0 前言
本文将对存内计算前沿论文——ISSCC 2024 34.1进行分享介绍,包括背景介绍、解决方案和架构、主要创新点、最终结果对比四部分内容。
1 背景介绍
题目:《A 28nm 83.23TFLOPS/W POSIT-Based Compute-in-Memory Macro for High-Accuracy AI Applications》;
名称:适用于高精度 AI 应用的 28nm 83.23TFLOPS/W POSIT 内存计算宏;
链接:34.1 A 28nm 83.23TFLOPS/W POSIT-Based Compute-in-Memory Macro for High-Accuracy AI Applications | IEEE Conference Publication | IEEE Xplore
作者团队:清华大学尹首一团队&上海人工智能实验室,第一作者为清华大学Yang Wang;
简述:运用了一种全新的数据格式“POSIT”,可以用较低的位宽达到与高位宽FP几乎相同的训练和推理精度。同时基于这种数据格式,搭建建了一种具有三个特征的数字POSIT CIM宏(BRPU、CPCS、CASU),可达83.23TFLOPS/W的能效和2.74TFLOPS/mm2的面效。
2 解决方案和架构
2.1 challenge & solution
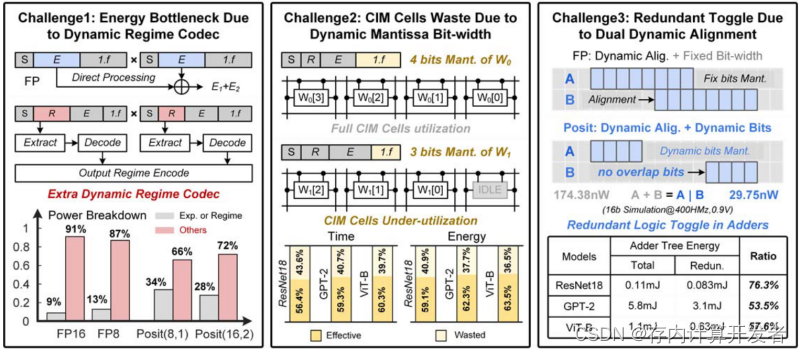
图1 challenge & solution
POSIT的动态特性带来的三个挑战:
1)POSIT的动态机制引入了额外的提取和解码逻辑,这需要比传统FP在同等条件下高2.62倍的功率;
2)POSIT的动态位宽尾数(M)与CIM架构冲突,导致41.3%的CIM未被充分利用;
3)66.8%的动态尾数对齐时没有重叠位,全加器的计算浪费了62.5%的能量。
因此,针对三个挑战提出了对应的解决方案,提出了一种具有三个特征的数字POSIT CIM宏:
1)双向机制处理单元(BRPU),用移位和连接逻辑取代复杂的编解码器逻辑,节省了40.3%的能量;
2)关键位预计算和存储(CPCS)CIM,利用空闲位方便CIM阵列在每个周期执行双位MAC,CIM单元利用率提高63%;
3)循环交替计算调度单元(CASU),如果没有重叠位,用按位或操作代替加法,节省了56.9%的能量。
2.2 该数字POSIT CIM宏(DP-CIM)的整体架构
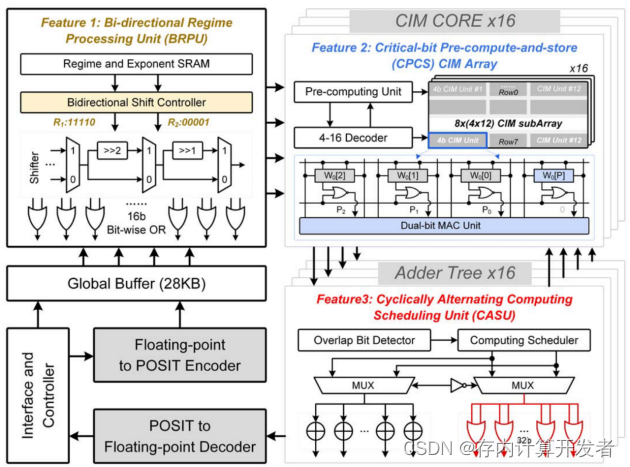
图2 DP-CIM整体架构
整体架构组成:BRPU、16个带CPCS CIM阵列的CIM核、16个带CASU的加法器树、一个28kB的全局SRAM、一个FP2POSIT编码器、一个POSIT2FP解码器、顶层控制器。
数据流:数据先到编码器,FP转换成POSIT格式然后存储。CPCS检测权重位数位宽以预先计算并将逻辑值存储到备用CIM单元中。BRPU执行基于移位或的机制。CIM core具有CPCS,三种工作模式,包括3b模式、2-4b关联模式、正常模式,前两种模式是用预先计算和存储的逻辑值来实现CIM间双位MAC。CASU将加法替换为按位或的操作来代替无重叠尾数,他也改变了CPCS的计算顺序以增加不重叠尾数的数量。以上是此存算基本的数据流通路和计算模式,接下来我们详细介绍BRPU、CPCS、CASU这三个主要处理单元。
3 主要创新点
3.1 POSIT数据格式描述
POSIT数据由4部分组成:符号(S)、区位(R)、指数(E)、尾数(M),定义为POSIT(n,es),细节如下:
1)n是总比特位数;
2)es是指数E的比特位宽;
3)R是具有连续个0或1的一元码(温度计码);
(本文的R表示为:正值时,连续的1的个数减去1,例:R=3表示为“11110”;负值时,即为连续的0的个数,例:R=-4表示为“00001”.)
4)S是符号位,1bit位宽;
5)M和R可以动态变化(此动态机制后文会详细提到),m=n-r-es-1;
POSIT的计算表示为:(R需解码,其中K=2es)
POSIT=(-1)S × (2K)R × 2E × 1.M
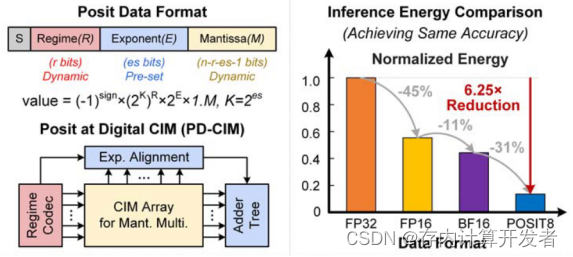
图3 POSIT数据格式
3.2 具有三个特征的数字POSIT CIM宏(DP-CIM)
具有三个特征的数字POSIT CIM宏,以解决POSIT动态特性带来的挑战,主要提出了三块:
1)BRPU处理单元:
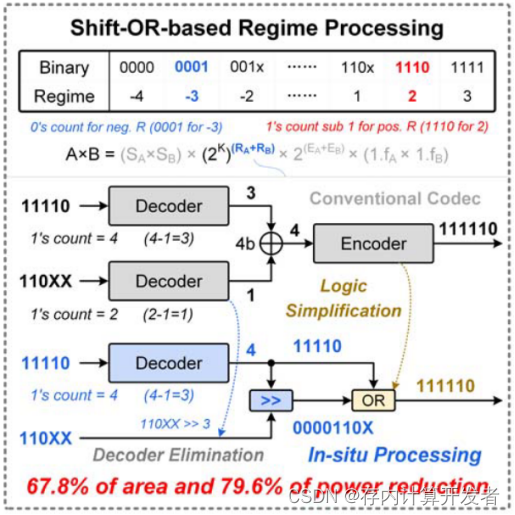
图4 R位计算
一句话解释:利用移位+按位或来代替多位加法+编码实现POSIT数据的R位计算。
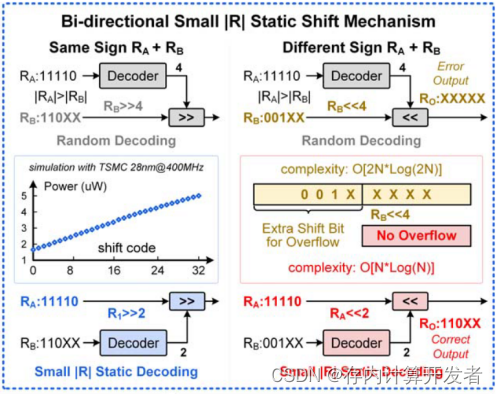
图5 小绝对值数固定的移位
一句话解释:第一种随机移位只适用于两个正数,第二种小绝对值数固定的移位在各种情况下都适用。
2)CPCS处理单元:
一个8*48CIM阵列、一个负载控制器、一个关键位计算单元和一个3-8译码器。每行12个CIM单元,每列8个CIM单元(8行12列,每个单元包含4个存储cell)。
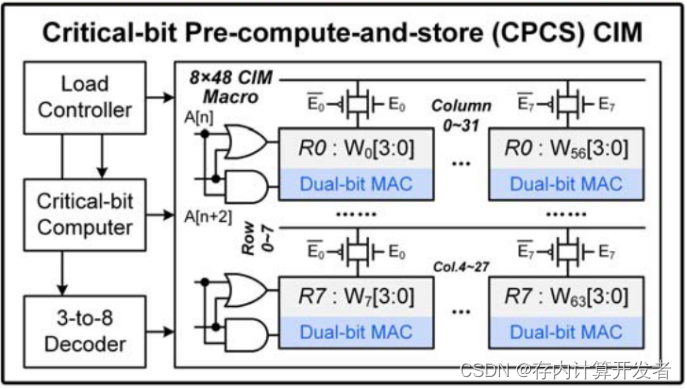
图6 CPCS处理单元
4b CIM单元有三种工作模式,首先来看第一种:
存储3b W[2:0]时,简单来说每个循环中计算P[2:0]=W*(A[n]|A[n+2]),双位MAC单元用这个结果获得O=W*A[n]+W*A[n+2];
当A[2]/A[0]=00/01时,O=P[2:0]=W*A[2]+W*A[0];
当A[2]/A[0]=10时,O=P[2:0]<<2;
当A[2]/A[0]=11时,O=P[2:0]+P[2:0]<<2;
双位MAC单元计算S[3:0]时,S[1]步骤消耗的晶体管最多,所以PCS是先把这一步结果预计算后储存在备用单元中。
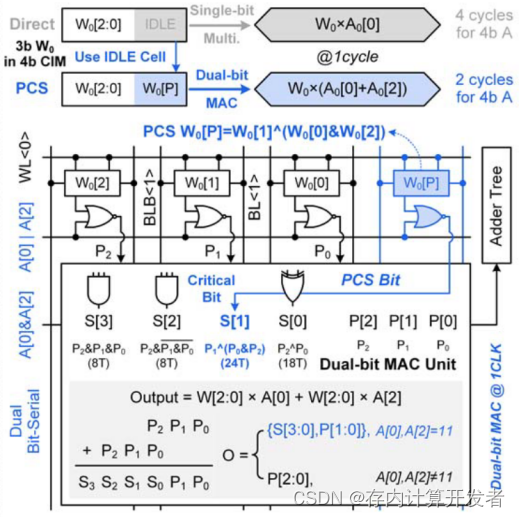
图7 4b CIM的第一种工作模式
第二种模式,当Wn[0]=0时,存储4b权重,将Wn[3:1]视为3b权重,使用2bWm[1:0]中的备用位来存储Wn[P]。
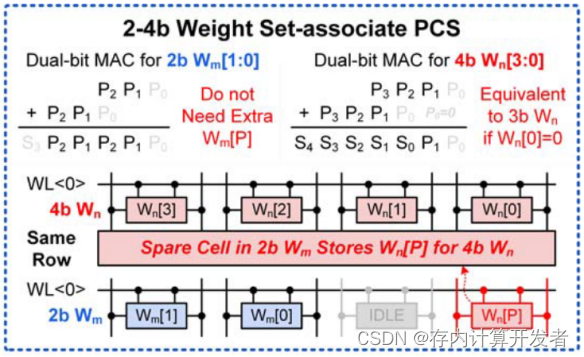
图8 4b CIM的第二种工作模式
第三种模式,当Wn[0]=1时,存储4b权重:进行标准的位串行计算。
3)CASU处理单元
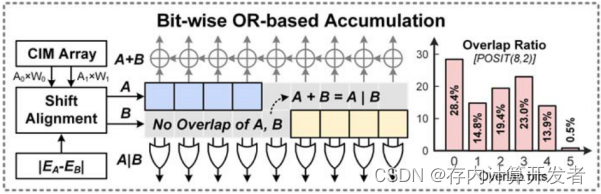
图9 CASU处理单元
一句话解释:对齐后没有重叠位时,直接用按位或代替加法。
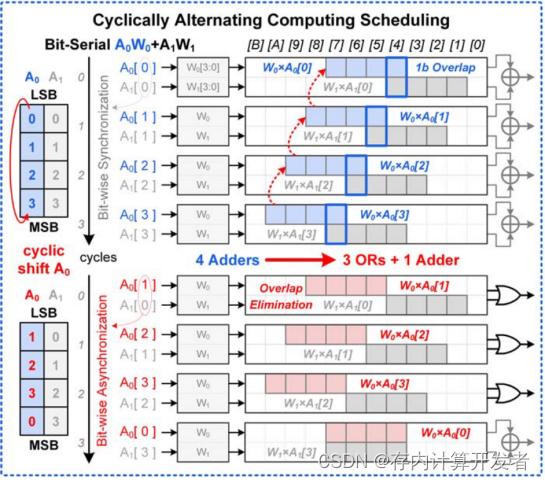
图10 有重叠位时进行置换
一句话解释:对齐后有重叠位,则对W*A和W*B的为串行计算顺序进行置换,创建无重叠条件,它只需要一个加法器。
4 最终结果对比
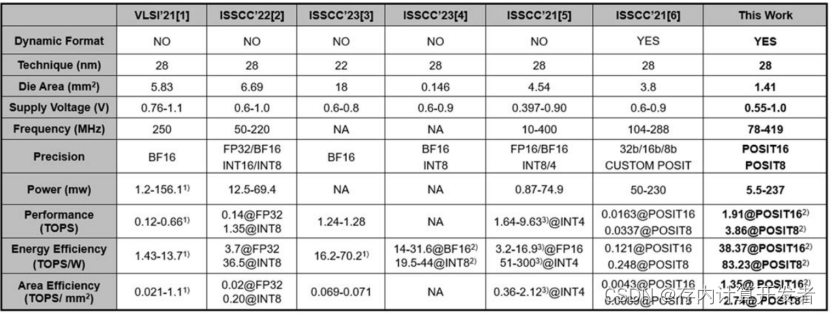
图11 最终性能对比表
与同样使用POSIT数据格式的ISSCC’21,本课题在相同的技术节点下功耗降低了近10倍,POSIT 16下的能效比提升316.11倍、POSIT 8下的能效比提升334.60倍,POSIT 16下的面效比提升312.95倍、POSIT 8下的面效比提升306.87倍。

图12 芯片显微照片
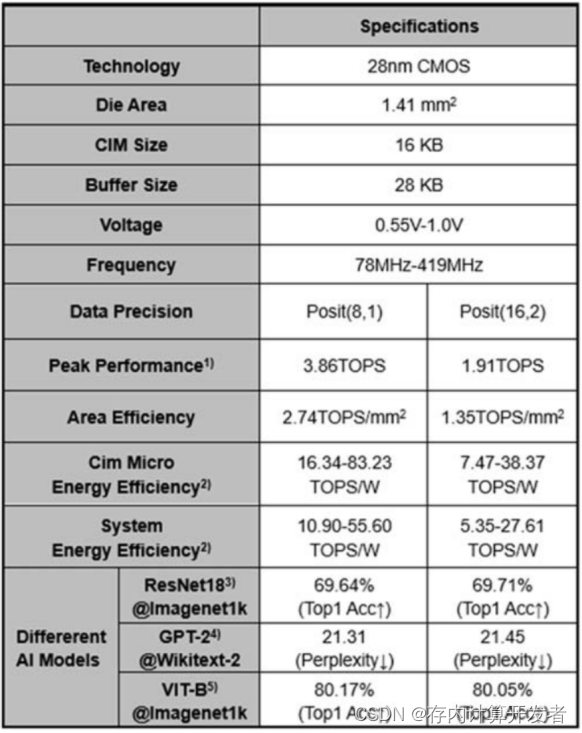
图13 最终测试性能