目录
- 1.业务背景
- 2.业务导入流程
- 3.流程优化
- 3.1 模板模式
- 3.1.1 导入处理器接口`ImportProcessor`
- 3.1.2 抽象父类 `AbstractImportProcessor`
- 3.1.3 子类实现 `ImportDemoProcessor`
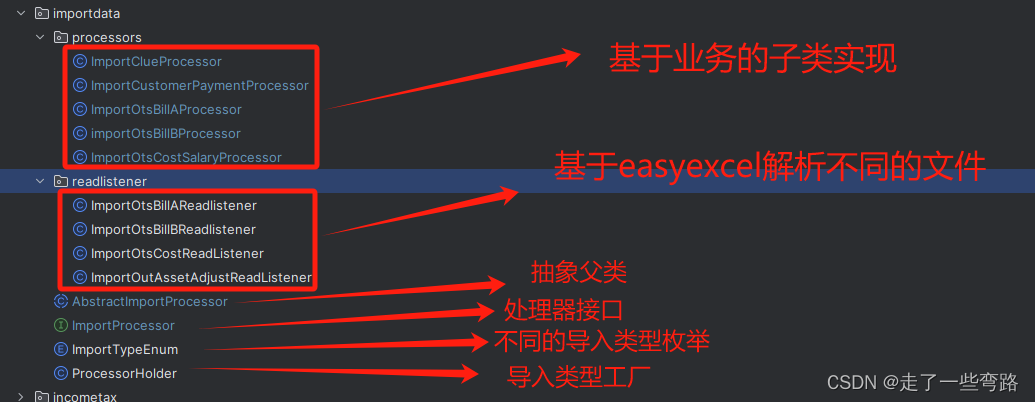
- 3.2 工厂模式
- 3.2.1 标识子类的枚举`ImportTypeEnum`
- 3.2.2 工厂类`ProcessorHolder`
- 3.2.3 工厂类的调用
- 4. 特别关注的点
- 4.1 EasyExcel的使用
- 4.1.1. ReadListener
- 4.1.2 Excel实体字段类型转换问题
- 4.2 规则引擎的使用
- 总结
1.业务背景
对于一个内部使用的交付系统来说,业务场景大多需要录入数据,时常的导入Excel业务数据是常态,交付人员通过批量的导入业务数据替代页面表单录入,可大幅提升工作效率。
业务的多样性往往也会伴随着个性化的导入Excel逻辑,例如我们的业务系统来说,导入数据场景是最常见的case,而且随着业务的不断发展,场景也在逐步增加。
导入财务数据,导入人员数据,导入众包订单数据,导入外包人员发薪数据等等。导入完毕后需要数据进行校验,然后回显校验结果。
2.业务导入流程
对于我们的业务系统来说,导入数据一般需要以下的步骤:
- 解析Excel
- 校验Excel
- 展示校验结果
- 校验成功后确认导入数据
还需要两类表模型:
1.导入数据的临时表
数据可以多次导入,然后进行校验,只有校验成功的数据才能进入下一步。
2.导入数据的实际业务数据表
导入校验成功后,生成业务数据,如果导入数据有唯一编码,业务数据表只会生成一条
每种业务场景如果都单独写一遍导入流程,再单独建立临时表的话,对于程序员来说无疑是一种折磨。
如何将上述场景流程通用化,当新增导入数据场景时,可以忽略通用部分,只需要聚焦于实际的业务逻辑呢?
3.流程优化
对于复杂的业务场景,如果要做到模块化、低耦合,我理解大部分时候还是需要围绕封装和抽象来进行。
封装不变部分,抽象不变部分来用于后续的拓展。
就本文讨论的业务场景,核心不变的部分是整体的导入流程,无论业务场景怎么多变,数据进入到系统中的如下步骤是固定的。
- 解析Excel
- 校验Excel
- 展示校验结果
- 校验成功后确认导入数据
3.1 模板模式
设计模式中模板模式无疑是解决重复代码的一大利器,应用在当前场景再合适不过了。
主要实现
在父类中定义了算法的骨架,并允许子类在不改变算法结构的前提下重定义算法的某些特定步骤。
设计意图
解决在多个子类中重复实现相同的方法的问题,通过将通用方法抽象到父类中来避免代码重复。
整体代码
通用的临时表模型
所有导入的数据在解析、校验后都会存储到此表中,不同的业务实体转为json后存储在Import_data字段中。
不同的业务表需要根据相应的业务进行创建,此处就不进行展示了。
create table import_data_tmp
(
id bigserial
primary key,
batch_id varchar(50) not null,
operator_id bigint not null,
operation_time timestamp with time zone not null,
line_num bigint,
import_data text not null,
import_result integer,
import_description varchar(500),
create_time timestamp with time zone not null,
update_time timestamp with time zone not null
);
comment on table import_data_tmp is '导入信息临时表';
comment on column import_data_tmp.id is '主键ID';
comment on column import_data_tmp.batch_id is '批次号';
comment on column import_data_tmp.operator_id is '操作人Id';
comment on column import_data_tmp.operation_time is '操作时间';
comment on column import_data_tmp.line_num is '导入文件行号';
comment on column import_data_tmp.import_data is '导入数据';
comment on column import_data_tmp.import_result is '导入结果';
comment on column import_data_tmp.import_description is '导入描述';
comment on column import_data_tmp.create_time is '创建时间';
comment on column import_data_tmp.update_time is '更新时间';
create index import_data_tmp_batch_id
on import_data_tmp (batch_id);
create index import_data_tmp_operator_id
on import_data_tmp (operator_id);
3.1.1 导入处理器接口ImportProcessor
ImportProcessor在此类中,定义抽象父类方法的处理函数ImportResultDTO process(String url, R r);定义一些子类需要自己实现的方法(这些方法也可在抽象父类中定义)。
public interface ImportProcessor<T, R> {
/**
* 核心导入处理流程
* @param url 导入的excel地址
* @param r 请求入参数据
* @return 处理结果
*/
ImportResultDTO process(String url, R r);
/**
* 生成批次号
* @return 批次号
*/
String createBatchId();
/**
* 读取excel数据
* @param r – 请求入参数据
* @return 解析出的数据
*/
List<T> readData(R r);
/**
* 组装需要存储的实体
* @param dataList 解析出的数据
* @param r 请求入参数据
* @return 需要存储的实体
*/
List<ImportDataTmpDO> assembleData(List<T> dataList, R r);
/**
* 导入成功的数据,生成真正的业务数据
* @param batchId 成功的批次号
* @return 导入结果
*/
boolean doImportSuccessData(String batchId);
}
3.1.2 抽象父类 AbstractImportProcessor
核心类AbstractImportProcessor,process方法定义算法骨架,即导入流程。
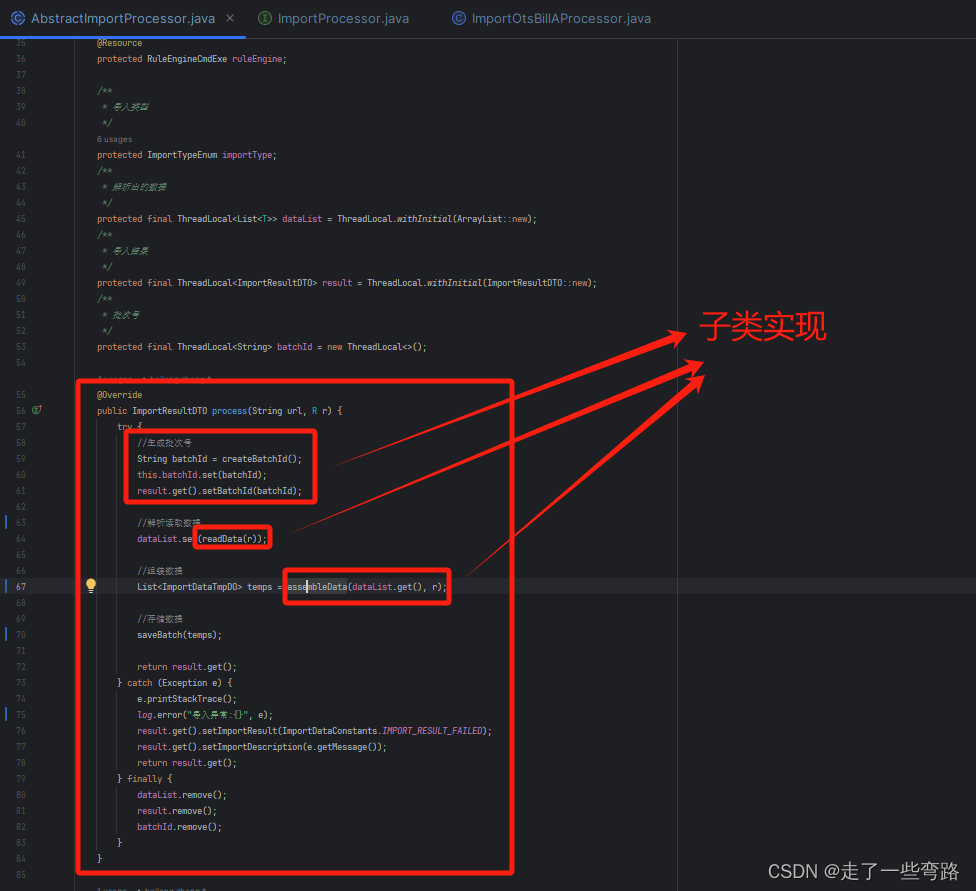
根据不同的业务,子类需要实现的方法。
整体代码如下:
@Component
@Slf4j
public abstract class AbstractImportProcessor<T, R> implements ImportProcessor<T, R> {
@Resource
private ImportDataTmpGateway importGateway;
@Resource
protected DistributeIDGenerator idGenerator;
@Resource
protected RuleEngineCmdExe ruleEngine;
/**
* 导入类型
*/
protected ImportTypeEnum importType;
/**
* 解析出的数据
*/
protected final ThreadLocal<List<T>> dataList = ThreadLocal.withInitial(ArrayList::new);
/**
* 导入结果
*/
protected final ThreadLocal<ImportResultDTO> result = ThreadLocal.withInitial(ImportResultDTO::new);
/**
* 批次号
*/
protected final ThreadLocal<String> batchId = new ThreadLocal<>();
@Override
public ImportResultDTO process(String url, R r) {
try {
//生成批次号
String batchId = createBatchId();
this.batchId.set(batchId);
result.get().setBatchId(batchId);
//解析读取数据
dataList.set(readData(r));
//组装数据
List<ImportDataTmpDO> temps = assembleData(dataList.get(), r);
//存储数据
saveBatch(temps);
return result.get();
} catch (Exception e) {
e.printStackTrace();
log.error("导入异常:{}", e);
result.get().setImportResult(ImportDataConstants.IMPORT_RESULT_FAILED);
result.get().setImportDescription(e.getMessage());
return result.get();
} finally {
dataList.remove();
result.remove();
batchId.remove();
}
}
@Override
public List<T> readData(R r) {
return readDataFromExcel(r);
}
/**
* 组装通用的临时数据表
* @param data 需要转换为json的实体
* @param gigUserId 用户id
* @param batchId 批次编号
* @param lineNum excel行号
* @return 组装完毕的实体
*/
protected ImportDataTmpDO assembleTmp(T data, Long gigUserId, String batchId, Long lineNum) {
ImportDataTmpDO tmp = new ImportDataTmpDO();
tmp.setBatchId(batchId);
tmp.setLineNum(lineNum);
tmp.setOperatorId(gigUserId);
tmp.setOperationTime(Instant.now());
tmp.setImportData(JSONObject.toJSONString(data));
tmp.setImportDescription("");
return tmp;
}
/**
* 使用自定义规则引擎校验数据
* @param context 上下文数据
* @param temp 组装后的数据
*/
protected void checkData(RuleContext<T> context, ImportDataTmpDO temp) {
RuleExecuteResult result = this.ruleEngine.executeRule(context);
temp.setImportResult(ImportDataConstants.IMPORT_RESULT_SUCCESS);
if (result.isRefuse()) {
//拼接校验提示语
temp.setImportResult(ImportDataConstants.IMPORT_RESULT_FAILED);
temp.setImportDescription((temp.getImportDescription() == null ? "" : temp.getImportDescription()) + result.getHitRules().stream().reduce("",(a, b) -> a + b + ";"));
}
}
/**
* 保存数据至通用临时表中
* @param temps 组装后的数据
*/
private void saveBatch(List<ImportDataTmpDO> temps) {
this.importGateway.saveImportTaskTmpBatch(temps);
}
/**
* 读取数据
* @param r 数据
* @return 解析校验后的数据
*/
public abstract List<T> readDataFromExcel(R r);
/**
* 获取数据流
* @param fileUrl 文件存储地址
* @return 数据流
*/
protected InputStream getInputStream(String fileUrl) {
StreamResponseHolder responseHolder = HttpUtils.queryAsStream(HttpUtils.createGet(fileUrl));
return responseHolder.getValue();
}
/**
* 初始化不同的导入处理器到工厂中
*/
@PostConstruct
protected void init() {
ProcessorHolder.putProcessor(importType, this);
}
}
3.1.3 子类实现 ImportDemoProcessor
当新增导入数据场景时,只需要新增一个子类,例如ImportDemoProcessor,继承AbstractImportProcessor,实现相应的方法即可,如下。
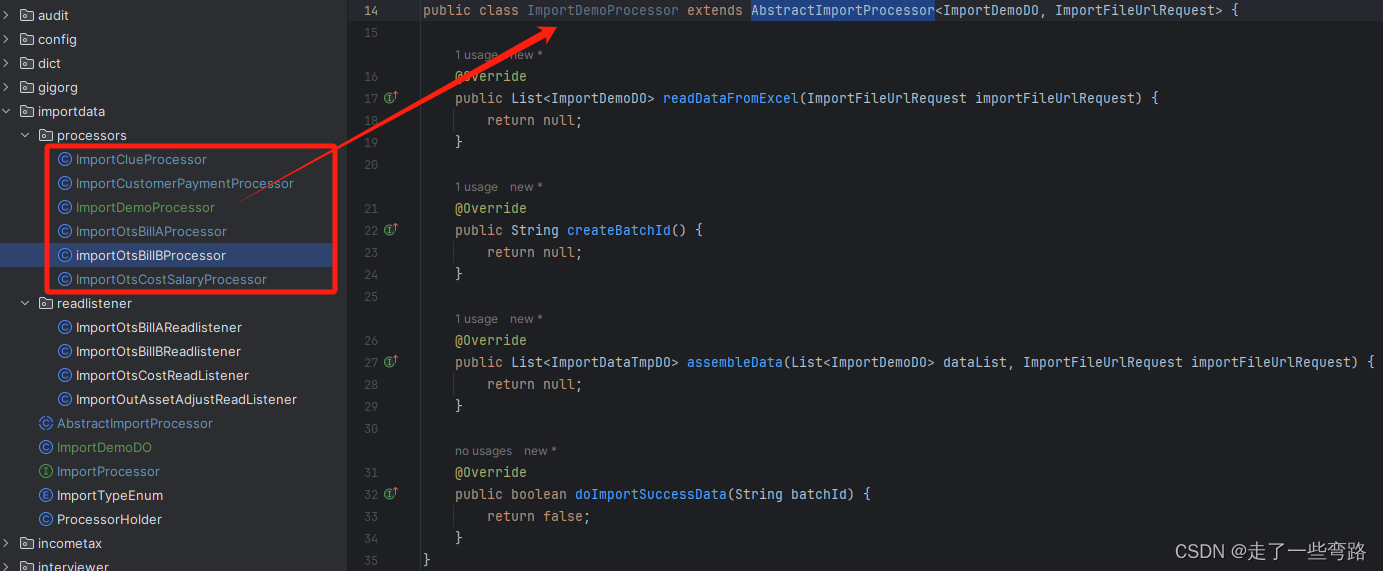
完善后的子类如下。核心实现有两个:
1.从excel中读取数据readDataFromExcel,可以自定义一个DemoReadListener来处理excel解析,一般不包含业务逻辑。
这里借助EasyExcel框架,具体使用可以查看官网https://easyexcel.opensource.alibaba.com/
2.填充业务实体ImportDemoDO,assembleData()方法,其中可以自定义业务逻辑,用于完善字段,比如业务逻辑的校验,可以调用自定义的规则引擎进行校验,规则引擎也是一个单独实现的模块,具体可查看之前我写过的一篇文章。
基于Aviator开发一个简单的规则引擎
@Data
public class ImportDemoDO {
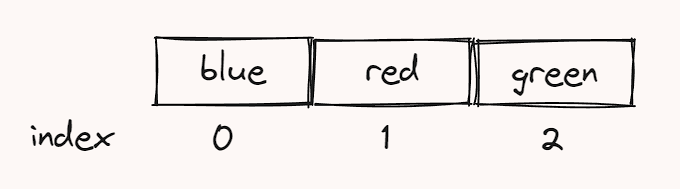
@ExcelProperty(index = 0)
private String userName;
@ExcelProperty(index = 1)
private String address;
@ExcelProperty(index = 2, converter = BigDecimalConverter.class)
private BigDecimal salary;
/**
* 行号 用于前端的展示
*/
private Long lineNum;
}
public class ImportDemoProcessor extends AbstractImportProcessor<ImportDemoDO, ImportFileUrlRequest> {
/**
* 每次导入的批次号前缀
*/
private static final String IMPORT_PREFIX = "DEMO";
/**
* 导入excel的表头列数限制
*/
private static final Integer HEAD_SIZE = 6;
/**
* 具体的业务表基础层处理
*/
private final DemoGateway demoGateway;
private final ImportDataTmpGateway tempGateway;
public ImportDemoProcessor(DemoGateway demoGateway, ImportDataTmpGateway tempGateway) {
this.demoGateway = demoGateway;
this.tempGateway = tempGateway;
//定义一个业务导入类型ImportTypeEnum.DEMO,会在父类的init方法中添加进导入类型工厂中
this.importType = ImportTypeEnum.DEMO;
}
@Override
public List<ImportDemoDO> readDataFromExcel(ImportFileUrlRequest request) {
//使用EasyExcel读取数据,其中DemoReadListener可以对读取解析过程自定义一些处理
return EasyExcel.read(this.getInputStream(request.getUrl()),
ImportBillTypeADO.class,
new DemoReadListener(HEAD_SIZE)
).headRowNumber(3).sheet().doReadSync();
}
@Override
public String createBatchId() {
//生成唯一batchId
return IMPORT_PREFIX + idGenerator.nextId();
}
@Override
public List<ImportDataTmpDO> assembleData(List<ImportDemoDO> dataList, ImportFileUrlRequest request) {
List<ImportDataTmpDO> temps = new ArrayList<>();
dataList.forEach(data -> {
... 可以根据不同的业务逻辑,填充实体
//组装ImportDataTmpDO
ImportDataTmpDO tmp = assembleTmp(data, request.getStaffId(), batchId.get(), data.getLineNum());
//调用规则引擎校验excel数据,规则引擎的实现可以翻看之前的文章
checkData(data, tmp);
temps.add(tmp);
});
return temps;
}
@Override
public boolean doImportSuccessData(String batchId) {
//校验是否有失败的数据
int failedCounts = this.tempGateway.count(batchId, Collections.singletonList(ImportDataConstants.IMPORT_RESULT_FAILED));
if (failedCounts > 0) {
throw new ContractBaseException(ResponseCodeEnum.DATA_ERROR);
}
List<ImportDataTmpDO> list = this.tempGateway.listImportDataTmp(batchId);
List<DemoDO> dataList = convert2DemoDataList(list);
//存储业务数据
this.demoGateway.saveBatch(dataList);
return false;
}
private void checkData(ImportDemoDO data, ImportDataTmpDO tmp) {
RuleContext<ImportDemoDO> context = new RuleContext<>();
context.setRuleTypes(Arrays.asList(RuleTypeEnum.DEMO));
context.setData(data);
checkData(context, tmp);
}
}
3.2 工厂模式
前文中,细心的童鞋应该已经发现在抽象父类中有个init()方法,会初始化所有的子类注册到工厂ProcessorHolder中。
3.2.1 标识子类的枚举ImportTypeEnum
@Getter
public enum ImportTypeEnum {
... 省略其他的业务处理枚举
DEMO(40,"DEMO测试"),
;
private final int value;
private final String message;
ImportTypeEnum(int value, String message) {
this.value = value;
this.message = message;
}
/**
* 整形值转换为枚举类
*
* @param value 值
* @return 枚举类
*/
public static ImportTypeEnum valueOf(int value) {
for (ImportTypeEnum anEnum : values()) {
if (value == anEnum.getValue()) {
return anEnum;
}
}
return null;
}
}
3.2.2 工厂类ProcessorHolder
public final class ProcessorHolder {
private static Map<ImportTypeEnum, ImportProcessor> processors = new HashMap<>(64);
public static void putProcessor(ImportTypeEnum bizType, ImportProcessor handler) {
processors.put(bizType, handler);
}
public static ImportProcessor getProcessor(ImportTypeEnum bizType) {
ImportProcessor importProcessor = processors.get(bizType);
if (importProcessor == null) {
throw new ContractBaseException(ResponseCodeEnum.IMPORT_TYPE_NOT_EXISTS);
}
return importProcessor;
}
}
3.2.3 工厂类的调用
在service层中,基于不同的业务场景,使用ImportTypeEnum从工厂中获取对应的实现。
例如:
public ImportResultDTO importDemoFile(ImportFileUrlRequest request) {
return ProcessorHolder.getProcessor(ImportTypeEnum.DEMO).process(request.getUrl(), request);
}
4. 特别关注的点
4.1 EasyExcel的使用
相对于自己封装解析Excel的方法来说,EasyExcel挺好用的,方便且功能全面,是一个比较成熟的框架。
4.1.1. ReadListener
对于不同的Excel数据,可以实现ReadListener可以在解析开始、解析过程、解析后自定义解析逻辑。

当然,最简单的读取Excel场景,也无需上述ReadListener,只需要一行代码就可以搞定。
EasyExcel.read(this.getInputStream(request.getUrl())).headRowNumber(3).sheet().doReadSync();
4.1.2 Excel实体字段类型转换问题
很多时候,用户在使用Excel文件时会给你一个惊喜,比如在应该填数值类型的字段填上了奇怪的字符,这种情况下Excel会在第一步读取的时直接就失败了。
对于上述场景我们可以实现Convert,来处理字段类型转换异常问题。
如下BigDecimalConverter
@Slf4j
public class BigDecimalConverter implements Converter<BigDecimal> {
@Override
public BigDecimal convertToJavaData(ReadCellData<?> cellData, ExcelContentProperty contentProperty, GlobalConfiguration globalConfiguration) throws Exception {
if (cellData.getNumberValue() != null) {
return cellData.getNumberValue();
}
if (StrUtil.isNotBlank(cellData.getStringValue())) {
try {
return NumberUtils.parseBigDecimal(cellData.getStringValue(), contentProperty);
} catch (Exception e) {
log.info("excel列转换异常:{}", e.toString());
return null;
}
}
return null;
}
}
4.2 规则引擎的使用
再次给大家安利下我们项目中轻量级规则引擎的实现,可查看下文。
基于Aviator开发一个简单的规则引擎
对于不同的业务导入场景,可在规则引擎中配置json文件,结合自定义function,对Excel中的数据进行业务层面的校验。
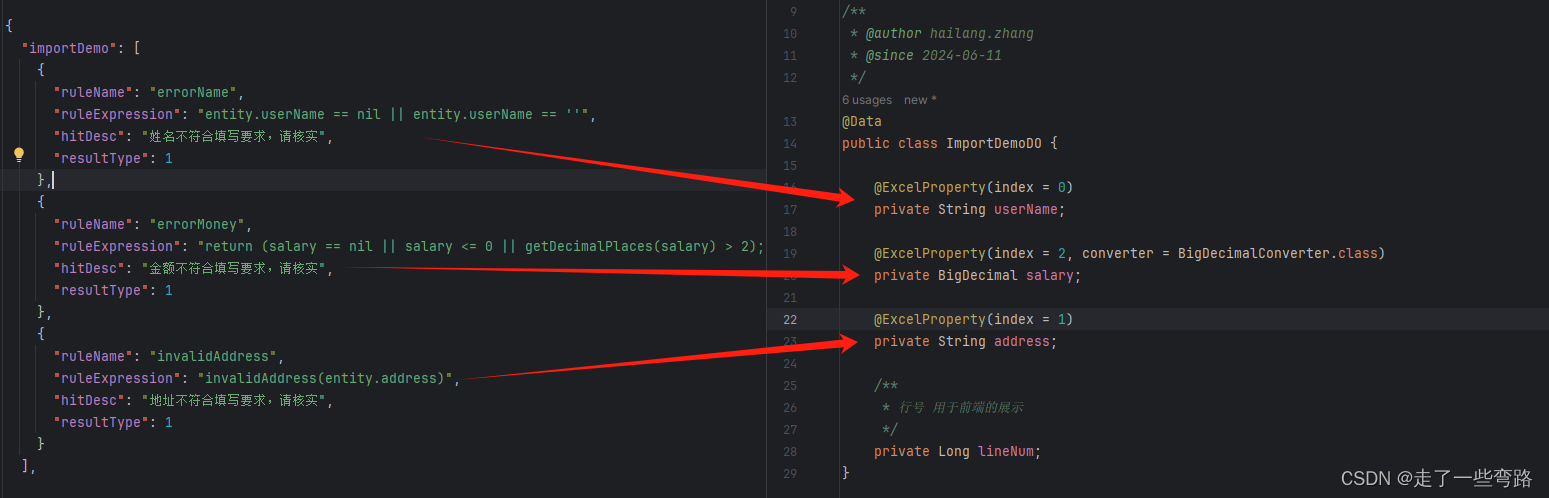
总结
经过通用化改造后,我们封装了通用的Excel导入流程,并且对于可变部分进行了抽象,对新增的业务导入流程开发,开发中只需关注业务逻辑,而无需处理导入流程。
新增流程时只需关注如下几点:
- 定义一个新的
ImportTypeEnum枚举。 - 继承抽象父类
AbstractImportProcessor,例如上述中的ImportDemoProcessor,实现业务逻辑。 - 按需实现
ReadListener。 - 按需调用规则引擎。
- service层使用只需要一行代码:
ProcessorHolder.getProcessor(ImportTypeEnum.DEMO).process(request.getUrl(), request);






![数据库错误[ERR] 1071 - Specified key was too long; max key length is 1000 bytes](https://img-blog.csdnimg.cn/direct/868f4cf31d2642d18c2a26bf246c16d3.png)