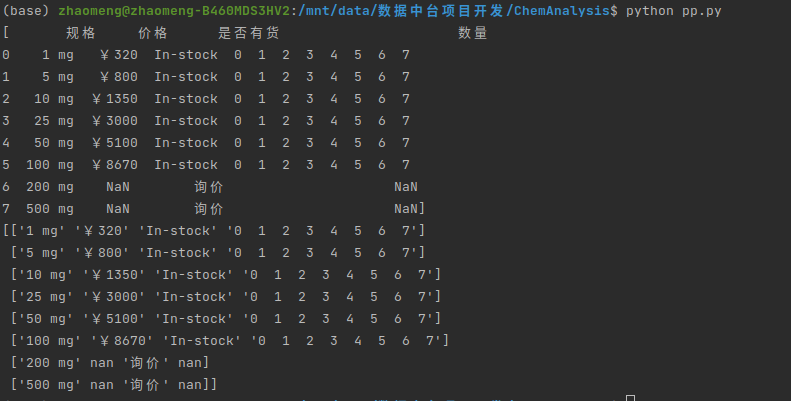
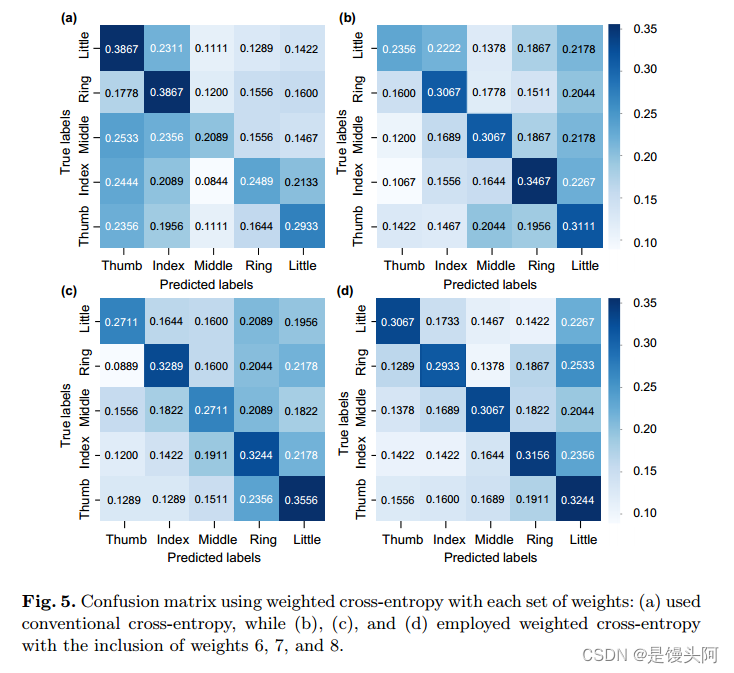
day01
1、报错获取不到浏览器二进制文件:需要指定浏览器路径及驱动路径。
第一次使用谷歌浏览器驱动,找不到二进制文件
报错:
selenium.common.exceptions.WebDriverException: Message: unknown error: cannot find Chrome binary
Stacktrace:
原因:没有把谷歌浏览器安装在默认的地方
这个错误信息表明在尝试初始化webdriver.Chrome()时,Selenium无法找到Chrome浏览器的二进制文件。错误信息为:“unknown error: cannot find Chrome binary”。这通常发生在以下几种情况:
Chrome未安装:确保Google Chrome浏览器已经安装在你的系统上,并且安装在默认路径。对于Windows系统,Chrome通常安装在C:\Program Files (x86)\Google\Chrome\Application\chrome.exe或者C:\Program Files\Google\Chrome\Application\chrome.exe。
安装路径非标准:如果Chrome安装在非标准路径,Selenium可能无法自动找到它。在这种情况下,你需要在Selenium的ChromeOptions中手动指定Chrome的位置。
环境变量问题:确保系统的环境变量中包含了Chrome的路径,这样Selenium就能找到Chrome的二进制文件。
针对这个问题,如果Chrome已经安装但Selenium仍然报错,你可以通过以下方式手动指定Chrome的路径:指定路径的代码:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
chrome_driver_path = "D:/path/to/chromedriver.exe" # Chrome Driver的路径
chrome_binary_path = "C:/Program Files/Google/Chrome/Application/chrome.exe" # Chrome浏览器的路径,根据实际安装位置调整
options = Options()
options.binary_location = chrome_binary_path
service = Service(executable_path=chrome_driver_path)
driver = webdriver.Chrome(service=service, options=options)
请确保将chrome_driver_path和chrome_binary_path替换为你系统上实际的路径。这样,Selenium就能正确地找到并使用Chrome浏览器了。
2、selenium的原理
地址:了解组件 | Selenium
3、更新pip的指令
python -m pip install --upgrade pip -i https://mirrors.aliyun.com/pypi/simple/day02
1、会手写Xpath--只用相对路径
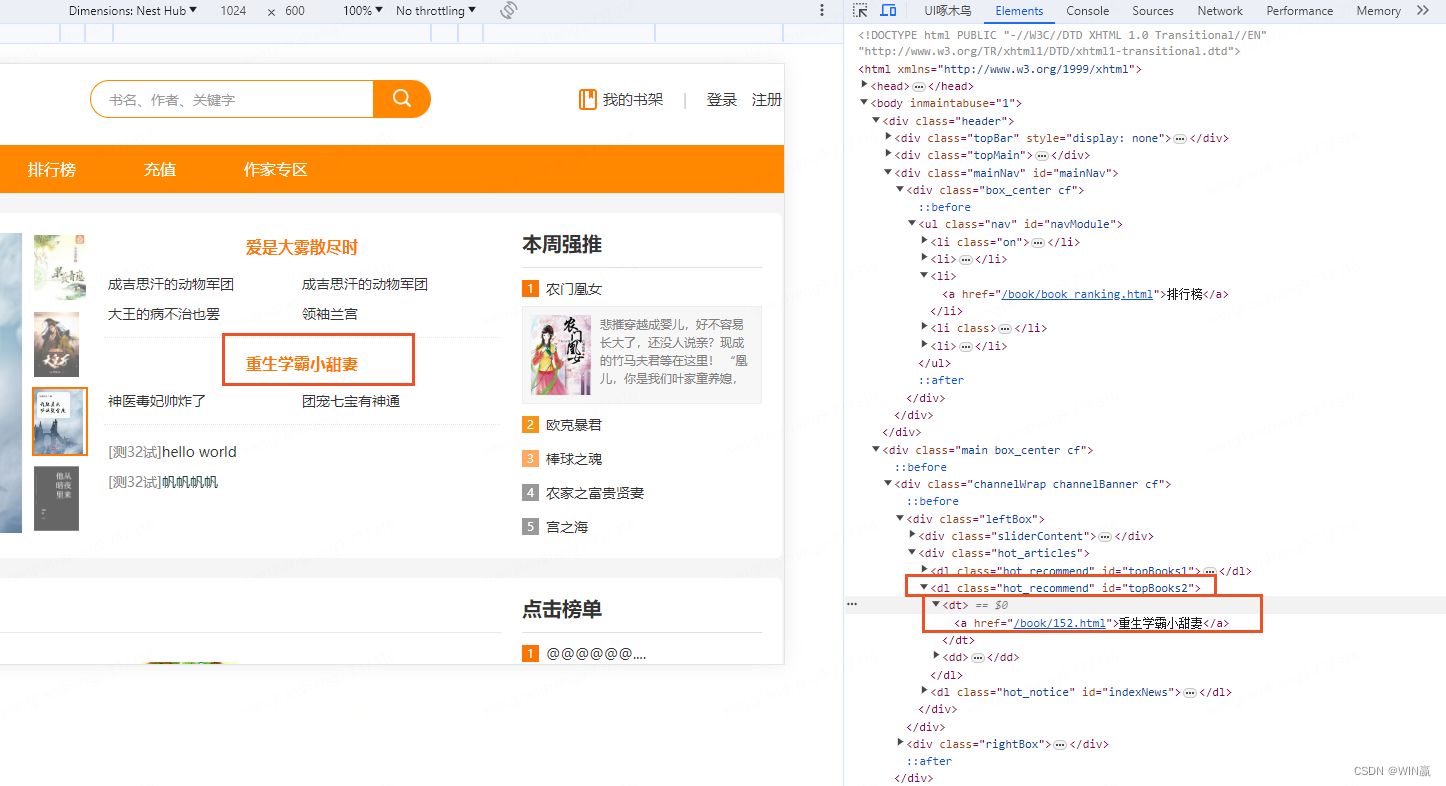
1)通过唯一标识的方式
不管是什么元素类型,使用通配符*
el = driver.find_element(By.XPATH,"//*[@ID='topBooks2']") 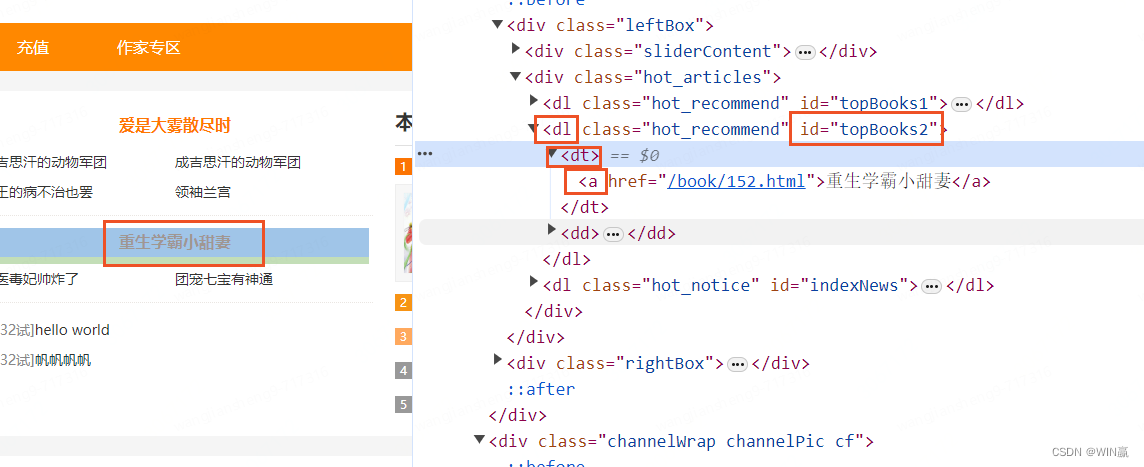
在确定元素类型的情况下,使用元素类型 dl 去匹配元素
el = driver.find_element(By.XPATH,"//dl[@ID='topBooks2']")2)以。。开头--模糊查询
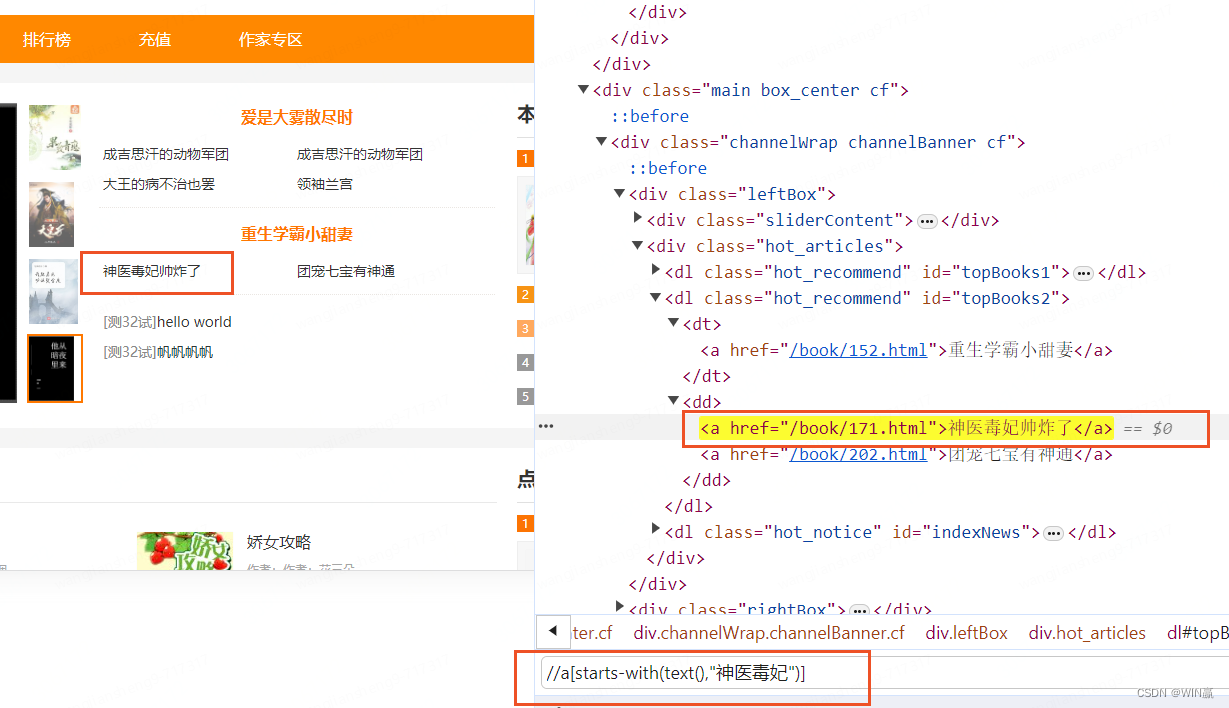
el = driver.find_element(By.XPATH,'//a[starts-with(text(),"神医毒妃")]')3)包含
el = driver.find_element(By.XPATH,'//a[contains(text(),"神医毒妃")]')4)苏雪梅
要编写XPath来定位包含“苏雪梅”的元素
1. **直接定位包含文本的`<a>`标签**:
//td[@class='name']/a[contains(text(),'苏雪梅')]
这个XPath查找类名为`name`的`<td>`标签下的`<a>`标签,其中包含文本“苏雪梅”。
2. **使用文本定位整个`<td>`标签**:
//td[contains(.,'苏雪梅')]
这个XPath查找任何包含“苏雪梅”文本的`<td>`标签。点(`.`)表示当前节点,所以`contains(.,'苏雪梅')`是查找当前节点及其子节点中包含指定文本的情况。
3. **基于特定父标签的ID定位**:
//tbody[@id='newRankBooks2']//a[contains(text(),'苏雪梅')]
```
如果页面上有多个元素包含“苏雪梅”且你只对特定区域(例如ID为`newRankBooks2`的`<tbody>`内的元素)感兴趣,这个XPath会更加精确。
4. **考虑使用兄弟节点定位**:
如果你想基于与目标元素相邻的其他元素(例如作者名“张莹”)来定位“苏雪梅”,可以使用如下XPath:
//td[a[contains(text(),'张莹')]]/preceding-sibling::td[@class='name']/a[contains(text(),'苏雪梅')]
这个XPath首先定位包含文本“张莹”的`<a>`标签的`<td>`标签,然后向前查找前一个兄弟`<td>`标签,该标签的类为`name`,并且其子`<a>`标签包含文本“苏雪梅”。
day03
1、等待
1)强制等待--调试代码
import time
time.sleep(3)
程序执行到此处会强制等待3s2)隐式等待
driver.implicitly_wait(2)
表示对程序执行整个生命周期内的元素都会等待2s.不需要导包哦3)显式等待
4)包含下拉框的项目地址
包含下拉框的项目地址:https://sahitest.com/demo/selectTest.ht