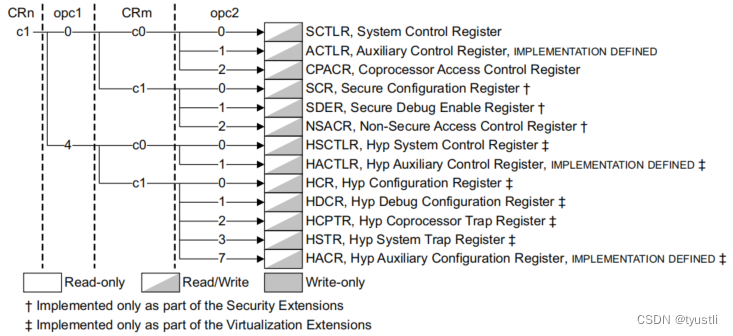
一、基本介绍
在C语言中,处理文件编码(如UTF-8或GBK)时,需要注意C标准库中的文件操作函数(如fopen, fread, fwrite, fclose等)并不直接支持Unicode或特定字符集的编码。这些函数通常处理字节流,而不是字符流,因此需要确保在读取或写入文件时以正确的编码格式处理这些字节。
对于UTF-8编码,由于它是兼容ASCII的,并且是一个变长编码,可以直接使用C标准库的文件操作函数。但是,对于GBK(或GB2312、GB18030),可能需要使用特定的库(如ICU或 iconv)来在C语言中处理这种编码,或者确保操作环境(如操作系统或文本编辑器)能够正确解释这些文件。
二、UTF-8编码文件测试代码
基本的示例简单演示如何在C语言中写入和读取UTF-8编码的文件。
//写入UTF-8文件
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(void)
{
FILE *file = fopen("utf8_text.txt", "w");
if (file == NULL)
{
perror("Error opening file");
return EXIT_FAILURE;
}
// UTF-8编码的字符串(对于ASCII字符,UTF-8编码与ASCII相同)
const char *text = "你好,世界!";
fwrite(text, sizeof(char), strlen(text), file);
fclose(file);
return 0;
}
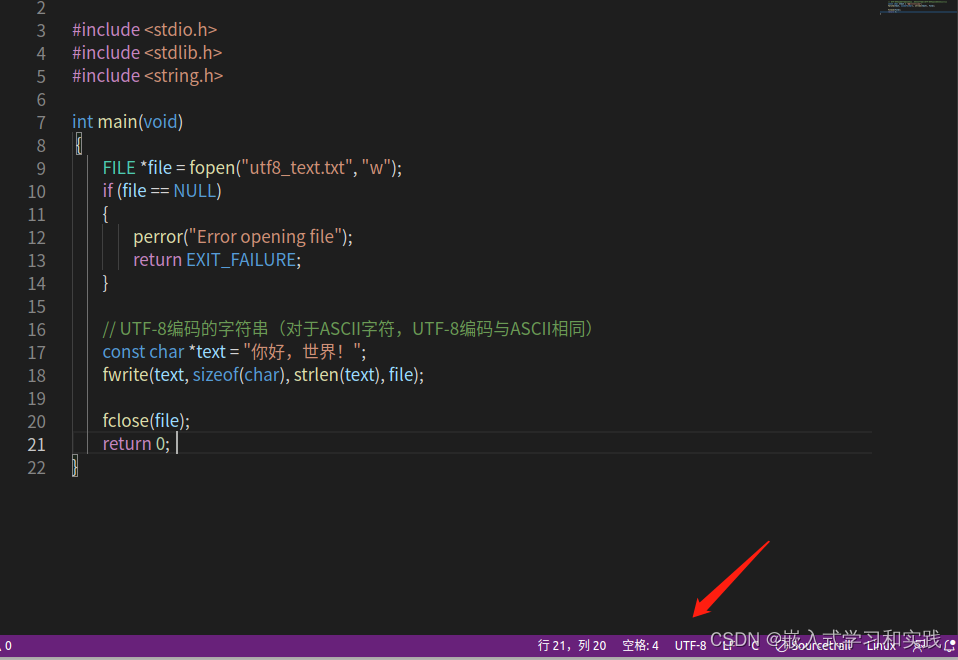
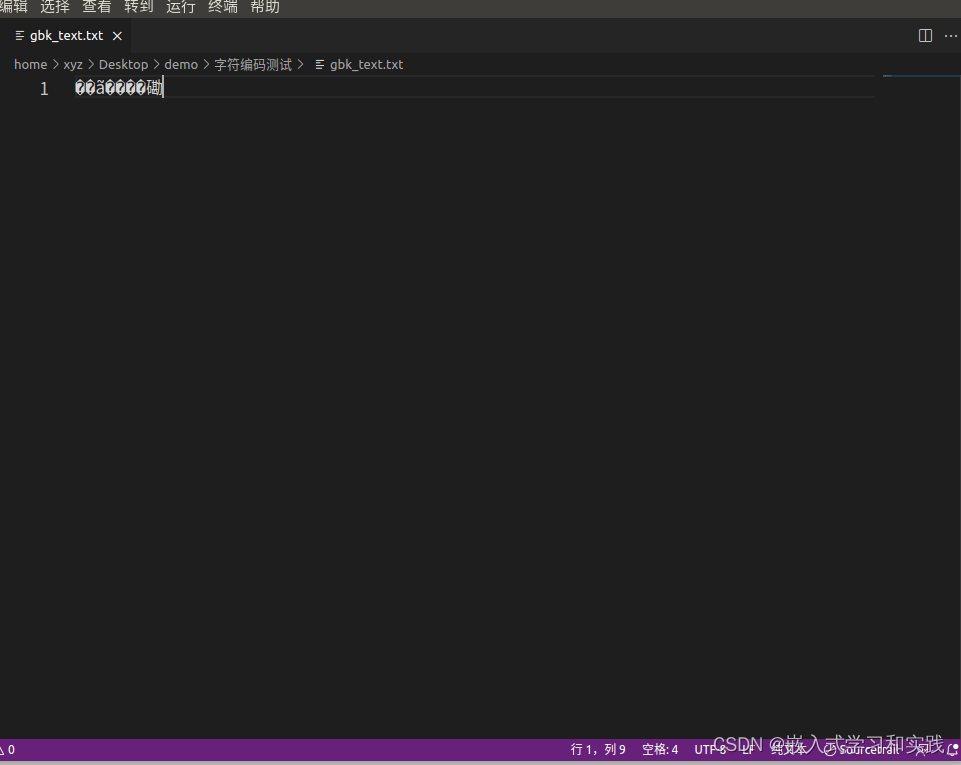
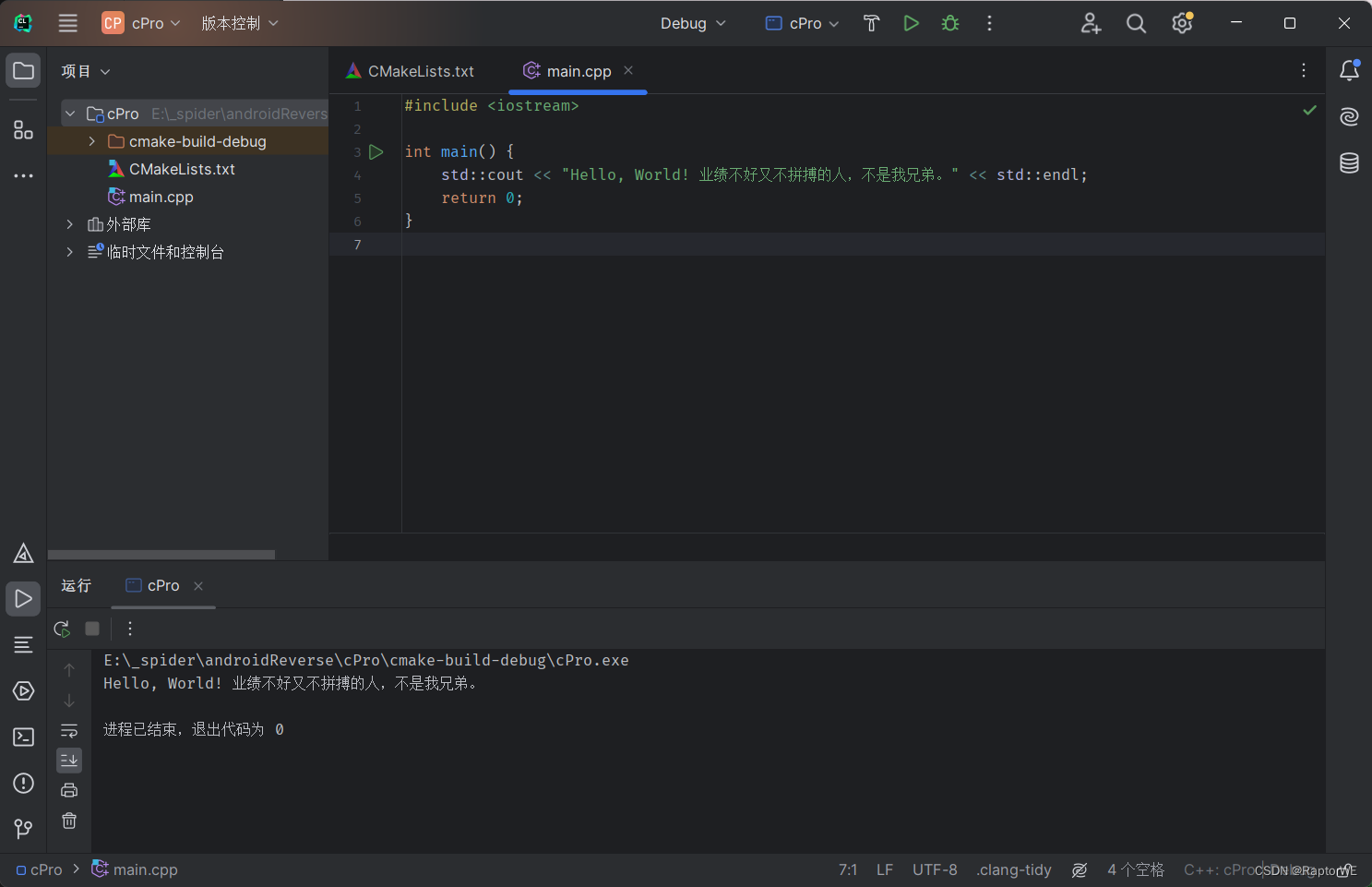
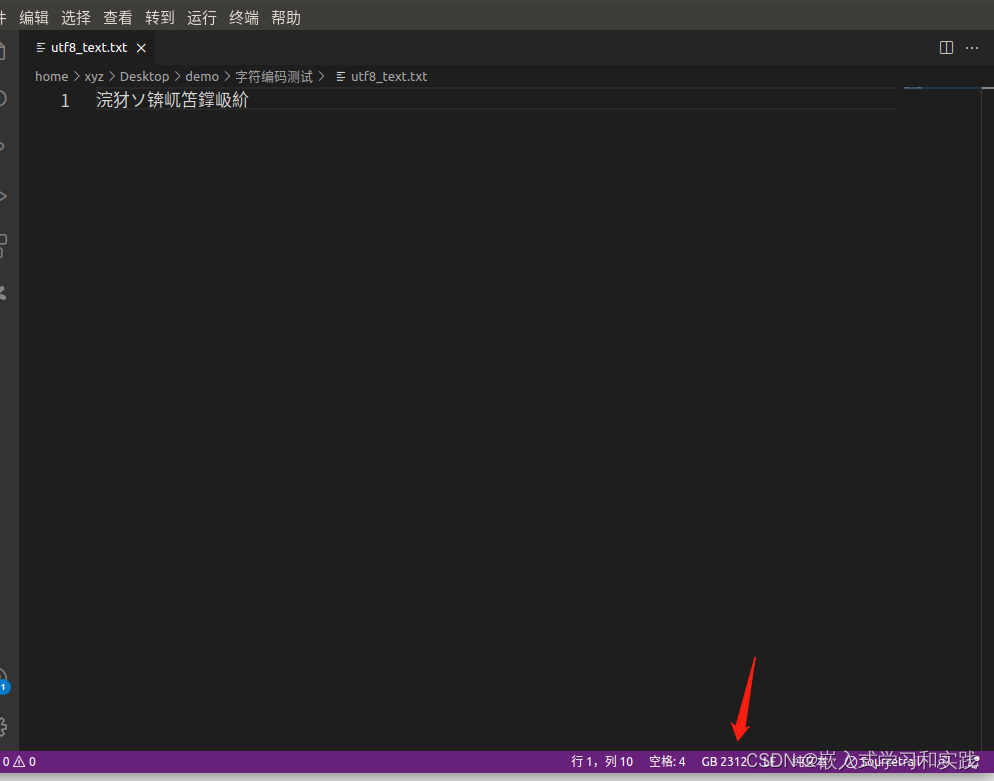
查看写入的文本文件
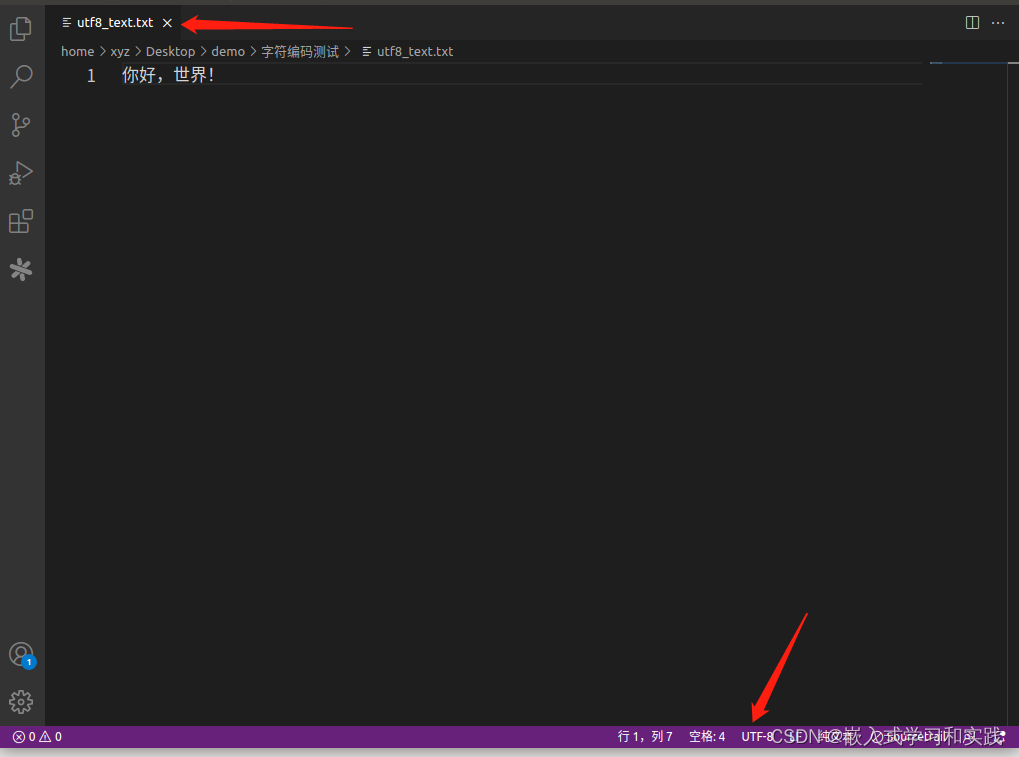
如果切换为别的格式,则会显示乱码,如下:
//读取UTF-8文件
#include <stdio.h>
#include <stdlib.h>
#define BUFFER_SIZE 1024
int main(void)
{
FILE *file = fopen("utf8_text.txt", "r");
if (file == NULL)
{
perror("Error opening file");
return EXIT_FAILURE;
}
char buffer[BUFFER_SIZE];
size_t n = fread(buffer, sizeof(char), BUFFER_SIZE - 1, file);
if (n > 0)
{
buffer[n] = '\0'; // 确保字符串以null结尾
printf("%s\n", buffer);
}
fclose(file);
return 0;
}
注意:源文件和终端/控制台都支持UTF-8编码。如果环境不支持UTF-8,需要配置编译器、IDE或终端来正确显示UTF-8编码的文本。
三、GBK编码文件测试代码
如果源字符串已经是GBK编码的字节序列(即已经有了一个unsigned char[]数组,它包含了正确的GBK编码的字节),可以直接使用 fwrite 来写入文件。
如果是一个UTF-8编码的字符串,需要先将其转换为GBK编码的字节序列。这通常需要使用一个库来完成,比如Linux 下的 iconv库。
示例:将UTF-8字符串转换为GBK并写入文件。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <iconv.h>
int main(void)
{
// 原始UTF-8编码的字符串
const char *utf8_text = "你好,世界!";
size_t utf8_len = strlen(utf8_text);
// 转换输出缓冲区的大小(可能需要调整以适应实际转换的大小)
size_t gbk_size = 4 * utf8_len + 1; // 假设GBK编码的字符最多是UTF-8的4倍长,再加一个null终止符
unsigned char gbk_buffer[gbk_size];
// 初始化iconv_t转换描述符
iconv_t cd = iconv_open("GBK", "UTF-8");
if (cd == (iconv_t)-1)
{
perror("iconv_open");
return EXIT_FAILURE;
}
// 转换UTF-8到GBK
char *inbuf = (char *)utf8_text;
size_t inbytesleft = utf8_len;
char *outbuf = (char *)gbk_buffer;
size_t outbytesleft = gbk_size;
size_t result = iconv(cd, &inbuf, &inbytesleft, &outbuf, &outbytesleft);
if (result == (size_t)-1)
{
perror("iconv");
iconv_close(cd);
return EXIT_FAILURE;
}
// 确保字符串以null结尾(如果转换后的长度小于缓冲区大小)
*outbuf = '\0';
// 写入GBK编码的文件
FILE *file = fopen("gbk_text.txt", "wb"); // 使用二进制模式写入
if (file == NULL)
{
perror("Error opening file");
iconv_close(cd);
return EXIT_FAILURE;
}
fwrite(gbk_buffer, 1, outbuf - (char *)gbk_buffer, file); // 写入转换后的数据(不包括null终止符)
fclose(file);
// 关闭iconv转换描述符
iconv_close(cd);
return 0;
}
①示例中的gbk_size是一个估计值,需要根据实际情况调整它以确保转换后的数据不会溢出缓冲区。
②使用iconv函数时,输入和输出缓冲区都是char * 类型,但在这里我们将其强制转换为unsigned char * 来避免可能的符号扩展问题。在大多数情况下,这不会造成问题,因为iconv只关心字节,而不关心它们的符号。
③写入文件时使用了二进制模式(“wb”),以确保不会进行任何字符到字节的转换(例如换行符的转换)。
测试结果:
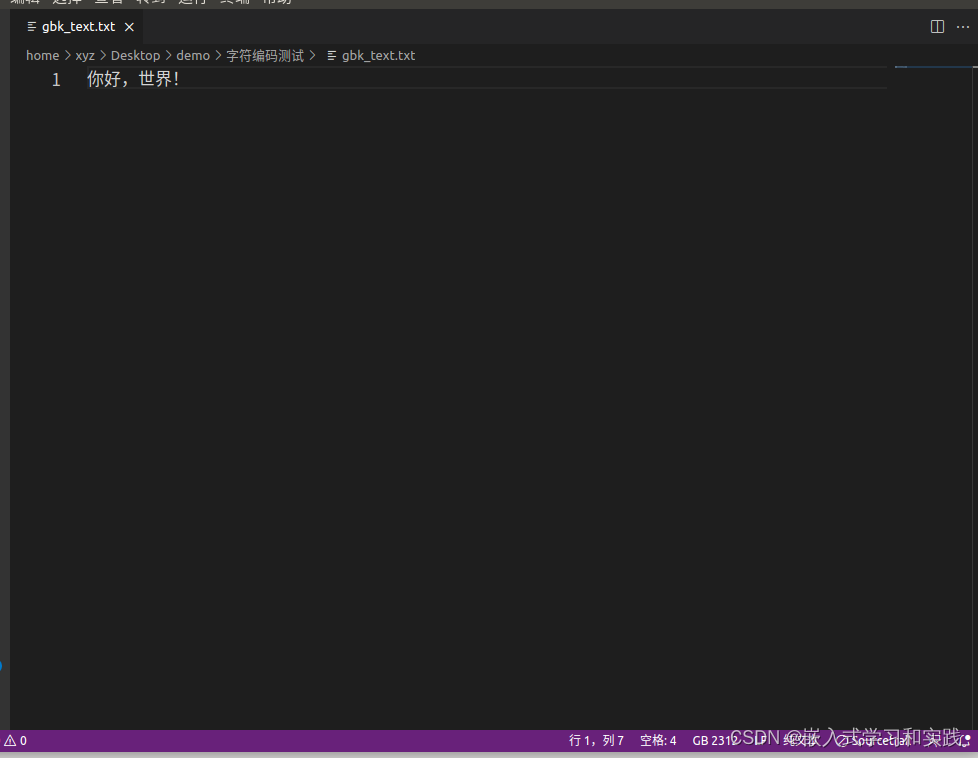
改成 UTF-8 编码则是乱码,如下: