一、分块与向量化
首先,我们的目标是创建一个向量索引,用以代表我们文档的内容,然后在运行时寻找所有这些向量与查询向量之间的最小余弦距离,以匹配最接近的语义含义。
1、分块
由于 Transformer 模型具有固定的输入序列长度,即便输入上下文窗口很大,一个句子或几个句子的向量通常能比几页文本的平均向量更好地表达其语义含义(这也取决于模型,但一般情况下是这样)。
因此,我们需要对数据进行分块 —— 将原始文档分割成某个大小的块,同时保留它们的含义(如将文本分割成句子或段落,而不是将单个句子切分成两部分)。目前有许多能够实现这一任务的文本分割器。
**块的大小是一个需要考虑的重要参数。**它取决于你使用的嵌入模型及其在 Token 上的处理能力。例如,标准的基于 BERT 的 Transformer 编码器模型(如 Sentence Transformers)最多处理 512 个 Token,而 OpenAI 的 ada-002 能够处理更长的序列,如 8191 个 Token。这里的权衡在于为 LLM 提供足够的上下文以进行推理,同时确保文本嵌入足够具体,以便有效执行搜索。
关于块大小选择的考虑因素,你可以参考下面链接里的研究。在 LlamaIndex 中,这些问题由 NodeParser 类以及一些高级选项(如自定义文本分割器、元数据、节点 / 块关系等)来处理。
https://www.pinecone.io/learn/chunking-strategies/
2、向量化
下一步是选择一个模型来嵌入这些块。市面上有不少选择,我倾向于使用像 bge-large 或 E5 嵌入系列这样的搜索优化模型。可以查看 MTEB 排行榜以获取最新的更新信息。
排行榜:https://huggingface.co/spaces/mteb/leaderboard
要了解分块和向量化步骤的端到端实现,可以参考 LlamaIndex 中完整数据摄入流程的示例:
https://docs.llamaindex.ai/en/latest/module_guides/loading/ingestion_pipeline/root.html
二、搜索索引
1、向量存储索引
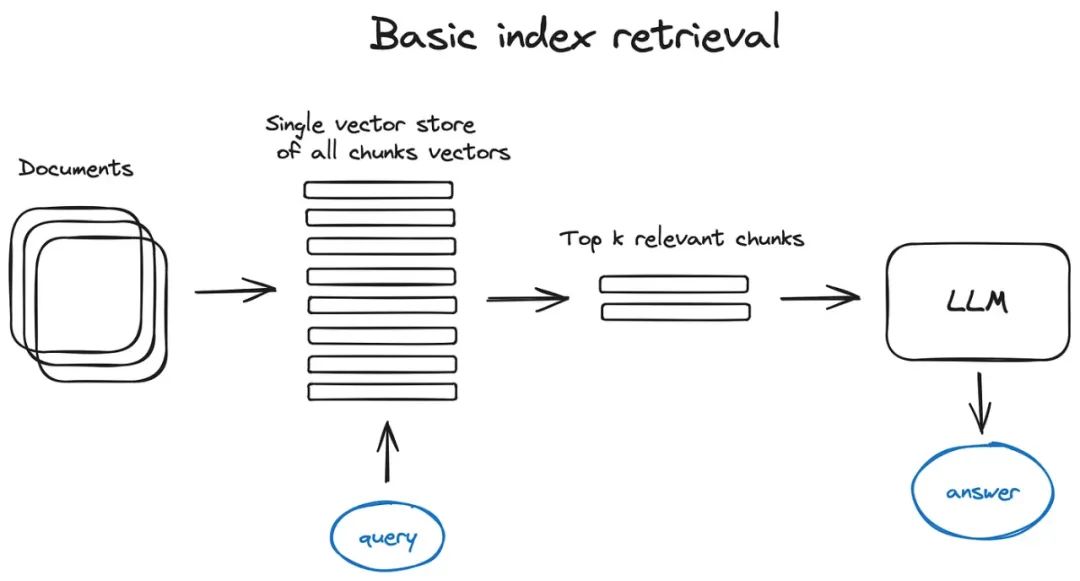
在这个架构及后续内容中,为了简化描述,我们不考虑编码器部分,直接把查询内容送入索引。显然,查询内容会首先被向量化。类似地,尽管索引是根据向量而不是具体的块来进行检索的,但最终我们还是以块的形式展现结果,因为获取这些块相对简单。
搜索索引是 RAG 流程中的核心部分,它存储了我们在前一步骤中生成的向量化内容。最基本的实现方法是使用平面索引,即对查询向量和所有文本块的向量进行直接的距离计算。
一个高效的搜索索引,专为超过 10000+ 元素的高效检索优化,会采用像 faiss、nmslib 或 annoy 这样的向量索引,它们利用了近似最近邻算法,如聚类、树结构或 HNSW 算法。
还有像 OpenSearch 或 ElasticSearch 这样的托管解决方案,以及像 Pinecone、Weaviate 或 Chroma 这样的向量数据库,它们在底层