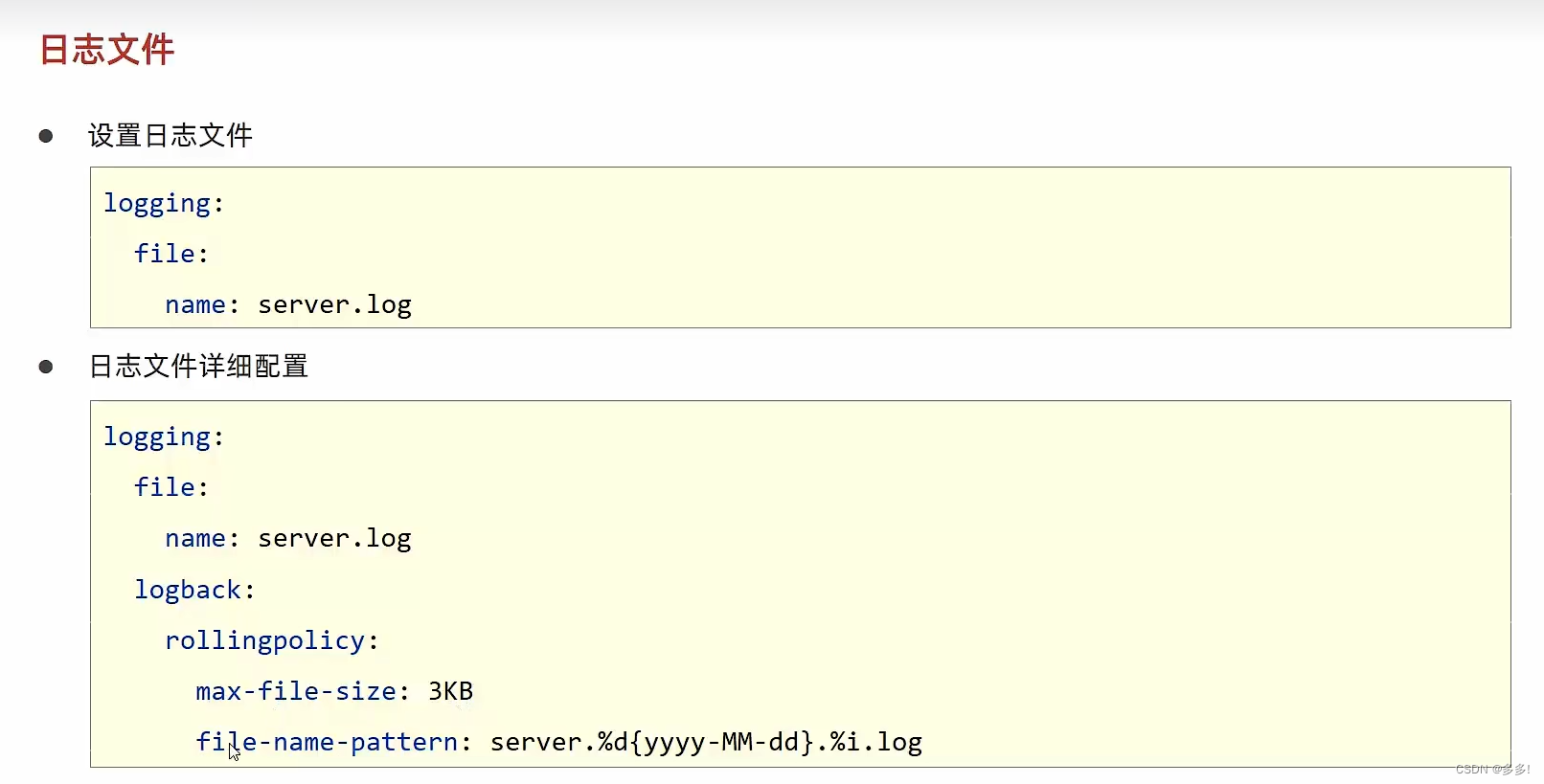
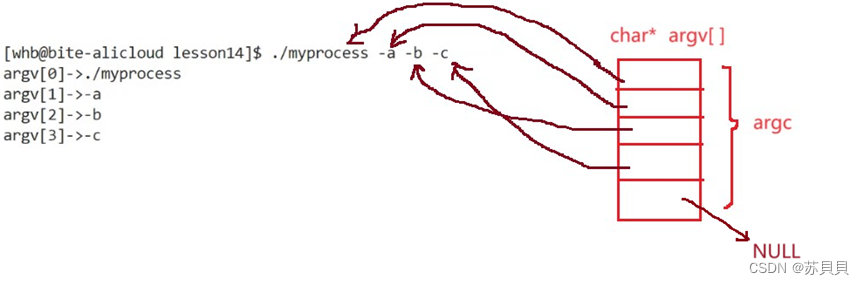
一、导入依赖库
pip install opencv-python
pip install numpy
pip install tensorflow二、分类识别实现
import os
import cv2
import numpy as np
from tensorflow import keras
# 加载模型
model_name = "dog_cat.keras"
model = keras.models.load_model(model_name)
# 预测文件夹路径
folder_path = "imgs"
# 获取文件夹中的图像文件列表
image_files = [
os.path.join(folder_path, file)
for file in os.listdir(folder_path)
if file.endswith(".jpg")
]
# 模型类别
class_names = [
"cat",
"dog"
]
# 预测每张图像
for image_file in image_files:
# 读取图像
image = cv2.imread(image_file)
image_size = (128, 128)
image = cv2.resize(image, image_size)
image = image.astype("float32") / 255.0
image = np.expand_dims(image, axis=0)
# 进行预测
predictions = model.predict(image)
predicted_class_index = np.argmax(predictions[0])
predicted_class_name = class_names[predicted_class_index]
print("Image:", image_file, "Predicted class:", predicted_class_name)
# print("Predicted class:", predicted_class_name)
# print()三、分类识别结果
原图:

模型识别结果:
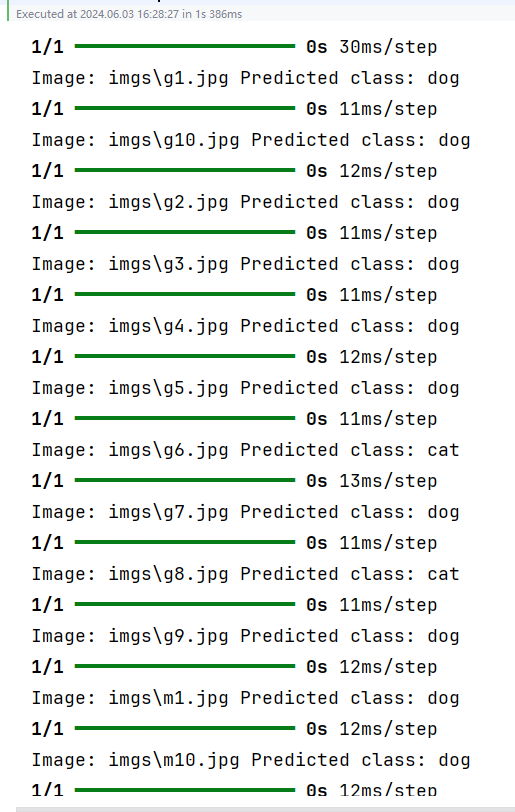
结论:模型严重过拟合。
原因:分类数据样本量太小。
解决方法:增大样本量、模型调优。
四、注意事项
要成功运行这个程序,你需要注意以下几个关键事项:
-
确保所需库已安装:
程序使用了os,cv2(OpenCV),numpy, 和tensorflow库。在运行程序之前,请确保这些库已经通过pip或其他方式安装在你的Python环境中。 -
模型文件的位置和格式:
确保dog_cat.keras模型文件存在,并且与你的程序在同一个目录下,或者更新model_name变量以包含模型文件的完整路径。同时,确认模型文件没有损坏,并且是与你当前TensorFlow版本兼容的Keras模型。 -
图像文件夹和文件格式:
确认imgs文件夹存在,并且包含.jpg格式的图像文件。如果图像文件不是.jpg格式,你需要修改image_files列表的生成逻辑来包含你实际的图像文件格式。 -
图像预处理:
程序中将图像大小调整为128x128,并归一化到[0,1]范围。确保这种预处理方式与你的模型训练时的预处理一致。 -
类别名称与模型输出匹配:
class_names列表中的类别名称应该与模型训练时的类别顺序相匹配。如果模型是用不同的类别顺序训练的,你需要更新class_names以反映正确的顺序。 -
模型输入输出尺寸:
确保你的模型接受的输入尺寸是128x128,因为这是程序中设定的图像大小。如果模型训练时使用了不同的输入尺寸,你需要在程序中做相应的调整。 -
Python和库的版本兼容性:
确认你的Python环境和所有库的版本是相互兼容的。特别是TensorFlow的版本,因为不同版本的TensorFlow可能在模型加载和行为上有细微差别。 -
依赖库的运行时环境:
如果你在某些特定的环境(如Docker容器、虚拟环境或不同操作系统)中运行程序,请确保所有依赖库都已正确安装在这些环境中。 -
错误处理:
考虑添加错误处理逻辑来处理文件不存在、模型加载失败、图像读取错误等潜在问题。 -
资源限制:
如果你的模型很大或图像数量很多,确保你的系统有足够的内存和计算能力来处理这些任务。