg.cn/direct/c12c3fb9de874cd7bf3d6e0e5809f4c9.png)
其中,|D|为语料库中的文件总数。由于考虑到词语可能不在语料库中,所以用这个分母表示。然后再计算TF与IDF的乘积。
![[图片]](https://img-blog.csdnimg.cn/direct/904ec534ca6648fdb219e4a0eab3cbd9.png)
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
TextRank
概念
TextRank算法是一种用于从文本中提取关键信息的算法,它基于图的排序算法。该算法的基本思想来源于谷歌的PageRank算法,通过把文本分割成若干组成单元(如单词、句子)并建立图模型,利用投票机制对文本中的重要成分进行排序。TextRank算法不需要事先对多篇文档进行学习训练,仅利用单篇文档本身的信息即可实现关键词提取、文摘等任务。
流程
TextRank算法的一般流程如下:
文本预处理:将所有文章整合成文本数据,并进行必要的文本清洗和分词处理。
构建图模型:
关键词提取:将文本中的每个单词视为一个节点,通过设置一个滑动窗口(例如长度为N),将窗口内的词视为相邻节点,构建无向词图。
句子提取:将文本中的每个句子视为一个节点,计算句子之间的相似性(如使用同时出现在两个句子中的词的个数作为相似度衡量标准),并根据相似度构建以句子为节点、相似性得分为边的图结构。
权重计算:在图中,每个节点都有一个初始的权重值。通过迭代计算,根据节点与其他节点之间的关联以及它们之间的权重值,不断更新节点的权重值,直到收敛为止。
结果提取:
关键词提取:根据节点的权重值,选择权重值较高的节点作为关键词。
句子提取:根据节点的权重值(即句子的TextRank值),选择权重值较高的句子作为文本摘要。
应用场景
TextRank算法在文本处理领域有着广泛的应用,包括但不限于以下场景:
文本摘要:通过提取文本中权重值较高的句子,自动生成文本摘要,帮助用户快速了解文本的主要内容。
关键词提取:从文本中提取出权重值较高的单词或短语,作为文本的关键词,有助于用户快速了解文本的主题和重点。
内容管理:在内容管理系统中,可以使用TextRank算法对文章进行分类、标签生成、推荐等,提高内容管理的效率和质量。
问答系统:在问答系统中,可以使用TextRank算法对问题和答案进行相似度计算,从而找到与问题最匹配的答案。
社交网络分析:在社交网络分析中,TextRank算法可以用于分析用户生成的内容(如微博、评论等),提取关键信息,帮助理解用户的兴趣和行为。
通过以上介绍,可以看出TextRank算法在文本处理领域具有广泛的应用前景和实用价值。
LDA(Latent Dirichlet Allocation)
概念
LDA(Latent Dirichlet Allocation)是一种概率模型,属于生成模型的一种,用于从文档集合中发掘隐藏的主题结构。它假设每篇文档都是由一系列主题(Theme)按照一定的比例混合而成,而每个主题又由一系列词汇按照特定的概率分布来表达。LDA利用贝叶斯统计方法,通过迭代计算来估计出文档-主题分布和主题-词分布,从而揭示文档集中的隐含主题结构。
流程
- 初始化:为每个文档的每个单词随机分配一个主题标签,同时初始化文档-主题分布θ和主题-词分布β的参数。
- 采样:对于每篇文档中的每个词,依据当前的文档-主题分布和主题-词分布,重新采样这个词的主题标签,使得分配更加合理。
- 更新参数:根据新的主题分配,更新文档-主题分布θ和主题-词分布β的参数。
- 重复迭代:重复执行采样和参数更新步骤,直到模型参数收敛,即主题分配稳定或达到预定的迭代次数。
应用场景
- 文本挖掘与分析:LDA常用于新闻文章、社交媒体内容、科研论文等大量文本数据的分析,帮助理解数据中的主要话题。
- 文档分类与聚类:基于LDA提取的主题,可以作为文档的特征向量,用于文档的自动分类或聚类。
- 推荐系统:结合用户行为数据和内容信息,LDA可以帮助构建个性化推荐系统,提升推荐的准确性和多样性。
- 信息检索与过滤:通过主题建模优化查询扩展和相关性排名,提高搜索引擎的性能。
- 市场研究:分析消费者评论或反馈,发现产品特性、品牌印象等市场热点,指导营销策略。
- 社交网络分析:理解用户兴趣、社群结构,为用户画像和社群发现提供依据。
LDA因其强大的主题发现能力,在多个领域展现出广泛的应用价值,特别是在处理大规模无结构文本数据时,能够有效地提取出有价值的信息模式。
Word2Vec
概念
Word2Vec是一种用于学习文本数据中词的向量表示(词嵌入)的技术,由Google在2013年开源。它通过浅层神经网络模型,将自然语言中的词汇映射到一个连续的向量空间中,使得语义上相似的词在该空间中的向量也相近。Word2Vec不仅保留了词语的语法和语义信息,还能捕捉到词语之间的复杂关系,如类比推理(“国王"相对于"女王"就像"男人"相对于"女人”)。
流程
Word2Vec主要包含两种模型:CBOW(Continuous Bag of Words)和Skip-gram。其基本流程如下:
-
数据预处理:将原始文本数据清洗并转换成词序列,通常需要去除停用词、标点符号,并进行词干提取或词形还原。
-
模型选择与设置:选择CBOW或Skip-gram模型,设定向量的维度(比如100、300维)、窗口大小(决定上下文的范围)等超参数。
-
训练:
- CBOW:根据中心词周围的上下文词预测中心词。模型试图最小化从上下文词向量的组合预测中心词的概率的负对数似然。
- Skip-gram:相反,给定一个中心词,预测其周围的上下文词。模型通过最大化给定中心词向量预测其上下文词的概率来学习。
-
优化:使用梯度下降法或其他优化算法,如Negative Sampling或Hierarchical Softmax来加速训练过程并减少计算复杂度。
-
输出:训练完成后,每个词都被赋予一个高维向量,这些向量就是最终的词嵌入,可用于后续的自然语言处理任务。
应用场景
- 语义相似度计算:通过计算词向量间的余弦相似度或欧氏距离,评估词语间的语义相似度,用于信息检索、推荐系统中的相关性排序。
- 文本分类与情感分析:词嵌入作为文本特征,增强模型理解文本的能力,提高分类准确性。
- 机器翻译:词向量可以作为跨语言模型的输入,帮助捕捉不同语言间词汇的对应关系。
- 文本生成:基于词向量的连续性,可以用于生成连贯的文本段落。
- 命名实体识别:词嵌入有助于模型理解上下文,从而更准确地识别出文本中的实体。
- 问答系统:利用词向量理解问题与答案的语义,提升问答系统的精确匹配度。
Word2Vec由于其高效和强大的泛化能力,已经成为自然语言处理领域的重要基石之一。
深度学习算法
概念
深度学习算法是机器学习的一个子领域,它使用深层的神经网络结构来学习复杂的数据表示。这些网络由多个层次组成,每一层对输入数据进行逐步的抽象和转换,从低级特征逐渐提炼到高级特征。深度学习算法的核心在于其自动特征学习能力,即不需要手动设计特征,而是让模型从原始数据中自动学习有用的表示。
主流学习模型及其特点和应用
-
循环神经网络 (RNN):
- 特点: RNN具有循环结构,允许信息在序列中传递,使得每个时间步的输出不仅依赖于当前输入,还依赖于过去的信息。LSTM(长短期记忆)和GRU(门控循环单元)是RNN的变种,通过门机制解决了长期依赖问题。
- 应用: 适用于时间序列数据处理,如自然语言处理(NLP)、语音识别、音乐生成、股票市场预测等。
-
卷积神经网络 (CNN):
- 特点: 利用卷积层和池化层高效提取数据的局部特征,特别是对于图像和音频信号,能够通过权值共享减少参数量,提高模型效率。
- 应用: 主要用于图像识别、物体检测、视频分析、语音识别、图像生成等领域。
-
Transformer:
- 特点: 引入自注意力机制,能够并行处理整个序列,有效处理长距离依赖,无需递归结构,提高了处理速度和模型规模。
- 应用: 在自然语言处理领域取得了巨大成功,如机器翻译、文本摘要、问答系统、情感分析等,代表性模型包括BERT、GPT系列。
-
BERT (Bidirectional Encoder Representations from Transformers):
- 特点: 使用双向Transformer编码器学习文本的深度上下文表示,能够理解词汇在句子中的前后文关系。
- 应用: 在多项NLP任务中刷新纪录,包括问答、文本分类、命名实体识别等。
-
GPT (Generative Pre-trained Transformer):
- 特点: 是一种生成式的预训练模型,基于Transformer架构,通过无监督学习在大量文本数据上预先训练,然后针对特定任务进行微调。
- 应用: 文本生成、语言建模、对话系统、文章创作等,特别是在生成连贯、高质量的文本内容方面表现突出。
这些模型的特点和应用展示了深度学习在处理不同类型数据和解决复杂问题上的强大灵活性和有效性。随着技术的不断进步,深度学习算法正被不断探索和优化,以适应更多领域和挑战。