实现数据查询代码:Elastic Search(ES)Java 入门实操(2)搜索代码-CSDN博客
Elastic Search 官方描述,是一个分布式的搜素数据分析引擎,可以集中存储数据,快速完成搜索,微调相关性,进行强大的分析。
ES 中的索引、映射、文档和字段等概念和传统关系型数据库相似。可以结合数据库去理解。比如索引可以理解为表。
ES 使用了倒排索引机制来优化搜索效率。比如”唱跳rap篮球“,根据机制可能会为 唱跳、rap、篮球分别建立索引,当我们搜索其中一个关键词,就能搜索出来相关的结果,然后通过正排索引来详细展示相关文章。
官方文档:Quick start | Elasticsearch Guide [7.17] | Elastic
下载安装
需要下载的有 Elastic Search 和 kibana(可视化界面)
Elastic Search 下载地址:Elasticsearch 7.17.21 | Elastic
kibana 下载地址:Install Kibana on Windows | Kibana Guide [7.17] | Elastic
推荐下载 7.17版本,避免出现其他问题。
下载完成后直接解压即可,路径名不要带有中文
在解压目录的 bin 目录下使用 cmd 命令 elasticsearch 就可以启动,访问端口 localhost:9200
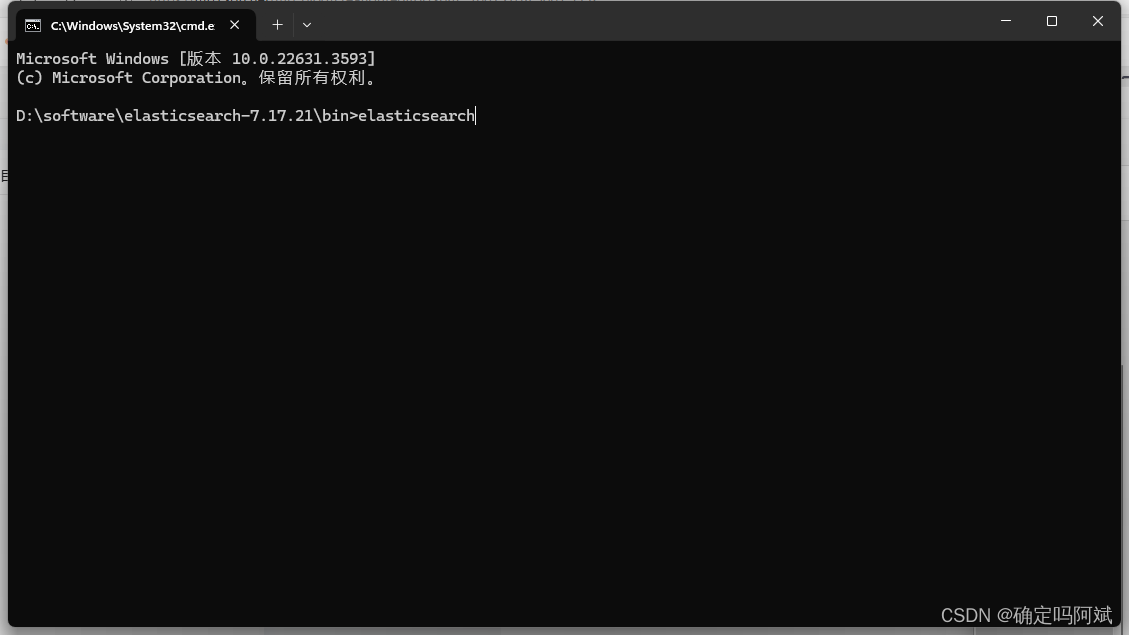
同样的 kibana 也是在 bin 目录下启动 kibana 命令,可视化界面的端口号是 5601
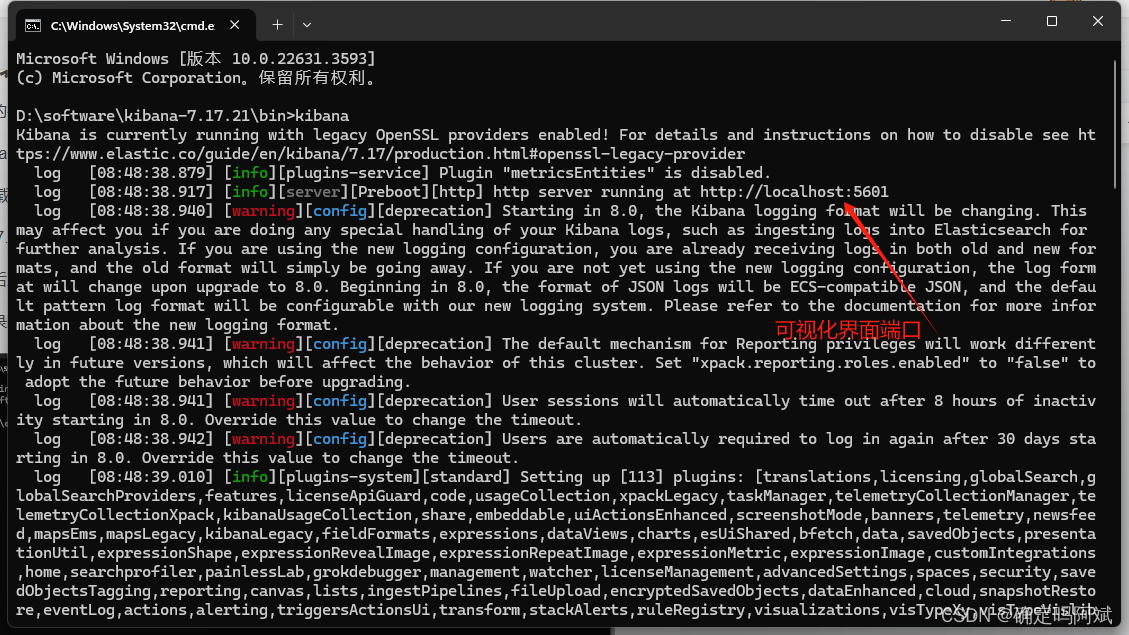
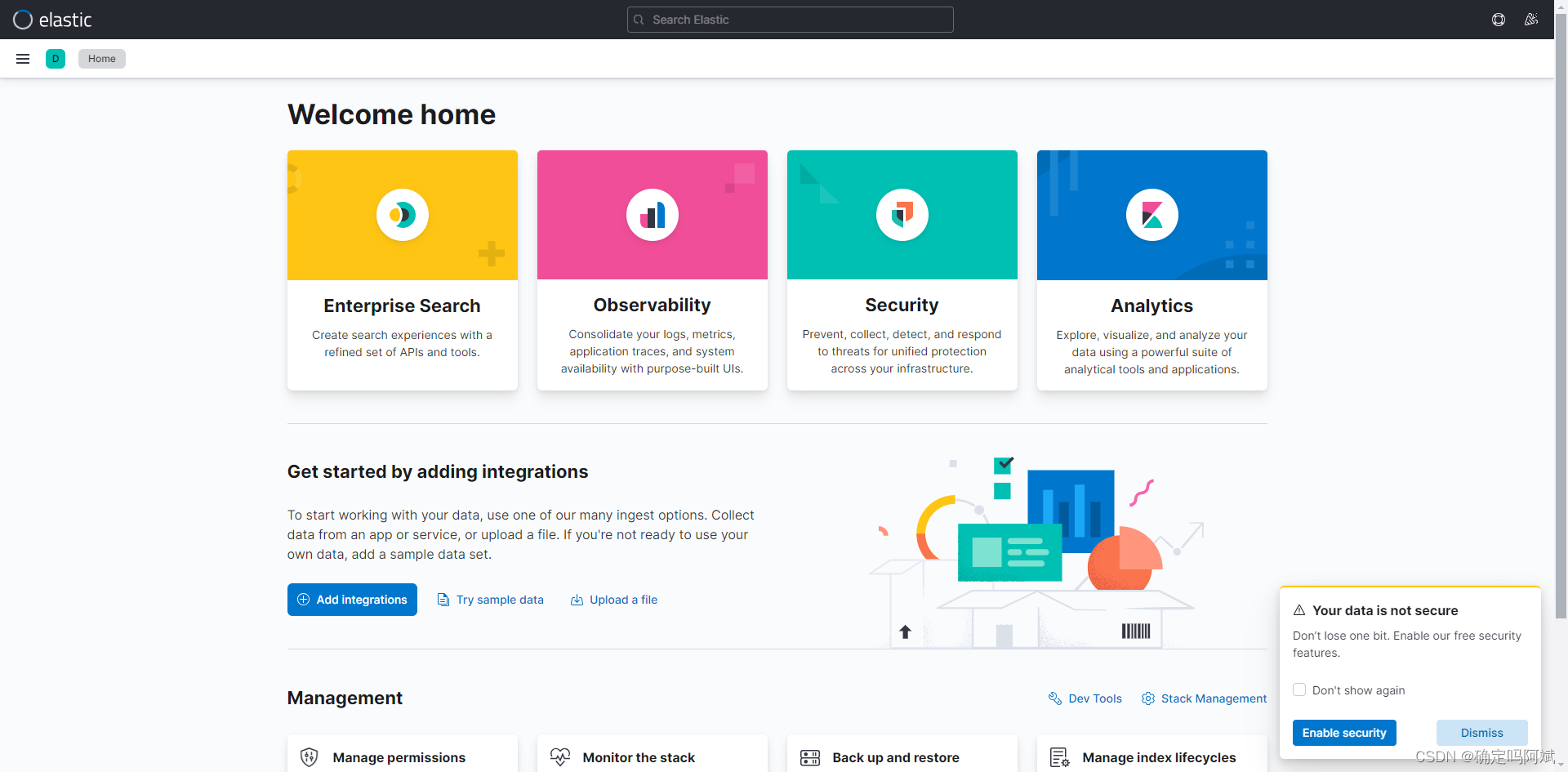
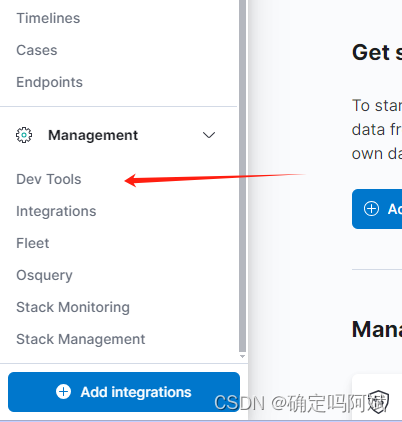
在左侧边栏使用 Dev Tools 即可进入控制台使用 ES 自己的操作数据的语法
DSL
应用最广的,是 Json 格式,好理解,和 http 请求兼容
官方文档:Query DSL | Elasticsearch Guide [7.17] | Elastic
新增数据
井号后面是注释,实际使用不需要
注意:当添加新数据时如果不指定 id ,ES 会自动生成,类型是 string 类型,如果需要在代码层面和 MySQL 同步,最好是新增的时候指定 id ,避免出现类型不同等其他问题。
POST#请求的类型 post_1#表的名称 /_doc/ 5#id
{ #字段和数据
"title": "kun",
"desc": "唱跳"
}
#结果
{
"_index" : "post_v1",
"_type" : "_doc",
"_id" : "5",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 6,
"_primary_term" : 3
}
查询
#查询对应的表
GET post_v1/_search
#根据 id 查询
GET post_v1/_doc/5修改
POST post_v1/_doc/5
{
"title": "cxk",
"desc": "ctrl"
}实际修改数据和新增数据格式差不多,只需要指定对应的 id 即可,如果表(索引)中没有对应的 id,就会直接创建新的数据。
一句话概括就是有就修改,没有就新增,所以也不会出现重复修改的情况,因为只要有就会修改。
删除
#删除普通索引
DELETE index_name
#删除数据流式索引
DELETE _data_stream/logs-my_app-default
ES 还有其他格式的 Query 格式命令,比如 EQL、SQL、Painless Scrpiting language,详情可以查看官方文档。
Mapping
官方文档:Mapping | Elasticsearch Guide [7.17] | Elastic
相当于数据库表的表结构,字段和字段类型。有的字段不指定会自动生成,比如主键 id。
ES 支持动态 mapping,表结构可以动态改变,如果表结构中不存在的字段,如果插入了数据,也能插入,并新增字段。
也可以手动指定字段类型,显式创建 mapping
PUT user
{
"mappings": {
"properties": {
"age": { "type": "integer" },
"email": { "type": "keyword" },
"name": { "type": "text" }
}
}
}分词器
顾名思义,就是 ES 的一种分词策略/规则
官方文档:Test an analyzer | Elasticsearch Guide [7.17] | Elastic
#使用空格分词
POST _analyze
{
"analyzer": "whitespace",
"text": "The quick brown fox."
}
#标准分词
POST _analyze
{
"tokenizer": "standard",
"filter": [ "lowercase", "asciifolding" ],
"text": "Is this déja vu?"
}
#关键词分词,整句当作一个关键词,不分开
POST _analyze
{
"analyzer": "keyword",
"text": "The quick brown fox."
}官方提供的分词器问题在于对于中文来说不太友好 ,中文是不使用空格作为分隔的。
IK 分词器
中文友好,文档:GitHub - infinilabs/analysis-ik: 🚌 The IK Analysis plugin integrates Lucene IK analyzer into Elasticsearch and OpenSearch, support customized dictionary.
下载地址:Index of: analysis-ik/stable/ (infinilabs.com)
注意版本,本文的 ES 版本为 7.17.21,避免出现兼容性问题
下载完成后在 ES 文件夹中新建 plugins 文件夹,然后把下载的插件解压到里面。重启 ES 和 kibana 即可加载。
![]() 载入成功
载入成功
IK 分词器有两种:ik_smart、ik_max_word
打个比方,天青色等烟雨而我在等你,ik_smart 是按照系统自己认为的方式进行组词,比如青色,烟雨,ik_max_word 是最大细度得组词,比如,天青,青色,都是系统认为的词语。
POST _analyze
{
"analyzer": "ik_smart",
"text": "天青色等烟雨而我在等你"
}
#结果
{
"tokens" : [
{
"token" : "天",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "青色",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "等",
"start_offset" : 3,
"end_offset" : 4,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "烟雨",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "而我",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "在",
"start_offset" : 8,
"end_offset" : 9,
"type" : "CN_CHAR",
"position" : 5
},
{
"token" : "等你",
"start_offset" : 9,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 6
}
]
}POST _analyze
{
"analyzer": "ik_max_word",
"text": "天青色等烟雨而我在等你"
}
#结果
{
"tokens" : [
{
"token" : "天青",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "青色",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "等",
"start_offset" : 3,
"end_offset" : 4,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "烟雨",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "而我",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "在",
"start_offset" : 8,
"end_offset" : 9,
"type" : "CN_CHAR",
"position" : 5
},
{
"token" : "等你",
"start_offset" : 9,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 6
}
]
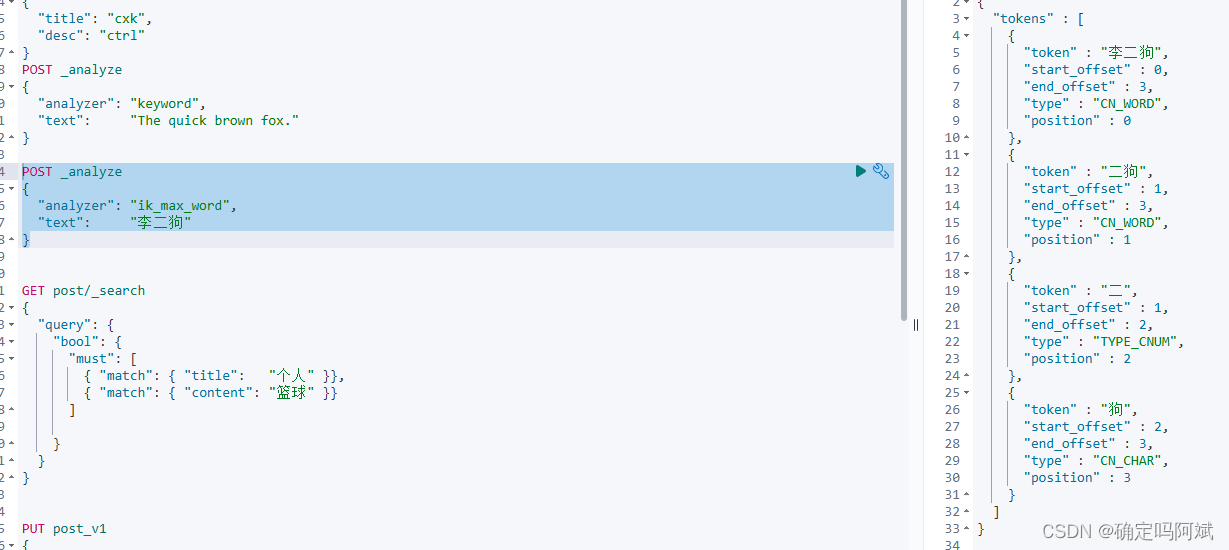
}即使使用了分词器,系统也不一定能够按照我们想的方式进行分词,比如我叫 李二狗,拆出来是李、二、狗,不会把我的名字作为关键词进行分词。ik有一个词典机制,就和输入法的词库类似,我们只需要将我们想要分成的词写成词典即可。
POST _analyze
{
"analyzer": "ik_max_word",
"text": "李二狗"
}
#结果
{
"tokens" : [
{
"token" : "李",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "二",
"start_offset" : 1,
"end_offset" : 2,
"type" : "TYPE_CNUM",
"position" : 1
},
{
"token" : "狗",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 2
}
]
}IK 词典
首先进入到 解压的 IK 插件目录,进入 config 目录,elasticsearch-7.17.21\plugins\ik\config。
找到 IKAnalyzer.cfg.xml 文件,打开可以看见这里就是添加词典的地方
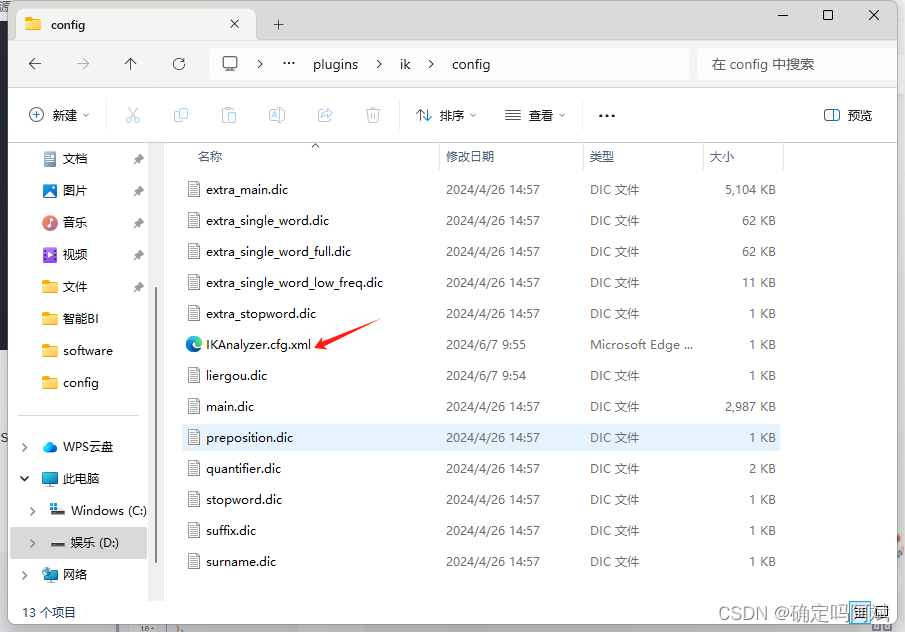
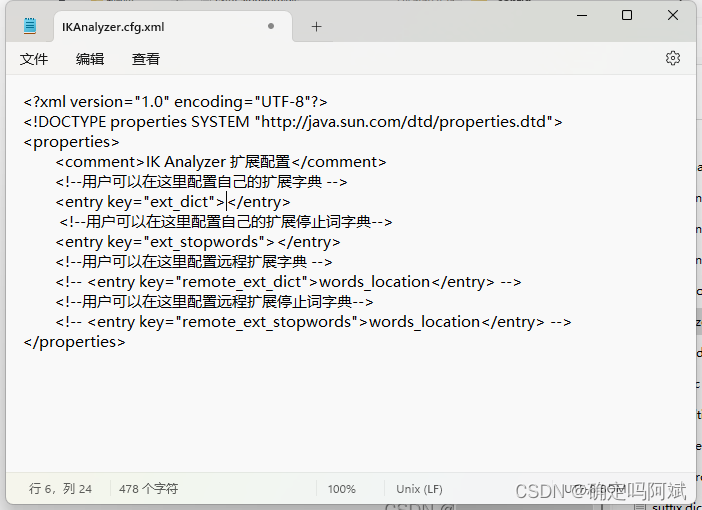
然后在 config 目录下新建一个词典,名字最好是中文,后缀是 .dic,然后在里面加上想要作为分词的词组。
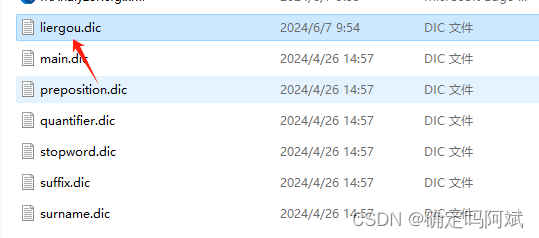

再然后在刚刚的文件中把词典添加进去
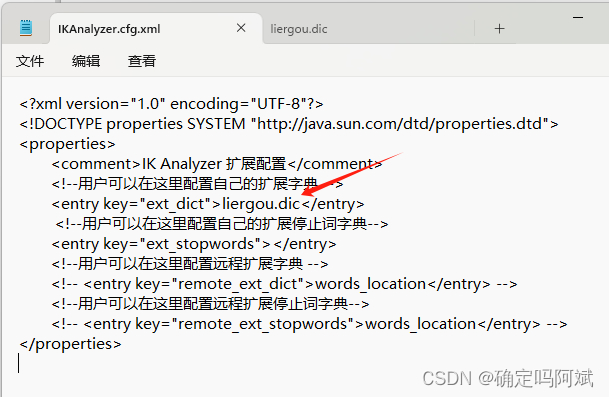
重启 ES 和 kibana,测试,发现按照词典进行分词了。
篇幅有限,Java 整合 ES 在下一篇文章。






![[数据集][目标检测]室内积水检测数据集VOC+YOLO格式761张1类别](https://img-blog.csdnimg.cn/direct/9e58aa61e5c44340a230b80f0fcc0733.png)