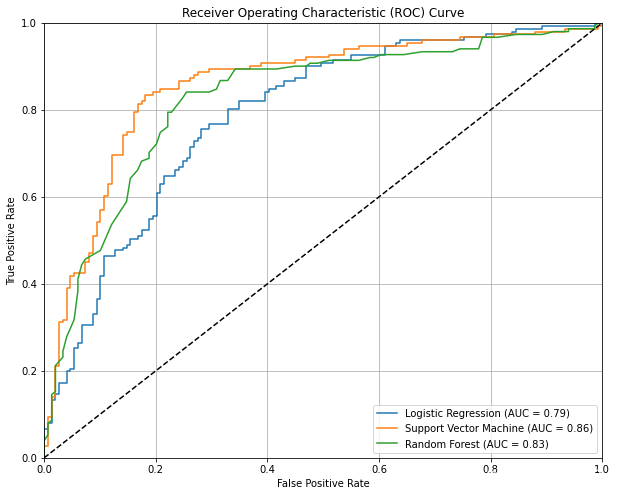
Reading AMD GPU ISA — ROCm Blogs
对于应用开发者来说,了解用于执行其计算的 GPU 架构的指令集架构(ISA)通常是非常有帮助的。理解感兴趣的代码区域的指令可以帮助调试和实现应用程序的性能优化。
在这篇博客文章中,我们将讨论如何阅读和理解 AMD 的 Graphics Core Next (AMDGCN) 架构的 ISA,该架构被用于 AMD Instinct™ 和 AMD Radeon™ 系列 GPU 中。AMDGCN ISA 包含 AMDGCN 架构用于执行计算任务的指令。尽管我们将在本文中讨论几个重要的主题和示例,但我们鼓励读者参考相关的 ISA 文档以获取更多细节,例如,对于 AMD Instinct™ MI200™ GPU,参考 CDNA2™ ISA,或对于 AMD NAVI™ 20s GPU,参考 RDNA2™ ISA。我们将讨论以下内容:
• AMDGCN 架构概述。
• AMDGCN ISA 支持的指令和寄存器类型。
• 一些阅读和理解基本 ISA 指令的示例。
先决条件知识
在讨论其 ISA 时,理解以下的 AMDGCN 架构概念将是有帮助的。
术语解释
让我们定义本博客文章中常用的几个术语。
• 指令集架构(ISA):处理器(CPU、GPU 或 FPGA)的语言,定义了处理器能够执行的操作。ISA 在处理器的系统软件中定义的操作与这些操作在硬件上的执行映射之间充当接口。x86、ARM、RISC-V、GCN 都是特定于处理器的 ISA。
• AMD Graphics Core Next (AMDGCN):AMD GPU 特有的 ISA。Southern Islands、Vega™、RDNA™(Radeon™)都是 AMDGCN ISA 的特定架构实现。
通常,ISA 是指特定处理器能够发出的所有可能指令。而“汇编”(ASM)指的是使用 ISA 的实际编程语言。然而,它们通常可以互换使用。
计算机架构知识点
这里讨论一些计算机架构的概念。
• 位(Bits)、字节(Bytes)和字(Words):一个字节是 8 位,一个字是 16 位(2 字节),一个双字(double word)是 32 位(4 字节)。假设以 C/C++ 作为程序实现语言并采用64位系统:一个 char 是 1 字节,一个 int 是 4 字节,一个 float 是 4 字节,一个 double 是 8 字节。在 AMDGCN ISA 中,经常可以看到 DWORD、`DWORDX2` 和 DWORDX4 指令。这些指示说明指令将分别对 4 字节(1 双字)、8 字节(2 双字)和 16 字节(4 双字)的数据进行操作。
• 指令类型:AMDGCN 实现为负载和存储架构,与 x86 的寄存器-存储器架构不同。因此,指令被分为两类:i) 存储操作(在存储器和寄存器之间的加载和存储),以及 ii) 算术逻辑单元(ALU)和浮点单元(FPU) 的操作(仅在寄存器之间发生)。
• 高位/低位比特:在指令集架构(ISA)中,最高有效比特(MSb)是一个数值中最重要的比特。高位比特是最左边的比特,而低位比特(最右边的比特)是数值中最不重要的比特(LSb)。
• 进位输入/输出:进位输入或输出指的是在算术运算中可能会溢出或下溢的比特。例如,如果两个32位数的算术运算产生超过32位的比特,那些比特就是“进位输出”,因为它们无法适应32位寄存器。这些比特会作为“进位输入”传递到表示更高位比特的32位寄存器中的下一个更重要的位置。因此,"进位输入/输出"操作便于使用较小精度的寄存器进行多精度算术运算。例如,即使是32位的寄存器也可以实现64位的运算。
• 执行掩码:执行掩码(`EXEC`)是一个决定在一个波前中哪些线程(threads)被执行的64位掩码:1 = 执行,0 = 不执行。所有向量指令都支持执行掩码。在GPU内核中,这个掩码通常用于处理流程分支的处理工作,其中每个分支只有一部分线程处于活跃状态。更多详细信息可以从 CDNA2™ ISA 的第3.3节中阅读到。
在处理器的小单元之间
一个内核在 CDNA2™ ISA 中的一个波前由 64 个线程以锁步方式运行。在 RDNA2™ ISA (第二节). 中,波前的尺寸可以在 32 和 64 线程之间切换。处理器使用以下小单元来操作内核:
• 标量算术逻辑单元(SALU):SALU 对每个波前的一个值进行操作,这个值对所有线程都是共同的。所有内核流程都使用 SALU 指令处理,包括 if/else、分支和循环。
• 矢量算术逻辑单元(VALU):VALU 对每个线程的唯一值进行操作,但指令在一个波前的所有线程中一次通过地进行。每个波前都有一个 64 位的 EXEC 位掩码,标记每个线程为 1 (活动 - 处理指令)或 0(休眠 - 指令无操作)。
• 标量存储器(SMEM):SMEM 通过标量数据缓存在标量寄存器和内存之间传输数据。SMEM 指令在 SGPRs 和内存之间读写连续的 DWORDs。
• 矢量存储器(VMEM):VMEM 允许矢量寄存器与存储器之间的数据传输,每个线程都可以提供一个独特的存储器地址。VMEM 指令也支持 EXEC 掩码。
• 本地数据共享(LDS):AMD GPU 中的本地数据共享(LDS)是类似于 CUDA 中共享内存的高速、与寄存器相邻的存储空间。这个存储空间可以被看作是一个显式管理的缓存。
指令和寄存器类型
寄存器是位于芯片上处理单元附近的高速存储器。几乎所有的计算都使用寄存器。数据被 加载 到它们中,执行操作后数据被 存储 出来。
指令和寄存器分为标量和矢量两种形式。在 ISA 语言中,标量指令以 "s_" 开头,而矢量指令以 "v_" 开头。对于跨波前显然是统一的操作,使用标量指令。这里的统一是指波前中的每个线程使用相同的数据,即没有必要在线程间重复努力。对于编译器无法证明为统一的任何事务,使用矢量指令。最常见的示例是每个波前中的每个线程都使用来自内存中独特位置的数据。
标量指令只能在标量寄存器(SGPRs)中操作数据。矢量指令可以在矢量寄存器(VGPRs)中操作数据,但也可以读取存储在 SGPRs 中的数据。标量和矢量寄存器都是双字(32 位)大小,但可以连接起来以适应更大的数据类型。例如,一个单一的双精度浮点值或指针(64 位)将存储在两个连续的 32 位寄存器中。
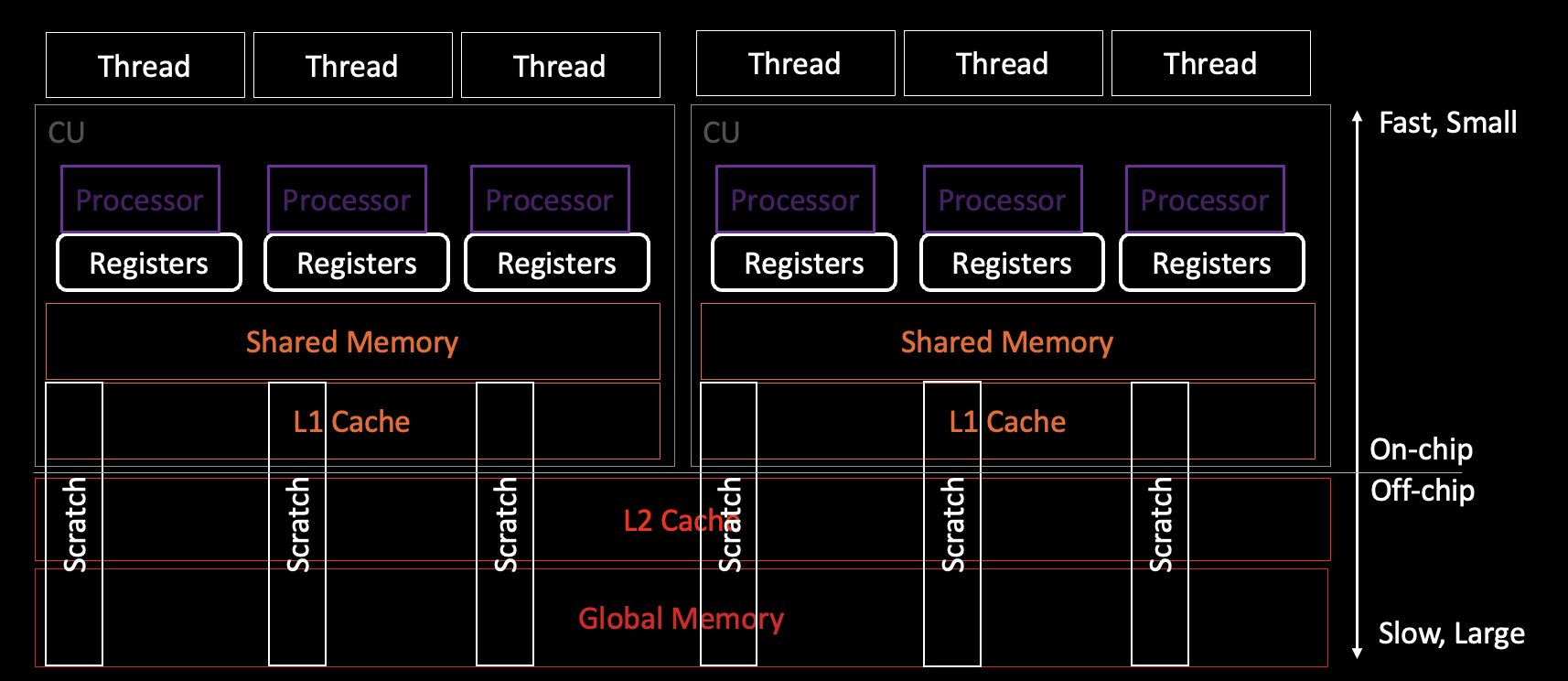
在 MI200 系列 GPU 上,每个计算单元由一个 SALU 和四个 VALU 组成。每个 VALU 有 800 个 SGPRs,每个计算单元总共有 12.8 KB。一个波前中的单个线程可以使用多达 256 个 VGPRs 和 256 个累加 VGPRs(AGPRs),总共 2 KB。总之,一个计算单元有 524 KB 的 VGPRs 和 AGPRs。下面的图示以示意性的方式代表了 CU 内部的结构。这里 SIMD 是 VALUs。详见 ORNL 幻灯片 来获取细节。

常见指令
下面是一些在高性能计算应用程序中常见的指令:
算术指令
这些指令包括在 SALU 或 VALU 小单元上的整数算术指令。例如,`s_add_i32`、`s_sub_i32` 是使用 SALU 小单元完成的标量操作加法和减法。类似地,`v_add_i32`、`v_sub_i32` 是使用 VALU 小单元完成的相同操作。
移动
这类指令包括将输入移动到标量或矢量寄存器中。例如,`v_mov_b32` 将 32 位矢量输入移动到矢量寄存器。类似地,`s_mov_b64` 将 64 位标量输入移动到标量寄存器。
比较
在标量(SOPC)或矢量(VOPC)输入上执行比较操作的指令。这些指令的格式为 *_cmp_*。矢量比较指令在 每 个通道(或线程)上执行相同的比较操作。一个标量比较操作设置标量条件码(SCC),它被用作条件分支条件。矢量比较操作设置矢量条件码(VCC)掩码。
条件指令
条件指令基本上使用 SCC 值(0 或 1)来执行操作,或者决定使用哪个源操作数。例如,`s_cmove_b32` 将一个标量 32 位输入移动到一个标量寄存器。
加载/存储
加载和存储是主要类型的内存操作。这些操作从存储器中加载数据,并将执行算术操作后的数据从寄存器存储回存储器。例如,标量加载指令 (s_load_dword) 从存储器中加载一单倍字的数据到一个 SGPR 中。同样,矢量加载指令 global_load_dword 每个线程从 HBM 到矢量寄存器中加载了一个双倍字的数据。更多细节请参阅 CDNA2™ ISA。
指令与其与存储器的关系
以下是有关指令和存储器的一些重要点:
内存层次结构
虽然阅读 AMDGCN ISA 不一定需要对 GPU 的内存空间和层次结构有深入的理解,但了解 GPU 的内存空间和层次结构对帮助理解是有益的。例如,在 MI250X GPU 的单个图形计算芯片上,内存层次结构可以分解为:

图表注释:
1. 块是由多个波前组成的,然后波前由多个线程组成。波前内的线程可以向另一个线程的寄存器发出交叉通道指令。
2. 共享内存和 L1 缓存位于计算单元内,而 L2 缓存是在计算单元之间共享的。
作为旁注,要了解关于在 MI200 GPU 上高效使用内存空间的信息,请参考 MI200 GPU 内存空间博客文章。
划痕/堆栈内存
(Scratch memory 这个术语来源于其临时和快速访问的性质。就像在现实生活中,我们有时会“快速草拟”(scratch out a quick note)一个笔记来记住某事,scratch memory 在计算机中提供了临时的存储,以便快速记录下计算过程中产生的数据。然而,在计算机术语中,此术语的使用比这种类比更为技术化。
Scratch memory 的用法源自更早时期的计算机语言和系统,其中“scratchpad memory”常被用来指临时存储区,作为快速读写数据的地方,而非长期存储。在早期的计算机系统中,这种存崇空间经常被用作计算的一部分,但并不是程序的主要存储区域。
对于现代的 GPU 和 CPU,当寄存器(提供最快的数据存取速度)不足以存放所有临时变量时,scratch memory 提供了一个后备的存储选项。它仍然是线程私有的,这意味着每个线程都可以访问自己的 scratch memory 区域,但这部分内存位于全局内存中,因此访问速度比寄存器慢。
因此,术语“scratch”强调了这种存储类型的临时性和辅助性。尽管它更慢,但仍然是必要的,以保证即使在寄存器不足的情况下,每个线程也能持续进行运算。
Scratch memory" 翻译成中文通常可以说成“刮痕内存”或“即时内存”。这里的“刮痕”(Scratch)表达了该内存是用于临时快速存取的含义。不过,这个术语在中文中没有一个固定的标准翻译,有时会根据上下文进行适当的变通。例如,它也可以翻译为“暂存内存”、“快速临时内存”或者“辅助内存”。在实际的技术文档或者讨论中,专业人士可能会根据具体情况来选择最适合的翻译。在没有特定上下文的情况下,“暂存内存”可能是最直接传达其用途的翻译。)
如果内核中存在高寄存器压力,一些数据会被存储在一个特殊的内存空间,即属于全局内存但对线程私有的Scratch(划痕)内存中。这意味着数据访问速度比使用寄存器内存要慢。划痕内存不使用 LDS,因此划痕指令也不使用 LDS 带宽。这些指令只使用 vm_cnt(用于全局内存访问)而不使用 lgmk_cnt。以下示意图展示了线程访问划痕内存的方式。
示意图备注:
1. 线程和处理器之间的连接是通过波前实现的。实际上并不是每个处理器都和一个线程一一对应,而是每个四分之一波前的处理器会分为四个阶段来处理完整的波前。
2. 编译器寄存器使用和划痕诊断按线程报告。
ISA 示例
此部分通过几个简单的例子讨论 ISA 指令。可以使用编译器的 --save-temps 标志生成 ISA 源文件(包括 *.s 文件)。例如:
hipcc -c --save-temps -g example.cpp虽然 --save-temps 足以生成相关的 ISA 源文件,但添加调试符号标志 -g 会进一步以相应的内核代码行注释 ISA。
要生成内核资源使用情况,例如 SGPR、VGPR、划痕内存、LDS 和占用率(每个 SIMD 的活动波前),请使用:
hipcc -c example.cpp -Rpass-analysis=kernel-resource-usage请注意,这个报告只包含 编译时 信息。如果使用了运行时定义的动态共享内存或动态堆栈分配,则 -Rpass-analysis=kernel-resource-usage 不会报告正确的划痕内存、LDS 和/或占用率信息。
加载和存储
以下是几个代码示例及其对应的ISA:
简单的加载和存储
下面的代码片段显示了一个简单的HIP内核,包含一个加载和一个存储操作:
__global__
void load_store(int n, float* in, float* out)
{
int tid = threadIdx.x + blockDim.x * blockIdx.x;
out[tid] = in[tid];
}这个内核的注释版ISA为:
; %bb.0:
s_load_dword s7, s[4:5], 0x24 # SGPRs s[4:5] 保存内核参数
# 和内核分派包。
# 从s[4:5]的偏移量36 (=0x24)读取
# 并保存blockDim.x到s7。
s_load_dwordx4 s[0:3], s[4:5], 0x8 # 保存输入数组in[]到SGPR对s[0:1],输出数组out[]到SGPR对s[2:3]。
s_waitcnt lgkmcnt(0) # 等待标量内存加载完成,直到计数器(lgkmcnt)值减少到0。
s_and_b32 s4, s7, 0xffff # 保留blockDim.x (s7)的低位比特,并将所有高位比特置为0。保存到s4。
s_mul_i32 s6, s6, s4 # s6=blockDim.x * blockIdx.x (s4 * s6)
v_add_u32_e32 v0, s6, v0 # tid (v0) = threadIdx.x (v0) + s6
# --- 输入数组in[]和输出数组out[]的整数操作 ---
v_ashrrev_i32_e32 v1, 31, v0 # 将32位的v0存储到64位对v[0:1]中
v_lshlrev_b64 v[0:1], 2, v[0:1] # tid<<2 (tid *= 4),第tid个元素的偏移量是tid*4字节从第0个元素开始
v_mov_b32_e32 v3, s1 # 将in[]的高位地址(s1)移动到VGPR v3的高位比特上
v_add_co_u32_e32 v2, vcc, s0, v0 # 将in[]的基地址(s0)加上tid*4(v0)得到
# 每个tid的地址。
v_addc_co_u32_e32 v3, vcc, v3, v1, vcc # 将进位加到tid*4的高位比特上,保存在v3
# 现在,VGPR对v[2:3]拥有了in[]的正确地址,对于每个线程
global_load_dword v2, v[2:3], off # 从v[2:3]加载in[]到v2。
v_mov_b32_e32 v3, s3 # 当v2数据被加载并准备使用的时候,让我们进行一些out[]的指针运算
v_add_co_u32_e32 v0, vcc, s2, v0 # 类似于上面的数组输入操作
v_addc_co_u32_e32 v1, vcc, v3, v1, vcc # v[0:1] = 每个线程正确的out[]地址
s_waitcnt vmcnt(0) # 等待"全局内存"计数器vmcnt减少到值0。
# 它等待global_load_dword操作执行完毕,
# 再进行存储操作。
global_store_dword v[0:1], v2, off # 在v[0:1]中存储全局数据v2
s_endpgm # 内核程序结束前隐式等待全局存储操作完成。
# 该指令告诉硬件波前已完成。请注意,AMDGCN调用约定的明确要求是,内核参数必须通过SGPRs传递。这与通过将函数参数推入栈来传递的x86不同。
带条件的加载和存储
让我们在上面的内核中引入一个条件,确保线程的内存访问保持在数组范围内。以下代码片段显示了更新后的内核。
__global__
void load_store(int n, float* in, float* out)
{
int tid = threadIdx.x + blockDim.x * blockIdx.x;
if (n > tid)
out[tid] = in[tid];
}上述带有条件语句的加载和存储HIP内核的ISA如下:
; %bb.0:
# --- 第1部分: 见简单内核 ---
s_load_dword s0, s[4:5], 0x24
s_load_dword s1, s[4:5], 0x0
s_waitcnt lgkmcnt(0)
s_and_b32 s0, s0, 0xffff
s_mul_i32 s6, s6, s0
v_add_u32_e32 v0, s6, v0 # 保存每个线程的tid到v0。
# --- 第2部分: 条件 ---
v_cmp_gt_i32_e32 vcc, s1, v0 # 64位寄存器对向量条件码
# 'vcc'持有布尔值(0或1) "n (s1) > tid (v0)"
s_and_saveexec_b64 s[0:1], vcc # 64位寄存器对s[0:1]存储
# 执行掩码 'exec' 指示激活/掩蔽(1/0)的通道数
# SGPR寄存器对(exec掩码)
# 存储对于"tid < n"为真的所有tid为1,否则为0.
s_cbranch_execz .LBB0_2 # 如果所有执行掩码都是
# 0位,跳转到程序的末尾。
# 见LBB0_2下面。
# --- 第3部分: 全局加载/存储 ---
# 整数运算和全局加载/存储指令
# 与简单内核相同。
# 注意:第3部分只
# 为s[0:1]位值为1的线程执行。
; %bb.1:
s_load_dwordx4 s[0:3], s[4:5], 0x8 # s[0:1]: in[], s[2:3]: out[]
v_ashrrev_i32_e32 v1, 31, v0 # ...
v_lshlrev_b64 v[0:1], 2, v[0:1]
s_waitcnt lgkmcnt(0)
v_mov_b32_e32 v3, s1
v_add_co_u32_e32 v2, vcc, s0, v0
v_addc_co_u32_e32 v3, vcc, v3, v1, vcc
global_load_dword v2, v[2:3], off # 将全局数据in[tid]加载到v2
v_mov_b32_e32 v3, s3 # 指针运算,用于out[]
v_add_co_u32_e32 v0, vcc, s2, v0 # ...
v_addc_co_u32_e32 v1, vcc, v3, v1, vcc # ...
s_waitcnt vmcnt(0) # 等待全局加载完成
# 并且在VGPR v2中可用。
global_store_dword v[0:1], v2, off # 将加载的全局数据v2
# 存储到VGPR对v[0:1]中。
.LBB0_2:
s_endpgm # 在程序结束前隐式地等待直到全局存储
# 完成。波前完成。划分为暂存存储空间
内核中使用暂存空间的一个例子可以通过简单地在内核中分配一个数组来完成,其大小超过了寄存器所能承受。例如:
__global__ void kernel(int* x, int len)
{
int y[16] = {0}; //64 bytes
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < len) {
x[i] = y[i];
}
}上述内核的资源使用情况:
SGPRs: 11 [-Rpass-analysis=kernel-resource-usage]
VGPRs: 3 [-Rpass-analysis=kernel-resource-usage]
AGPRs: 0 [-Rpass-analysis=kernel-resource-usage]
ScratchSize [bytes/lane]: 0 [-Rpass-analysis=kernel-resource-usage]
Occupancy [waves/SIMD]: 8 [-Rpass-analysis=kernel-resource-usage]
SGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]
VGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]
LDS Size [bytes/block]: 0 [-Rpass-analysis=kernel-resource-usage]这里的 y 可以放在向量寄存器(VGPRs)中。然而,如果寄存器数组大小进一步增加:
__global__ void kernel(int* x, int len)
{
int y[17] = {0}; //68 bytes
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < len) {
x[i] = y[i];
}
}这个内核的资源使用情况现在如下:
SGPRs: 14 [-Rpass-analysis=kernel-resource-usage]
VGPRs: 4 [-Rpass-analysis=kernel-resource-usage]
AGPRs: 0 [-Rpass-analysis=kernel-resource-usage]
ScratchSize [bytes/lane]: 96 [-Rpass-analysis=kernel-resource-usage]
Occupancy [waves/SIMD]: 8 [-Rpass-analysis=kernel-resource-usage]
SGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]
VGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]
LDS Size [bytes/block]: 0 [-Rpass-analysis=kernel-resource-usage]y 不再放在向量寄存器中,因为它太大了,现在被溢出到暂存内存中。机器上的物理内存并非无限细腻,我们可以看到栈是以96字节的“块”来分配的。以下ISA代码显示,通过使用`buffer_store_dword`指令将scratch内存存储在17个缓冲栈中:
buffer_store_dword v1, off, s[0:3], 0 offset:76
buffer_store_dword v1, off, s[0:3], 0 offset:72
buffer_store_dword v1, off, s[0:3], 0 offset:68
buffer_store_dword v1, off, s[0:3], 0 offset:64
buffer_store_dword v1, off, s[0:3], 0 offset:60
buffer_store_dword v1, off, s[0:3], 0 offset:56
buffer_store_dword v1, off, s[0:3], 0 offset:52
buffer_store_dword v1, off, s[0:3], 0 offset:48
buffer_store_dword v1, off, s[0:3], 0 offset:44
buffer_store_dword v1, off, s[0:3], 0 offset:40
buffer_store_dword v1, off, s[0:3], 0 offset:36
buffer_store_dword v1, off, s[0:3], 0 offset:32
buffer_store_dword v1, off, s[0:3], 0 offset:28
...
buffer_store_dword v1, off, s[0:3], 0 offset:24
buffer_store_dword v1, off, s[0:3], 0 offset:20
buffer_store_dword v1, off, s[0:3], 0 offset:16
buffer_store_dword v1, off, s[0:3], 0 offset:80请注意,寄存器溢出到scratch内存的情况严重依赖于GPU架构和ROCm™版本。
位移拷贝
位移拷贝的一个示例是:
__global__ void shifted_copy (float *in, float *out) {
size_t gid = blockDim.x * blockIdx.x + threadIdx.x
out[gid] = in[gid+4];
}以下是上述 shifted_copy 内核的显著的ISA指令:
s_load_dwordx4 s[0:3], s[4:5], 0x0 # s[0:1] 64位: 输入数组 in[], s[2:3] 64位: 输出数组 out[]
# 从内核参数 s[4:5] 读取
v_lshlrev_b64 v[0:1], 2, v[0:1] # gid 存储在 v[0:1] 64位中。
# v[0:1] 左移2位,来
# 账户每个浮点元素的 in[] 4字节的访问。
# 例如:gid[波段=0] 在 0 和
# gid[波段=1] 在 4
v_add_co_u32_e32 v2, vcc, s0, v0 # 向每个线程的虚拟寄存器 v[0:1]
# 添加 in[] 的基地址
# 存储在 s[0:1] 以访问 corr 地址 [gid],
# 并保存在 v[2:3]
global_load_dword v2, v[2:3], off offset:16 # 全局加载 float,地址偏移
# 16=(4移位)*(4字节/float),
# 保存在 v2 64位
v_add_co_u32_e32 v0, vcc, s2, v0 # int 操作通过每个线程访问 out[] 指针
v_addc_co_u32_e32 v1, vcc, v3, v1, vcc # 在 [gid],并在 v[0:1] 中存储
s_waitcnt vmcnt(0) # 波在 vmem 指令前等待
# 直到所有加载完成,
# 或直到加载等待计数器
# 达到 0。即,等待直到
# v2 中的数据加载完成并在波中可用
global_store_dword v[0:1], v2, off # 加载完成后,将
# 数据存储在数组 out[] 的 v[0:1] 中请注意,通过4个索引的偏移复制体现在指令中:`global_load_dword v2, v[2:3], off offset:16`。这里的16指的是每个浮点数4字节乘以总共4次偏移。如果我们使用双精度浮点型,相应的指令将是:`global_load_dword2 v2, v[2:3], off offset:32`。这里的总偏移是每个双精度8字节乘以总共4次偏移,即32。同样注意到 dwordx2 用于加载双精度类型。
Pragma unroll
编译器指令 #pragma unroll <unroll_factor> 可以通过控制 <unroll_factor> 来优化内核性能。较大的 unroll_factor 可能会yield更低的执行时间,但可能会导致更大的寄存器压力和减少占用。例如,让我们比较 unroll 因子为8和32的循环在 unroll 内核示例中的第一个循环。
Baseline kernel (unroll factor=8)
__global__ void kernel_unroll(float* in, size_t fac)
{
size_t tid = threadIdx.x;
if (tid >= N)
return;
float temp[NITER];
#pragma unroll 8
for (size_t it = 0; it < NITER; ++it)
temp[it] = in[tid + it*fac];
for (size_t it = 0; it < NITER; ++it)
if (temp[it] < 0.0)
in[tid + it*fac] = 0.0;
}Optimized kernel (unroll factor=32)
__global__ void kernel_unroll(float* in, size_t fac)
{
size_t tid = threadIdx.x;
if (tid >= N)
return;
float temp[NITER];
#pragma unroll 32
for (size_t it = 0; it < NITER; ++it)
temp[it] = in[tid + it*fac];
for (size_t it = 0; it < NITER; ++it)
if (temp[it] < 0.0)
in[tid + it*fac] = 0.0;
}以下是常见于这些内核的一些变量的值:
#define N 1024 * 1024 * 8
#define NITER 128基准内核(unroll 因子为8)的内核使用情况如下所示:
SGPRs: 22 [-Rpass-analysis=kernel-resource-usage]
VGPRs: 21 [-Rpass-analysis=kernel-resource-usage]
AGPRs: 0 [-Rpass-analysis=kernel-resource-usage]
ScratchSize [bytes/lane]: 528 [-Rpass-analysis=kernel-resource-usage]
Occupancy [waves/SIMD]: 8 [-Rpass-analysis=kernel-resource-usage]
SGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]
VGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]
LDS Size [bytes/block]: 0 [-Rpass-analysis=kernel-resource-usage]使用32的展开因子,我们注意到VGPRs的数量大约增加了两倍。
SGPRs: 22 [-Rpass-analysis=kernel-resource-usage]
VGPRs: 42 [-Rpass-analysis=kernel-resource-usage]
AGPRs: 0 [-Rpass-analysis=kernel-resource-usage]
ScratchSize [bytes/lane]: 528 [-Rpass-analysis=kernel-resource-usage]
Occupancy [waves/SIMD]: 8 [-Rpass-analysis=kernel-resource-usage]
SGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]
VGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]
LDS Size [bytes/block]: 0 [-Rpass-analysis=kernel-resource-usage]在查看基线代码的ISA源代码 *.s 时,最大的 global_load_dword VGPR索引是v20,这对应于21个VGPRs。
...
global_load_dword v20, v[8:9], off
...另一方面,具有32大小的pragma unroll的内核具有最大VGPR索引为v41,相当于42个VGPRs。
...
global_load_dword v41, v[10:11], off
...请注意,使用大小为32的pragma unroll时,ISA将只显示32个全局加载。然而,因为循环有 niter = 128,所以总共必须有128个全局加载。使用pragma unroll的内核简单地通过4次这样的传递来执行128个全局加载,每个传递中有32个全局加载。
继续讨论循环展开,我们必须小心使用过大的pragma unroll大小。例如,展开大小为64的内核会导致更大的寄存器(VGPRs)使用和减少的占用率,相比于展开大小为32,占用率减少到每SIMD 6个波浪。这从其内核使用摘要中可以清晰看到:
SGPRs: 22 [-Rpass-analysis=kernel-resource-usage]
VGPRs: 74 [-Rpass-analysis=kernel-resource-usage]
AGPRs: 0 [-Rpass-analysis=kernel-resource-usage]
ScratchSize [bytes/lane]: 528 [-Rpass-analysis=kernel-resource-usage]
Occupancy [waves/SIMD]: 6 [-Rpass-analysis=kernel-resource-usage]
SGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]
VGPRs Spill: 0 [-Rpass-analysis=kernel-resource-usage]
LDS Size [bytes/block]: 0 [-Rpass-analysis=kernel-resource-usage]最大的 VPGR 索引的 global load 从 ISA 源文件观察到是 v73,对应 74 VPGRs:
...
global_load_dword v73, v[10:11], off
...警告
有时编译器可能会默认使用循环展开进行优化。这可能会导致较大的寄存器使用并可能降低占用率。在上述例子中,由于编译器优化,如果没有包含任何 pragma unroll 指令,则仍然会导致 pragma unroll 因子为128,例如在MI250上的rocm/6.1.0。这将导致更大的寄存量使用85 VGPRs和更低的占用率,每SIMD 5波。
请注意,上面的例子中有较大的划痕分配(528字节/线程)。这并不奇怪,因为内核使用了一个大的堆栈数组 temp[NITER]。这在之前关于划痕的例子中讨论过。理想情况下,在内核中应该避免使用如此大的堆栈分配,以进一步提高其性能。这也在 Register pressure in AMD CDNA™2 GPUs — ROCm Blogs 博客帖子中进行了讨论。
总结
在这篇博客中,我们讨论了如何阅读 AMDGCN 架构的 ISA。我们讨论了一些基本的指令类型,它们与处理器子单元和内存层次结构的关系。为了让读者熟悉 ISA,我们使用了一些例子。虽然这作为对 AMDGCN ISA 阅读的良好介绍,但鼓励读者参考特定的 AMDGCN ISA 文档。如果您有任何问题或评论,请在 GitHub 讨论区与我们联系 Discussions
额外资源
• AMDGCN Assembly
• LLVM-AMDGPU-Assembler-Extra
• Assembly cross lane operations
• AMD ISA Doc
• RDNA3™ ISA guide