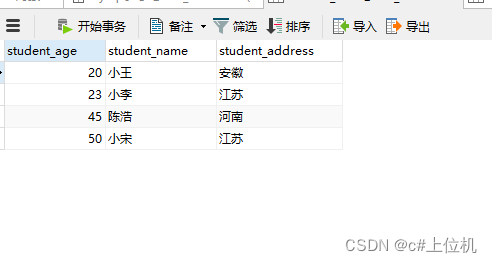
LDA简析
最明显的特征是能够将若干文档自动编码分类为一定数量的主题(注意:主题的数量需要人为指定)。设定好主题数量之后,运行LDA模型就会得到每个主题下边词语的发布概率以及文档对应的主题概率。
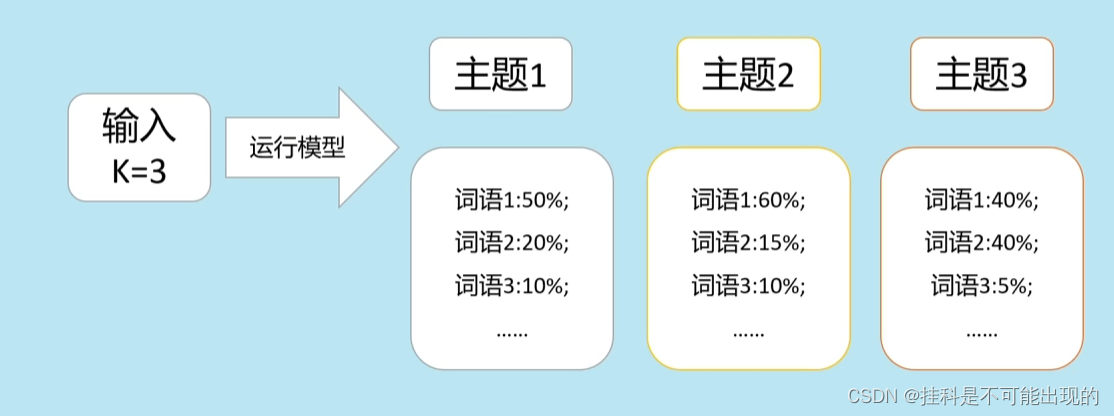

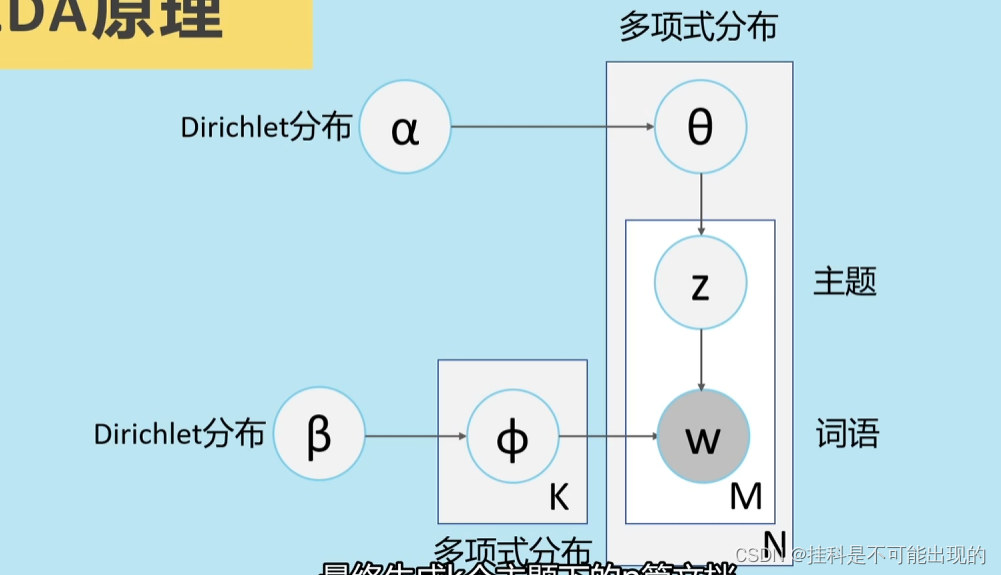
LDA原理
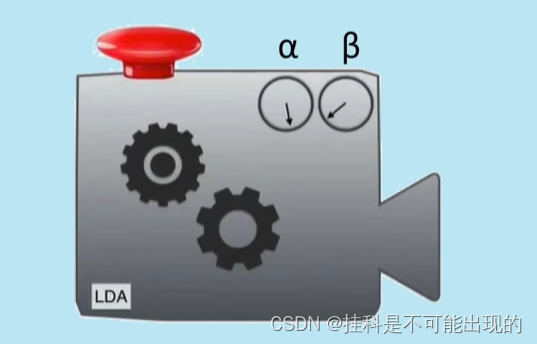
LDA的工作原理 可把它比作上图中的机器 当我们确定主题数量之后,就可以通过设定机器上这两个旋钮α和β的参数值来控制这两个齿轮的工作状态最终随机生成一篇文档。(注意:这篇文章 它是随机生成的新的文档和原文档没有关系)

通过对比这篇文档与原文档的相似性,我们就可以判断这个模型的好坏(注意:随机生成的新文档不是最终的目的,最重要的是通过对比新旧文档来判断模型的好坏然后在不同参数的很多模型中找到最优的模型,也就是找到最佳的α和β的值)
α和β如何调动模型内部的工作
α和β分别控制一个狄利克雷分布。第一步:α随机生成文档对应主题的多项式分布θ。第二步:θ随机生成一个主题z。第三步:β随机生成主题对应词语的多项式分布φ。第四步:综合主题z和主题对应词语分布情况φ生成词语w。 如此循环生成一个文档,包含m个词语,最终生成k个主题下的n篇文档。这个模型的训练采用的是吉布斯采样。