1. 总体原则
1.1 深度神经网络(Deep Neural Network)的训练过程
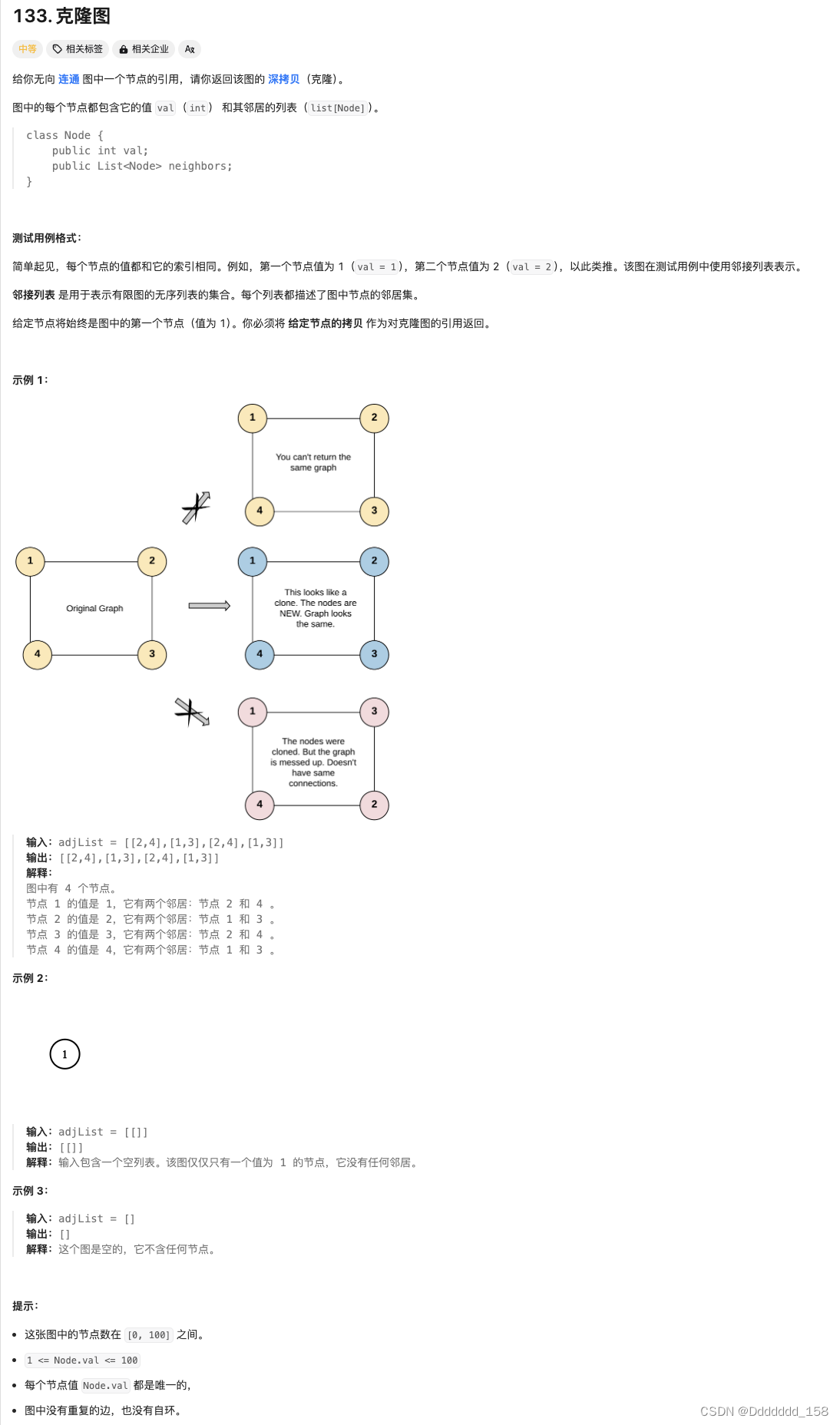
下图展示了自然语言处理(NLP)领域内使用的深度神经网络(Deep Neural Network)的训练过程的简化图。
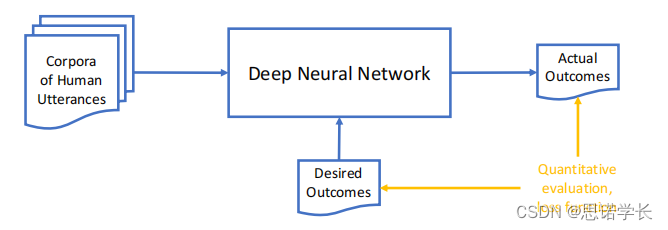
在神经网络的NLP领域:
语料库(Corpora of Human Utterances):这是神经网络训练的起点,包含了大量的人类语言数据。这些数据可以是文本或者是语音形式,用于让机器学习语言的模式。
深度神经网络(Deep Neural Network):这个框代表了一个或多个层次的神经网络,它通过学习语料库中的模式来进行训练。网络的每一层都会提取数据中的不同特征,并逐渐形成复杂的表示。
实际输出(Actual Outcomes):网络在处理输入数据后得到的结果。这些结果是模型当前学习状态的直接产物。
期望输出(Desired Outcomes):这些是在训练过程中用于指导网络训练方向的标签或结果。通过比较实际输出与期望输出,网络可以调整其内部参数。
定量评估、损失函数(Quantitative evaluation, loss function):损失函数是用来衡量实际输出与期望输出之间差异的一个指标。通过最小化损失函数,网络可以优化其参数以更好地进行预测。
在神经NLP哲学中,这种方法完全符合经验主义范式。这意味着,系统完全基于数据来学习语言,而不是基于预设的关于语言如何工作的规则。这是一种归纳的方法:系统分析大量的语料库,并且知道它需要预测什么,但是不被告知如何获得预测结果。初始时,网络对自然语言一无所知,也没有内置关于语言工作方式的假设——至少在理论上是这样。这种方法使得网络能够学习各种语言现象,而不受限于人类语言学家的先入为主的假设。
1.2 激活函数
1.2.1 softmax函数
softmax函数的数学表达式以及他的图,它是深度学习模型中常用的激活函数。
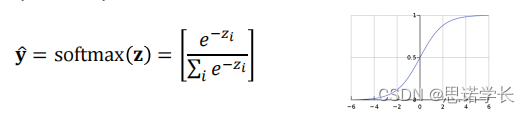
softmax函数的作用是将一个实数向量转换为一个概率分布。对于向量中的每个元素
,通过公式:
计算得到相应的输出,其中
是自然对数的底数,
是输出概率向量中的第
个元素,且所有的
加起来等于1。
这个函数通常用在多分类任务的输出层,它能够给出每个类别的预测概率。
某个变量对应的softmax函数输出值随该变量取值变化的曲线。softmax函数输出是一个S形曲线,当输入值较大时,输出
接近1;当输入值
较小或者为负数时,输出
接近0。
1.2.2 归纳方法
归纳方法(Inductive Approach)在深度学习中的一些含义:
神经网络理论上可以支持任何语言,只要有足够大量的语料库。
输入数据的质量和数量至关重要:为了良好的泛化能力(避免过拟合),输入的语料库需要大量的数据。
数据的质量决定了输出的质量(即“垃圾进,垃圾出”)。
训练任务(即期望的输出)对模型的可重用性和泛化能力有很大影响。
需要选择合适的评估方法。
神经AI类似于神谕机:它提供了结果,但并没有提供验证或理解这些结果的方法(这就是可解释性问题)。
如同统计方法,我们希望以概率形式获得预测结果:神经网络的最后一层通常使用softmax激活函数。
2. 神经网络语言处理的历史
神经网络自然语言处理(NLP)的历史可以追溯到人工神经网络的早期发展。下面是一些关键的历史时刻:
2.1 早期的人工神经网络
早在1943年,McCulloch和Pitts就提出了感知机的概念,这是一种非常初步的神经网络模型。随后,Rosenblatt在1957到1960年间实现了第一个感知机模型,主要用于图像识别。这些单层感知机网络仅仅是线性分类器,其能力有限。
2.2 机器翻译作为AI的主要动机
1954年,Georgetown-IBM实验成功地将大约70个精心挑选的句子翻译成俄语。这项实验大部分是一次通信操作,使用的是非常简单的词典方法。
2.3 AI冬天
Minsky和Papert在1969年的著作《感知机》中提出了悲观的观点:简单的感知机网络过于有限,多层密集网络过于复杂,无法扩展。
这也是关于支持编程(符号化、程序化)还是根本性的神经方法设计计算硬件的辩论。
1969年的ALPAC报告(自动语言处理咨询委员会)指出,超越人类的机器翻译在近期内是无法实现的,应该专注于为人类提供工具。
这段历史反映了神经NLP的起源和早期发展的挑战,以及人工智能研究的起伏变化。当时的科技和理论限制了早期神经网络模型的能力,导致了长时间的停滞期。然而,随着时间的推移,尤其是在近几十年内,硬件的进步、大数据的可用性以及深度学习方法的发展,使得神经网络模型再次成为NLP研究的前沿。
2.4 1980年代
人工神经网络研究获得新的活力。
Rumelhart、Hinton和Williams在1986年实现了反向传播学习算法,并进行了实验研究。
开始对两层和三层网络进行建模和研究。
循环神经网络(RNN)的研究开始兴起,这类网络可以处理任意长度的文本。
2.5 1990年代
基于语料库的统计方法出现,并逐渐取得成功。
例如,基于案例的机器翻译技术。
分布语义学开始使用单词的统计分布,如奇异值分解(SVD),这是早期的‘词嵌入’方法。
隐藏马尔科夫模型(HMM)、最大熵模型、条件随机场(CRF)等开始用于更加健壮地解决经典NLP任务。
2.6 1997年
长短期记忆网络(LSTM)的发明,这是一种RNN变体,能更好地处理任意长度的文本。
2.7 2001年:神经网络语言模型
神经网络语言模型的发展,这些模型基于之前n个单词来预测下一个单词。灵感来自于之前在语音识别中的工作,这是一种前馈网络(没有循环)。
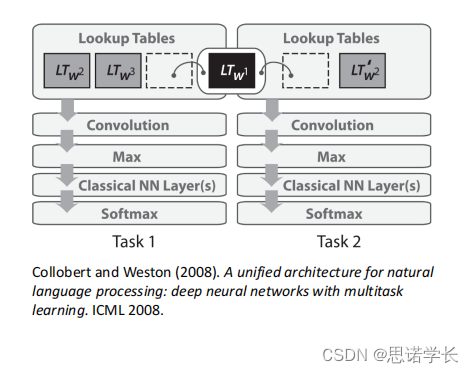
神经语言模型是由Bengio等人在2001年提出的。这个模型通过学习单词的特征向量(类似于词嵌入),并使用它们来预测序列中下一个单词的概率。这个模型被认为是现代词嵌入和深度学习在NLP中应用的先驱。在这个结构中,单词通过查找表(lookup table)转换为特征向量,然后这些向量被送入一个神经网络,网络通过softmax层来预测下一个单词。这个模型的核心在于它可以同时学习单词表示和语言模型。

2.8 2008年:multitask learning多任务学习
多任务学习的兴起,能够利用预训练的词向量在同一个网络中训练多种任务。
下图描述了Collobert和Weston在2008年提出的一种多任务学习的深度神经网络架构,这种架构能够在同一个神经网络中同时训练多个NLP任务,例如词性标注(POS)、命名实体识别(NER)、语义角色标注和困惑度(用于判断一个句子是否有意义)。这种架构的关键是使用预训练的词向量作为多个任务的共享表示,这种方法提高了效率和性能。
2.9 2013年
word2vec的推出,它是一种利用神经网络实现分布式语义的工具,由于以下原因而具有突破性:
高效的训练方法,甚至可以在个人电脑上运行。
由于参数调优得当,取得了更好的结果。
这是一个实实在在走出实验室的工具。
由于其出色的结果,对AI社区产生了重大影响。
2.10 2017年
Transformer模型和注意力机制的出现,这在几乎所有语言处理任务中都是一个根本性的突破。
2.11 GPT和大型语言模型(LLMs)
这些模型仍然基于Transformer架构,但有所新颖的是:
网络规模更大,训练数据以自然语言表达(例如提示)。
这些发展改变了NLP的研究和应用领域,大大提高了语言模型处理各种任务的能力,从基本的文本分类到复杂的问答和文本生成等。这种架构也催生了诸如GPT这样的预训练模型,它们能够理解和生成自然语言,对各种语言处理任务产生了深远的影响。
3. 语言处理网络的流水线Neural NLP Pipeline
下图展示了现代神经网络自然语言处理(NLP)的典型流程。尽管存在许多变体,但这种方法已成为主导。具体步骤包括:

3.1 步骤一:语料库准备(Corpus Preparation)
质量和数量充足的训练数据是模型性能的关键。这一步骤包括处理语料库的形式和内容上的异质性。
3.1.1 形式的异质性Heterogeneity in form:
a. 从在线文档(如PDF、HTML等)中提取“原始”文本通常比说起来容易做起来难。这个过程可能需要特殊的解析工具和大量的数据清洗。
b. 字符编码的统一:相同的文本可能因为不同的编码方式而呈现为不同的标记,这会增加词汇量大小,引入噪声等问题。尽管Unicode编码已广泛支持超过30年,旧编码仍在使用中。Unicode标准化形式通过规范的和兼容性的构成与分解帮助减少异质性。
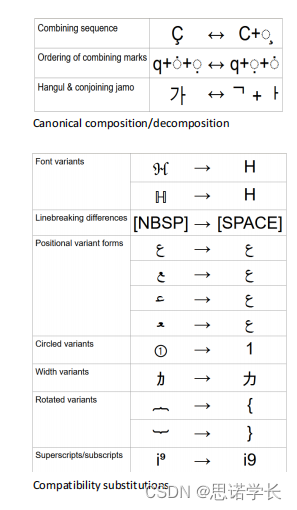
c. 各种文本字符的规范化形式,在语料库准备阶段是处理文本异质性的重要环节。下图具体列出了如何处理字符编码的不同情况,包括合并序列、韩语音节的组合、规范组合/分解、字体变体、换行差异、位置变体形式、圆圈变体、宽度变体、旋转变体、上标/下标以及兼容性替代等。
d.针对任务的简化,如小写转换(例如bert-base-uncased)。然而,在大多数情况下,保留大写是很重要的,比如用于识别专有名词、情感分析等——需要谨慎处理!
3.1.2 内容上的异质性Heterogeneity in content
异质性是否有用、无关紧要或有害,取决于要解决的任务。对于特定的任务,可能需要侦测语言,并使用特定语言的语料库。
针对特定领域的任务使用特定领域的语料库。
不平衡的语料库:某些类别可能表现为数量过多或过少。
有偏见的语料库:不希望出现的内容过于突出。
3.1.3 处理异质性通常要考虑什么
在实际操作中,处理异质性通常要考虑以下几点:
a. 尽可能降低异质性,以提高训练和预测的效率。
b. 如果无法降低,可以增加异质性,让模型学会处理它。
c. 根据任务需求,采取针对性的预处理措施,如分词、标准化、去除或替换不需要的字符等。
d. 在数据预处理时要注意保留对任务有用的信息,避免过度清洗数据导致信息丢失。
总的来说,语料库准备是建立高质量NLP模型的基础,需要精心设计和执行,以确保最终模型的有效性和准确性。
3.2 步骤二:计算词汇表Computing the Vocabulary: Token Splitting
嵌入(Embedding):将语言空间转换为数值向量空间。这包括计算一个词汇表,并将输入语料库分割为标记(tokens),然后为每个标记计算一个高效且有意义的数值(向量)表示。
在神经网络自然语言处理(NLP)中,计算词汇表即确定组成语料库的基本词汇。词汇表的计算关键在于如何定义和划分“标记”(token)。
所谓“标记”,实际上可以看作是神经网络NLP的基本单位。通常情况下,我们可以简单地将“标记”理解为词、标点符号、表情符号等,它们通常由空白字符分隔开。
3.2.1 解决方案 #1
3.2.1.1 标记的定义
将标记定义为{单词, 标点(如逗号)、表情符号等}的集合,这些标记之间由空白符隔开。这种方法在传统词嵌入技术中使用较多,比如word2vec、GloVe等。
在西方语言中,使用空白和标点来分割单词相对简单。但对于不标记词边界的语言(如中文或泰语),就需要使用复杂的算法(通常是机器学习算法)来进行标记化。
3.2.1.2 空白和标点来分割单词的缺点
词级以下的构词能力被隐藏:比如单词 house 和 houses 会被视为独立的词汇表条目,它们之间没有先验的共同点。网络需要仅通过上下文来学习它们的相似性,但不会意识到一个是另一个的复数形式。
同样的,对于像“démilitarisons”(法语中的一个词,意味着“我们停止军事化”)这样的单词,它的构成信息如时态、语气、数、根本含义、否定含义等都被隐藏了。
对于高度屈折或黏着性的语言(世界上大多数语言,但不包括英语或汉语),这是一个坏消息:一个大型语料库可能包含远超10万个不同的单词,其中大多数出现频率不高,这使得模型的泛化变得更加困难。
因此,在不同语言环境下进行标记化时,需要考虑到以上这些问题,并选择合适的策略以便更好地处理语言的复杂性和多样性。
3.2.2 解决方案 #2:标记化可以基于字符集(即“字符嵌入”)
在自然语言处理中采用基于字符集的标记化策略,这里的 字符集 通常指Unicode字符集。这意味着每个字符——无论是字母、数字、标点符号还是其他符号——都作为单独的标记来处理。这样做的好处是词汇量相对较小,实现起来比基于单词的分割要简单,特别是对于不同语言都适用。
使用字符级别的嵌入意味着每个字符都会被转换成一个数值向量,这个向量将被用作神经网络的输入。例如,在Google的百亿词语言模型中,就使用了这种字符级的嵌入。
采用字符级嵌入的后果包括:
训练速度和模型轻量化:由于词汇量小,模型训练速度会更快,模型也相对更轻。
大部分嵌入单元无明确意义:字符级嵌入可能不会捕获到像单词那样的明确语义信息。
存在意义相似的例外:如数字、标点、大小写字母等,这些字符在不同语境中具有一致或相似的用途和意义。
适合中文等语言:对于中文这样的语言,单个字符往往近似于一个意义单元,因此,字符嵌入可以很好地捕获语义信息。
形声字的特殊处理:大约80%的汉字是形声字,包含了声音和意义的信息。例如,“晴”字包含了“日”(太阳)的意思,并且读音为“qīng”,与“晴朗”或“清晰”相关。
可以用于更细粒度的任务:字符级嵌入可用于诸如语音识别/合成等任务,它们允许模型处理更细微的语言差异。
通常,字符嵌入并不单独使用,而是结合到更高级别的嵌入(如单词或短语级别)中,以丰富和改善模型对语言的理解和处理。在处理未知词或罕见词时,字符嵌入特别有用,因为即使模型之前未见过某个单词,它也可以通过字符组合来尝试理解该单词的意义。
3.2.3 解决方案 #3:标记可以是单词、子词、标点符号(如逗号)、表情符号
在神经网络自然语言处理(NLP)中,为了解决单词级标记和字符级标记的局限性,人们引入了 子词级(subword)标记方法。子词是介于单词和字符之间的一种妥协方案:相比单词,它减少了词汇表的大小;相比字符,它又保留了更多的意义
子词是语料库中最频繁出现的字符序列。这个定义完全是基于数据压缩的思想,并不基于语言学原理。
然而,假设在大型语料库中,子词能够近似于有意义的语言单位,即语素。例如,在法语中,词尾经常以"-ez"结尾,所以它是一个很好的子词候选。
现在,几乎所有的大型语言模型(LLM)都使用子词,包括Transformer模型。
3.2.4 Byte Pair Encoding (BPE) 一种压缩算法
3.2.4.1 算法的步骤
原始算法:BPE(字节对编码,Philip Gage,1994年),以适应版本使用。
1. 将语料库表示为以空格分隔的标记序列。
2. 最初,基础标记词汇表由字符集合及其在语料库中的频率构成。
3. 找到最频繁的两个标记序列(“字节对”),将它们合并为新符号
加入
,在
中减少
和
的频率,并在语料库中将序列
替换为
。
4. 重复步骤3,直到达到词汇表大小限制或增量收益很低。
5. 在词汇表之外的所有标记在语料库中表示为“未知标记”[UNK]。
这个算法是贪心的,执行速度快(存在线性时间复杂度的实现)。它被证明接近最优,而真正的最优算法的复杂度是或更高(Gallé, EMNLP 2019)。这样的算法使得模型在处理单词的变体或新词时具有更好的泛化能力,并且可以更有效地处理语料库中的稀有词。
Byte Pair Encoding (BPE) 是一种压缩算法,后来被应用到自然语言处理的子词切分(subword segmentation)中,用于处理词汇表外的单词或更高效地表示词汇。在NLP中,BPE可以减少处理未知词(out-of-vocabulary, OOV)的问题,因为它将单词分解为更常见的子单位。
3.2.4.2 算法的详细解释
输入:一个句子,如 ‘the longest and widest pools are the best’。

3.2.4.3 步骤
a.初始标记化:首先,将句子分割为标记。在这个例子中,单词被分解为字母序列,并且每个单词末尾加上下划线 `_` 以区分单词边界。所以 "the" 变成 `[t h e _]`。
b.统计并合并频繁对:计算各个字符对在整个语料库中出现的频率。这个例子中,`t+h`, `h+e`, `e+_`, `e+s`, `s+t`, `t+_` 是出现频率最高的字符对。
c.合并最频繁的字符对:选择最常见的字符对,并在所有标记中将这个字符对合并为一个新的标记。例如,`e` 和 `s` 被合并为 `es`,因为 `e+s` 是最常见的字符对之一。
d.重复:重复第2步和第3步,每次迭代都选择最常见的字符对进行合并。每一轮合并之后,标记的表示都会稍微简化。
e.继续合并:继续这个过程,直到达到预定的词汇表大小或者再合并不会有显著的收益。
在整个过程中,BPE算法是贪心的,它每次都选择当前最频繁的字符对进行合并。在一个足够大的语料库上应用BPE算法后,最终会形成一系列的子词单元,这些子词单元能够有效地表示单词的不同形态变化。
3.2.4.4 结果
经过多轮迭代之后(通常在更大的语料库上),句子中的单词被分解为更基础的、频繁出现的子单位,如 `the_ long est_ and_ wid est_ pools_ are_ the_ b est_`。这样,模型就能够处理词汇表中不存在的单词,同时还可以更好地捕捉单词的内在结构,如词根、词缀等。
3.2.4.5 BPE的局限性
Byte Pair Encoding(BPE)是一种基于数据压缩的子词切分技术,它在自然语言处理中被用于减小词汇表的大小并增强模型对于生僻词的处理能力。然而,BPE并不是没有局限性,主要包括:
a. 非语言学合并:BPE算法是贪心的,它可能会在非语言学的方式下将频繁出现的字节对合并起来,如例子中的后缀“-est”。这可能导致一些非预期的合并,比如在单词“rest”中也会应用"-est"。
b. 改进版的BPE
WordPiece:Google未公开的WordPiece算法使用点互信息(pointwise mutual information, PMI),而不是像BPE那样仅使用频率。如果两个子词不太可能独立出现,它们被合并的可能性就更大。WordPiece通过评分机制来考虑两个子词组合出现的频率与它们各自出现频率的比值。
SentencePiece:这种算法不假设存在由空格分隔的单词,因此适用于东亚语言,例如中文和日文。SentencePiece的优势在于它可以在没有明确单词边界的文本上直接进行子词分割。
c. 近似的形态学分割:尽管BPE和它的变种可以在某种程度上近似真实的形态学分割,但仍然不够精确。比如在测试WordPiece分词能力时,它可能会产生一些意外的切分,如将 tokenization 切分为 to ken ization。
d. 形态学丰富的语言问题:对于形态学丰富的语言,比如阿拉伯语、土耳其语或芬兰语,这种基于频率的分割方法可能不太适用,因为这些语言的单词变形非常丰富复杂。
e. 研究方向:目前的研究正在尝试结合形态学分析或形态学词典与BPE等子词切分技术,以期获得更精准的语言模型输入表示。
总的来说,BPE及其衍生算法是理解和处理子词级别信息的强大工具,但它们在处理复杂语言形态时的限制也激发了对新方法的研究和开发。
3.2.5 分布式语义学(Distributional Semantics)
3.2.5.1 分布式语义学的基本概念
分布式语义学(Distributional Semantics)基于一个核心假设:一个词的含义可以通过它出现的上下文来定义和捕捉。这一理论认为,如果两个词在相似的上下文中出现,那么它们的含义也相似。这就是所谓的分布式假设(distributional hypothesis)。
在神经网络中,我们不能直接使用单词或字符串,因为神经网络运作的是数字。因此,我们需要为词汇表V中的每个标记分配一个数字向量。通过训练过程,网络“学习”了每个向量的含义,这些含义是根据其他向量的上下文推断出来的。
在分布式语义学的早期方法中,最直接的方式是统计词语共现的次数:单词 X 和单词 Y 一起出现了多少次。这里的“一起”可以指紧挨着出现,也可以是在同一个文档中出现。这通常被形式化为一个大小为n的上下文窗口。
这种方法的结果是一个共现矩阵,这是一个对称矩阵,在对角线上是零。每个词的分布式表示就是它的共现向量。
共现矩阵和向量往往非常巨大且稀疏。为了解决这个问题,线性代数中的奇异值分解(SVD)技术被用来降维,这在自然语言处理中的应用就是潜在语义分析(Latent Semantic Analysis,LSA)。
简而言之,分布式语义学试图利用统计学习方法来捕捉单词的语义,认为单词的含义可以通过它与其他单词在大量文本中的共现关系来表示。通过这种方式,即使是没有明确定义的词汇,也可以根据其在语料库中与其他词汇的关联程度来推断其含义。
3.2.5.2 词共现矩阵
这个表格是一个词共现矩阵的示例,它体现了分布式语义的概念。在这个矩阵中,我们可以看到两个句子:“The cat chased the mouse in the barn.” 和 “A cat chased a rat in the attic.”,以及基于这两个句子构建的词共现情况。

分布式语义假设上下文相似的单词意义也相似。在这里,上下文是指单词周围的其他单词。为了将单词表示成可以被神经网络处理的数值,每个单词都与一个数字向量相关联。
这个共现矩阵是根据上下文窗口大小计算的,这里窗口大小是正负2个单词。表中的每个数字表示在上下文窗口中,行标题的单词与列标题的单词共同出现的次数。比如,the 和 cat 在一定的上下文窗口内共现了2次。矩阵是对称的,对角线上的值为0,因为它表示单词与其自身的共现,这在计算中通常被忽略。
词共现矩阵和向量往往非常大且稀疏,一个常用的解决方案是使用代数中的奇异值分解(SVD)技术,它在自然语言处理中被用于潜在语义分析(LSA)中。通过LSA,可以将词共现矩阵降维到更小、更密集的向量空间,从而提取出词义的潜在结构。
3.2.6 词嵌入(Word Embeddings)
这是一种文本表示形式,它能将单词转换为一组定长的数值向量。这些向量能够捕捉单词的语义特征,使得语义上相近的单词在向量空间中也相互靠近。
词嵌入是通过神经网络从大量文本数据中自动学习得到的,是自然语言处理中的一项重要技术。以下是对词嵌入输入输出、训练方式和参数选择的解释:
3.2.6.1 输入和输出
输入:词嵌入模型的输入是一个大型的、已经分词的训练语料库,这个语料库包含了丰富的词汇(V)。
输出:对于词汇表V中的每个词汇,词嵌入模型会计算出一个固定维度N的词向量(也称为“语义特征”向量)。这意味着每个单词都被表示为一个N维的实数向量。
3.2.6.2 词嵌入与其他文本表示方法的关系
词嵌入可以看作是共现矩阵(co-occurrence matrices)和奇异值分解(SVD)/潜在语义分析(LSA)的神经网络等价物。研究表明,当其他条件相同时,这三种表示方法在预测能力上是相似的。这表明,尽管词嵌入是通过神经网络计算得到的,但它们与传统的基于统计的文本表示方法有着本质上的联系。
3.2.6.3 如何计算词嵌入
实际上,用于生成词嵌入的输入向量是通过另一个神经网络计算得到的。这意味着,我们使用一个神经网络来学习如何将文本表示为词嵌入向量。
3.2.6.4 参数选择
V(词汇表大小):原始的词嵌入模型中,词汇表的大小大约在10,000到50,000之间。这是模型的一个超参数,需要根据具体的应用场景进行调整。
N(向量维度):词向量的维度,通常设定为300。向量维度是另一个超参数,它决定了词向量空间的大小。较大的维度可以捕捉更多的语义信息,但也会增加模型的计算复杂度和存储需求。
总的来说,词嵌入通过学习语料库中单词的使用模式,为每个单词生成一个固定维度的数值向量,这些向量能够有效地表示单词的语义信息。词嵌入的计算依赖于神经网络模型,且涉及到一些重要的超参数选择,如词汇表的大小和词向量的维度。
3.3 步骤三:自监督预训练(Self-supervised Pre-training)
获取关于语言的“通用知识”。这类似于符号和统计方法的上游语言分析和特征提取任务。自监督范式是一种可以容易且稳定自动生成的监督任务。
3.4 步骤四:监督训练(Supervised Training)
将预训练模型适配(或称为“微调”)到要解决的具体任务。监督是指通过手动或(复杂的)自动化方法获得的训练数据,使用特定于领域的评价指标进行控制。
整个流程从原始语料库开始,经过预处理、生成嵌入、自监督学习基础语言模式,最终通过监督学习适配到特定的NLP任务。这个流程体现了从广泛语言理解到特定任务应用的过程。