论文名称:Physics of Language Models: Part 3.3, Knowledge Capacity Scaling Laws
论文地址:https://arxiv.org/pdf/2404.05405
相关博客
【自然语言处理】【Scaling Law】Observational Scaling Laws:跨不同模型构建Scaling Law
【自然语言处理】【大模型】语言模型物理学 第3.3部分:知识容量Scaling Laws
【自然语言处理】Transformer中的一种线性特征
【自然语言处理】【大模型】DeepSeek-V2论文解析
【自然语言处理】【大模型】BitNet:用1-bit Transformer训练LLM
【自然语言处理】BitNet b1.58:1bit LLM时代
【自然语言处理】【长文本处理】RMT:能处理长度超过一百万token的Transformer
【自然语言处理】【大模型】MPT模型结构源码解析(单机版)
【自然语言处理】【大模型】ChatGLM-6B模型结构代码解析(单机版)
【自然语言处理】【大模型】BLOOM模型结构源码解析(单机版)
一、简介
Scaling laws描述了模型尺寸与其能力的关系。不同于先前通过loss或者基准来评估模型能力,本文评估模型存储的知识数量。这里主要是关注以元组方式表示的知识,例如(USA, capital, Washington D.C)。通过多个受控数据集,发现每个参数仅能存储2 bit的知识,即使参数量化为8bit也有相同结论。因此,7B模型能够存储14B bit的指数,超过了英文Wikipedia和教科书的总和。
二、预备知识
知识片段(knowledge picec):三个字符串组成的元组 (name,attribute,value)=(n,a,v) \text{(name,attribute,value)=(n,a,v)} (name,attribute,value)=(n,a,v)。例如, n="张三" \text{n="张三"} n="张三", a="生日" \text{a="生日"} a="生日"且 v=1992年10月1日 \text{v=1992年10月1日} v=1992年10月1日。
1. 知识的理论设定
一组知识的复杂度不仅由知识片段的数量决定,也取决于 v v v的长度、词表多样性和一些其他的隐藏。例如,若 a a a表示身份证号,则其包含的知识量比 a a a为性别要多,因为身份证号多样性更高。此外,若 a a a为生日,则 v v v由3个块(chunks)组成,例如(1996,10,1)。
基于这些观察,列出一些可能影响知识复杂度的超参数:
- N:名称(name) n n n的数量,名称集合表示为 N \mathcal{N} N;
- K:属性(attribute) a a a的数量,令 A \mathcal{A} A表示属性集合,则 ∣ A ∣ = K |\mathcal{A}|=K ∣A∣=K;
- T:token的数量,令 v v v中的每个字符都属于集合 T \mathcal{T} T,则有 ∣ T ∣ = T |\mathcal{T}|=T ∣T∣=T。因此,T也可以认为是tokenizer中词表大小;
- C和L:块(chunk)的数量以及每个块的长度。 v ∈ ( T L ) C v\in(\mathcal{T}^L)^C v∈(TL)C可以表示为 v = ( v 1 , v 2 , … , v C ) v=(v_1,v_2,\dots,v_C) v=(v1,v2,…,vC),其中 v i ∈ T L v_i\in\mathcal{T}^L vi∈TL;
- D:块(chunk)的多样性。对于每个知识片段 ( n , a , v ) (n,a,v) (n,a,v),若块 v i v_i vi属于 D a ⊂ T L \mathcal{D}_a\subset\mathcal{T}^L Da⊂TL,则块的多样性表示为 D = def ∣ D a ∣ ≪ T L D\overset{\text{def}}{=}|\mathcal{D}_a|\ll T^L D=def∣Da∣≪TL;
为了简化表示,令属性 a ∈ A a\in\mathcal{A} a∈A内的所有块(chunk)共享多样性集合 D a \mathcal{D}_a Da且所有块均有相同长度。这里先引入 bioD(N,K,C,D,L,T) \text{bioD(N,K,C,D,L,T)} bioD(N,K,C,D,L,T)数据集,定义如下:
定义2.2
假设属性集合 A \mathcal{A} A中有K个属性,例如 A = { "ID1" … "ID K" } \mathcal{A}=\{\text{"ID1"}\dots\text{"ID K"}\} A={"ID1"…"ID K"};候选名称集合 N 0 ( N 0 = def ∣ N 0 ∣ ≫ N ) \mathcal{N}_0(N_0\overset{\text{def}}{=}|\mathcal{N}_0|\gg N) N0(N0=def∣N0∣≫N)。
- 从 N 0 \mathcal{N}_0 N0中均匀采样N个名称,形成集合 N \mathcal{N} N;
- 对于每个属性 a ∈ A a\in\mathcal{A} a∈A,均匀随机生成D个不同的字符串 w 1 , a , … , w D , a ∈ T L w_{1,a},\dots,w_{D,a}\in\mathcal{T}^L w1,a,…,wD,a∈TL,从而形成多样性集合 D a \mathcal{D}_a Da;
- 对于每个名称 n ∈ N n\in\mathcal{N} n∈N和属性 a ∈ A a\in\mathcal{A} a∈A,通过均匀采样 v i ∈ D a v_i\in\mathcal{D}_a vi∈Da来生成取值 v ⋆ ( n , a ) = ( v 1 , v 2 , … , v C ) v^{\star}(n,a)=(v_1,v_2,\dots,v_C) v⋆(n,a)=(v1,v2,…,vC);
令 Z = def { ( n , a , v ⋆ ( n , a ) ) } n ∈ N , a ∈ A \mathcal{Z}\overset{\text{def}}{=}\{(n,a,v^{\star}(n,a))\}_{n\in\mathcal{N},a\in\mathcal{A}} Z=def{(n,a,v⋆(n,a))}n∈N,a∈A表示知识集合。
命题2.3 bit复杂度上界
给定 N 0 \mathcal{N}_0 N0、 A \mathcal{A} A和 T \mathcal{T} T,描述由定义2.2生成的知识集合,至多需要的bit数为
log 2 ( ∣ N 0 ∣ N ) + N K C log 2 D + K log 2 ( T L D ) ≈ N log 2 ∣ N 0 ∣ N + N K C log 2 D + K D log 2 T L D \log_2\Big(\begin{matrix}|\mathcal{N}_0| \\ N \end{matrix}\Big)+ NKC\log_2 D+K\log_2\Big(\begin{matrix}T^L \\ D \end{matrix}\Big) \approx N\log_2\frac{|\mathcal{N}_0|}{N}+NKC\log_2 D+KD\log_2\frac{T^L}{D} \\ log2(∣N0∣N)+NKClog2D+Klog2(TLD)≈Nlog2N∣N0∣+NKClog2D+KDlog2DTL
从 N 0 \mathcal{N}_0 N0中挑选N个名称形成 N \mathcal{N} N的可能性包含 ( ∣ N 0 ∣ N ) \Big(\begin{matrix}|\mathcal{N}_0| \\ N \end{matrix}\Big) (∣N0∣N)种,需要的bit数为 log 2 ( ∣ N 0 ∣ N ) \log_2\Big(\begin{matrix}|\mathcal{N}_0| \\ N \end{matrix}\Big) log2(∣N0∣N);N个名称,K个属性,C个块,每个块有D种可能性,需要的bit数为 N K C log 2 D NKC\log_2 D NKClog2D;
K个属性,每个属性从 T L T^L TL的可能空间中挑选D个作为多样性集合,需要的bit数为 K log 2 ( T L D ) K\log_2\Big(\begin{matrix}T^L \\ D \end{matrix}\Big) Klog2(TLD);
2. 知识的经验设定
这里使用定义2.2生成的bioD数据集和其他一些人物简介数据集来评估LM的scaling law。
Allen-Zhu和Li构造了一个合成人物简介数据集,包含N个人物且每个人物具有6个属性:生日、出生城市、大学、专业、雇主和工作城市。为了将bioS数据集中的元组翻译为自然语言,每个人通过6个随机选择的句子模板进行描述。
本文中,探索了该数据集的三种变体:
- bioS(N) \text{bioS(N)} bioS(N)表示包含N个人物的在线数据集,每个人物都是通过动态选择和排序6个句子模板来随机生成的;
- bioS simple ( N ) \text{bioS}^{\text{simple}}(N) bioSsimple(N)表示类似的数据集,但是每个人物都是通过对句子模板进行固定的随机选择和排序;
- bioR(N) \text{bioR(N)} bioR(N)表示相同的数据集,但是每个人物都通过LLaMA2重写40次,从而增加真实性和多样性;
这些数据集对应"bioS multi+permute"、“bioS single+permute"和"bioR multi”。先前的研究将N限制在100K,本文则将bioS中的N限制在20M,而bioR的N限制在1M。通过这样的方式构造的数据集达到22GB。
若每个知识片段在训练时见过1000次,则称为1000次曝光。对于bioS(N),1000次曝光不太可能包含相同的人物数据,因为每个属性有50个句子模板,那么每个人就有 5 0 6 × 6 ! 50^6\times 6! 506×6!个可能的人物传记。对于 bioS simple ( N ) \text{bioS}^{\text{simple}}(N) bioSsimple(N),1000次曝光意味着1000次数据通过。对于bioR(N),1000/100曝光意味着训练数据仅有25/2.5通过。
对于bioD数据集,定义
N
0
\mathcal{N}_0
N0与bioS相同,
∣
N
0
∣
=
400
×
400
×
1000
|\mathcal{N}_0|=400\times 400\times 1000
∣N0∣=400×400×1000。通过使用随机句子顺序和一致的句子模板,将单个人物的属性封装在同一个段落中。例如
Anya Briar Forger’s ID 7 is
v
7
,
1
,
…
,
v
7
,
C
.
Her ID 2 is
v
2
,
1
,
…
,
v
2
,
C
.
[
…
]
Her ID 5 is
v
5
,
1
,
…
,
v
5
,
C
\text{Anya Briar Forger's ID 7 is }v_{7,1},\dots,v_{7,C}.\text{ Her ID 2 is }v_{2,1},\dots,v_{2,C}.[\dots]\text{ Her ID 5 is }v_{5,1},\dots,v_{5,C}
Anya Briar Forger’s ID 7 is v7,1,…,v7,C. Her ID 2 is v2,1,…,v2,C.[…] Her ID 5 is v5,1,…,v5,C
本文主要利用bioS。为了能够表明更广泛的适用性并且更好的连接理论边界,也会报告
bioS
simple
\text{bioS}^{\text{simple}}
bioSsimple、
bioR
\text{bioR}
bioR和
bioD
\text{bioD}
bioD。
3. 模型和训练
将GPT2的位置编码换为RoPE并且禁用dropout。 GPT2-l-h \text{GPT2-l-h} GPT2-l-h表示 l l l层、 h h h头且隐藏层维度为 64 h 64h 64h的模型,例如GPT2-small对应于GPT2-12-12。使用默认的GPT2Tokenizer,将人物的姓名和属性转换为变长token序列。后续在测试模型结构的scaling law时,也会使用LLaMA/Mistral架构。
使用特定的数据集从头开始训练语言模型。人物的知识片段被随机拼接,使用进行分隔,然后随机划分为512 tokens的窗口。使用标准的自回归损失函数进行训练。
三、Bit复杂度下界
当评估模型中存储的知识,不能简单的依赖于平均的、逐个单词的交叉熵损失值。例如,短语“received mentorship and guidance from faculty members”中不包含有用的知识。相反,应该关注知识tokens的损失值之和。
考虑具有权重
W
∈
W
W\in\mathcal{W}
W∈W的模型
F
F
F。假设
F
F
F在一个bioD(N,K,C,D,L,T)数据集
Z
\mathcal{Z}
Z上训练,该过程表示为
W
=
W
(
Z
)
W=W(\mathcal{Z})
W=W(Z)。在评估阶段,通过两个函数来表示
F
F
F:
F
⊤
(
W
,
R
)
F^\top(W,R)
F⊤(W,R)用来生成名称、
F
⊥
(
W
,
n
,
a
,
R
)
F^{\perp}(W,n,a,R)
F⊥(W,n,a,R)表示在给定(n,a)的情况下生成具体的取值,
R
R
R表示生成中使用的随机性。令
F
1
⊥
(
W
(
Z
)
,
n
,
a
,
R
)
F^{\perp}_1(W(\mathcal{Z}),n,a,R)
F1⊥(W(Z),n,a,R)表示
F
⊥
(
W
(
Z
)
,
n
,
a
,
R
)
F^{\perp}(W(\mathcal{Z}),n,a,R)
F⊥(W(Z),n,a,R)生成的第一个分块(chunk)。通过计算下面的三个交叉熵损失来评估
F
F
F:
loss
n
a
m
e
(
Z
)
=
def
E
n
∈
N
−
log
Pr
R
[
F
⊤
(
W
(
Z
)
,
R
)
=
n
]
loss
v
a
l
u
e
1
(
Z
)
=
def
E
n
∈
N
,
a
∈
A
−
log
Pr
R
[
F
1
⊤
(
W
(
Z
)
,
n
,
a
,
R
)
=
v
1
⋆
(
n
,
a
)
]
loss
v
a
l
u
e
(
Z
)
=
def
E
n
∈
N
,
a
∈
A
−
log
Pr
R
[
F
⊥
(
W
(
Z
)
,
n
,
a
,
R
)
=
v
⋆
(
n
,
a
)
]
\begin{align} \textbf{loss}_{name}(\mathcal{Z})&\overset{\text{def}}{=}\mathbb{E}_{n\in\mathcal{N}}-\log\textbf{Pr}_{R}[F^\top(W(\mathcal{Z}),R)=n] \\ \textbf{loss}_{value1}(\mathcal{Z})&\overset{\text{def}}{=}\mathbb{E}_{n\in\mathcal{N},a\in\mathcal{A}}-\log\textbf{Pr}_R[F_1^\top(W(\mathcal{Z}),n,a,R)=v_{1}^{\star}(n,a)] \\ \textbf{loss}_{value}(\mathcal{Z})&\overset{\text{def}}{=}\mathbb{E}_{n\in\mathcal{N},a\in\mathcal{A}}-\log\textbf{Pr}_R[F^{\perp}(W(\mathcal{Z}),n,a,R)=v^{\star}(n,a)] \\ \end{align} \\
lossname(Z)lossvalue1(Z)lossvalue(Z)=defEn∈N−logPrR[F⊤(W(Z),R)=n]=defEn∈N,a∈A−logPrR[F1⊤(W(Z),n,a,R)=v1⋆(n,a)]=defEn∈N,a∈A−logPrR[F⊥(W(Z),n,a,R)=v⋆(n,a)]
对于一个语言模型,这些量可以通过自回归交叉熵损失进行计算。例如,在句子"
Anya Briar Forger’s ID 7 is
v
7
,
1
,
…
,
v
7
,
C
\text{Anya Briar Forger's ID 7 is }v_{7,1},\dots,v_{7,C}
Anya Briar Forger’s ID 7 is v7,1,…,v7,C"中评估模型,通过在token "Anya Briar Forger"上的loss进行求和能够精准计算出当
n
=
"Anya Briar Forger"
n=\text{"Anya Briar Forger"}
n="Anya Briar Forger"时的
−
log
Pr
R
[
F
⊤
(
W
(
Z
)
,
R
)
=
n
]
-\log\textbf{Pr}_{R}[F^\top(W(\mathcal{Z}),R)=n]
−logPrR[F⊤(W(Z),R)=n]。将token
v
7
,
1
v_{7,1}
v7,1的损失值进行求和则计算出n和a="ID 7"时的
−
log
Pr
R
[
F
1
⊤
(
W
(
Z
)
,
n
,
a
,
R
)
=
v
7
,
1
]
-\log\textbf{Pr}_R[F_1^\top(W(\mathcal{Z}),n,a,R)=v_{7,1}]
−logPrR[F1⊤(W(Z),n,a,R)=v7,1]。在整个序列
v
7
,
1
,
…
,
v
7
,
C
v_{7,1},\dots,v_{7,C}
v7,1,…,v7,C上的损失值求和则有
−
log
Pr
R
[
F
⊥
(
W
(
Z
)
,
n
,
a
,
R
)
=
v
7
,
1
,
…
,
v
7
,
C
]
-\log\textbf{Pr}_R[F^{\perp}(W(\mathcal{Z}),n,a,R)=v_{7,1},\dots,v_{7,C}]
−logPrR[F⊥(W(Z),n,a,R)=v7,1,…,v7,C]。
定理3.2 (bit复杂度的下界)
假设 N ≥ Ω ( D log N ) N\geq\Omega(D\log N) N≥Ω(DlogN),则有
log 2 ∣ W ∣ ≥ E Z [ N log 2 N 0 − N e loss n a m e ( Z ) + N K log 2 D C e loss v a l u e ( Z ) + K D log 2 T L − D D e ( 1 + o ( 1 ) ) loss v a l u e 1 ( Z ) − o ( K D ) ] = N log 2 N 0 − N e E Z loss n a m e ( Z ) + N K log 2 D C e E Z loss v a l u e ( Z ) + K D log 2 T L − D D e ( 1 + o ( 1 ) ) E Z loss v a l u e 1 ( Z ) − o ( K D ) \begin{align} \log_2 |\mathcal{W}|&\geq\mathbb{E}_{\mathcal{Z}}\Big[N\log_2\frac{N_0-N}{e^{\textbf{loss}_{name}(\mathcal{Z})}}+NK\log_2\frac{D^C}{e^{\textbf{loss}_{value}(\mathcal{Z})}}+KD\log_2\frac{T^L-D}{De^{(1+o(1))\textbf{loss}_{value1}(\mathcal{Z})}}-o(KD)\Big] \\ &=N\log_2\frac{N_0-N}{e^{\mathbb{E}_{\mathcal{Z}}\textbf{loss}_{name}(\mathcal{Z})}}+NK\log_2\frac{D^C}{e^{\mathbb{E}_{\mathcal{Z}}\textbf{loss}_{value}(\mathcal{Z})}}+KD\log_2\frac{T^L-D}{De^{(1+o(1))\mathbb{E}_{\mathcal{Z}}\textbf{loss}_{value1}(\mathcal{Z})}}-o(KD) \\ \end{align} \\ log2∣W∣≥EZ[Nlog2elossname(Z)N0−N+NKlog2elossvalue(Z)DC+KDlog2De(1+o(1))lossvalue1(Z)TL−D−o(KD)]=Nlog2eEZlossname(Z)N0−N+NKlog2eEZlossvalue(Z)DC+KDlog2De(1+o(1))EZlossvalue1(Z)TL−D−o(KD)
本文的目标是就研究模型参数数量与这个下界的关系。
推论3.3 (理想无误差的情况)
理想情况下,对于 Z \mathcal{Z} Z中的每个数据, F F F都能以1/N的概率从 N \mathcal{N} N中生成名称,那么有 loss n a m e ( Z ) = log N \textbf{loss}_{name}(\mathcal{Z})=\log N lossname(Z)=logN;给定(n,a)样本对, F F F能够100%准确生成v,那么 loss v a l u e ( Z ) = loss v a l u e 1 ( Z ) = 0 \textbf{loss}_{value}(\mathcal{Z})=\textbf{loss}_{value1}(\mathcal{Z})=0 lossvalue(Z)=lossvalue1(Z)=0。在这种情况下,
log 2 ∣ W ∣ ≥ N log 2 N 0 − N N + N K C log 2 D + K D log 2 T L − D D − o ( K D ) \log_2 |\mathcal{W}|\geq N\log_2\frac{N_0-N}{N}+NKC\log_2 D+KD\log_2\frac{T^L-D}{D}-o(KD) \\ log2∣W∣≥Nlog2NN0−N+NKClog2D+KDlog2DTL−D−o(KD)
- 三部分进行求和是获得下界的必要条件,忽略其中任何一个都会导致次优下界;
- 研究固定数据集 Z \mathcal{Z} Z的下界是不可能的,即使没有任何可训练参数,模型也能硬编码 Z \mathcal{Z} Z至其架构中。因此,需要考虑数据集分布上的下界。
若名称是固定的 ( N = N 0 ) (\mathcal{N}=\mathcal{N}_0) (N=N0)并且具有N个知识片段,每个知识片段都是从固定集合 [ T ] [T] [T]中挑选出来的。那么,当满足 log 2 ∣ W ∣ ≥ N log 2 T \log_2|\mathcal{W}|\geq N\log_2 T log2∣W∣≥Nlog2T时,任何模型 F ( W ) F(\mathcal{W}) F(W)都能够完美学习到这些知识。为了能够与定理3.2联系起来,需要解决三个挑战。(1) 模型F仅能以一定程度的准确率来学习知识;(2) N ≠ N 0 \mathcal{N}\neq\mathcal{N}_0 N=N0,因此名称需要进行学习,即使是完美的模型在生成名称时都无法实现0交叉熵损失。(3) 知识片段之间存在依赖关系。
四、容量比
基于定理3.2,忽略低阶项,定义经验容量比为
定义4.1
给定一个具有 P P P个参数的模型 F F F,其在bioD(N,K,C,D,L,T)数据集 Z \mathcal{Z} Z上训练。假设其能够给出 p 1 = loss n a m e ( Z ) p_1=\textbf{loss}_{name}(\mathcal{Z}) p1=lossname(Z)、 p 2 = loss v a l u e ( Z ) p_2=\textbf{loss}_{value}(\mathcal{Z}) p2=lossvalue(Z)、 p 3 = loss v a l u e 1 ( Z ) p_3=\textbf{loss}_{value1}(\mathcal{Z}) p3=lossvalue1(Z),定义容量比(capacity)和最大容量比(max capacity ratio)为
R ( F ) = def N log 2 N 0 e p 1 + N K log 2 D C e p 2 + K D log 2 T L D e p 3 P R(F)\overset{\text{def}}{=}\frac{N\log_2\frac{N_0}{e^{p_1}}+NK\log_2\frac{D^C}{e^{p_2}}+KD\log_2\frac{T^L}{De^{p_3}}}{P} \\ R(F)=defPNlog2ep1N0+NKlog2ep2DC+KDlog2Dep3TLR max ( F ) = def N log 2 N 0 N + N K C log 2 D + K D log 2 T L D P R^{\max}(F)\overset{\text{def}}{=}\frac{N\log_2\frac{N_0}{N}+NKC\log_2 D+KD\log_2\frac{T^L}{D}}{P} \\ Rmax(F)=defPNlog2NN0+NKClog2D+KDlog2DTL
必然满足 R ( F ) ≤ R max ( F ) R(F)\leq R^{\max}(F) R(F)≤Rmax(F),仅当模型是完美的情况下等号才成立。对于固定的数据集,进一步增大模型尺寸也不会增加额外的知识。因此,随着模型尺寸P的增加, R max ( F ) R^{\max}(F) Rmax(F)会逐步趋近于0。对于bioS(N)数据,可以通过忽略多样性项来略微降低容量比。
定义4.3
给定一个具有 P P P个参数的模型 F F F,其在bioS(N)数据集 Z \mathcal{Z} Z上训练。假设其能够给出 p 1 = loss n a m e ( Z ) p_1=\textbf{loss}_{name}(\mathcal{Z}) p1=lossname(Z)、 p 2 = loss v a l u e ( Z ) p_2=\textbf{loss}_{value}(\mathcal{Z}) p2=lossvalue(Z),其容量比为
R ( F ) = def N log 2 N 0 e p 1 + N log 2 S 0 e p 2 P R max ( F ) = def N log 2 n 0 N + N log 2 S 0 P \begin{align} R(F)&\overset{\text{def}}{=}\frac{N\log_2\frac{N_0}{e^{p_1}}+N\log_2\frac{S_0}{e^{p_2}}}{P} \\ R^{\max}(F)&\overset{\text{def}}{=}\frac{N\log_2\frac{n_0}{N}+N\log_2 S_0}{P} \\ \end{align} \\ R(F)Rmax(F)=defPNlog2ep1N0+Nlog2ep2S0=defPNlog2Nn0+Nlog2S0
忽略名称,每个人包含 log 2 ( S 0 ) ≈ 47.6 \log_2(S_0)\approx47.6 log2(S0)≈47.6bit的知识。
五、基础Scaling Laws

使用bioS(N)数据集训练了一系列GPT2模型。训练的方式能够确保每个知识片段都被训练1000次,该过程称为"1000次曝光"。下面是一些初步的结论:
通过训练保证bioS(N)有1000次曝光,N的范围从10K到10M,GPT2模型的尺寸从1M到0.5B。上图1(a)显示结果为:
- 峰值容量比R(F)始终大于2;
- 当 R max ( F ) ≤ 1.8 R^{\max}(F)\leq 1.8 Rmax(F)≤1.8时,模型接近完美的知识准确率(数据集包含B bit的知识,那么模型参数量选择 P ≥ B / 1.8 P\geq B/1.8 P≥B/1.8就足够了);
- 对于所有的模型,均有 R ( F ) ≤ 2.3 R(F)\leq 2.3 R(F)≤2.3;
"2bit/param"并不是逐字逐句的记忆,这样的知识可以灵活抽取并且能够进一步在下游任务中操作。这是因为bioS(N)数据是知识增强的,人物简介有充足的文本多样性。
1. 数据格式:多样性和重写
在 bioS simple \text{bioS}^{\text{simple}} bioSsimple和 bioR \text{bioR} bioR上执行相同的分析, bioS \text{bioS} bioS是 bioS simple \text{bioS}^{\text{simple}} bioSsimple的文本多样性版本, bioR \text{bioR} bioR是由LLaMA2生成的接近真实的人物简介。
在相同1000次曝光,GPT2在 bioS simple \text{bioS}^{\text{simple}} bioSsimple和 bioR \text{bioR} bioR上的峰值容量比都接近2。因此,多样性数据并不会损坏模型容量,甚至可能会改善容量。
比较 bioS \text{bioS} bioS和 bioS simple \text{bioS}^{\text{simple}} bioSsimple,同一个数据重写1000次要比相同数据传递给模型1000个更有优势。若数据失去多样性,模型将会浪费容量记忆句子结构,从而降低容量。
在真实场景中,使用LLaMA2这种工具对预训练数据进行重写,就像 bioR \text{bioR} bioR那样。重写40次则产生40个不同的片段,那么需要40倍大的模型吗?不需要,比较 bioS \text{bioS} bioS和 bioR \text{bioR} bioR表明训练相同时间,模型容量比基本相同。
Allen-Zhu and Li表明,重写预训练数据对于知识抽取而不是逐字记忆至关重要。然而,他们并没探索模型容量的影响。本文解决了这个问题,表明重写预训练数据并不会损害模型的知识容量,甚至有可能增强。
2. 参数化Scaling Laws
进一步研究了 bioD(N,K,C,D,L,T) \text{bioD(N,K,C,D,L,T)} bioD(N,K,C,D,L,T)数据上的scaling laws。不同于人物简介数据中的变量仅有N, bioD \text{bioD} bioD数据集允许更灵活的操作超参数K,C,D,L,T。这允许进一步测试这些参数对模型容量的影响。
跨越各种取值,K和G的范围从1到50,D的范围从10到10000,L从1到50,T从20到40000,观察到的结果:GPT2模型的峰值容量比始终有 R ( F ) ≥ 2 R(F)\geq 2 R(F)≥2。
六、训练时间与Scaling Law
当模型没有被充分训练会怎样?例如,每个知识在预训练阶段仅出现100次。令 bioS ( N ) \text{bioS}(N) bioS(N)曝光100次来计算容量比,可以发现:
当训练过程中 bioS(N) \text{bioS(N)} bioS(N)数据仅曝光100次,N从10K到10M,GPT2模型尺寸从1M到0.5B,峰值容量比始终满足 R ( F ) ≥ 1 R(F)\geq 1 R(F)≥1。
因此,虽然1000次曝光可能是达到最大容量的必然条件,但仅曝光100次也不会有很多损失。
七、模型结构与Scaling Law
目前有很多transformer架构被使用,其中LLaMA和Mistral是其中比较常见的。就知识容量来说,在充足训练下,GPT2结构并没有比其他结构更差。
在1000次曝光设定下,架构并不重要:
- LLaMA结构在小模型上略微不如GPT2,但是这个差距随着参数增大而缓解;
- Mistral结构也能观察到类似现象;
- 降低GPT2中MLP尺寸的1/4,甚至消除所有的MLP层都不影响容量比。这表明,不同于传统认知,注意力层也能够存储知识。
这表明 2bit/param容量比在大多数典型语言模型结构中是一个相对普遍的规律。
在100次曝光设置中:
- 即使是更大的模型,LLaMA结构的容量比也比GPT2差1.3倍。Mistral也有类似的结果。
- 降低GPT2中MLP尺寸的1/4,对容量比影响微不足道。
- 移除MLP会降低容量比1.5倍以上。
为了能够明确在100次曝光设定中,LLaMA结构为什么差于GPT2,逐步修改LLaMA结构至GPT2来确定关键的结构变化。
- 对于大模型,将LLaMA结构中的gated MLP替换为标准MLP,显著提高了LLaMA的容量比。
- 对于小型LLaMA模型,将其转换为GPT2Tokenizer是匹配GPT2效果的必要条件,尽管这不是主要问题。
- 其他一些修改,例如将silu修改为gelu或者为LayerNorm添加可训练偏差,都不会显著影响容量比。
八、量化与Scaling Law
模型训练和测试都使用16bit浮点数。在训练后使用int8/int4量化会有什么影响呢?
对16bit训练的语言模型进行量化:
- int8对容量来说可以忽略不计;
- int4使得容量减少2倍以上;
对于峰值容量为2 bits/param,量化至int8不会对容量有影响。在高质量数据上进行1000次曝光能够达到的最优容量比为2 bits/param,那么可以得出结论:即使进一步训练也无法改善容量,但是量化可以。由于int8模型的容量比具有绝对上界 R ( F ) ≤ 8 R(F)\leq 8 R(F)≤8,因此
像GPT2这样的语言模型,能够超过绝对理论限制的1/4来存储知识。
LLM能够压缩知识至其参数空间中,从而实现2bit/param。那么这些知识是如何存储的呢?本文认为知识以不太冗余的方式存储在模型中。不太可能是MLP层单独存储知识,因为注意力层也能够存储知识。此外,当模型接近容量极限的时候,移除L层模型中的最后一层,余下的知识显著小于 1 − 1 L 1-\frac{1}{L} 1−L1。这也就表明知识不是单独存储在独立的层,而是以复杂的方式进行存储。
九、MoE与Scaling Law
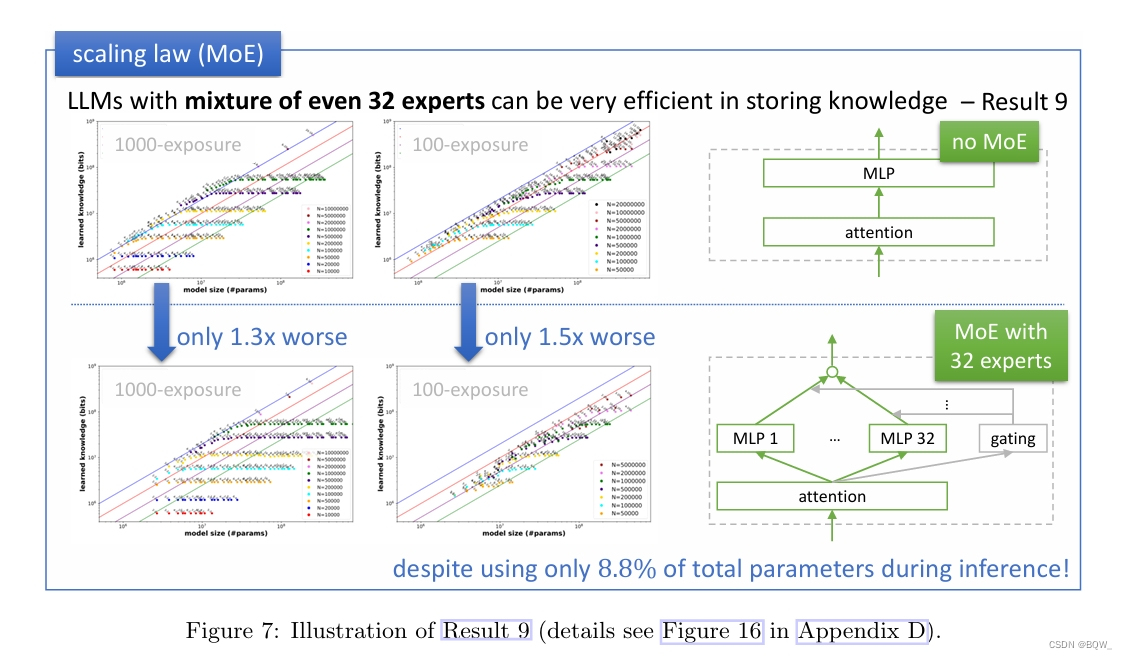
MoE模型在容量比方面会有所不同吗?对于一个MoE模型,令P表示模型中的总参数量,包括所有专家。由于其稀疏性,有效参数数量显著小于P。
考虑一个GPT2模型,但是MLP层替换为32个专家,每个专家遵循 d → d → d d\rightarrow d\rightarrow d d→d→d的配置。这种设置总共会使用 64 d 2 64d^2 64d2的总参数,但是在推理时每个token仅使用 2 d 2 2d^2 2d2参数。考虑了具有 4 d 2 4d^2 4d2参数的注意力层,具有32个专家的MoE模型总参数量和有效参数量比值接近于 4 d 2 + 64 d 2 4 d 2 + 2 d 2 ≈ 11.3 \frac{4d^2+64d^2}{4d^2+2d^2}\approx 11.3 4d2+2d24d2+64d2≈11.3。
那么在推理时,模型使用的参数少11.3倍,这对模型容量比的影响是11.3倍还是没有影响?
MoE在存储知识方面完全有效,尽管有稀疏性的约束,但能够利用所有的参数。
具体来说,考虑具有32个专家的GPT2-MoE模型。若计算其相对于总参数量的容量比,则有
- 在1000次曝光设定中,峰值容量比降低1.3倍;
- 在100次曝光设定中,峰值容量比降低1.5倍;
即使是在topk=1且cap_factor=2最稀疏设定下,上述结果仍然成立。通常MoE模型要比相同参数量的稠密模型要差,这里表明这种退化并不是来自于模型的知识存储能力。
十、垃圾数据与Scaling Law
并不是所有的数据对于获取知识都是有用的。低质量数据如何影响有用知识容量的scaling laws?为了研究这个问题,创建了一个混合数据集:
- 1/8的tokens来自于 bioS(N) \text{bioS(N)} bioS(N),即有用数据;
- 7/8的tokens来自于 bioS ( N ′ ) \text{bioS}(N') bioS(N′), N ′ = 100 M N'=100M N′=100M,即垃圾数据;
在该混合数据上训练模型,每100次曝光中确保包含有用数据,使得总训练时间比没有垃圾数据100次曝光多8倍。垃圾数据会降低容量比吗?
当训练数据7/8的token来自垃圾数据,transformer学习有用数据的速度显著降低:
- 若在100次曝光设定中,相比于没有垃圾数据,容量比下降约20倍;
- 即使在300/600/1000次曝光中,容量比仍然会下降3/1.5/1.3倍。
这强调了预训练数据质量的重要性:即使垃圾数据是完全随机的,其也会对模型的知识容量产生显著负面影响。
若7/8的训练token来自高度重复的数据,并不影响有用知识的学习速度。
若预训练数据质量差且难以提高,则有策略
当7/8的训练token来自于垃圾数据,在有用数据前添加特殊token能够显著改善容量比。
- 100次曝光设定中,容量比仅下降2倍;
- 300次曝光设定中,容量比没有下降;
进一步,为每个预训练数据添加域名。这将显著增加模型的知识能力,因为语言模型能够自动检测哪些领域包含高质量知识并优先进行学习。
:即使垃圾数据是完全随机的,其也会对模型的知识容量产生显著负面影响。
若7/8的训练token来自高度重复的数据,并不影响有用知识的学习速度。
若预训练数据质量差且难以提高,则有策略
当7/8的训练token来自于垃圾数据,在有用数据前添加特殊token能够显著改善容量比。
- 100次曝光设定中,容量比仅下降2倍;
- 300次曝光设定中,容量比没有下降;
进一步,为每个预训练数据添加域名。这将显著增加模型的知识能力,因为语言模型能够自动检测哪些领域包含高质量知识并优先进行学习。