1、演示项目背景
2、pom.xml
3、启动项目
4、测试
5、保存数据到数据库
6、通过mq保存数据到mysql
7、通过mq保存数据到es
1、演示项目背景
下载zipkin,建议使用2.x版本的,3.x版本的要求jdk高版本。如果自己是1.8,就下载2.x的
下载地址:Central Repository: io/zipkin/zipkin-server (maven.org)
使用consul作为注册配置中心,自己也可以使用nacos等其他的。
三个微服务(consumer和provider代码在上一篇文章)
新加个gateway是为了更能清楚查看链路信息
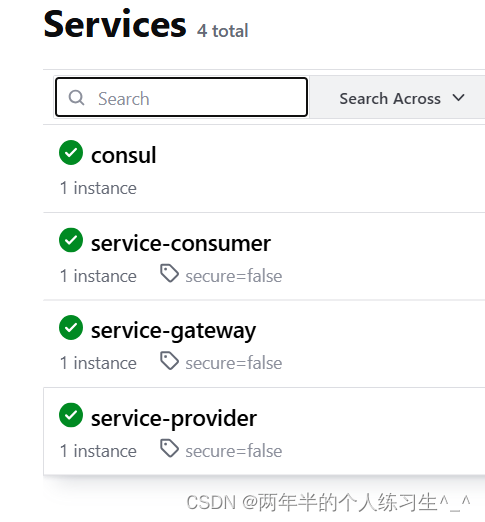
service-gateway代码
application.yml
server:
port: 9092
spring:
application:
name: service-gateway
cloud:
consul:
host: localhost
port: 8500
discovery:
register: true #是否需要注册
instance-id: ${spring.application.name}-01 #实例名称(必须唯一)
service-name: ${spring.application.name} #服务名称
port: ${server.port} #服务端口
prefer-ip-address: true #是否使用ip注册服务
ip-address: ${spring.cloud.client.ip-address} #请求服务ip地址
health-check-timeout: 5s
gateway:
routes:
- id: service-consumer
uri: lb://service-consumer
predicates:
- Path=/service-consumer/**
filters:
- StripPrefix=1
- id: service-provider
uri: lb://service-provider
predicates:
- Path=/service-provider/**
filters:
- StripPrefix=1
zipkin:
base-url: http://localhost:9411/
sender:
type: web #传输方式,web、rabbit、kafka、rocketmq
sleuth:
sampler:
probability: 1.0 #应该采样的请求的概率。
#例如。 1.0-应抽样100%的请求。 精度仅是整数(即不支持0.1%的迹线). 如果是1.0就会保存所有的请求。启动类
package com.txd;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class GatewayApplication
{
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class,args);
}
}
pom
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
<version>2.2.1.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-discovery</artifactId>
<version>2.2.1.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
<version>2.2.1.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
<version>2.2.1.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
</dependencies>service-consumer的yml
server:
port: 9090
spring:
application:
name: service-consumer
cloud:
consul:
host: localhost
port: 8500
discovery:
register: true #是否需要注册
instance-id: ${spring.application.name}-01 #实例名称(必须唯一)
service-name: ${spring.application.name} #服务名称
port: ${server.port} #服务端口
prefer-ip-address: true #是否使用ip注册服务
ip-address: ${spring.cloud.client.ip-address} #请求服务ip地址
zipkin:
base-url: http://localhost:9411/
sender:
type: web #传输方式,web、rabbit、kafka、rocketmq
sleuth:
sampler:
probability: 1.0 #应该采样的请求的概率。
#例如。 1.0-应抽样100%的请求。 精度仅是整数(即不支持0.1%的迹线). 如果是1.0就会保存所有的请求。service-provider的yml
spring:
application:
name: service-provider
cloud:
consul:
host: localhost
port: 8500
discovery:
register: true #是否需要注册
instance-id: ${spring.application.name}-01 #实例名称(必须唯一)
service-name: ${spring.application.name} #服务名称
port: ${server.port} #服务端口
prefer-ip-address: true #是否使用ip注册服务
ip-address: ${spring.cloud.client.ip-address} #请求服务ip地址
config:
enabled: true #是否开启配置中心
format: yaml #配置文件格式,这里用的yaml
profile-separator: "-" #例如: service-provider和dev中间的符号 用-就是service-provider-dev
data-key: data #默认的值就是data 是config的key
prefix: config #默认的值就是config 是配置的前缀
profiles:
active: dev
zipkin:
base-url: http://localhost:9411/
sender:
type: web #传输方式,web、rabbit、kafka、rocketmq
sleuth:
sampler:
probability: 1.0 #应该采样的请求的概率。
#例如。 1.0-应抽样100%的请求。 精度仅是整数(即不支持0.1%的迹线). 如果是1.0就会保存所有的请求。
server:
port: 90912、pom.xml
因为需要用sleuth和zipkin,依赖必须导。保证三个微服务都有
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
<version>2.2.1.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
<version>2.2.1.RELEASE</version>
</dependency>3、启动项目
保证consul和zipkin服务端都已经运行
zipkin启动: java -jar zipkin....jar
consul启动: consul.exe agent -dev
启动后分别访问:localhost:8500 localhost:9411
启动三个微服务项目,查看consul都已经注册上去了

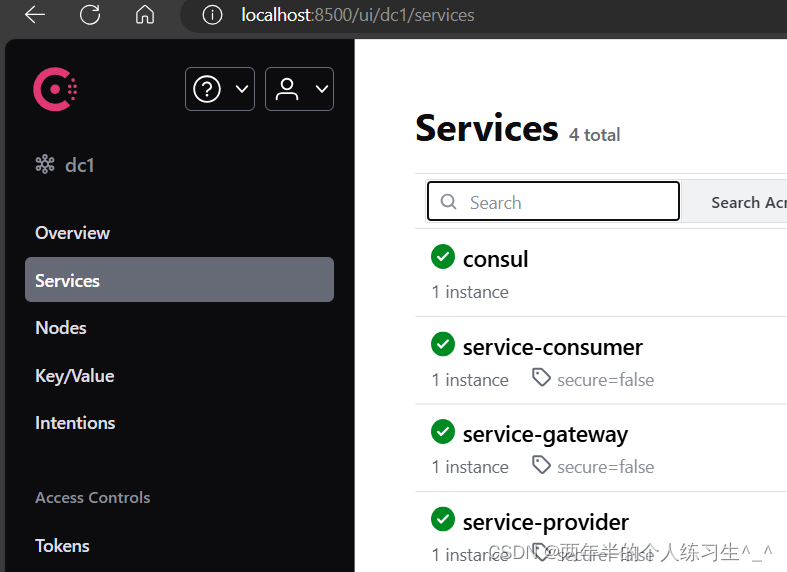
4、测试
接口逻辑1:通过gateway网关访问consumer服务,consumer服务调用provider服务
接口逻辑2:直接访问consumer服务,consumer服务调用provider服务
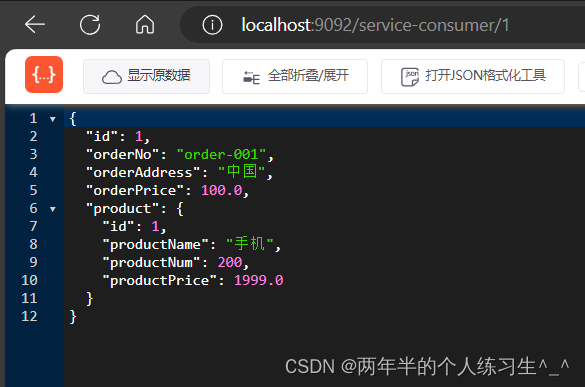
测试接口:访问localhost:9092/service-consumer/1
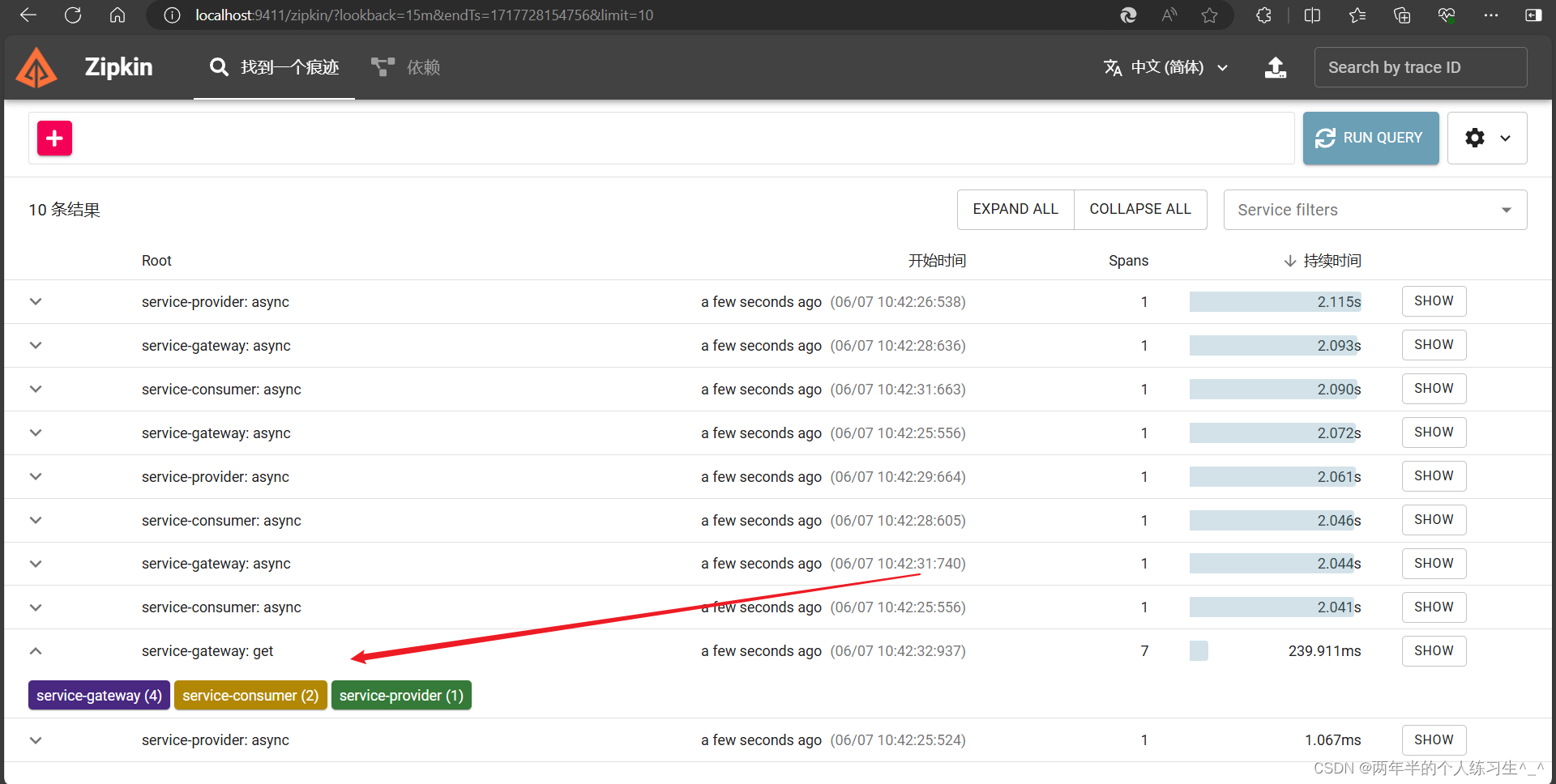
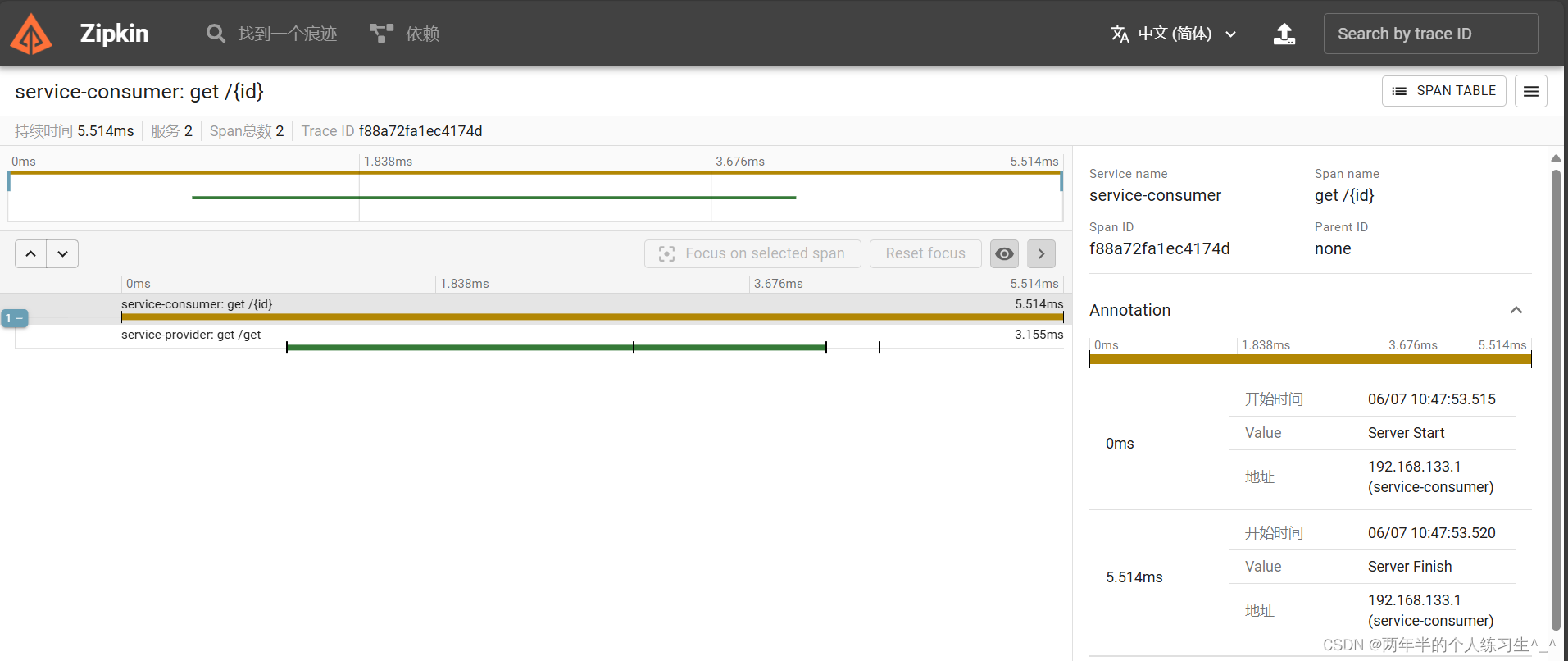
查看zipkin:
可以看到我们调用的方法,经过了三个服务的链路(其他的链路是consul的异步请求不用管)
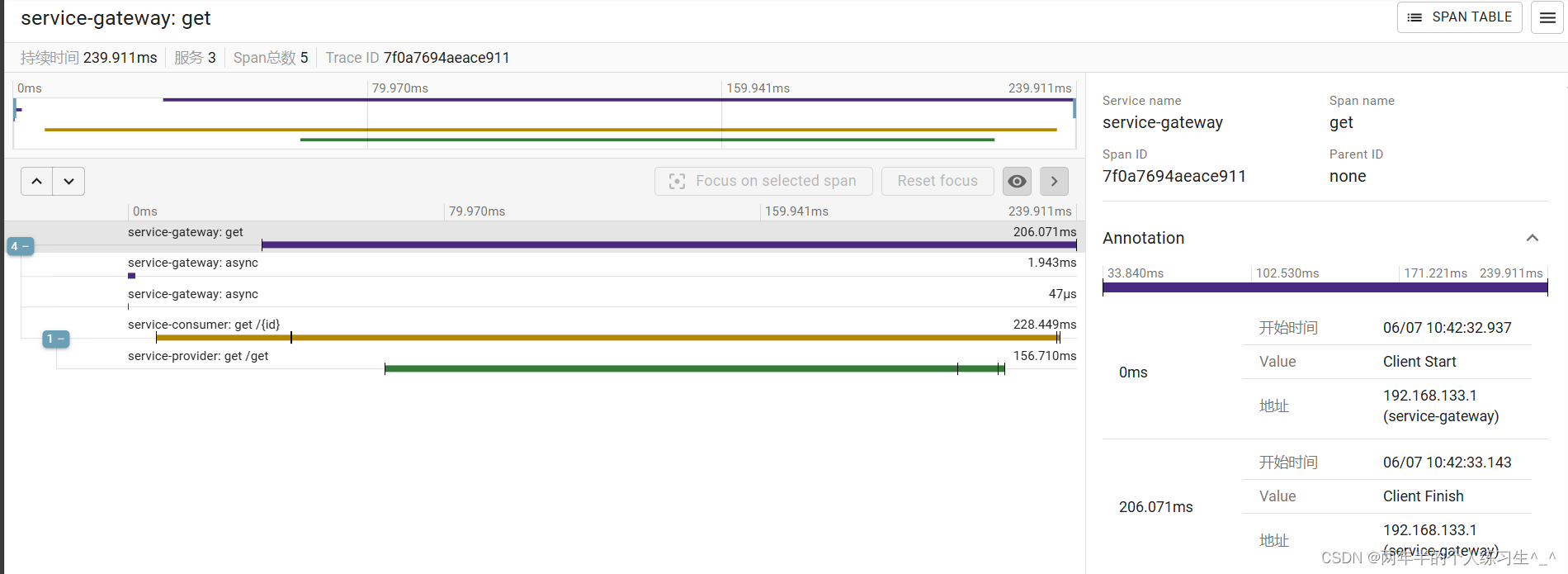
点进去查看,我们可以看到每一个服务的耗时、地址等信息。
点击依赖:
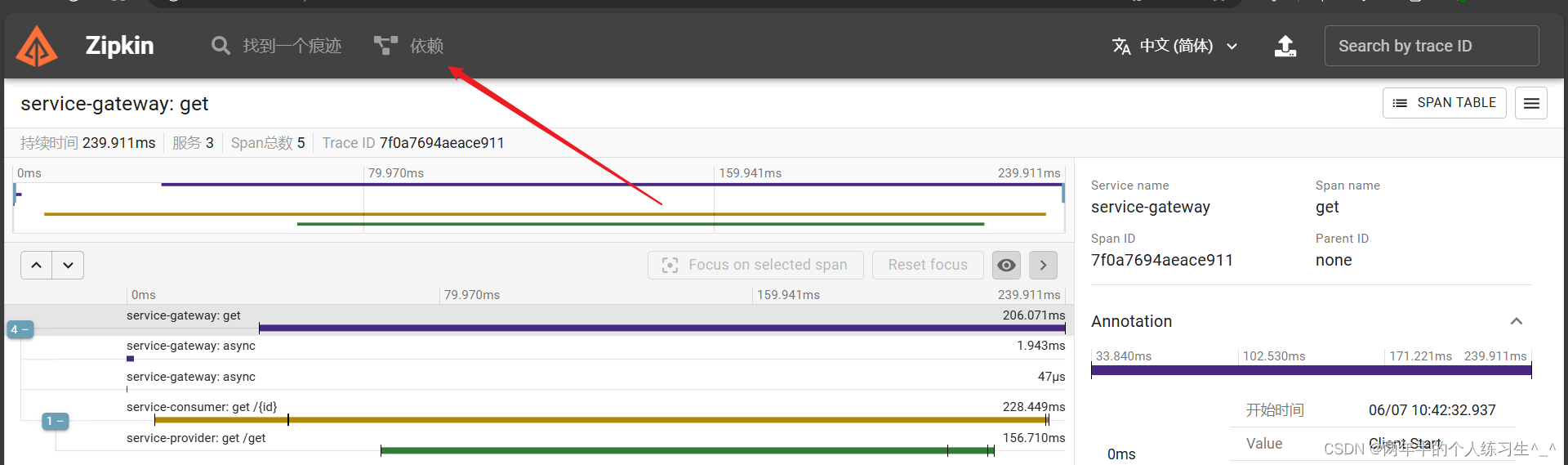
我们可以看到每个服务之间的调用关系
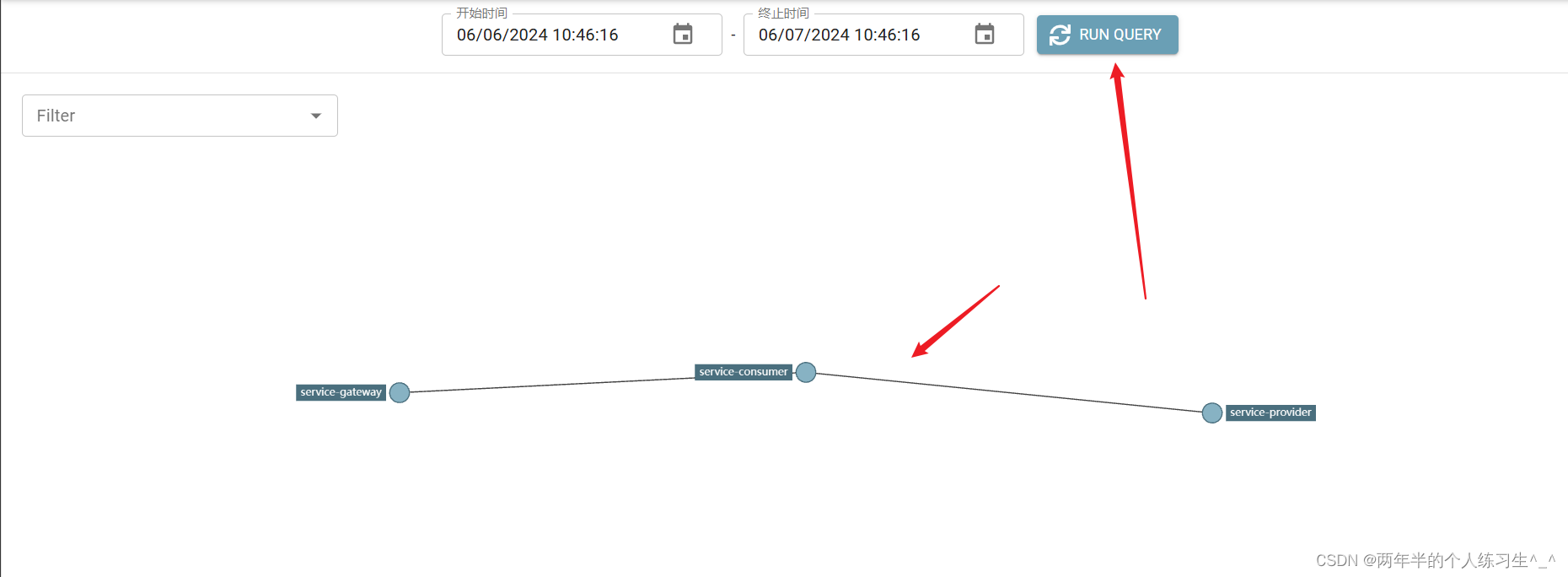
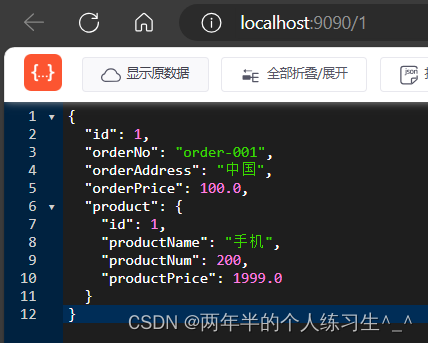
直接访问consumer服务,不经过网关:localhost:9090/1
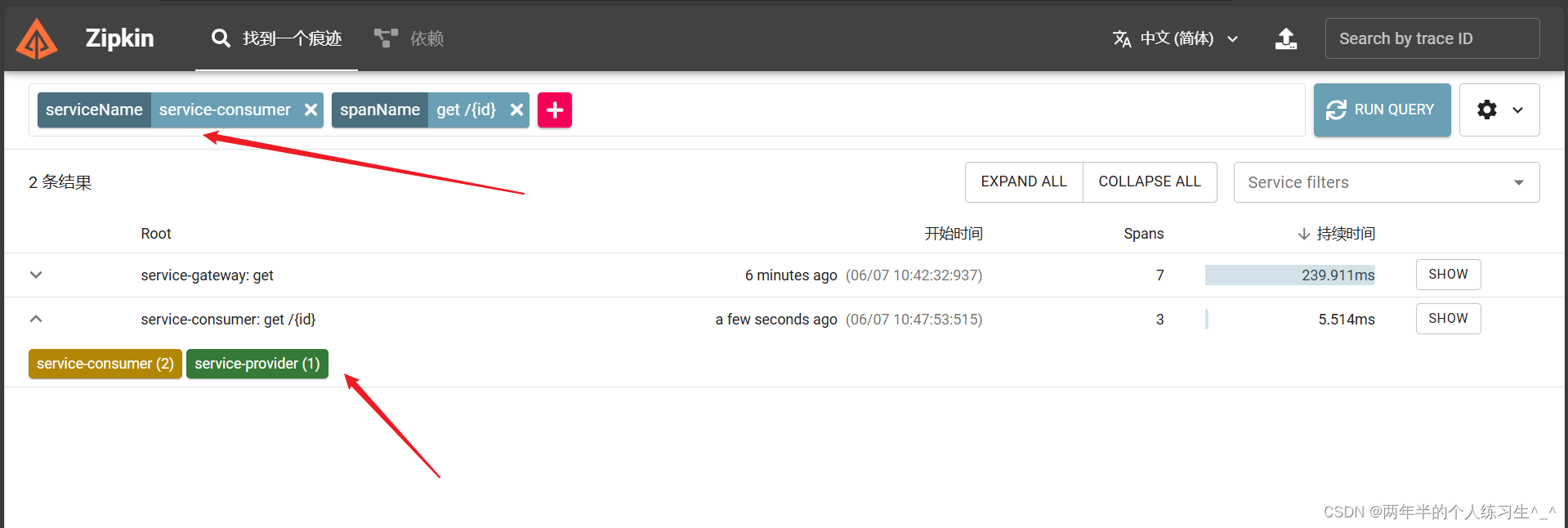
如果太多了,我们可以进行筛选:
现在的请求都是保存在内存中,如果我们重启zipkin这些链路数据就会全部丢失。
5、保存数据到数据库
不用改代码
新建数据库zipkin 建表语句(官方提供的,我复制到这里)
CREATE TABLE IF NOT EXISTS zipkin_spans (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL,
`id` BIGINT NOT NULL,
`name` VARCHAR(255) NOT NULL,
`remote_service_name` VARCHAR(255),
`parent_id` BIGINT,
`debug` BIT(1),
`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',
`duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query',
PRIMARY KEY (`trace_id_high`, `trace_id`, `id`)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`remote_service_name`) COMMENT 'for getTraces and getRemoteServiceNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range';
CREATE TABLE IF NOT EXISTS zipkin_annotations (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',
`span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',
`a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',
`a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',
`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',
`a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',
`endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces and autocomplete values';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job';
CREATE TABLE IF NOT EXISTS zipkin_dependencies (
`day` DATE NOT NULL,
`parent` VARCHAR(255) NOT NULL,
`child` VARCHAR(255) NOT NULL,
`call_count` BIGINT,
`error_count` BIGINT,
PRIMARY KEY (`day`, `parent`, `child`)
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;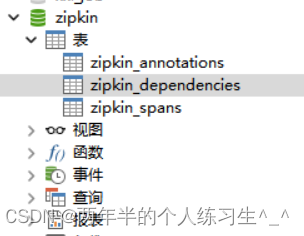
重新启动zipkin,启动命令:
java -jar zipkin-server-2.24.1-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=localhost --MYSQL_TCP_PORT=3306 --MYSQL_USER=root --MYSQL_PASS=123456 --MYSQL_DB=zipkin

可以发现数据已经存入到mysql中,当我们继续使用上面配置数据库命令启动时就会自动恢复数据库中的数据
链路信息是巨多的,长时间持续写入对数据库压力也是巨大的
6、通过mq保存数据到mysql
给三个微服务都添加rabbit依赖
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>修改配置文件:(三个都修改)
spring:
application:
name: service-provider
cloud:
consul:
host: localhost
port: 8500
discovery:
register: true #是否需要注册
instance-id: ${spring.application.name}-01 #实例名称(必须唯一)
service-name: ${spring.application.name} #服务名称
port: ${server.port} #服务端口
prefer-ip-address: true #是否使用ip注册服务
ip-address: ${spring.cloud.client.ip-address} #请求服务ip地址
config:
enabled: true #是否开启配置中心
format: yaml #配置文件格式,这里用的yaml
profile-separator: "-" #例如: service-provider和dev中间的符号 用-就是service-provider-dev
data-key: data #默认的值就是data 是config的key
prefix: config #默认的值就是config 是配置的前缀
profiles:
active: dev
zipkin:
base-url: http://localhost:9411/ #服务名称
sender:
#传输方式改为rabbit
type: rabbit #传输方式,web、rabbit、kafka、rocketmq
#指定rabbitmq的传输队列
rabbitmq:
queue: zipkin
sleuth:
sampler:
probability: 1.0
#rabbitmq相关配置
rabbitmq:
addresses: 192.168.133.102
port: 5672
username: guest
password: guest
listener:
direct:
retry:
enabled: true
max-attempts: 5
initial-interval: 5000
simple:
retry:
enabled: true
max-attempts: 5
initial-interval: 5000
server:
port: 9091
启动rabbitmq。
为了更加清楚看到链路数据发送到mq中,我们先关掉zipkin服务端。
如果打开,消息发送到mq就会被直接消费掉。
并且清空数据库之前的链路数据,清空三个表的数据。
现在队列是没有任何东西的,我们重新启动三个服务
数据库zipkin表中也没有任何数据
启动微服务项目
可以看到zipkin队列已经自动创建出来了,而且也有了消息。(注册中心调用的异步请求)
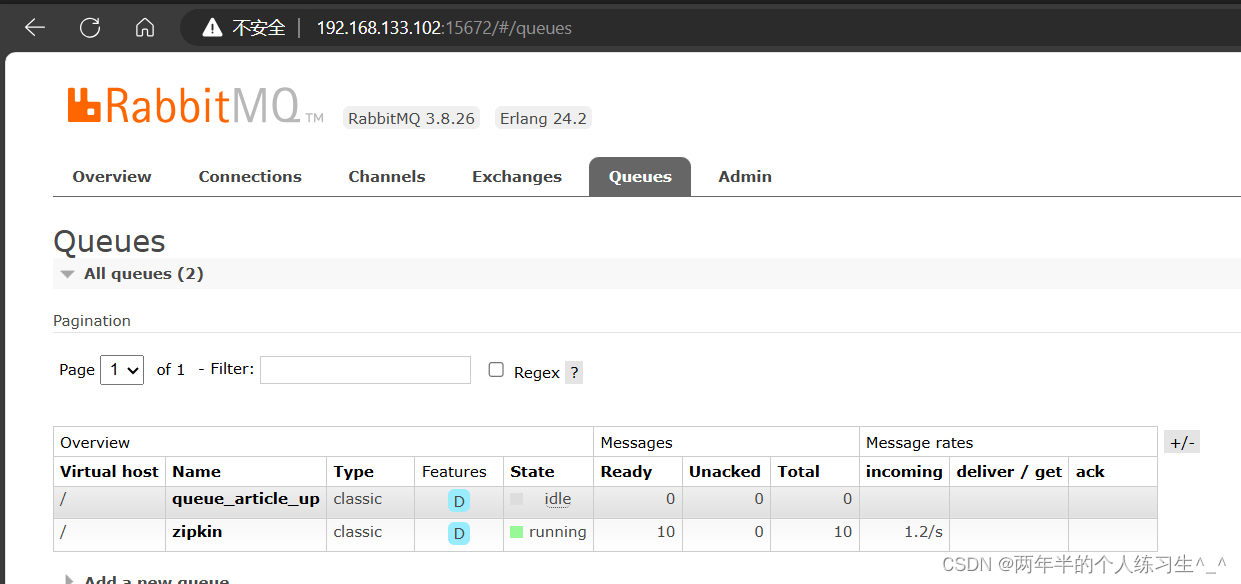
我们再调用几次接口

启动zipkin(连接信息换成自己的)
java -jar zipkin-server-2.24.1-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=localhost --MYSQL_TCP_PORT=3306--MYSQL_USER=root --MYSQL_PASS=123456 --MYSQL_DB=zipkin --RABBIT_ADDRESSES=192.168.133.102:5672 --RABBIT_USER=guest --RABBIT_P
ASSWORD=guest --RABBIT_VIRTUAL_HOST=/ --RABBIT_QUEUE=zipkin配置数据库信息和RabbitMQ连接信息
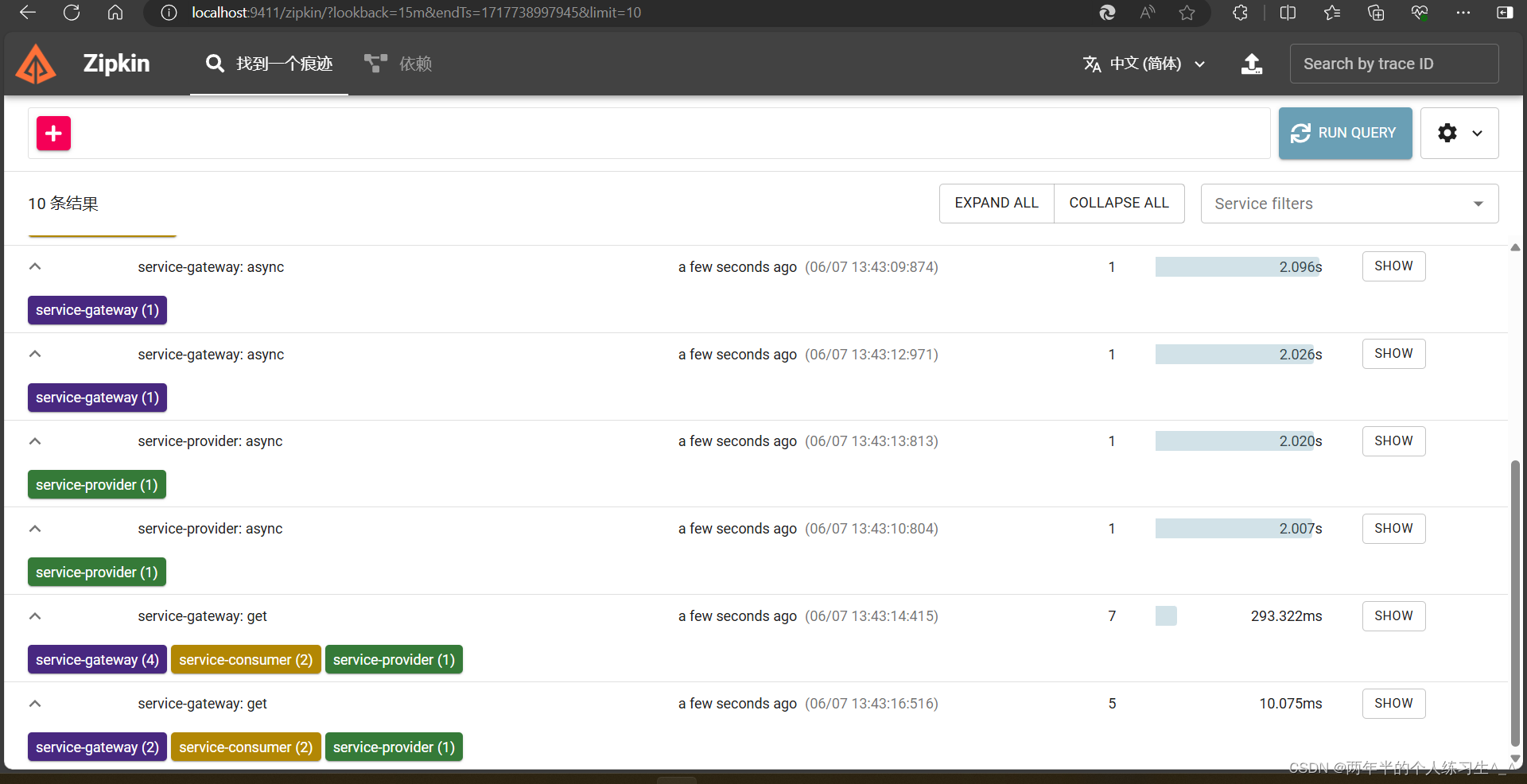
可以看到zipkin中已经有了链路数据
再查看数据库
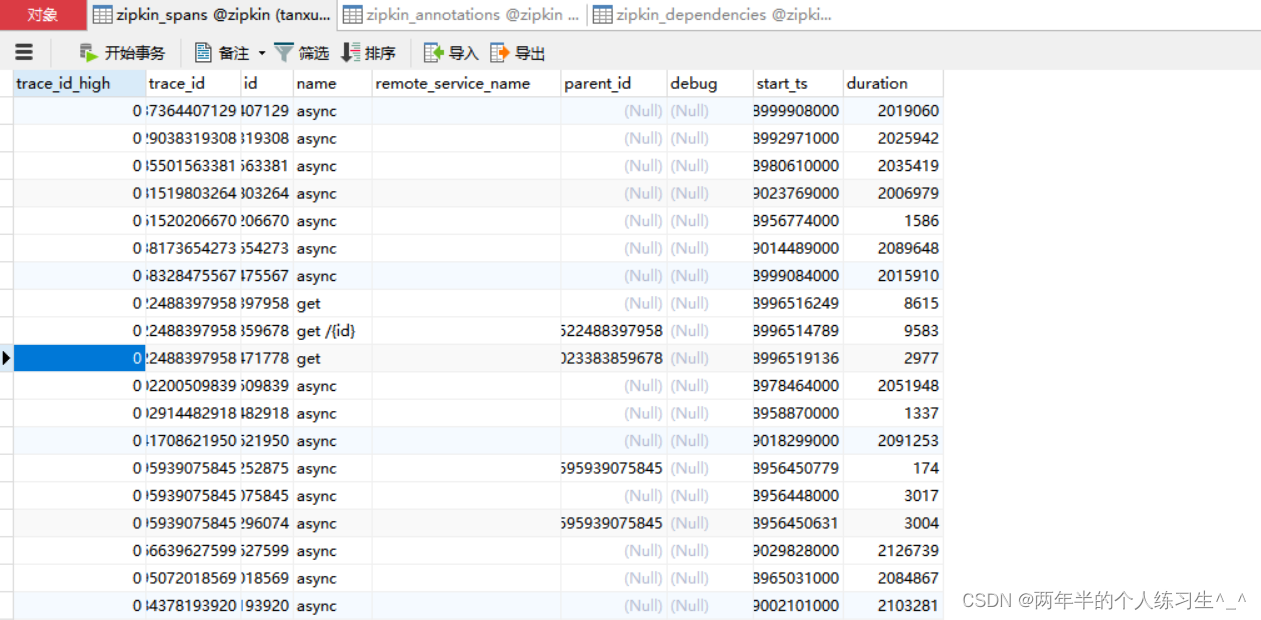
数据也已经成功保存到mysql中
7、通过mq保存数据到es
不用修改代码,启动es服务 ,启动kibana
重新启动zipkin
启动命令:(换成自己的es地址和mq地址)
java -jar zipkin-server-2.24.1-exec.jar --STORAGE_TYPE=elasticsearch --ES_HOSTS=192.168.133.102:9200 --RABBIT_ADDRESSES=192.168.133.102:5672 --RABBIT_USER=guest --RABBIT_PASSWORD=guest --RABBIT_QUEUE=zipkin
启动微服务项目
查看rabbitmq界面(已经有数据被消费了)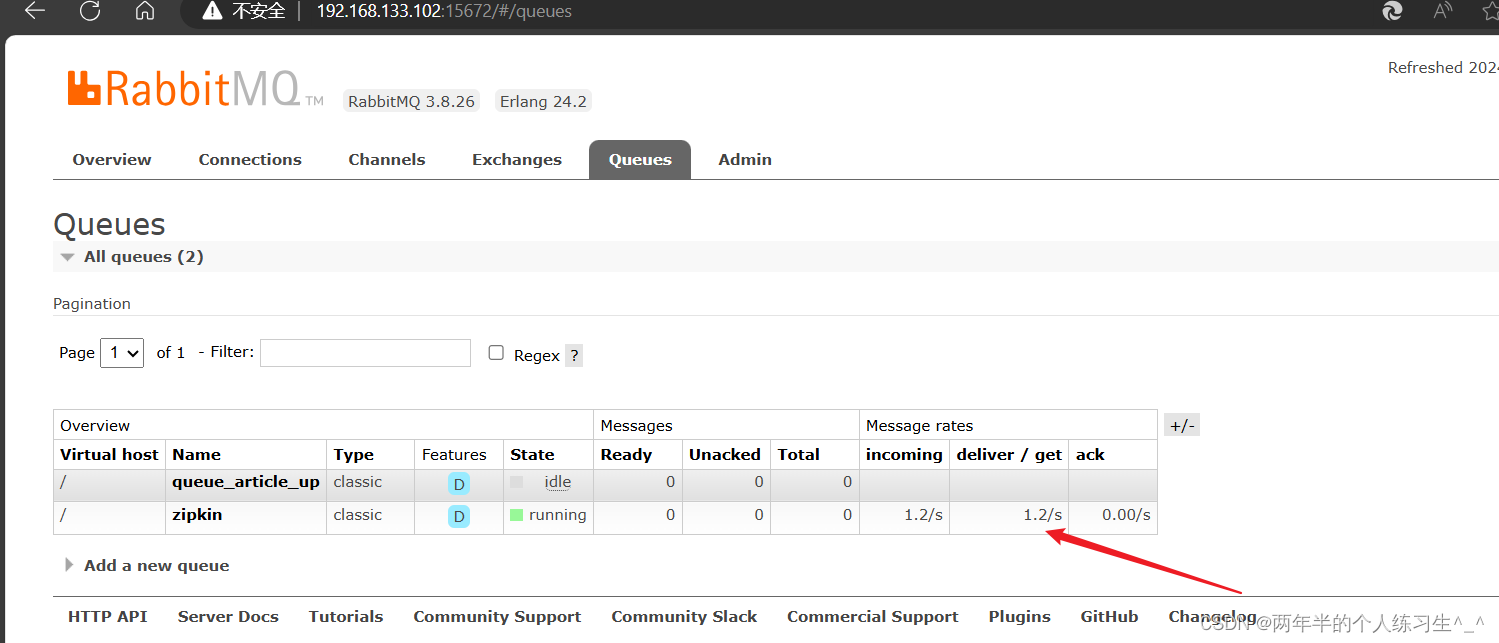
这时候查看elasticsearch
打开192.168.133.102:5601
zipkin会自动根据当前年月日创建index
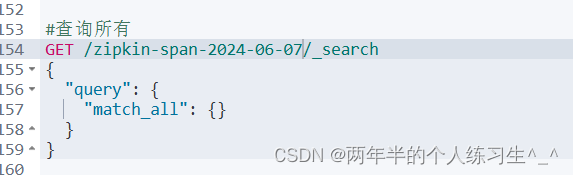
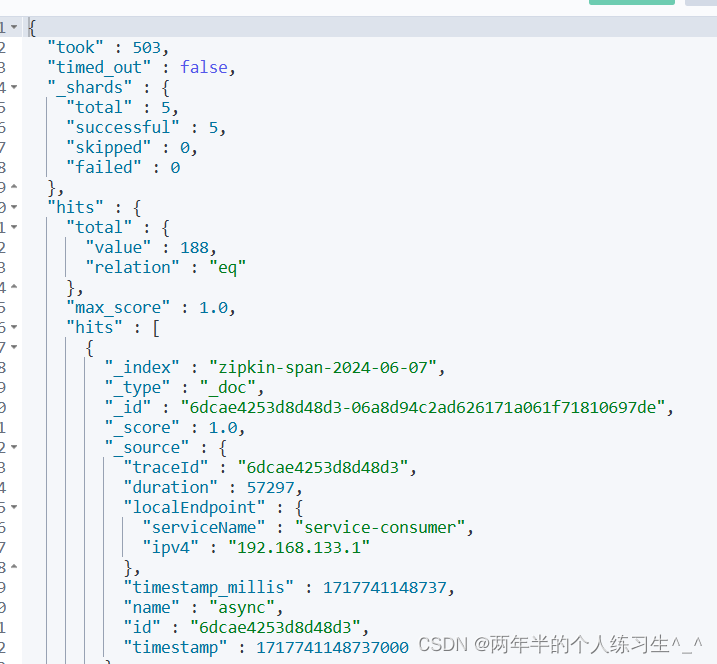
可以看到数据已经成功被存储到es中了