Value at Risk(VaR)是一种统计技术,用于量化投资组合在正常市场条件下可能遭受的最大潜在损失。它是风险管理和金融领域中一个非常重要的概念。VaR通常以货币单位表示,用于估计在给定的置信水平和特定时间范围内,投资组合可能遭受的最大损失。例如,一个1%的一日VaR为$1百万意味着在任何给定的日子里,只有1%的概率投资组合的损失会超过100万美元。
VaR的主要特点和考虑因素包括:
置信水平:这是VaR计算中的一个关键参数,表示损失不会超过VaR估计的概率。常见的置信水平有95%、99%等。
时间范围:VaR估计的另一个关键方面是时间范围,比如一天、一周或一个月。时间范围越长,潜在损失的估计通常越大。
损失的估计:VaR提供了一个损失估计,但并不预测损失会发生的确切时间点。
方法论:计算VaR的方法有多种,包括历史模拟法、方差-协方差法和蒙特卡洛模拟法。每种方法都有其优缺点,适用于不同类型的投资组合。
局限性:虽然VaR是一个有用的风险度量工具,但它也有局限性。它不考虑超过VaR估计值的极端损失,且对于非线性和复杂的金融工具可能不够精确。
VaR在金融领域广泛应用,特别是在风险管理、资产管理和资本要求计算方面。银行、投资公司和其他金融机构使用VaR来监控和管理其暴露在市场、信用和其他风险中的资产组合。尽管它是一个有力的工具,但专业人士和监管机构都认识到,依赖单一风险度量标准是不足够的,需要结合其他风险管理技术和工具。
这里我选取的是googel的股票,使用dailyReturn函数算出它的收益率,前五行如下:
# 计算股票的日度收益率 # 计算对数收益率
returns <- dailyReturn(GOOGL)
returns
# 绘制收益率时序图
plot(returns, main = "Daily Returns of Alphabet (GOOGL) in the Last Year", ylab = "Daily Returns")
# 计算收益率的均值、方差和标准差
mean_return <- mean(returns, na.rm = TRUE)
variance <- var(returns, na.rm = TRUE)
std_deviation <- sd(returns, na.rm = TRUE)
# 输出均值、方差和标准差
print(paste("Mean of returns:", mean_return))
print(paste("Variance of returns:", variance))
print(paste("Standard deviation of returns:", std_deviation))daily.returns
2023-08-15 -0.0100686499
2023-08-16 -0.0083217753
2023-08-17 0.0094794095
2023-08-18 -0.0189347291
2023-08-21 0.0071394947
接下来可视化:

接下来分别使用mean,var,sd函数进行算出结果:
Mean of returns: 0.000487064370016916
Variance of returns: 0.000277345687220339
Standard deviation of returns: 0.0166536989050583
对该股票采用Weibul1分布法估计其180天周期90%置信水平的VaR序列(用前180天历史数据预测未来180天的日度VaR,并画出Va 时序图
# 自定义 Weibull 分布的估计函数
weibull_func <- function(data) {
fit <- suppressWarnings(
tryCatch(
fitdistr(data, densfun = "weibull",
start = list(shape = 1, scale = 1), # 自定义合适的初始参数值
method = "BFGS"), # 自定义拟合方法
error = function(e) NULL
)
)
return(fit)
}
# 进行 Weibull 分布的拟合
fit_weibull <- weibull_func(positive_returns)
# 使用拟合的 Weibull 分布计算 VaR
confidence_level <- 0.9
VaR_90 <- qweibull(1 - confidence_level, shape = fit_weibull$estimate[1], scale = fit_weibull$estimate[2])90% 置信水平的 VaR: 0.0023112336283049
计算所有日期的 VaR并画图

另选一只股票,采用排序法计算其一年期 70%置信度的日度 VaR,若回测时次日跌幅超过 VaR 预测的闯值,则判定为一次“违约’。采用交易量、拆幅(最高价减最低价)和收益率MACDKDJOBVCCI等来预测违约估计 logit 模型,然后评价你的模型效果 (NP、ROC、CAP),并提出些可行改进方案。
这里选取的是APPLE的股票数据,设置API接口获取:
同样也是计算日度收益率,前5行如下:
daily.returns
2023-08-15 0.0000000000
2023-08-16 -0.0049591434
2023-08-17 -0.0145551339
2023-08-18 0.0028160920
2023-08-21 0.0077368331
计算采用排序法计算其一年期 70%置信度的日度 VaR,若回测时次日跌幅超过 VaR 预测的闯值,则判定为一次“违约’。写成相应的代码:
var_70 <- quantile(returns, 0.3) # 70%分位数即为VaR
default_event <- ifelse(returns < var_70, 1, 0)
default_event
default_event输出示例如下:
daily.returns
2023-08-15 0
2023-08-16 0
2023-08-17 1
2023-08-18 0
2023-08-21 0
接下来分别计算各个特征并且最终合并文件:
# 计算日度收益率
returns <- dailyReturn(AAPL$AAPL.Close)
returns
# 计算VaR
var_70 <- quantile(returns, 0.3) # 70%分位数即为VaR
default_event <- ifelse(returns < var_70, 1, 0)
default_event
# 计算交易量
volume <- AAPL$AAPL.Volume
volume
# 计算拆幅
range <- AAPL$AAPL.High - AAPL$AAPL.Low
range
# 计算收益率
returns <- dailyReturn(AAPL$AAPL.Close)
returns
# 计算技术指标
# 计算MACD指标
macd_data <- MACD(AAPL$AAPL.Close)
macd_data
# 计算KDJ指标
Hi <- AAPL$AAPL.High
Lo <- AAPL$AAPL.Low
Cl <- AAPL$AAPL.Close
# 假设N=9天
N <- 9
# 计算RSV值
RSV <- (Cl - rollapplyr(Lo, width = N, min, align = "right")) /
(rollapplyr(Hi, width = N, max, align = "right") - rollapplyr(Lo, width = N, min, align = "right")) * 100
# 计算K值、D值和J值
K <- D <- J <- rep(NA, length(Cl))
for (i in N:length(Cl)) {
if (i == N) {
K[i] <- 50 # 初始K值为50
D[i] <- 50 # 初始D值为50
} else {
K[i] <- (RSV[i] + (N - 1) * K[i - 1]) / N
D[i] <- (K[i] + (N - 1) * D[i - 1]) / N
}
J[i] <- 3 * K[i] - 2 * D[i]
}
# 将计算结果添加到数据框中
KDJ_data <- data.frame(Date = index(AAPL), K = K, D = D, J = J)
KDJ_data最终数据合并如下:
| macd | signal | K | D | J | OBV | |
| 2023-08-15 | 0.502 | 0.607 | 56.791 | 56.537 | 57.299 | 43622593 |
| 2023-08-16 | 0.502 | 0.607 | 56.791 | 56.537 | 57.299 | -3342264 |
| 2023-08-17 | 0.502 | 0.607 | 56.791 | 56.537 | 57.299 | -69405146 |
| 2023-08-18 | 0.502 | 0.607 | 56.791 | 56.537 | 57.299 | -8232996 |
| 2023-08-21 | 0.502 | 0.607 | 56.791 | 56.537 | 57.299 | 38078883 |
| 2023-08-22 | 0.502 | 0.607 | 56.791 | 56.537 | 57.299 | 80163128 |
| CCI | Returns | macd.1 | macd_data | Volume | default_event | |
| 2023-08-15 | 15.587 | 0.000 | 0.502 | 0.607 | 43622593 | 0 |
| 2023-08-16 | 15.587 | -0.005 | 0.502 | 0.607 | 46964857 | 0 |
| 2023-08-17 | 15.587 | -0.015 | 0.502 | 0.607 | 66062882 | 1 |
| 2023-08-18 | 15.587 | 0.003 | 0.502 | 0.607 | 61172150 | 0 |
| 2023-08-21 | 15.587 | 0.008 | 0.502 | 0.607 | 46311879 | 0 |
| 2023-08-22 | 15.587 | 0.008 | 0.502 | 0.607 | 42084245 | 0 |
# 建立逻辑回归模型
# 建立 Logit 模型
model <- glm(default_event ~ ., data = train, family = binomial)
model
# 在测试集上进行预测
predicted <- predict(model, newdata = test, type = "response")
predicted

理想情况下,ROC 曲线会向左上角弯曲,靠近左上角的(0,1)点,这表明模型具有很高的真正例率和很低的假正例率。在这张图中,曲线开始时沿着 y 轴急剧上升,表明在低假正例率下模型能够实现相对较高的真正例率。总体而言,这个 ROC 曲线表明模型在某些阈值设置下对正类的预测有一定的准确性。
Area under the curve: 0.9074
曲线下面积(AUC)为 0.9074 表示模型具有很高的区分能力。
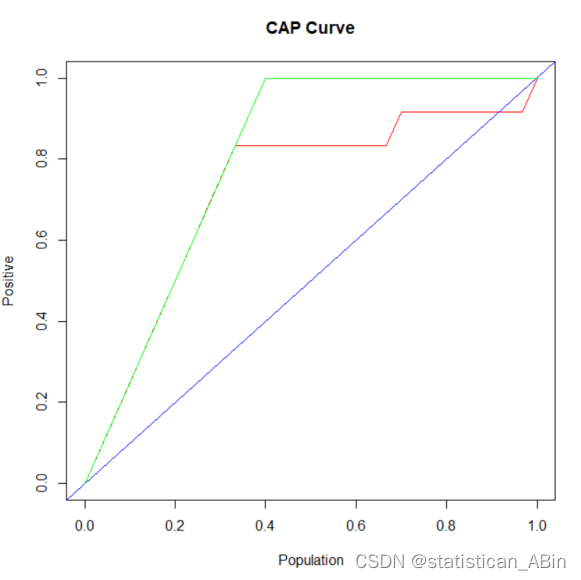
# 绘制 CAP 曲线
cap_curve <- function(actual, predicted) {
total <- length(actual)
num_positive <- sum(actual == 1)
# 确保排序后的实际值和预测值长度一致
actual_sorted <- actual[order(predicted, decreasing = TRUE)]
# 计算累积正例的比例
cum_positive <- cumsum(actual_sorted == 1) / num_positive
# 生成 x 和 y 值
x_values <- c(0, (1:total) / total)
y_values <- c(0, cum_positive)
# 确保 x_values 和 y_values 长度一致
if (length(x_values) != length(y_values)) {
stop("Lengths of x_values and y_values are not equal.")
}
# 绘制 CAP 曲线
plot(x_values, y_values, type = "l", col = "red", xlab = "Population", ylab = "Positive", main = "CAP Curve")
abline(0, 1, col = "blue") # 随机预测线
lines(c(0, sum(actual == 1) / total, 1), c(0, 1, 1), col = "green") # 理想曲线
}
# 调用函数绘制 CAP 曲线
cap_curve(test_data$default_event, predictions)基于这些指标,以下是一些改进模型性能的策略:
数据重新采样:如果数据集不平衡,即违约和非违约的案例数量有很大差异,可以尝试过采样少数类别或欠采样多数类别。也可以使用合成数据生成技术,如 SMOTE,来合成新的正例。
特征工程:检查是否有可能从现有数据中创建更有信息量的特征。评估并可能移除对预测不具有统计显著性的特征。使用特征选择技术来识别和保留最重要的特征。
模型调整:调整模型超参数,使用网格搜索或随机搜索确定最佳参数。尝试不同的模型算法,比如随机森林、支持向量机或梯度提升机,并与当前的逻辑回归模型比较。
阈值调整:改变分类的决策阈值,可能会提高正类别的预测准确性。
使用成本敏感学习,并为错误分类的类别分配不同的权重。
模型集成:使用集成方法如 Bagging 或 Boosting,这些方法可以提高模型的稳定性和性能。
考虑堆叠不同的模型来利用各自的优势。
评估指标选择:依据业务目标,选择更合适的评估指标,例如利润曲线,以确保模型优化方向与业务目标一致。
题目和代码和数据
创作不易,希望大家多多点赞收藏和评论!