第五章 深度学习
十三、自然语言处理(NLP)
2. 传统NLP处理技术
2.1 中文分词
中文分词是一项重要的基本任务,分词直接影响对文本语义的理解。分词主要有基于规则的分词、基于统计的分词和混合分词。基于规则的分词主要是通过维护词典,在切分语句时,将语句的每个子字符串与词表中的词语进行匹配,找到则切分,找不到则不切分;基于统计的分词,主要是基于统计规则和语言模型,输出一个概率最大的分词序列(由于所需的知识尚未讲解,此处暂不讨论);混合分词就是各种分词方式混合使用,从而提高分词准确率。下面介绍基于规则的分词。
2.1.1 正向最大匹配法
正向最大匹配法(Forward Maximum Matching,FMM)是按照从前到后的顺序对语句进行切分,其步骤为:
- 从左向右取待分汉语句的m个字作为匹配字段,m为词典中最长词的长度;
- 查找词典进行匹配;
- 若匹配成功,则将该字段作为一个词切分出去;
- 若匹配不成功,则将该字段最后一个字去掉,剩下的字作为新匹配字段,进行再次匹配;
- 重复上述过程,直到切分所有词为止。
2.1.2 逆向最大匹配法
逆向最大匹配法(Reverse Maximum Matching, RMM)基本原理与FMM基本相同,不同的是分词的方向与FMM相反。RMM是从待分词句子的末端开始,也就是从右向左开始匹配扫描,每次取末端m个字作为匹配字段,匹配失败,则去掉匹配字段前面的一个字,继续匹配。
2.1.3 双向最大匹配法
双向最大匹配法(Bi-directional Maximum Matching,Bi-MM)是将正向最大匹配法得到的分词结果和逆向最大匹配法得到的结果进行比较,然后按照最大匹配原则,选取词数切分最少的作为结果。双向最大匹配的规则是:
-
如果正反向分词结果词数不同,则取分词数量少的那个;
-
分词结果相同,没有歧义,返回任意一个;分词结果不同,返回其中单字数量较少的那个。
【示例1】正向最大匹配分词法
# 正向最大匹配分词示例
class MM(object):
def __init__(self):
self.window_size = 3
def cut(self, text):
result = [] # 分词结果
start = 0 # 起始位置
text_len = len(text) # 文本长度
dic = ["吉林", "吉林市", "市长", "长春", "春药", "药店"]
while text_len > start:
for size in range(self.window_size + start, start, -1): # 取最大长度,逐步比较减小
piece = text[start:size] # 切片
if piece in dic: # 在字典中
result.append(piece) # 添加到列表
start += len(piece)
break
else: # 没在字典中,什么都不做
if len(piece) == 1:
result.append(piece) # 单个字成词
start += len(piece)
return result
if __name__ == "__main__":
text = "吉林市长春药店"
tk = MM() # 实例化对象
result = tk.cut(text)
print(result)
执行结果:
['吉林市', '长春', '药店']
【示例2】逆向最大匹配分词法
# 逆向最大匹配分词示例
class RMM(object):
def __init__(self):
self.window_size = 3
def cut(self, text):
result = [] # 分词结果
start = len(text) # 起始位置
text_len = len(text) # 文本长度
dic = ["吉林", "吉林市", "市长", "长春", "春药", "药店"]
while start > 0:
for size in range(self.window_size, 0, -1):
piece = text[start-size:start] # 切片
if piece in dic: # 在字典中
result.append(piece) # 添加到列表
start -= len(piece)
break
else: # 没在字典中
if len(piece) == 1:
result.append(piece) # 单个字成词
start -= len(piece)
break
result.reverse()
return result
if __name__ == "__main__":
text = "吉林市长春药店"
tk = RMM() # 实例化对象
result = tk.cut(text)
print(result)
执行结果:
['吉林市', '长春', '药店']
【示例3】Jieba库分词
Jieba是一款开源的、功能丰富、使用简单的中文分词工具库,它提供了三种分词模式:
- 精确模式:试图将句子最精确地分词,适合文本分析
- 全模式:把句子中所有可以成词的词语分割出来,速度快,但有重复词和歧义
- 搜索引擎模式:在精确模式基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词
使用Jieba库之前,需要进行安装:
pip install jieba==0.42.1
分词示例代码如下:
# jieba分词示例
import jieba
text = "吉林市长春药店"
# 全模式
seg_list = jieba.cut(text, cut_all=True)
for word in seg_list:
print(word, end="/")
print()
# 精确模式
seg_list = jieba.cut(text, cut_all=False)
for word in seg_list:
print(word, end="/")
print()
# 搜索引擎模式
seg_list = jieba.cut_for_search(text)
for word in seg_list:
print(word, end="/")
print()
执行结果:
吉林/吉林市/市长/长春/春药/药店/
吉林市/长春/药店/
吉林/吉林市/长春/药店/
【示例4】文本高频词汇提取
# 通过tf-idf提取高频词汇
import glob
import random
import jieba
# 读取文件内容
def get_content(path):
with open(path, "r", encoding="gbk", errors="ignore") as f:
content = ""
for line in f.readlines():
line = line.strip()
content += line
return content
# 统计词频,返回最高前10位词频列表
def get_tf(words, topk=10):
tf_dict = {}
for w in words:
if w not in tf_dict.items():
tf_dict[w] = tf_dict.get(w, 0) + 1 # 获取词频并加1
# 倒序排列
new_list = sorted(tf_dict.items(), key=lambda x: x[1], reverse=True)
return new_list[:topk]
# 去除停用词
def get_stop_words(path):
with open(path, encoding="utf8") as f:
return [line.strip() for line in f.readlines()]
if __name__ == "__main__":
# 样本文件
fname = "d:\\NLP_DATA\\chap_3\\news\\C000008\\11.txt"
# 读取文件内容
corpus = get_content(fname)
# 分词
tmp_list = list(jieba.cut(corpus))
# 去除停用词
stop_words = get_stop_words("d:\\NLP_DATA\\chap_3\\stop_words.utf8")
split_words = []
for tmp in tmp_list:
if tmp not in stop_words:
split_words.append(tmp)
# print("样本:\n", corpus)
print("\n 分词结果: \n" + "/".join(split_words))
# 统计高频词
tf_list = get_tf(split_words)
print("\n top10词 \n:", str(tf_list))
执行结果:
分词结果:
焦点/个股/苏宁/电器/002024/该股/早市/涨停/开盘/其后/获利盘/抛/压下/略有/回落/强大/买盘/推动/下该/股/已经/再次/封于/涨停/主力/资金/积极/拉升/意愿/相当/强烈/盘面/解析/技术/层面/早市/指数/小幅/探低/迅速/回升/中石化/强势/上扬/带动/指数/已经/成功/翻红/多头/实力/之强/令人/瞠目结舌/市场/高度/繁荣/情形/投资者/需谨慎/操作/必竟/持续/上攻/已经/消耗/大量/多头/动能/盘中/热点/来看/相比/周二/略有/退温/依然/看到/目前/热点/效应/外扩散/迹象/相当/明显/高度/活跌/板块/已经/前期/有色金属/金融/地产股/向外/扩大/军工/概念/航天航空/操作/思路/短线/依然/需/规避/一下/技术性/回调/风险/盘中/切记/不可/追高
top10词:
[('已经', 4), ('早市', 2), ('涨停', 2), ('略有', 2), ('相当', 2), ('指数', 2), ('多头', 2), ('高度', 2), ('操作', 2), ('盘中', 2)]
2.2 词性标注
2.2.1 什么是词性标注
词性是词语的基本语法属性,通常也称为词类。词性标注是判定给定文本或语料中每个词语的词性。有很多词语在不同语境中表现为不同的词性,这就为词性标注带来很大的困难。另一方面,从整体上看,大多数词语,尤其是实词,一般只有一到两个词性,其中一个词性的使用频率远远大于另一个。
2.2.2 词性标注的原理
词性标注最主要方法同分词一样,将其作为一个序列生成问题来处理。使用序列模型,根据输入的文本,生成一个对应的词性序列。
2.2.3 词性标注规范
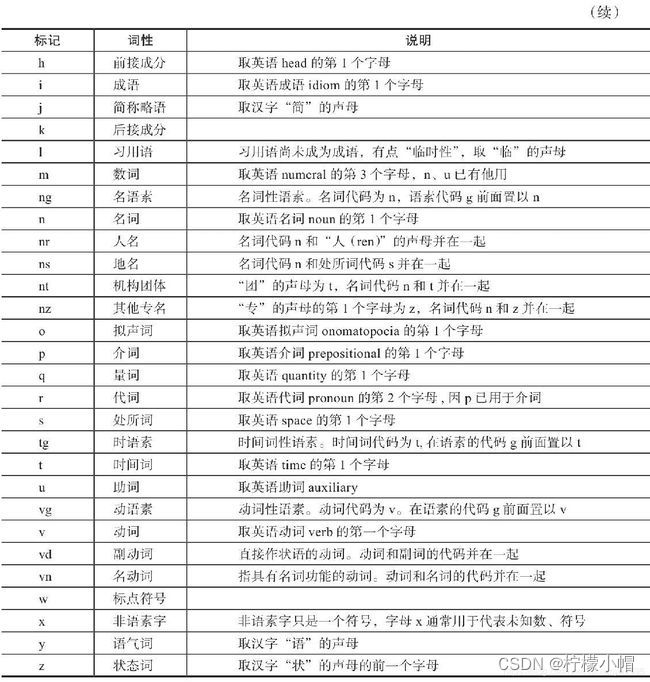
词性标注要有一定的标注规范,如将名词、形容词、动词表示为"n", “adj”, "v"等。中文领域尚无统一的标注标准,较为主流的有北大词性标注集和宾州词性标注集。以下是北大词性标注集部分词性表示:

2.2.4 Jieba库词性标注
Jieba库提供了词性标注功能,采用结合规则和统计的方式,具体为在词性标注的过程中,词典匹配和HMM共同作用。词性标注流程如下:
第一步:根据正则表达式判断文本是否为汉字;
第二步:如果判断为汉字,构建HMM模型计算最大概率,在词典中查找分出的词性,若在词典中未找到,则标记为"未知";
第三步:若不如何上面的正则表达式,则继续通过正则表达式进行判断,分别赋予"未知"、”数词“或"英文"。
【示例】Jieba库实现词性标注
import jieba.posseg as psg
def pos(text):
results = psg.cut(text)
for w, t in results:
print("%s/%s" % (w, t), end=" ")
print("")
text = "呼伦贝尔大草原"
pos(text)
text = "梅兰芳大剧院里星期六晚上有演出"
pos(text)
执行结果:
呼伦贝尔/nr 大/a 草原/n
梅兰芳/nr 大/a 剧院/n 里/f 星期六/t 晚上/t 有/v 演出/v
2.3 命名实体识别(NER)
命名实体识别(Named Entities Recognition,NER)也是自然语言处理的一个基础任务,是信息抽取、信息检索、机器翻译、问答系统等多种自然语言处理技术必不可少的组成部分。其目的是识别语料中人名、地名、组织机构名等命名实体,实体类型包括3大类(实体类、时间类和数字类)和7小类(人名、地名、组织机构名、时间、日期、货币和百分比)。中文命名实体识别主要有以下难点:
(1)各类命名实体的数量众多。
(2)命名实体的构成规律复杂。
(2)嵌套情况复杂。
(4)长度不确定。
命名实体识别方法有:
(1)基于规则的命名实体识别。规则加词典是早期命名实体识别中最行之有效的方式。其依赖手工规则的系统,结合命名实体库,对每条规则进行权重赋值,然后通过实体与规则的相符情况来进行类型判断。这种方式可移植性差、更新维护困难等问题。
(2)基于统计的命名实体识别。基于统计的命名实体识别方法有:隐马尔可夫模型、最大熵模型、条件随机场等。其主要思想是基于人工标注的语料,将命名实体识别任务作为序列标注问题来解决。基于统计的方法对语料库的依赖比较大,而可以用来建设和评估命名实体识别系统的大规模通用语料库又比较少,这是该方法的一大制约。
(3)基于深度学习的方法。利用深度学习模型,预测词(或字)是否为命名实体,并预测出起始、结束位置。
(4)混合方法。将前面介绍的方法混合使用。












![[C][数据结构][时间空间复杂度]详细讲解](https://img-blog.csdnimg.cn/direct/2d72f83e4dc04d13a3136216e76c4cf3.png)