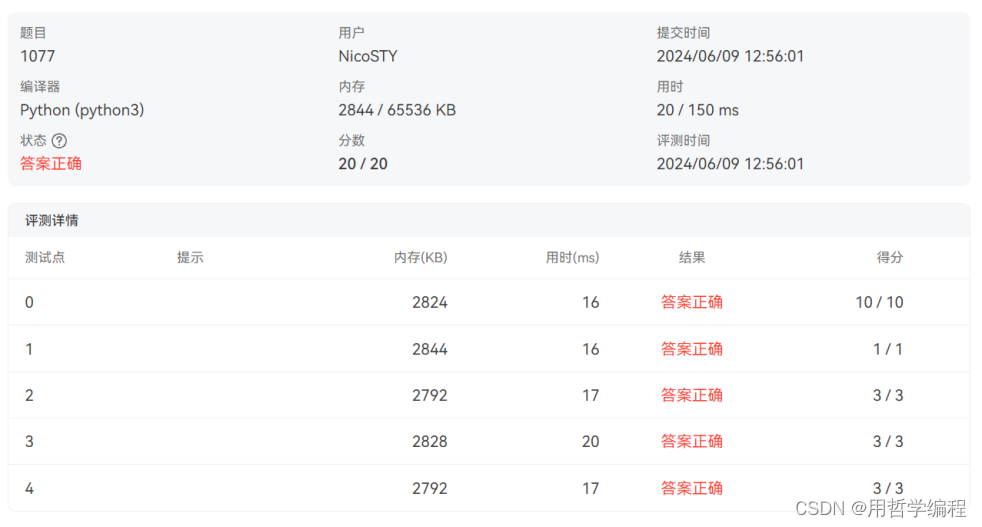
作者:来自 Elastic Valeriy Khakhutskyy

你是否想在 Elasticsearch 向量数据库之上构建 RAG 应用程序?你是否需要对大量数据使用语义搜索?你是否需要在隔离环境中本地运行?本文将向你展示如何操作。
Elasticsearch 提供了多种方法来为你的数据创建嵌入以进行对称搜索。最流行的方法之一是将 Elasticsearch open inference API 与 OpenAI、Cohere 或 Hugging Face 模型结合使用。这些平台支持许多可以在 GPU 上运行的大型、强大的嵌入模型。但是,第三方嵌入服务不适用于隔离系统,或者对有隐私问题和监管要求的客户不开放。
或者,你可以使用 ELSER 和 E5 在本地计算嵌入。这些嵌入模型在 CPU 上运行,并针对速度和内存使用进行了优化。它们也适用于隔离系统,可以在云中使用。但是,这些模型的性能不如在 GPU 上运行的模型。
如果你可以在本地计算数据的嵌入,那不是很棒吗?使用 LocalAI,你就可以做到这一点。LocalAI 是一个与 OpenAI API 兼容的免费开源推理服务器。它支持使用多个后端进行模型推理,包括用于嵌入的 Sentence Transformers 和用于文本生成的 llama.cpp。LocalAI 还支持 GPU 加速,因此你可以更快地计算嵌入。
本文将向你展示如何使用 LocalAI 计算数据的嵌入。我们将引导你完成设置 LocalAI、配置它以计算数据的嵌入以及运行它以生成嵌入的过程。你可以在笔记本电脑、隔离系统或任何需要计算嵌入的地方运行它。
我引起了你的兴趣吗?让我们开始吧!
步骤 1:使用 docker-compose 设置 LocalAI
要开始使用 LocalAI,你需要在计算机上安装 Docker 和 docker-compose。根据你的操作系统,你可能还需要安装 NVIDIA Container Toolkit 以在 Docker 容器内提供 GPU 支持。
旧版本不支持 NVIDIA 运行时指令,因此请确保安装了最新版本的 docker-compose:
sudo curl -L https://github.com/docker/compose/releases/download/v2.26.0/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
检查 docker-compose 的版本:
docker-compose --version
你需要使用以下 docker-compose.yaml 配置文件
# file: docker-compose.yaml
services:
localai:
image: localai/localai:latest-aio-gpu-nvidia-cuda-12
container_name: localai
environment:
- MODELS_PATH=/models
- THREADS=8
ports:
- "8080:8080"
volumes:
- $HOME/models:/models
tty: true
stdin_open: true
restart: always
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
注意:
- 我们将 $HOME/models 目录挂载到容器内的 /models 目录。这是模型的存储位置。你需要调整要存储模型的目录的路径。
- 我们指定了用于推理的线程数和要使用的 GPU 数量。你可以根据硬件配置调整这些值。
第 2 步:配置 LocalAI 以使用 Sentence Transformers 模型
在本教程中,我们将使用 mixedbread-ai/mxbai-embed-large-v1,它目前在 MTEB 排行榜上排名第 4。但是,任何可以由 sentence-transformers 库加载的嵌入模型都可以以相同的方式工作。
创建目录 $HOME/models 和配置文件 $HOME/models/mxbai-embed-large-v1.yaml,内容如下:
# file: mxbai-embed-large-v1.yaml
name: mxbai-embed-large-v1
backend: sentencetransformers
embeddings: true
parameters:
model: mixedbread-ai/mxbai-embed-large-v1
步骤 3:启动 LocalAI 服务器
通过运行以下命令以分离模式启动 Docker 容器
docker-compose up -d
从你的 $HOME 目录。
通过运行 docker-compose ps 验证容器是否已正确启动。检查 localai 容器是否处于启动状态。
你应该看到类似于以下内容的输出:
~$ docker-compose ps
WARN[0000] /home/valeriy/docker-compose.yaml: `version` is obsolete
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
localai localai/localai:latest-aio-gpu-nvidia-cuda-12 "/aio/entrypoint.sh" localai About a minute ago Up About a minute (health: starting) 0.0.0.0:8080->8080/tcp
如果出现问题,请检查日志。你还可以使用日志来验证 localai 是否可以看到 GPU。运行
docker logs localai
应该可以看到这样的信息:
$ docker logs localai
===> LocalAI All-in-One (AIO) container starting...
NVIDIA GPU detected
Thu Mar 28 11:15:41 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.86.10 Driver Version: 535.86.10 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 59C P0 29W / 70W | 2MiB / 15360MiB | 6% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
NVIDIA GPU detected. Attempting to find memory size...
Total GPU Memory: 15360 MiB
最后,你可以通过查询已安装模型的列表来验证推理服务器是否正常工作:
curl -k http://localhost:8080/v1/models
应该产生如下输出:
{"object":"list","data":[{"id":"tts-1","object":"model"},{"id":"text-embedding-ada-002","object":"model"},{"id":"gpt-4","object":"model"},{"id":"whisper-1","object":"model"},{"id":"stablediffusion","object":"model"},{"id":"gpt-4-vision-preview","object":"model"},{"id":"MODEL_CARD","object":"model"},{"id":"llava-v1.6-7b-mmproj-f16.gguf","object":"model"},{"id":"voice-en-us-amy-low.tar.gz","object":"model"}]}
步骤 4:创建 Elasticsearch _inference 服务
我们已经创建并配置了 LocalAI 推理服务器。由于它是 OpenAI 推理服务器的直接替代品,我们可以在 Elasticsearch 中创建一个新的 openai 推理服务。Elasticsearch 8.14 中实现了对此功能的支持。
要创建新的推理服务,请在 Kibana 中打开 Dev Tools 并运行以下命令:
PUT _inference/text_embedding/mxbai-embed-large-v1
{
"service": "openai",
"service_settings": {
"model_id": "mxbai-embed-large-v1",
"url": "http://localhost:8080/embeddings",
"api_key": "ignored"
}
}
注意:
- api_key 参数是 openai 服务所必需的,必须设置,但具体值对我们的 LocalAI 服务并不重要。
- 对于大型模型,如果模型首次下载到 LocalAI 服务器需要很长时间,则 PUT 请求最初可能会超时。只需在短时间内重试 PUT 请求即可。
最后,你可以验证推理服务是否正常工作:
POST _inference/text_embedding/mxbai-embed-large-v1
{
"input": "It takes all the running you can do, to keep in the same place. If you want to get somewhere else, you must run at least twice as fast as that!"
}
应该产生如下输出:
{
"text_embedding": [
{
"embedding": [
-0.028375082,
0.6544269,
0.1583663,
0.88167363,
0.5215657,
0.05415681,
0.62085253,
0.069351405,
0.29407632,
0.51018727,
0.8183201,
...
]
}
]
}
结论
按照本文中的步骤,你可以设置 LocalAI,使用 GPU 加速计算数据的嵌入,而无需依赖第三方推理服务。借助 LocalAI,在隔离环境中或有隐私问题的 Elasticsearch 用户可以利用世界一流的向量数据库来开发他们的 RAG 应用程序,而无需牺牲计算性能或选择最适合其需求的 AI 模型的能力。
立即尝试使用 Elastic Stack 构建你自己的 RAG 应用程序:在云端、隔离环境中或在你的笔记本电脑上!
准备好自己尝试了吗?开始免费试用。
希望将 RAG 构建到你的应用程序中?想尝试使用矢量数据库的不同 LLM 吗?
查看我们在 Github 上为 LangChain、Cohere 等提供的示例笔记本,并立即加入 Elasticsearch Relevance Engine 培训。
原文:LocalAI for GPU-Powered Text Embeddings in Air-Gapped Environments — Elastic Search Labs