引入
针对用户画像项目来说(产品)必须要支持从多种数据源加载业务数据,构建用户标签。
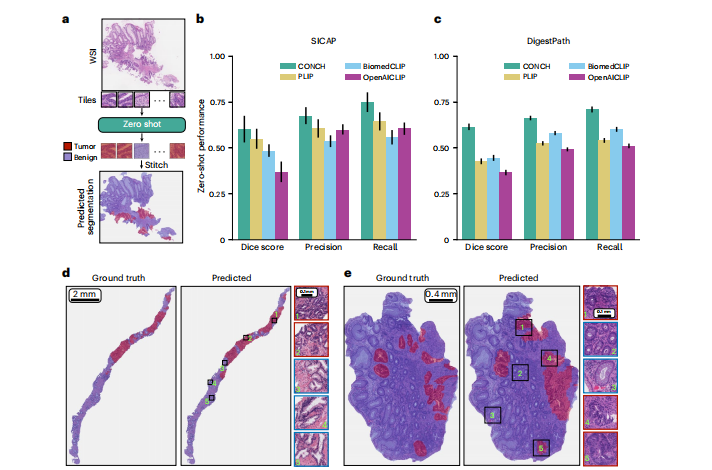
在之前的标签模型开发中,主要是为了简化开发复杂度,业务数据统一存储到HBase表中。
数据源包含如下几个方面:
存储HDFS文件系统
存储Hive表
存储HBase表
存储MySQL表
存储NoSQL数据库:Redis数据库、MongoDB数据库
存储Elasticsearch索引库
存储Kafka分布式队列
封装数据为RDD:
val offsetRanges = Array(
// topic, partition, inclusive starting offset, exclusive ending offset
OffsetRange(“test”, 0, 0, 100),
OffsetRange(“test”,1, 0, 100),
)
val rdd = KafkaUtils.createRDD[String, String](sparkContext, kafkaParams, offsetRanges, PreferConsistent)封装数据为DataFrame:
// Subscribe to multiple topics, specifyingexplicit Kafka offsets
val df = spark
.read
.format(“kafka”)
.option(“kafka.bootstrap.servers”, “host1:port1, host2:port2”)
.option(“subscribe”, “topic1, topic2”)
.option(“startingOffsets”, “””{“topic1”:{“0”:23,”1”:-2},”topic2”:{“0”:-2}}”””)
.option(“endingOffsets”, “””{“topic1”:{“0”:50,”1”:-1},”topic2”:{“0”:-1}}”””)
.load()
df.selectExpr(“CAST(key AS STRING)”, “CAST(value AS STRING)”)
.as[(String, String)]用户数据多种数据源
进入正题,先说明一下我们的用户画像:
1)、面向业务的用户标签及用户画像管理中台
统一规范的标签可视化管理中台,业务人员可自助生产和维护标签,适应营销策略变化。
2)全端采集用户行为数据,整合业务数据等多种数据源,帮助企业构建体系化用户标签图书馆,输出用户画像,赋能业务实现用户精细化运营和精准营销。
具体功能说明
1)、构建用户价值体系
实现用户召回等精准营销目标
用户在平台消费几次后,一段时间内没有再次访问平台进行消费,我们需要对其进行流失召回。
2)、输出全景用户画像
管理客户全生命周期、有效提升用户体验
用户群体的特征属性和偏好概况,使用产品的方式是否和预期一致;为精准营销做有效的数据支撑
3)、利用用户标签形成用户分层
提供个性化推荐内容,持续提升用户转化
用户在平台的消费金额达到一定的级别时,根据其消费能力不同,投其所好的推荐不同价格定位的商品。
4)、利用智能算法,快速找到相似似人群
补充标签定制的不足,高效锁走目标人群
选定种子人群,根据特征在更大范围内为每个用户计算相似度,精准找到相似人群,挖掘更多潜在客户
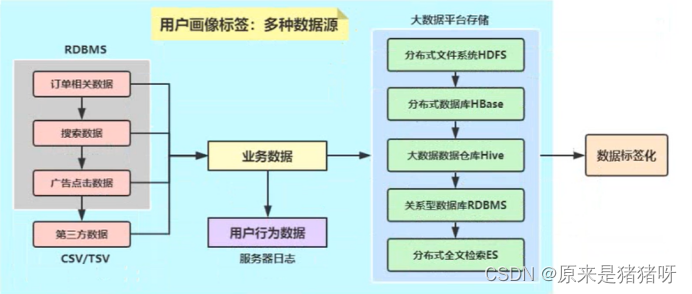
数据源概述
针对用户画像标签系统来说,不同标签(业务标签,4级标签)来源于不同的业务数据(订单相关数据、搜搜数据、广告点击数据等)、用户行为数据以及第三方数据(社交数据、信用数据等)构建而来。
不同类型数据采集存储在不同的存储引擎系统(比如HDFS、HBase、Hive、Elasticsearch、MYSQL数据库等),因此需要用户画像标签系统可以支持从不同的数据源读取业务数据,进行构建标签,恰好Spark SQL支持多数据源的加载与保存。
加载HBase表
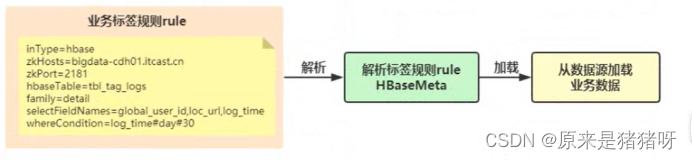
前面的标签开发中,无论是加载注册会员信息表tbl_tag_users还是订单数据表tbl_tag_orders,都是从HBase数据库中读取,自己依据Spark SQL实现外部数据源接口,在标签管理平台构建标签时,通过标签规则rule传递参数,开发标签模型时:解析标签规则获取业务数据,逻辑如下:
重构代码(加载数据)
将上述代码抽象为两个方法:
其一:解析标签规则rule为Map集合
其二:依据规则Map集合中inType判断具体数据源,加载业务数据
编写MetaParse对象object,创建方法parseRuleToMap和parseMetaToData
- 、解析规则rule为参数ParamsMap
获取业务标签规则rule,按照分隔符分割数据,具体实现代码如下:
import org.apache.spark.internal.Logging
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 加载业务数据工具类:
* 解析业务标签规则rule,依据规则判断数段数据源,加载业务数据
*/
object MetaParse extends Logging {
/**
* 依据标签数据,获取业务标签规则rule,解析转换为Map集合
* @param tagDF 标签数据
* @return Map集合
*/
def parseRuleToParams(tagDF: DataFrame): Map[String, String] = {
import tagDF.sparkSession.implicits._
// 1. 4级标签规则rule
val tagRule: String = tagDF
.filter($"level" === 4)
.head()
.getAs[String]("rule")
logInfo(s"==== 业务标签数据规则: {$tagRule} ====")
// 2. 解析标签规则,先按照换行\n符分割,再按照等号=分割
/*
inType=hbase
zkHosts=bigdata-cdh01.itcast.cn
zkPort=2181
hbaseTable=tbl_tag_logs
family=detail
selectFieldNames=global_user_id,loc_url,log_time
whereCondition=log_time#day#30
*/
val paramsMap: Map[String, String] = tagRule
.split("\n")
.map{ line =>
val Array(attrName, attrValue) = line.trim.split("=")
(attrName, attrValue)
}
.toMap
// 3. 返回集合Map
paramsMap
}
/**
* 依据inType判断数据源,封装元数据Meta,加载业务数据
* @param spark SparkSession实例对象
* @param paramsMap 业务数据源参数集合
* @return
*/
def parseMetaToData(spark: SparkSession,
paramsMap: Map[String, String]): DataFrame = {
// 1. 从inType获取数据源
val inType: String = paramsMap("inType")
// 2. 判断数据源,封装Meta,获取业务数据
val businessDF: DataFrame = inType.toLowerCase match {
case "hbase" =>
// 解析map集合,封装Meta实体类中
val hbaseMeta = HBaseMeta.getHBaseMeta(paramsMap)
// 加载业务数据
spark.read
.format("hbase")
.option("zkHosts", hbaseMeta.zkHosts)
.option("zkPort", hbaseMeta.zkPort)
.option("hbaseTable", hbaseMeta.hbaseTable)
.option("family", hbaseMeta.family)
.option("selectFields", hbaseMeta.selectFieldNames)
.option("filterConditions", hbaseMeta.filterConditions)
.load()
case "mysql" =>
// 解析Map集合,封装MySQLMeta对象中
val mysqlMeta = MySQLMeta.getMySQLMeta(paramsMap)
// 从MySQL表加载业务数据
spark.read
.format("jdbc")
.option("driver", mysqlMeta.driver)
.option("url", mysqlMeta.url)
.option("user", mysqlMeta.user)
.option("password", mysqlMeta.password)
.option("dbtable", mysqlMeta.sql)
.load()
case "hive" =>
// Map集合,封装HiveMeta对象
val hiveMeta: HiveMeta = HiveMeta.getHiveMeta(paramsMap)
// 从Hive表加载数据, TODO:此时注意,如果标签模型业务数从Hive表加载,创建SparkSession对象时,集成Hive
spark.read
.table(hiveMeta.hiveTable)
// def select(cols: Column*): DataFrame, selectFieldNames: _* -> 将数组转换可变参数传递
.select(hiveMeta.selectFieldNames: _*)
//.filter(hiveMeta.whereCondition)
case "hdfs" =>
// 解析Map集合,封装HdfsMeta对象中
val hdfsMeta: HdfsMeta = HdfsMeta.getHdfsMeta(paramsMap)
// 从HDFS加载CSV格式数据
spark.read
.option("sep", hdfsMeta.sperator)
.option("header", "true")
.option("inferSchema", "true")
.csv(hdfsMeta.inPath)
.select(hdfsMeta.selectFieldNames: _*)
case "es" =>
null
case _ =>
// 如果未获取到数据,直接抛出异常
new RuntimeException("业务标签规则未提供数据源信息,获取不到业务数据,无法计算标签")
null
}
// 3. 返回加载业务数据
businessDF
}
}加载Hive表
import org.apache.spark.sql.Column
/**
* 从Hive表中加载数据,SparkSession创建时与Hive集成已配置
inType=hive
hiveTable=tags_dat.tbl_logs
selectFieldNames=global_user_id,loc_url,log_time
## 分区字段及数据范围
whereCondition=log_time#day#30
*/
case class HiveMeta(
hiveTable: String,
selectFieldNames: Array[Column],
whereCondition: String
)
object HiveMeta{
/**
* 将Map集合数据解析到HiveMeta中
* @param ruleMap map集合
* @return
*/
def getHiveMeta(ruleMap: Map[String, String]): HiveMeta = {
// 此处省略依据分组字段值构建WHERE CAUSE 语句
// val whereCondition = ...
// 将选择字段构建为Column对象
import org.apache.spark.sql.functions.col
val fieldColumns: Array[Column] = ruleMap("selectFieldNames")
.split(",")
.map{field => col(field)}
// 创建HiveMeta对象并返回
HiveMeta(
ruleMap("hiveTable"), //
fieldColumns, //
null
)
}
}加载HDFS表
import org.apache.spark.sql.Column
/**
* 从HDFS文件系统读取数据,文件格式为csv类型,首行为列名称
inType=hdfs
inPath=/apps/datas/tbl_logs
sperator=\t
selectFieldNames=global_user_id,loc_url,log_time
*/
case class HdfsMeta(
inPath: String,
sperator: String,
selectFieldNames: Array[Column]
)
object HdfsMeta{
/**
* 将Map集合数据解析到HdfsMeta中
* @param ruleMap map集合
* @return
*/
def getHdfsMeta(ruleMap: Map[String, String]): HdfsMeta = {
// 将选择字段构建为Column对象
import org.apache.spark.sql.functions.col
val fieldColumns: Array[Column] = ruleMap("selectFieldNames")
.split(",")
.map{field => col(field)}
// 创建HdfsMeta对象并返回
HdfsMeta(
ruleMap("inPath"), //
ruleMap("sperator"), //
fieldColumns
)
}
}(叠甲:大部分资料来源于黑马程序员,这里只是做一些自己的认识、思路和理解,主要是为了分享经验,如果大家有不理解的部分可以私信我,也可以移步【黑马程序员_大数据实战之用户画像企业级项目】https://www.bilibili.com/video/BV1Mp4y1x7y7?p=201&vd_source=07930632bf702f026b5f12259522cb42,以上,大佬勿喷)