一、定义
- profiler 作用
- 入门
- pyprof
- torch.summary/torchinfo 模型参数量分析以及模型可视化
- profiling 参数分析-模型分析
二、实现
1.profiler 作用:分析模型执行时间,内存占用
CPU/GPU 端Op执行时间统计
CPU/GPU 端Op输入Tensor的维度分析
Op的内存消耗统计
2. 入门
- 安装profiling.
pip install torch_tb_profiler
- 命令行 运行tensorboard
tensorboard --logdir=./log #日志的路径

- 打开页面
http://localhost:6006/#pytorch_profiler
遇到的问题:json.decoder.JSONDecodeError: Invalid \escape: line 53124 column 56 (char 2265210)

报错:json.decoder.JSONDecodeError: Invalid \escape: line 53124 column 56 (char 2265210)
解决:将生成文件内 \ 路径全部替换为 /
- torch.summary/torchinfo 模型参数量分析以及模型可视化
torch.summary() 已经不在更新,合并到torchinfo 模块中。
import torch, torchvision
#model = torchvision.models.vgg
model = torchvision.models.vgg16().cuda()
from torchsummary import summary
summary(model, input_size=(3, 224, 224)) #旧版
新版
import torchvision.models as models
from torchinfo import summary
resnet18 = models.resnet18().cuda() # 实例化模型
summary(resnet18, (1, 3, 224, 224)) # 1:batch_size 3:图片的通道数 224: 图片的高宽
- profiling 参数分析-模型分析
从可视化界面的 解析结果,可以看出 各内存的占用情况,以及 各个模块,各个算子的内存占用、时间占用。 目的: 优化内存、优化时间
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim
import torch.profiler
import torch.utils.data
import torchvision.models
import torchvision.transforms as T
from torchvision.datasets.vision import VisionDataset
import numpy as np
from PIL import Image
# sample model
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 8, 3, padding=1)
self.conv2 = nn.Conv2d(8, 12, 3, padding=1)
self.conv3 = nn.Conv2d(12, 16, 3, padding=1)
self.conv4 = nn.Conv2d(16, 20, 3, padding=1)
self.conv5 = nn.Conv2d(20, 24, 3, padding=1)
self.conv6 = nn.Conv2d(24, 28, 3, padding=1)
self.conv7 = nn.Conv2d(28, 32, 3, padding=1)
self.conv8 = nn.Conv2d(32, 10, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.pool(F.relu(self.conv3(x)))
x = self.pool(F.relu(self.conv4(x)))
x = self.pool(F.relu(self.conv5(x)))
x = self.pool(F.relu(self.conv6(x)))
x = self.pool(F.relu(self.conv7(x)))
x = self.pool(F.relu(self.conv8(x)))
x = torch.flatten(x, 1) # flatten all dimensions except batch
return x
def log_softmax(x):
return x - x.exp().sum(-1).log().unsqueeze(-1)
def weighted_nll(pred, target, weight):
assert target.max() < 10
nll = -pred[range(target.shape[0]), target]
nll = nll * weight[target]
nll = nll / weight[target].sum()
sum_nll = nll.sum()
return sum_nll
# custom loss definition
class CrossEntropyLoss(nn.Module):
def forward(self, input, target):
pred = log_softmax(input)
loss = weighted_nll(pred, target, torch.Tensor([0.1]*10).cuda())
return loss
# dataset with random images that mimics the properties of CIFAR10
class FakeCIFAR(VisionDataset):
def __init__(self, transform):
super().__init__(root=None, transform=transform)
self.data = np.random.randint(low=0,high=256,size=(10000,32,32,3),dtype=np.uint8)
self.targets = np.random.randint(low=0,high=10,size=(10000),dtype=np.uint8).tolist()
def __getitem__(self, index):
img, target = self.data[index], self.targets[index]
img = Image.fromarray(img)
if self.transform is not None:
img = self.transform(img)
return img, target
def __len__(self) -> int:
return len(self.data)
transform = T.Compose(
[T.Resize(256),
T.PILToTensor()])
train_set = FakeCIFAR(transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=8,
shuffle=True, num_workers=8, pin_memory=True)
device = torch.device("cuda:0")
model = Net().to(device)
#criterion = CrossEntropyLoss().cuda(device)
criterion = torch.nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
model.train()
# # training loop wrapped with profiler object
with torch.profiler.profile(
schedule=torch.profiler.schedule(wait=1, warmup=4, active=3, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler('./log/example'),
record_shapes=True,
profile_memory=True,
with_stack=True
) as prof:
for step, data in enumerate(train_loader):
inputs = data[0].to(device=device, non_blocking=True)
labels = data[1].to(device=device, non_blocking=True)
inputs = (inputs.to(torch.float32) / 255. - 0.5) / 0.5
if step >= (1 + 4 + 3) * 1:
break
outputs = model(inputs)
loss = criterion(outputs, labels)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
prof.step()

gpu Utilization:gpu 利用率,越高越好
Est. SM Efficiency: 预估SM效率。数值越高越好。此指标为kernel的 SM 效率
Est. Achieved Occupancy:CUDA 理论占用率
kernel :GPU 设备上的kernel 执行时间;
Memcpy:涉及 GPU 的内存复制时间(D2D、D2H 或 H2D);
Memset:涉及 GPU 的内存设置时间;
通信:仅在 DDP 情况下出现的通信时间;
运行时:主机端的 CUDA 运行时执行时间;
例如 cudaLaunchKernel、cudaMemcpyAsync、cudaStreamSynchronize 等;
DataLoader:在 PyTorch DataLoader 对象中的数据加载时间;
CPU 执行:主机计算时间,包括每个 PyTorch 操作符的运行时间;
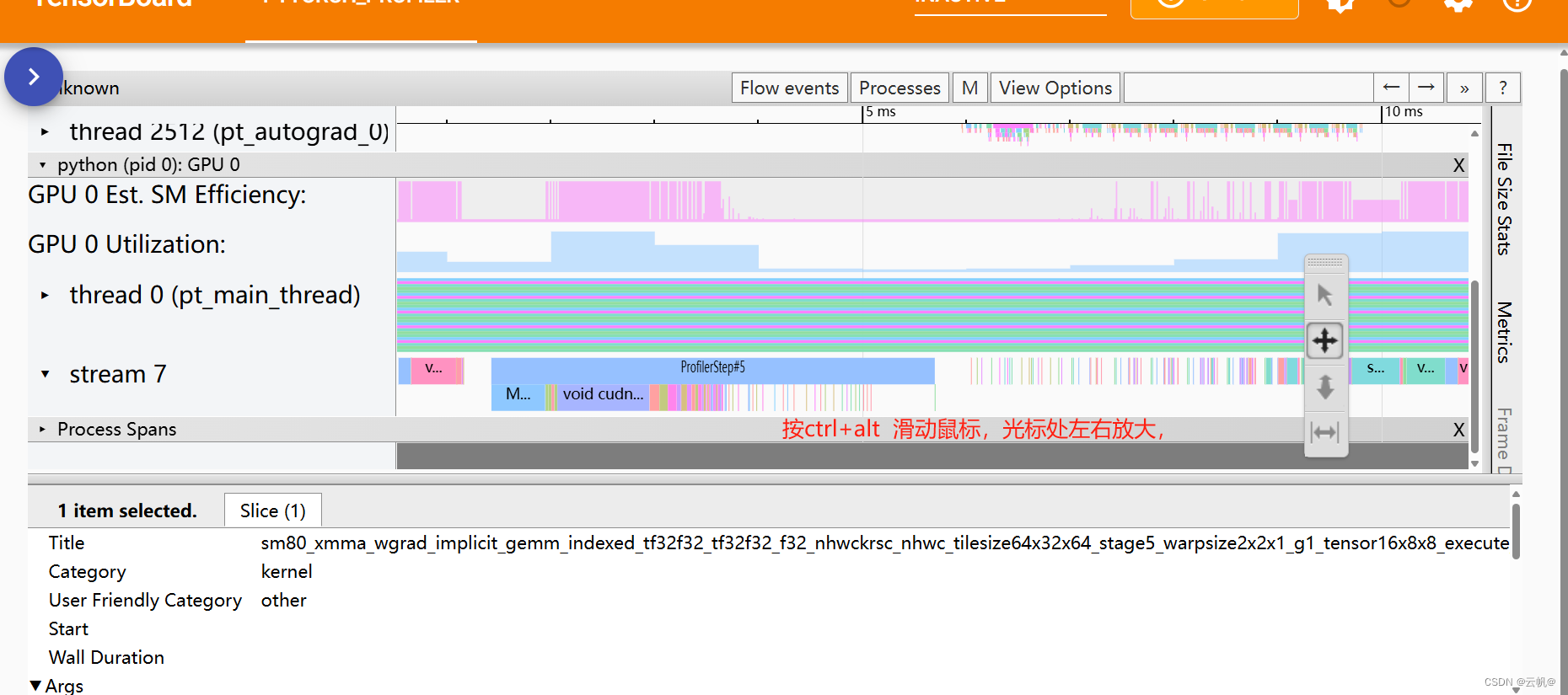
查看 时间占用。