大语言模型RAG-将本地大模型封装为langchain的chat model(三)
往期文章:
大语言模型RAG-技术概览 (一)
大语言模型RAG-langchain models (二)
上一期langchain还在0.1时代,这期使用的langchain v0.2已经与之前不兼容了。
本期介绍如何将开源模型封装为langchain的chat模型。 这是后面构建RAG应用的基础。
基于langchain_core.language_models.BaseChatModel创建类。这个类就是本地llm的langchain封装,需要定义以下方法或属性。
| 方法/属性 | 作用 | 是否必要 |
|---|---|---|
_generate | 根据prompt生成聊天结果 | 必要 |
_llm_type (属性) | 模型的唯一标识,用于生成日志 | 必要 |
_identifying_params(属性) | 用于返回模型的一些参数,用于日志和调试 | 可选 |
_stream | 用于流式输出 | 可选 |
_agenerate | 本机异步的_generate | 可选 |
_astream | 异步的_stream | 可选 |
示例如下,只实现比较常用的功能:
from typing import Any, AsyncIterator, Dict, Iterator, List, Optional
from threading import Thread
from langchain_core.callbacks import (
AsyncCallbackManagerForLLMRun,
CallbackManagerForLLMRun,
)
from langchain_core.language_models import BaseChatModel, SimpleChatModel
from langchain_core.messages import AIMessageChunk, BaseMessage, HumanMessage
from langchain_core.outputs import (
ChatGeneration,
ChatGenerationChunk,
ChatResult
)
from langchain_core.messages import (
AIMessage,
BaseMessage,
HumanMessage,
)
from typing import AsyncIterator, Literal, Iterator, Optional, List, Dict, Any
from transformers import AutoTokenizer, AutoModelForCausalLM
from pydantic import BaseModel, Field, validator
import torch
class CustomChatModel(BaseChatModel):
"""将本地模型封装为langchain的chat模型"""
model_name: str # 模型的本地地址
device: str = "cpu" # 计算设备
n: int = 512 # 最大生成长度
temperature: float = 1.0 # 温度
model: Optional[AutoModelForCausalLM] = None
tokenizer: Optional[AutoTokenizer] = None
def __init__(self, model_name: str, device: str, temperature: float = 1.0, **kwargs):
"""
我把模型加载放在初始化里面了。当然有更灵活的处理方式,这部分你可以随心所欲,只要在
模型获得输入前加载好模型就OK。
Params:
model_name (str): 本地模型的路径
device (str): 计算设备
temperature (float): 模型温度
"""
super().__init__(model_name=model_name, device=device, **kwargs)
self.model_name = model_name
self.device = device
self.temperature = temperature
# 加载本地模型。
try:
self.tokenizer = AutoTokenizer.from_pretrained(self.model_name, trust_remote_code=True, use_fast=False)
self.model = AutoModelForCausalLM.from_pretrained(self.model_name, trust_remote_code=True).half().to(self.device)
except Exception as e:
raise RuntimeError(f"模型或分词器加载失败: {e}")
def _generate(self, messages: List[BaseMessage], stop: Optional[List[str]] = ['.', '。', '?', '?', '!', '!'],
run_manager: Optional[CallbackManagerForLLMRun] = None, **kwargs: Any) -> ChatResult:
"""
实现模型的文本生成逻辑
这是langchain必须的类方法。
Params:
messages (BaseMessage): 输入模型的消息列表
stop (List[str]):
这是一个字符列表,langchain会根据这个列表中的字符找到
完整句子的结束位置。
run_manager (CallbackManagerForLLMRun):
用于管理和追踪执行的过程,通常用于实现回调和异步处理。
虽然这个功能很重要,但本文暂时不做示例(我没玩明白)
Return:ChatResult类的输出,完全符合langchain风格。
"""
last_message = messages[-1].content # 获取最后一条消息
inputs = self.tokenizer.encode(last_message, return_tensors="pt").to(self.device) # 将消息内容编码为张量
outputs = self.model.generate(inputs, max_length=self.n + len(inputs[0]), temperature=self.temperature) # 调用模型生成文本张量
tokens = self.tokenizer.decode(outputs[0], skip_special_tokens=True) # 将张量解码为文本
# 截取合适的长度(找到完整句子的结束位置)
end_positions = [tokens.find(c) for c in stop if tokens.find(c) != -1]
if end_positions:
end_pos = max(end_positions) + 1 # 包括结束符
if end_pos < self.n:
tokens = tokens[:end_pos]
else:
tokens = tokens[:self.n]
else:
tokens = tokens[:self.n]
message = AIMessage(content=tokens) # 将生成的文本封装为消息
generation = ChatGeneration(message=message) # 封装为ChatGeneration
return ChatResult(generations=[generation])
def _stream(self, messages: List[BaseMessage], stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None, **kwargs: Any) -> Iterator[ChatGenerationChunk]:
"""
流式生成文本。这个方法不是必须的,但实际应用中流式输出能提高用户
体验,从这个角度来说它是必须的。下面仅给出了最基本的流式输出的逻
辑,实际工程中你可以自行添加你需要的逻辑。
Params:
messages (BaseMessage): 输入模型的消息列表
stop (List[str]):
这是一个字符列表,langchain会根据这个列表中的字符找到
完整句子的结束位置。
run_manager (CallbackManagerForLLMRun):
用于管理和追踪执行的过程,通常用于实现回调和异步处理。
Return:ChatGenerationChunk类的输出,完全符合langchain风格。
"""
last_message = messages[-1].content
inputs = self.tokenizer(last_message, return_tensors="pt").to(self.device)
streamer = TextIteratorStreamer(tokenizer=self.tokenizer) # transformers提供的标准接口,专为流式输出而生
inputs.update({"streamer": streamer, "max_new_tokens": 512}) # 这是model.generate的参数,可以自由发挥
thread = Thread(target=self.model.generate, kwargs=inputs) # TextIteratorStreamer需要配合线程使用
thread.start()
for new_token in streamer:
# 用迭代器的返回形式 。
yield ChatGenerationChunk(message=AIMessage(content=new_token))
@property
def _llm_type(self) -> str:
"""返回自定义模型的标记"""
return "Custom"
@property
def _identifying_params(self) -> Dict[str, Any]:
"""返回自定义的debug信息"""
return {"model_path": self.model_name, "device": self.device}
本文使用chatglm3-6b模型为例,演示最基础使用方法。
import CustomChatModel
import os
from langchain_core.messages import HumanMessage
# 模型实例化
model = LoadChatLLM(model_name="THUDM/chatglm-6b",
device=“cuda”,
temperature=float(1.0))
def stream_generate_text(text):
"""
流式输出的方式打印到终端。
原理就是每生成一个新token,就清空屏幕,然后把原先生成过的所有tokens
都打印一次。
"""
generated_text = ''
count = 0
message = [HumanMessage(content=text)]
for new_text in model._stream(message):
generated_text += new_text.text
count += 1
if count % 8 == 0: # 避免刷新太频繁,每8个tokens刷新一次
os.system("clear")
print(generated_text)
os.system("clear")
print(generated_text)
while True:
ipt = input("请输入:")
stream_generate_text(ipt)
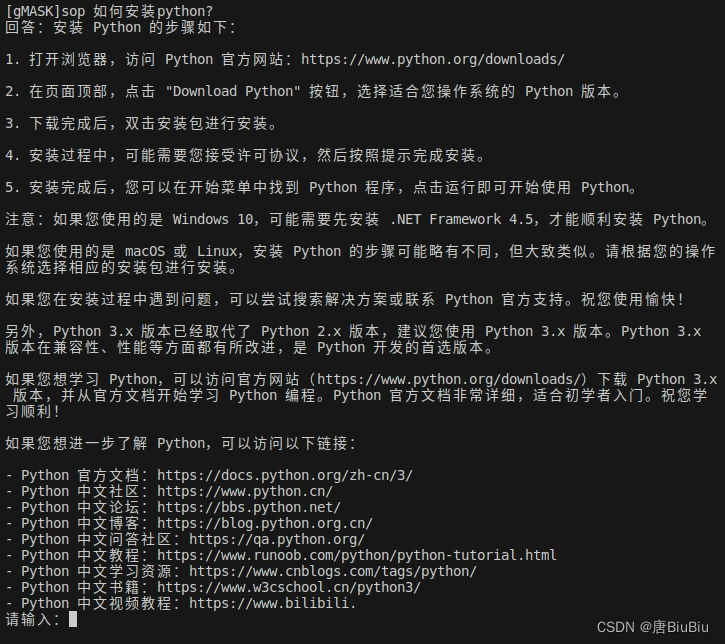
实际效果:
我问它:如何安装Python?

它的输出: