解析软中断引起的调度延迟问题
- 一、导言
- 二、线程调度的原理
- 三、如何定位中断导致的调度延迟
-
- 方法一:使用内核 ftrace工具
- 方法二:使用开源ko工具
- 方法三:修改内核源码添加打印
一、导言
硬件中断和软件中断都有可能导致调度延迟,但两者的影响方式略有不同。
硬件中断:当硬件设备发送中断请求时,CPU 会立即响应中断并执行对应的中断处理程序。在处理硬件中断时,CPU 会暂时中断当前任务的执行,切换到中断处理程序,处理完中断后再切换回原任务。硬件中断有可能打断正在执行的任务,引起调度延迟。
软件中断:软件中断是由软件程序触发的中断,通常是通过系统调用或软中断指令来实现。软件中断不像硬件中断那样突然而来,一般在优先级比较低,不会立即打断正在执行的任务。但是,软件中断也需要处理,其处理过程可能会影响调度和任务切换。
在处理硬件中断或软件中断时,操作系统需要适时地调度和管理中断处理程序的执行,以及恢复被打断的任务的执行。如果中断处理程序执行时间过长或调度机制不够高效,就有可能导致调度延迟,影响系统的响应性能和实时性能。
二、线程调度的原理
在 Linux 中,线程调度的原理是通过内核的调度器(Scheduler)来实现的。Linux 内核中的调度器负责决定在多个就绪状态的任务中选择哪个任务来运行,并在何时进行任务切换。Linux 的调度器采用抢占式调度(Preemptive Scheduling),即操作系统会根据一定的调度策略主动地进行进程(包括线程)的切换,以确保系统资源的合理利用和响应性能。
Linux 线程调度器通常会在以下情况下进行线程调度:
-
当一个线程主动放弃 CPU(例如调用了 sleep()、yield()、sched_yield() 等),使当前线程从运行状态切换到就绪状态时,调度器会根据调度策略选择就绪队列中的下一个任务来运行。
-
当一个线程的时间片用尽,需要被调度器挂起以便切换到另一个任务时,调度器会将当前线程放到就绪队列的末尾,然后选择另一个任务来执行。
-
当一个线程因为等待某个事件而被阻塞时(如等待 I/O 完成),调度器会从就绪队列中选择另一个可运行的任务来执行。
-
当一个高优先级的进程或线程需要执行时,调度器会挂起当前运行的低优先级任务,以确保高优先级任务得到及时响应。
-
当发生硬件中断时,调度器可能会对当前运行的任务进行抢占,以便执行中断处理程序。
总的来说,Linux 线程调度器会根据调度策略和就绪队列中的任务情况来动态地进行任务切换,以提高系统的资源利用率和响应速度。Linux 的调度策略可以通过设置调度器的参数和调度类别来进行调整,以满足不同场景下的需求。
在 Linux 中,需要周期性地检查各个线程状态并进行调度操作的触发条件通常是与时钟中断(Timer Interrupt)相关联的。时钟中断是操作系统中的一个重要机制,用于定时触发中断并告知内核当前时间已经过去,以便操作系统进行一些必要的处理,比如更新系统时间、检查线程状态、执行调度等。涉及到时钟中断处理和调度操作的函数包括:
- tick_handle_periodic:这个函数用于处理定时器子系统生成的周期性时钟中断,并负责更新系统时间、执行调度器的调度操作等。这个函数位于kernel/time/tick-common.c 文件中。
- scheduler_tick:这个函数是调度器模块中用于响应时钟中断事件的函数,负责在时钟中断发生时执行调度操作,包括检查各个线程的状态、进行线程调度等。这个函数根据不同的调度器(例如CFS 调度器)可能会有所不同,需要查看具体的调度器实现。
- 各个调度器特定的调度函数:不同的调度器模块(如 CFS、RT等)会有自己的调度函数,用于在时钟中断发生时进行相应的调度操作。这些函数通常在 kernel/sched/ 目录下。
三、如何定位中断导致的调度延迟
方法一:使用内核 ftrace工具
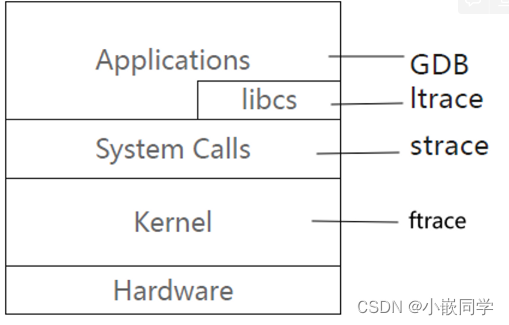
ftrace 是 Linux 内核提供的一个功能丰富的跟踪工具,用于帮助开发人员和系统管理员跟踪和调试内核和用户空间程序的性能和行为。ftrace 可以跟踪内核函数的调用关系、事件发生时序、中断处理等,以帮助诊断和优化系统性能。
以下是 ftrace 工具的一些主要特点和用途:
-
函数跟踪(Function Tracing):ftrace 可以跟踪内核函数的调用关系,包括函数的调用次数、执行时间等信息,帮助开发人员了解内核函数的执行情况。
-
事件跟踪(Event Tracing):ftrace 支持跟踪系统各种事件的发生时序,比如中断发生、进程切换等,帮助分析系统的行为和性能瓶颈。
-
深度跟踪(Deep Tracing):ftrace 可以跟踪更底层的操作,比如跟踪硬件事件、内核函数的参数等,帮助深入了解系统内部运行机制。
-
动态追踪(Dynamic Tracing):ftrace 允许用户在运行时配置跟踪参数和事件,实现动态地调整跟踪范围和精度。
-
性能分析和优化:通过使用 ftrace,开发人员可以快速诊断系统性能问题、分析系统瓶颈,并进行优化。
-
轻量级和低开销:ftrace 在设计上尽可能减小对系统性能的影响,可以在生产环境中使用。
ftrace 工具利用了 Linux 内核的功能,通过在内核中插入跟踪事件和钩子,来实现对系统行为的跟踪和分析。使用 ftrace 可以帮助开发人员更好地了解系统内部的运行情况,快速解决问题并进行性能优化。
关于ftrace的配置和使用方法,如何利用其进行问题排查,我找了几篇博客学习了下可以解决我们的需求,分享给大家(不重复制造垃圾,没太大意义):
linux内核:ftrace——追踪内核行为
【一文秒懂】Ftrace系统调试工具使用终极指南
irqs跟踪器
方法二:使用开源ko工具
Linux系统中,在执行硬件中断以及软件中断前都先会关闭中断,避免中断执行过程中被打断,所以某种程度而言,可以认为中断关闭操作伴随着中断的处理过程,所以我们可以借助这个原理来追溯中断;
下面链接是字节跳动的一个开源项目ko,我自己使用过,很不错,分享给大家;源码我自己看过加了一些注释,分享一个注释版本;
Kernel trace tools(一):中断和软中断关闭时间过长问题追踪
// SPDX-License-Identifier: GPL-2.0
/*
* Trace Irqsoff
*
* Copyright (C) 2020 Bytedance, Inc., Muchun Song
*
* The main authors of the trace irqsoff code are:
*
* Muchun Song <songmuchun@bytedance.com>
*/
#define pr_fmt(fmt) "trace-irqoff: " fmt
#include <linux/hrtimer.h>
#include <linux/irqflags.h>
#include <linux/kernel.h>
#include <linux/kallsyms.h>
#include <linux/module.h>
#include <linux/percpu.h>
#include <linux/proc_fs.h>
#include <linux/seq_file.h>
#include <linux/sizes.h>
#include <linux/stacktrace.h>
#include <linux/timer.h>
#include <linux/uaccess.h>
#include <linux/kprobes.h>
#include <linux/version.h>
#include <asm/irq_regs.h>
#if LINUX_VERSION_CODE < KERNEL_VERSION(4, 10, 0)
#include <linux/sched.h>
#else
#include <linux/sched/clock.h>
#endif
#define MAX_TRACE_ENTRIES (SZ_1K / sizeof(unsigned long))
#define PER_TRACE_ENTRIES_AVERAGE (8 + 8)
#define MAX_STACE_TRACE_ENTRIES \
(MAX_TRACE_ENTRIES / PER_TRACE_ENTRIES_AVERAGE)
#define MAX_LATENCY_RECORD 10
#if LINUX_VERSION_CODE < KERNEL_VERSION(5, 6, 0)
#ifndef DEFINE_SHOW_ATTRIBUTE
#define DEFINE_SHOW_ATTRIBUTE(__name) \
static int __name ## _open(struct inode *inode, struct file *file) \
{
\
return single_open(file, __name ## _show, inode->i_private); \
} \
\
static const struct file_operations __name ## _fops = {
\
.owner = THIS_MODULE, \
.open = __name ## _open, \
.read = seq_read, \
.llseek = seq_lseek, \
.release = single_release, \
}
#endif /* DEFINE_SHOW_ATTRIBUTE */
#define IRQ_OFF_DEFINE_SHOW_ATTRIBUTE DEFINE_SHOW_ATTRIBUTE
#else /* LINUX_VERSION_CODE */
#define IRQ_OFF_DEFINE_SHOW_ATTRIBUTE(__name) \
static int __name ## _open(struct inode *inode, struct file *file) \
{
\
return single_open(file, __name ## _show, inode->i_private); \
} \
\
static const struct proc_ops __name ## _fops = {
\
.proc_open = __name ## _open, \
.proc_read = seq_read, \
.proc_lseek = seq_lseek, \
.proc_release = single_release, \
}
#endif /* LINUX_VERSION_CODE */
static bool trace_enable;
/**
* Default sampling period is 10000000ns. The minimum value is 1000000ns.
*/
static u64 sampling_period = 10 * 1000 * 1000UL;
/**
* How many times should we record the stack trace.
* Default is 50000000ns.
*/
static u64 trace_irqoff_latency = 50 * 1000 * 1000UL;
struct irqoff_trace {
unsigned int nr_entries;
unsigned long *entries;
};
struct stack_trace_metadata {
u64 last_timestamp;
unsigned long nr_irqoff_trace;
struct irqoff_trace trace[MAX_STACE_TRACE_ENTRIES];
unsigned long nr_entries;
unsigned long entries[MAX_TRACE_ENTRIES];
unsigned long latency_count[MAX_LATENCY_RECORD];
/* Task command names*/
char comms[MAX_STACE_TRACE_ENTRIES][TASK_COMM_LEN];
/* Task pids*/
pid_t pids[MAX_STACE_TRACE_ENTRIES];
struct {
u64 nsecs:63;
u64 more:1;
} latency[MAX_STACE_TRACE_ENTRIES];
};
struct per_cpu_stack_trace {
struct timer_list timer;
struct hrtimer hrtimer;
struct stack_trace_metadata hardirq_trace;
struct stack_trace_metadata softirq_trace;
bool softirq_delayed;
};
static struct per_cpu_stack_trace __percpu *cpu_stack_trace;
#if LINUX_VERSION_CODE < KERNEL_VERSION(5, 1, 0)
static void (*save_stack_trace_skip_hardirq)(struct pt_regs *regs,
struct stack_trace *trace);
/**
* stack_trace_skip_hardirq_init - 初始化用于跳过硬中断堆栈跟踪的符号地址
*
* 本函数旨在查找并保存名为"save_stack_trace_regs"的内核符号的地址。
* 这样做的目的是为了在后续的堆栈跟踪操作中,能够跳过硬中断处理程序的上下文,
* 提供更准确的堆栈信息,特别是对于调试内核问题时非常有用。
*
* 注意:此函数使用inline定义,意味着它应该在调用点被内联展开,
* 以减少函数调用的开销。此外,函数声明为静态,意味着它只在当前文件中可见。
*/
static inline void stack_trace_skip_hardirq_init(void)
{
/* 通过kallsyms_lookup_name函数查找并保存符号"save_stack_trace_regs"的地址 */
save_stack_trace_skip_hardirq =
(void *)kallsyms_lookup_name("save_stack_trace_regs");
}
/**
* store_stack_trace - 获取并存储堆栈跟踪信息
* @regs: 寄存器状态指针,用于获取调用点的上下文信息
* @trace: 用于存储堆栈跟踪结果的结构体指针
* @entries: 用于存储堆栈地址的数组指针
* @max_entries: entries数组的最大容量
* @skip: 跳过的前几层堆栈帧,通常是为了避开特定的调用点
*
* 此函数用于在中断或异常发生时收集并存储堆栈跟踪信息。它首先初始化一个
* stack_trace结构体,然后根据是否在中断上下文中调用,选择不同的方法来
* 保存堆栈信息。最后,它将收集到的堆栈跟踪信息存储到提供的trace结构体中。
*
* 注意:某些架构会在堆栈跟踪的末尾添加ULONG_MAX来表示这是一个完整的跟踪,
* 但这种做法可能会导致一个完全填满的跟踪被错误地报告为不完整。
*/
static inline void store_stack_trace(struct pt_regs *regs,
struct irqoff_trace *trace,
unsigned long *entries,
unsigned int max_entries, int skip)
{
struct stack_trace stack_trace;
/* 初始化堆栈跟踪结构体 */
stack_trace.nr_entries = 0;
stack_trace.max_entries = max_entries;
stack_trace.entries = entries;
stack_trace.skip = skip;
/* 根据是否在中断上下文中,选择合适的函数来保存堆栈跟踪 */
if (regs && save_stack_trace_skip_hardirq)
save_stack_trace_skip_hardirq(regs, &stack_trace);
else
save_stack_trace(&stack_trace);
/* 将收集到的堆栈跟踪信息存储到trace结构体中 */
trace->entries = entries;
trace->nr_entries = stack_trace.nr_entries;
/*
* 如果堆栈跟踪的最后一个条目是ULONG_MAX,则认为它是一个填充项,
* 并将其从跟踪长度中移除。这是为了处理某些架构的特殊表示方法。
*/
/*
* Some daft arches put -1 at the end to indicate its a full trace.
*
* <rant> this is buggy anyway, since it takes a whole extra entry so a
* complete trace that maxes out the entries provided will be reported
* as incomplete, friggin useless </rant>.
*/
if (trace->nr_entries != 0 &&
trace->entries[trace->nr_entries - 1] == ULONG_MAX)
trace->nr_entries--;
}
#else
static unsigned int (*stack_trace_save_skip_hardirq)(struct pt_regs *regs,
unsigned long *store,
unsigned int size,
unsigned int skipnr);
#if LINUX_VERSION_CODE < KERNEL_VERSION(5, 6, 0)
static inline void stack_trace_skip_hardirq_init(void)
{
stack_trace_save_skip_hardirq =
(void *)kallsyms_lookup_name("stack_trace_save_regs");
}
#else