目录
一、引言
二、模型简介
2.1 Qwen1.5 模型概述
2.2 Qwen1.5 模型架构
三、训练与推理
3.1 Qwen1.5 模型训练
3.2 Qwen1.5 模型推理
四、总结

一、引言
Qwen是阿里巴巴集团Qwen团队的大语言模型和多模态大模型系列。现在,大语言模型已升级到Qwen1.5,共计开源0.5B、1.8B、4B、7B、14B、32B、72B、110B共计8个Dense模型以及1个14B(A2.7B)的MoE模型。多模态大模型主要是Qwen-VL图像大模型以及Qwen-Audio语音大模型。为了保证文章质量,今天重点介绍Qwen大语言模型的原理、训练及推理,Qwen-VL、Qwen-Audio在后面的篇幅另行展开。
二、模型简介
2.1 Qwen1.5 模型概述
Qwen1.5是上一代Qwen1.0的升级,Qwen2.0的beta版,与Qwen1.0一样,仍然是一个decoder-only的 transformer 模型,同时加入了 SwiGLU 激活、RoPE、多头注意力机制。相比于Qwen1.0,个人在使用过程中感觉有以下几点提升:
- 生态支持:与LLaMA-Factory、Xinference、Ollama、AutoAWQ、AutoGPTQ、llama.cpp、vLLM等开源生态搭配更加友好了,基本上就是即插即用,少了很多坑。(生态有助于一个产品迅速推广与普及,降低生态适配导致的门槛,一定会让Qwen增加更多的用户。我在之前写了一些大模型生态相关的文字,点击即达)
- 上下文size:统统调整为32K,不用再改来改去了。
- 代码合并进transformers:纯开源!不用再使用trust_remote_code了,要求transformers>=4.37.0
- 全尺寸通吃:这个太狠了,不管你有什么样的硬件条件,贫穷还是富有,Qwen都爱你。
- 所有模型均支持system prompt:更好的支持工具调用、RAG(检索增强文本生成)、角色扮演、AI Agent等(这点太关键了)
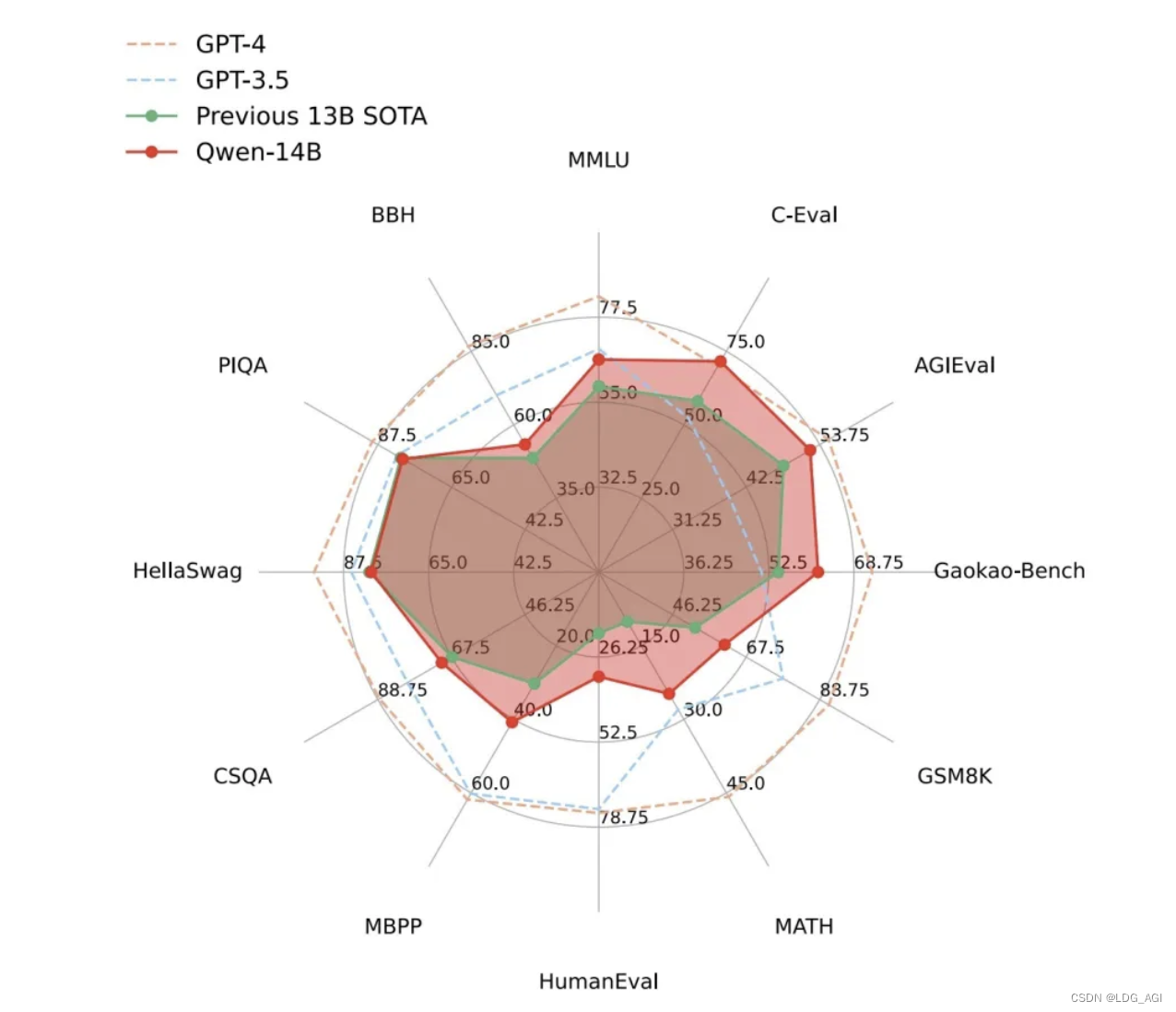
附榜单效果(其实并不重要,百模大战,兵荒马乱,自己用的顺手,感觉好才是最重要的):
2.2 Qwen1.5 模型架构
这里看一个简化的图,Qwen1.5是一个典型decoder-only的transformers大模型结构,主要包括文本输入层、embedding层、decoder层、输出层及损失函数

- 输入层:
- Tokenizer:将输入的文本序列转换为字或词标记的序列
- Input_ids:将Tokenizer生成的词标记ID化。
- Embedding层:
- 将每个ID映射到一个固定维度的向量,生成一个向量序列作为模型的初始输入表示
- Decoder层:堆叠一堆重复的Layers,每个内部相似:
- Self-Attention机制:多头自注意力机制,通俗理解每个头表示隐形的特征,针对NLP特征可以是动名词,主谓宾等,针对推荐系统可以是item标签、item类型等(我在实际工作中曾创新性的将transformer应用于推荐排序系统,构建listwise-rank环节,并取得了显著的收益,后面有机会会详细讲讲。)
class Qwen2Attention(nn.Module): """ Multi-headed attention from 'Attention Is All You Need' paper. Modified to use sliding window attention: Longformer and "Generating Long Sequences with Sparse Transformers". """ def __init__(self, config: Qwen2Config, layer_idx: Optional[int] = None): super().__init__() self.config = config self.layer_idx = layer_idx if layer_idx is None: logger.warning_once( f"Instantiating {self.__class__.__name__} without passing `layer_idx` is not recommended and will " "to errors during the forward call, if caching is used. Please make sure to provide a `layer_idx` " "when creating this class." ) self.hidden_size = config.hidden_size self.num_heads = config.num_attention_heads self.head_dim = self.hidden_size // self.num_heads self.num_key_value_heads = config.num_key_value_heads self.num_key_value_groups = self.num_heads // self.num_key_value_heads self.max_position_embeddings = config.max_position_embeddings self.rope_theta = config.rope_theta self.is_causal = True self.attention_dropout = config.attention_dropout if (self.head_dim * self.num_heads) != self.hidden_size: raise ValueError( f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}" f" and `num_heads`: {self.num_heads})." ) self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=True) self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=True) self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=True) self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False) self.rotary_emb = Qwen2RotaryEmbedding( self.head_dim, max_position_embeddings=self.max_position_embeddings, base=self.rope_theta, ) def forward( self, hidden_states: torch.Tensor, attention_mask: Optional[torch.Tensor] = None, position_ids: Optional[torch.LongTensor] = None, past_key_value: Optional[Cache] = None, output_attentions: bool = False, use_cache: bool = False, ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]: bsz, q_len, _ = hidden_states.size() query_states = self.q_proj(hidden_states) key_states = self.k_proj(hidden_states) value_states = self.v_proj(hidden_states) query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2) key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2) value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2) kv_seq_len = key_states.shape[-2] if past_key_value is not None: if self.layer_idx is None: raise ValueError( f"The cache structure has changed since version v4.36. If you are using {self.__class__.__name__} " "for auto-regressive decoding with k/v caching, please make sure to initialize the attention class " "with a layer index." ) kv_seq_len += past_key_value.get_usable_length(kv_seq_len, self.layer_idx) cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len) query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids) if past_key_value is not None: cache_kwargs = {"sin": sin, "cos": cos} # Specific to RoPE models key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs) # repeat k/v heads if n_kv_heads < n_heads key_states = repeat_kv(key_states, self.num_key_value_groups) value_states = repeat_kv(value_states, self.num_key_value_groups) attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim) if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len): raise ValueError( f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is" f" {attn_weights.size()}" ) if attention_mask is not None: if attention_mask.size() != (bsz, 1, q_len, kv_seq_len): raise ValueError( f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}" ) attn_weights = attn_weights + attention_mask # upcast attention to fp32 attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype) attn_weights = nn.functional.dropout(attn_weights, p=self.attention_dropout, training=self.training) attn_output = torch.matmul(attn_weights, value_states) if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim): raise ValueError( f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is" f" {attn_output.size()}" ) attn_output = attn_output.transpose(1, 2).contiguous() attn_output = attn_output.reshape(bsz, q_len, self.hidden_size) attn_output = self.o_proj(attn_output) if not output_attentions: attn_weights = None return attn_output, attn_weights, past_key_value- Feed-Forward Network (MLP):多层DNN神经网络感知机,用于交叉特征信息
class Qwen2MLP(nn.Module): def __init__(self, config): super().__init__() self.hidden_size = config.hidden_size self.intermediate_size = config.intermediate_size self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False) self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False) self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False) self.act_fn = ACT2FN[config.hidden_act] def forward(self, hidden_state): return self.down_proj(self.act_fn(self.gate_proj(hidden_state)) * self.up_proj(hidden_state))- Residual Connection:残差连接网络,在深度学习中经常用到的技巧,在神经网络的层与层之间添加一个直接的连接,允许输入信号无损地传递到较深的层。这样设计的目的是为了缓解梯度消失和梯度爆炸问题,同时促进梯度在深层网络中的流畅传播,使得训练更高效,模型更容易学习复杂的特征
class Qwen2DecoderLayer(nn.Module): def __init__(self, config: Qwen2Config, layer_idx: int): super().__init__() self.hidden_size = config.hidden_size if config.use_sliding_window and config._attn_implementation != "flash_attention_2": logger.warning_once( f"Sliding Window Attention is enabled but not implemented for `{config._attn_implementation}`; " "unexpected results may be encountered." ) self.self_attn = QWEN2_ATTENTION_CLASSES[config._attn_implementation](config, layer_idx) self.mlp = Qwen2MLP(config) self.input_layernorm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps) self.post_attention_layernorm = Qwen2RMSNorm(config.hidden_size, eps=config.rms_norm_eps) def forward( self, hidden_states: torch.Tensor, attention_mask: Optional[torch.Tensor] = None, position_ids: Optional[torch.LongTensor] = None, past_key_value: Optional[Tuple[torch.Tensor]] = None, output_attentions: Optional[bool] = False, use_cache: Optional[bool] = False, ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]: residual = hidden_states hidden_states = self.input_layernorm(hidden_states) # Self Attention hidden_states, self_attn_weights, present_key_value = self.self_attn( hidden_states=hidden_states, attention_mask=attention_mask, position_ids=position_ids, past_key_value=past_key_value, output_attentions=output_attentions, use_cache=use_cache, ) hidden_states = residual + hidden_states # Fully Connected residual = hidden_states hidden_states = self.post_attention_layernorm(hidden_states) hidden_states = self.mlp(hidden_states) hidden_states = residual + hidden_states outputs = (hidden_states,) if output_attentions: outputs += (self_attn_weights,) if use_cache: outputs += (present_key_value,) return outputs- Normalization层(如RMSNorm):标准化,这里使用RMSNorm(均方根标准化)代替LayerNorm(层标准化),具有加速训练和改善模型的泛化能力的效果,在实际的推荐系统工作中经常用到BatchNorm(批量标准化),在神经元激活函数前,加上一个BN层,使得每个批次的神经元输出遵循标准正态分布,解决深度传播过程中随数据分布产生的协变量偏移问题。
class Qwen2RMSNorm(nn.Module): def __init__(self, hidden_size, eps=1e-6): """ Qwen2RMSNorm is equivalent to T5LayerNorm """ super().__init__() self.weight = nn.Parameter(torch.ones(hidden_size)) self.variance_epsilon = eps def forward(self, hidden_states): input_dtype = hidden_states.dtype hidden_states = hidden_states.to(torch.float32) variance = hidden_states.pow(2).mean(-1, keepdim=True) hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon) return self.weight * hidden_states.to(input_dtype)- Rotary Position Embedding(RoPE):旋转位置编码,LLaMA也在用,可以更好的学习词之间的位置信息。后面开文章重点讲。
def apply_rotary_pos_emb(q, k, cos, sin, position_ids, unsqueeze_dim=1): cos = cos[position_ids].unsqueeze(unsqueeze_dim) sin = sin[position_ids].unsqueeze(unsqueeze_dim) q_embed = (q * cos) + (rotate_half(q) * sin) k_embed = (k * cos) + (rotate_half(k) * sin) return q_embed, k_embed
模型结构配置(config.json),看看上面网络结构中的数据具体如何配置的:
{
"architectures": [
"Qwen2ForCausalLM"
],
"attention_dropout": 0.0,
"bos_token_id": 151643,
"eos_token_id": 151645,
"hidden_act": "silu",
"hidden_size": 8192,
"initializer_range": 0.02,
"intermediate_size": 49152,
"max_position_embeddings": 32768,
"max_window_layers": 70,
"model_type": "qwen2",
"num_attention_heads": 64,
"num_hidden_layers": 80,
"num_key_value_heads": 8,
"rms_norm_eps": 1e-06,
"rope_theta": 1000000.0,
"sliding_window": 32768,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.37.2",
"use_cache": true,
"use_sliding_window": false,
"vocab_size": 152064
}
- vocab_size=152064,#词库大小,比deepseek v2多50%,deepseek v2是102400,
- hidden_size=8192,#隐层的维度,默认8192,deepseek v2默认4096
- intermediate_size=49152,#MLP的维度,默认49152,deepseek v2默认11008
- num_hidden_layers=80,#在transformer decoder中隐层的数量,默认30
- num_attention_heads=64,#多头注意力机制的头数,deepseek v2默认32
- num_key_value_heads=8,
- #用于实现分组查询注意力的 key_value 头的数量
- #如果`num_key_value_heads=num_attention_heads`,模型将使用多头注意力(MHA),
- #如果`num_key_value_heads=1 时,模型将使用多查询注意 (MQA),否则将使用 GQA。
- #当将多头检查点转换为 GQA 检查点,应构造每个组键和值头。意思是meanpooling该组内的所有original heads
- #详细说明见(https://arxiv.org/pdf/2305.13245.pdf)
- #默认num_key_value_heads=num_attention_heads
- hidden_act="silu",#decoder中非线性激活函数,默认为silu
- max_position_embeddings=32768,#上下文是32K
- initializer_range=0.02,#用于初始化所有权重矩阵的 truncated_normal_initializer 的标准差
- rms_norm_eps=1e-6,#均方根归一化层使用的 epsilon,用于处理浮点数比较时的误差或精度问题,通常是个很小的值。
- use_cache=True,模型是否应该返回最后的key value注意力的值(并非所有模型都使用)。仅当 `config.is_decoder=True` 才有意义
- bos_token_id=151643,#token流开始的id,与词表大小相近
- eos_token_id=151645,#token流结束的id,与词表大小相近
- rope_theta=1000000.0,#ROPE旋转位置编码里theta的空间,ROPE是一种位置编码算法,通过优化的矩阵乘法方式为Q/K引入位置信息,使得token能够在Attention计算中感知到相对位置信息。
Tips:
具体实现中还有Drop out(在训练过程中随机丢弃部分神经元)以及权重初始化(Xavier或He初始化)等策略,用来提升泛化能力以及加快训练速度。大模型中有太多地方都和推荐系统相通了,优化的方法包括但不限于:Xavier及He对权重标准化、BatchNorm对神经元标准化、Drop out随机丢弃神经元以及weight_decay对loss进行惩罚。是不是可以将大模型中的词,理解为推荐系统中的feature呢?
三、训练与推理
3.1 Qwen1.5 模型训练
今天这里还是使用LLaMA-Factory进行SFT微调训练,上文中提到了Qwen1.5对生态结合度更高,尤其是对LLaMA-Factory,训练起来一点坑没有,爽!关于LLaMA-Factory可以看我的这两篇文章:
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战
第一篇在百度“LLaMA Factory 部署”词条排行第一:

第二篇让我第一次冲进热榜(2024.5.26),最高排名第7,随后开启了篇篇上榜之路,一周(2024.5.27-2024.6.2)涨粉1400个。
言归正传,SFT训练启动代码:
CUDA_VISIBLE_DEVICES=2 llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path qwen/Qwen1.5-14B-Chat \
--finetuning_type lora \
--quantization_bit 4 \
--template qwen \
--flash_attn auto \
--dataset_dir data \
--dataset alpaca_zh \
--cutoff_len 1024 \
--learning_rate 5e-05 \
--num_train_epochs 20.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 2 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 10 \
--save_steps 1000 \
--warmup_steps 0 \
--optim adamw_torch \
--packing False \
--report_to none \
--output_dir saves/Qwen1.5-14B-Chat/lora/train_2024-06-03-22-15 \
--fp16 True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target q_proj,v_proj \
--val_size 0.1 \
--evaluation_strategy steps \
--eval_steps 1000 \
--per_device_eval_batch_size 2 \
--load_best_model_at_end True \
--plot_loss True这里受资源限制,采用int4量化。本人只有V100显卡,单卡最大显存32G,而微调训练需要32G多一点,可以启动,但训练一会儿直接爆显存。
Qlora训练资源快速计算(需要存储原始参数+微调参数两部分):
- int4:模型尺寸*1.25
- fp16:模型尺寸*2.3
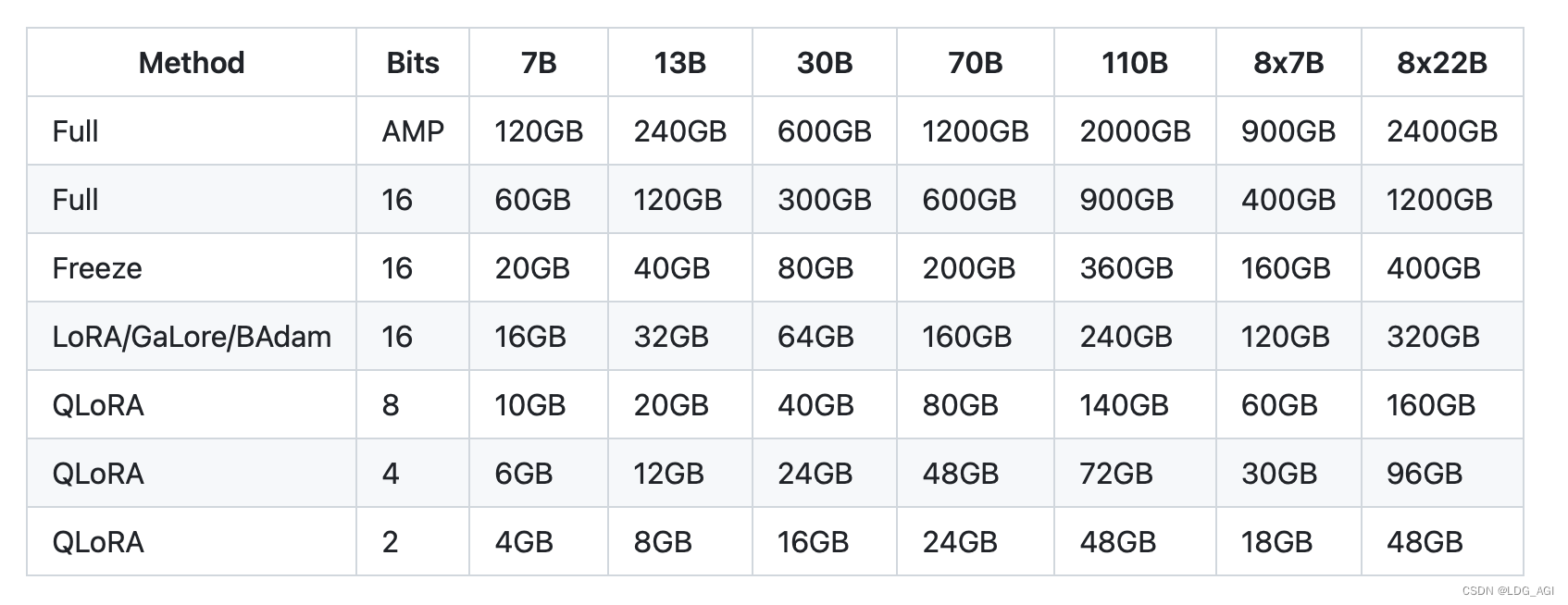
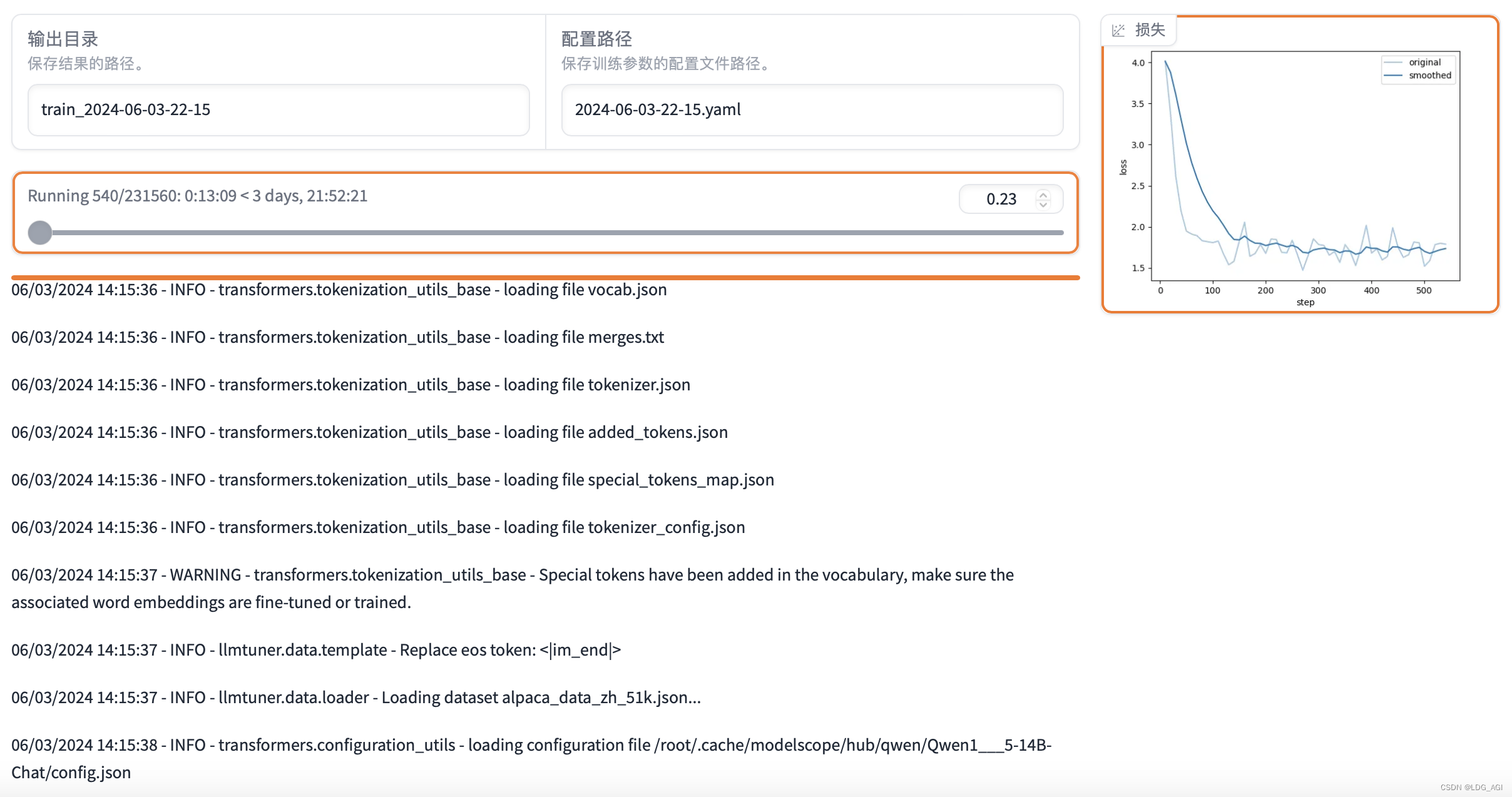
启动后,webui、docker logs或者save目录中的running_logs日志文件可以查看日志状态。

相较于deepseek v2,qwen启动的启动以及收敛真的好快!
3.2 Qwen1.5 模型推理
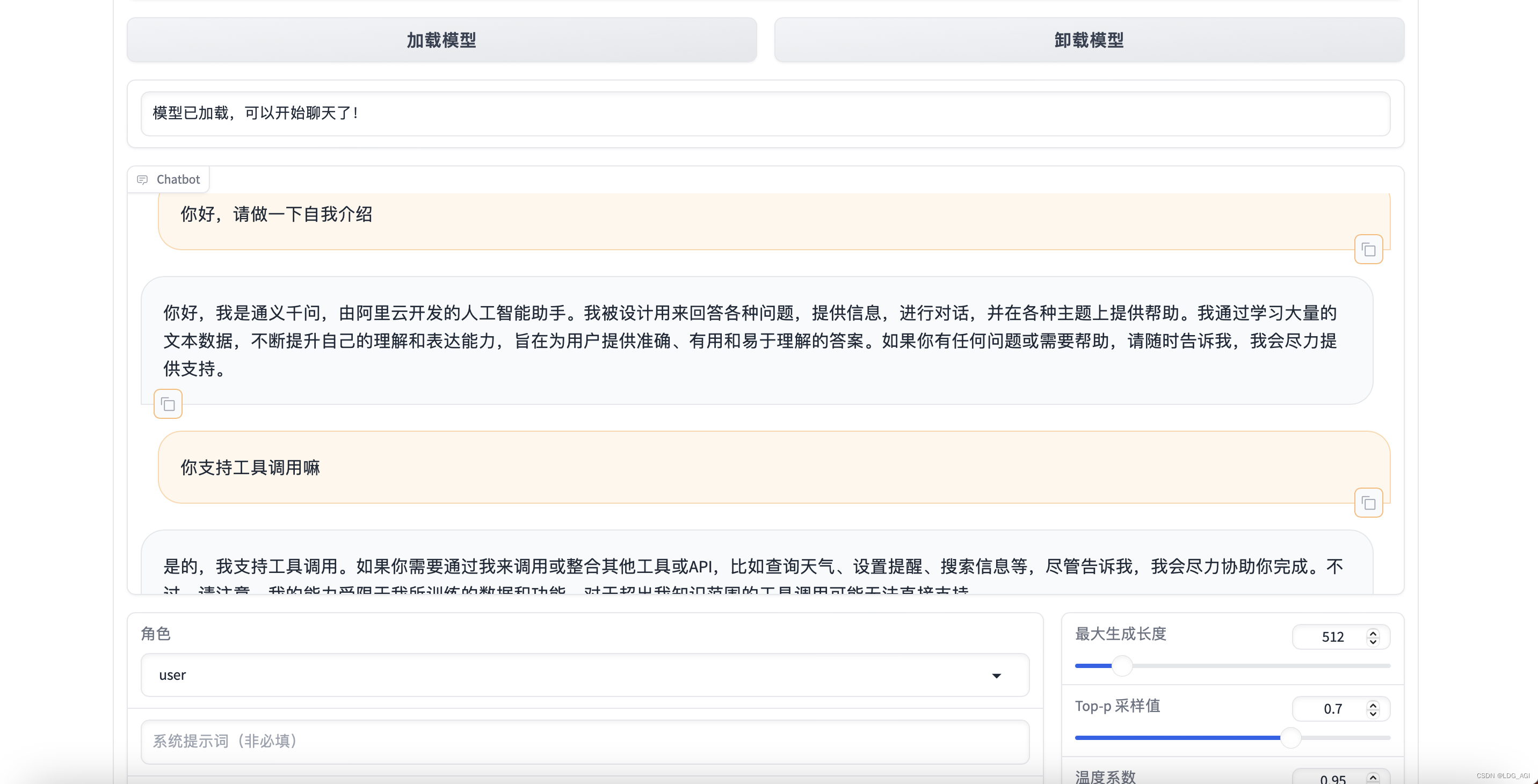
这里还是采用LLaMA Factory WebUI的chat部分进行模型推理测试,有一个推理显存快速计算公式分享给大家:
hf推理资源快速计算:
- int4:模型尺寸*0.75
- fp16:模型尺寸*2
比如今天采用Qwen1.5-14B-Chat进行推理,int4量化需要显存10G,fp16需要28G。

Chat效果测试: 与DeepSeek V2-16B-Chat比,推理速度和回复逻辑更加合理一些(DeepSeek V2-16B-Chat测试传送门)
四、总结
本文首先对Qwen1.5进行了概述,随后结合个人工作简要介绍了模型架构,最后对采用LLaMA-Factory大模型训练框架对Qwen1.5-14B-Chat的微调训练与推理进行测试。小道消息,马上就要正式发布Qwen2了,本博客也会第一时间跟进新版本的变化,如果感兴趣,期待您的关注与三连噢。
如果您还有时间,可以看看我的其他文章:
《AI—工程篇》
AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署
AI智能体研发之路-工程篇(三):大模型推理服务框架Ollama一键部署
AI智能体研发之路-工程篇(四):大模型推理服务框架Xinference一键部署
AI智能体研发之路-工程篇(五):大模型推理服务框架LocalAI一键部署
《AI-模型篇》
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战
AI智能体研发之路-模型篇(三):中文大模型开、闭源之争
AI智能体研发之路-模型篇(四):一文入门pytorch开发
AI智能体研发之路-模型篇(五):pytorch vs tensorflow框架DNN网络结构源码级对比
AI智能体研发之路-模型篇(六):【机器学习】基于tensorflow实现你的第一个DNN网络
AI智能体研发之路-模型篇(七):【机器学习】基于YOLOv10实现你的第一个视觉AI大模型




![[AIGC] 详解Mockito - 简单易学的Java单元测试框架](https://img-blog.csdnimg.cn/img_convert/9006239c81011c103d3f8fdd51bdd324.jpeg)