上一篇文章中,某互联网银行零售信贷风险建模专家使用数据科学平台Altair RapidMiner——完成了数据探索工作,《可视化数据科学平台在信贷领域应用系列一:数据探索》。本次这位建模专家再次和大家分享数据准备的第二步骤,数据清洗。

首先,让我们一起来看下他的数据清洗心得,以及如何高效的利用工具完成数据清洗工作。认识“数据清洗”
为什么需要“数据清洗”?
在进行机器学习建模时,数据清洗是必不可少的步骤。数据清洗的目的是确保数据的准确性、完整性和一致性,提升数据集的数据质量,提高机器学习模型的性能。
数据清洗的必要性主要体现在以下两个方面:
-
正确有效的模型离不开数据清洗。数据中的缺失值、异常值和错误数据均会影响模型的准确性,甚至导致模型错误,数据质量是模型质量的基础保证。通过数据清洗步骤校正或排除这些数据,提升数据质量和可靠性,排除无效数据对模型造成的扰动,有效提升模型的泛化能力。
-
数据清洗可提高模型开发效率。数据中异常值和错误数据会导致模型开发的效率降低。正所谓“磨刀不误砍柴工”,完整的数据清洗工作有效提升后续特征衍生和模型开发的效率。
如何进行“数据清洗”?
数据清洗是建立可靠模型的关键步骤,它确保了模型在训练和应用阶段的准确性和稳定性。
数据清洗的主要步骤包括:
-
数据检查:首先要对数据进行检查,了解数据的总体情况,包括数据的类型、格式、完整性、集中度等。
-
数据转换:根据机器学习模型对训练数据的要求,对数据类型进行转换适配,例如将类别型数据转换为数值型数据或进行数值编码。
-
数据清理:基于数据检查的结果,对数据进行清理,包括缺失值、异常值、重复值、错误值。
利用RapidMiner 的Turbo Prep模块进行数据清洗
数据清洗是信用模型开发数据准备工作的重要内容。数据清洗工作的主要内容有以下几个方面。
-
我们从数据库提取的数据集通常会因为各种原因存在种种问题,应对特征值缺失、重复数据等错误数据进行修正或剔除,提升数据准确性。
-
数据集中的特征质量不一,存在高集中度、高相关性等问题,也应当在数据清洗环节对低质量特征进行排除。实践中,对于集中度超过95%、相关系数大于0.8的特征应当剔除。
-
为适配不同类型的模型,应当对特定类型的特征进行编码或转码。对于评分卡模型,应当对连续性特征进行离散化处理,又称“分箱”,离散化增强了特征的稳定性,提升了模型的泛化能力。而对于限定连续型特征入模的模型,则应将类别型特征进行编码,使之适配模型入模要求。
我们沿用上一节采用的UCI台湾信用卡数据集,数据检查工作我们已经在探索性数据分析一篇中完成,对数据集有了整体认识,也知晓了各特征列的特点。下面我们运用RapidMiner来实操数据转换和数据清理工作。
01、TRANSFORM 数据转换
首先看一下数据转换(TRANSFORM)模块所支持的操作,包括了重命名(RENAME)、改变类型(CHANGE TYPE)、删除(REMOVE)、拷贝(COPY)、筛选(FILTER)、范围截取(RANGE)、采样(SAMPLE)、排序(SORT)、替换(REPLACE)和拆分(SPLIT)。
应用数据转换(TRANSFORM)模块可实现数据集的灵活变换,融合多个基本操作的组合可完成更复杂的数据变换处理。
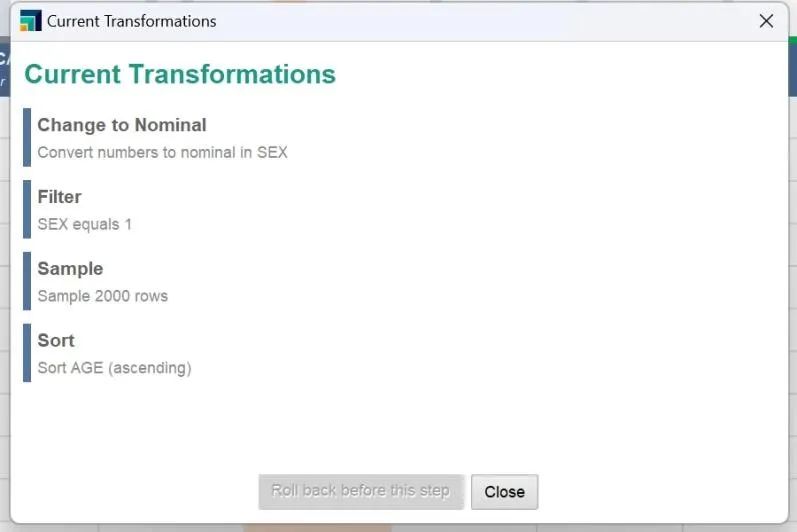
图1:数据变换操作记录
例如,我们希望将性别为“1-男”的数据筛选出来,随机抽样2000条记录并按照年龄排序,将FILTER、SAMPLE、SORT组合运用即可。如图1,RM会将所有的操作记录储存下来,以便用户查看或进行回退操作。
实践中,基于数据检查和探索性分析的结果,我们可以借助数据转换(TRANSFORM)模块实现对数据表的加工变换,排除掉异常值和错误数据。
02、CLEANSE 数据清洗
数据清洗(CLEANSE)支持对数据集进行多项清洗操作,包括移除低质量特征(REMOVE LOW QUALITY)、移除相关特征(REMOVE CORELATED)、缺失值填充(REPLACE MISSING)、标准化(NORMALIZATION)、离散化(DISCRETIZATION)、哑变量编码(DUMMY ENCODING),主成分分析(PCA)、去重(REMOVE DUPLICATES),涵盖了数据清洗的所有常规操作。
重点介绍一下自动清洗(AUTO CLEANSING),RapidMiner可以自动对数据集执行数据清理,自动化地完成数据清洗为机器学习建模做好准备,对新手用户或者业务人员十分友好。
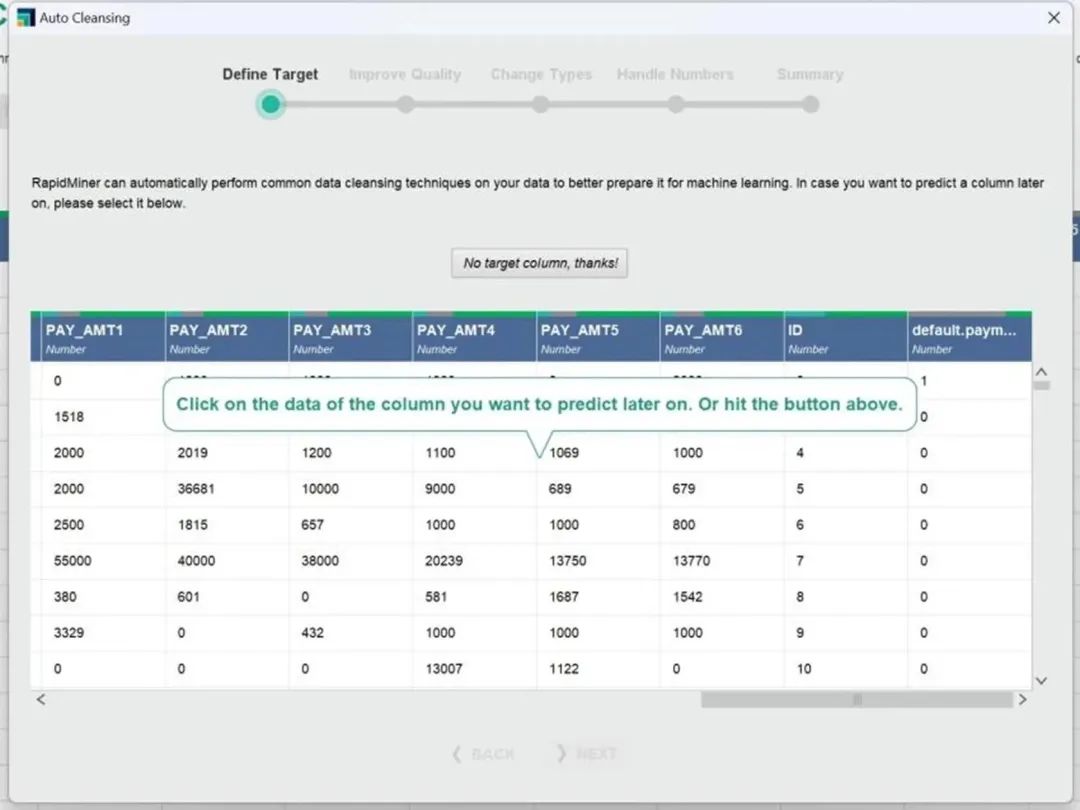
图2:自动清洗(AUTO CLEANSING)
如图2所示,仅需几个简单的操作步骤即可完成数据清洗。RapidMiner还提供了两种可能提高数值列质量的选项可供选择,主成分分析(PCA,Principal Component Analysis,一种通过将数据点映射到一个新空间来减少数据维数的方法)和归一化(通常有助于使所有列的范围大致相同,排除量纲对模型的影响)。
针对信贷风控建模,移除相关特征(REMOVE CORELATED)和离散化(DISCRETIZATION)这两个操作就必须要聊聊了。
移除相关特征,通常设定相关系数筛选阈值0.8,过滤掉高相关性特征中 iv 较低的特征。过滤高相关特征,可有效避免高相关特征在模型训练过程中耦合干扰,使开发的模型更加健壮,增强了模型的线上运行稳定性。
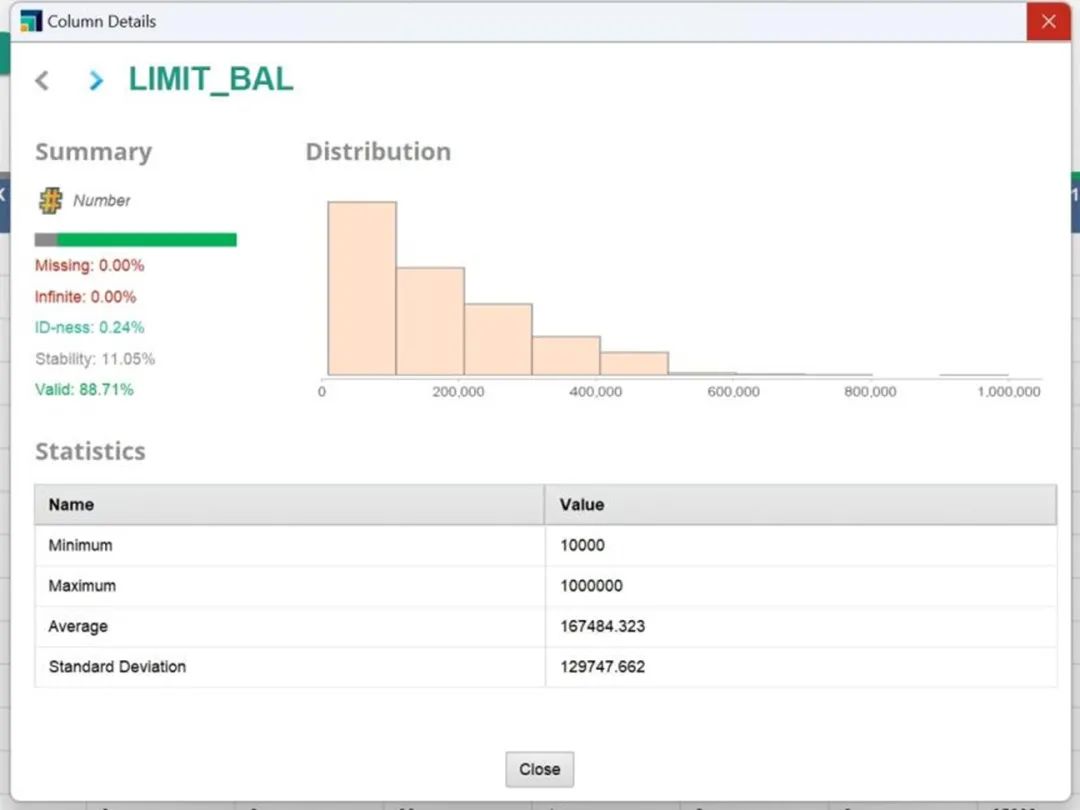
图3 用户信用额度原始分布
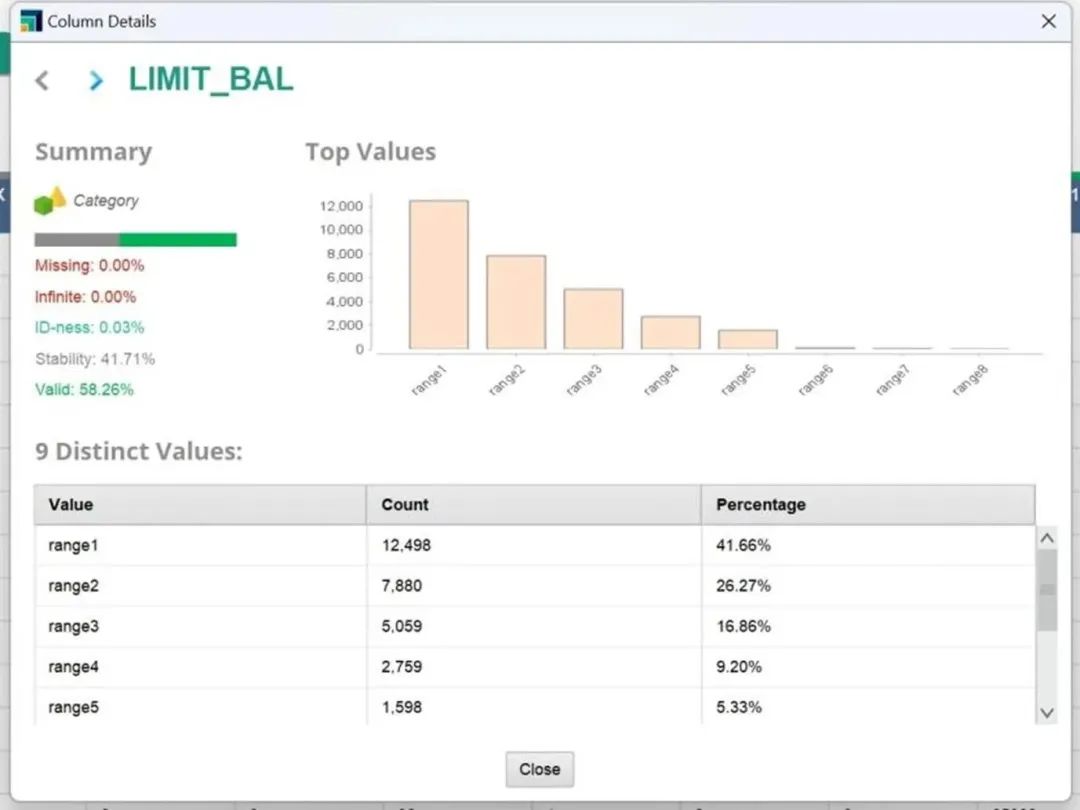
图4 用户信用额度分箱后分布
通过离散化(DISCRETIZATION)将连续型特征进行“分箱”操作,RM内置了“等距分箱”和“等频分箱”,用户可按需设定分箱箱数。如图3和图4,经过离散化操作,我们将特征“信用额度”从连续性特征“等距分10箱”得到了新的分组类别特征,增强了特征稳定性,排除了极端值和噪声值对模型的影响,增强了模型稳定性和泛化能力。
如何看待RapidMiner?
数据清洗是非标工作,但 Altair RapidMiner 在数据清洗过程中,能够很大的提效,有鲜明的优势特点:
-
数据转换与清洗功能模块完备:无论是在数据转换还是数据清洗模块中,RM所能够支持的基本操作十分完备,通过组合操作可完成数据清洗相关的工作内容,操作简洁灵活高效。
-
自动化数据清洗:RapidMiner 的AUTO CLEANSING提供了极为简化的数据清洗自动化执行模块,非专业数据科学家亦可在RM的提示下快速完成数据清洗工作。
若您对数据分析以及人工智能感兴趣,想要站在全球视野看待人工智能的发展,
一定不要错过6月20日面向工程师的全球人工智能线上会议“AI for Engineers”,
会议将邀请全球知名专家与权威学者,共同探讨生成式人工智能(GenAI) 如何助力产品设计研发
点击立即免费报名
关于 Altair RapidMiner
Altair RapidMiner 数据分析与人工智能平台,是 Altair 澳汰尔公司旗下仿真、HPC 和数据分析三块主营业务中的解决方案,它在数据分析领域最早实现将自动化数据科学、文本分析、自动特征工程和深度学习等多种功能同时集成的一站式数据分析平台,帮助用户解决从数据清洗、准备、数据科学建模到模型管理和部署,同时又支持数据和流数据的实时分析可视化的数据分析平台。
欲了解更多信息,欢迎访问:
www.altair.com.cn