一. 前言
哈喽大伙们好,好久不见距离上次更新博客已经有一年之久了,这将近一年的时间小编主要的时间都花在了实习和24届校招上面了,最终也是收获满满,选择了一个还不错的offer,感谢一路走来的自己和身边朋友的帮助,在实习期间我也是学习了一套比较适合新手学习的接口子自动化框架,前提是有Python基础,这样理解起来就很简单了,并且这套框架也是在企业中真正的完成了落地,技术栈主要是Python + Pytest + Requests + Allure,往下看吧;
二. 项目框架
1. 项目目录
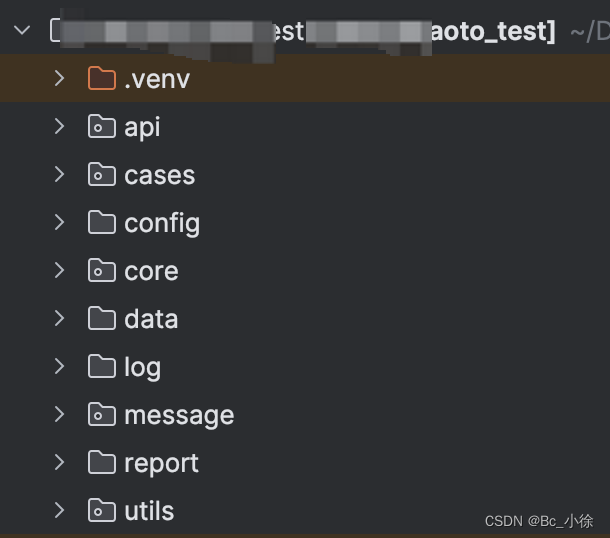
(1) api
顾名思义,api这个文件夹底下就是存放你要自动化的接口;
拿最简单的登录接口为代码示例:
def login(email, pwd): """ 用户登录 :param email: :param pwd: :return: """ json_data = { "email": str(email), "pwd": str(pwd) } # 这里对请求和返回做了二次封装 response = api_util.user_login(json=json_data) return process_response(response)
(2) cases
这个文件夹主要存放测试用例
登录接口代码示例:
@allure.title("用户登录") @pytest.mark.parametrize("email,pwd",base_data.read_data()['test_login']) @pytest.mark.run(order=1) def test_login(self,email,pwd): try: result = login(email,pwd) assert result.success is True print(result) # 断言返回的code是否是200 assert result.body['code'] == 200 except Exception as e: print("异常了",e)
(3) config
这个文件夹主要存放一些配置信息的,比如某些自动化场景我们涉及到查数据库,这里可以存放数据库的配置信息,一般在这个文件下创建一个ini文件,示例:
[host] url = https://www.baidu.com [mysql] MYSQL_HOST=x.x.x.x:x MYSQL_PORT=xxxx MYSQL_USER=xxxx MYSQL_PASSWD=xxxx MYSQL_DB=xxxx
(4) core
这个文件夹下主要是针对接口返回的信息做二次封装,代码示例:
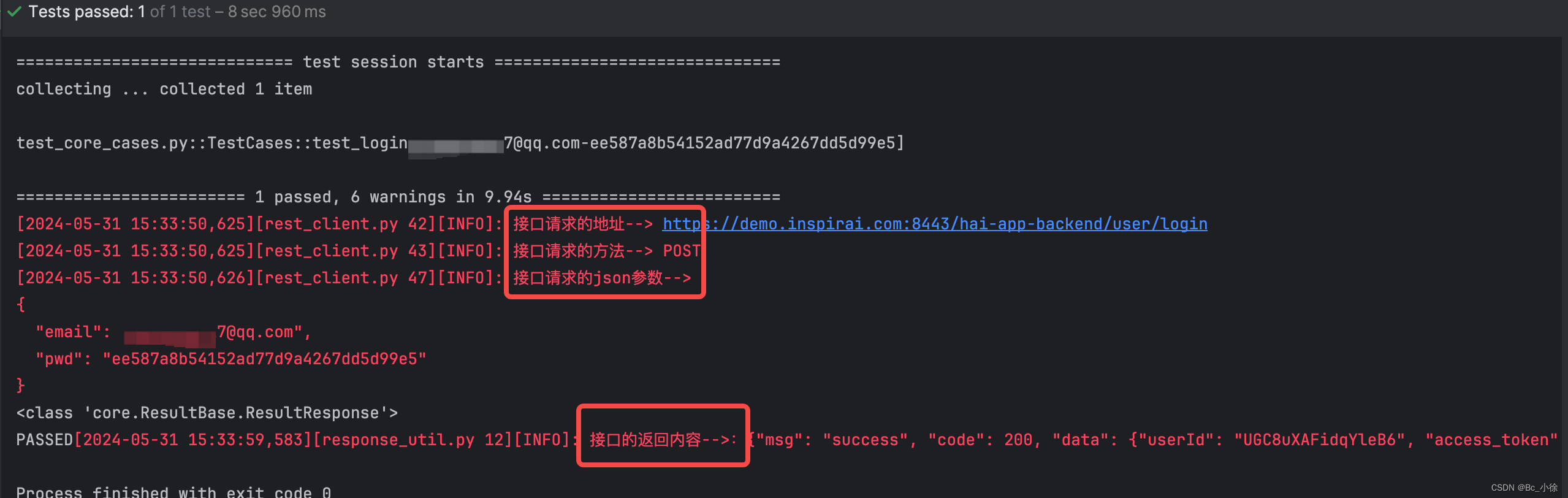
class RestClient: def __init__(self): self.api_root_url = api_root_url self.session = requests.Session() def get(self, url, **kwargs): return self.request(url, "GET", **kwargs) def post(self, url, **kwargs): return self.request(url, "POST", **kwargs) def put(self, url, **kwargs): return self.request(url, "PUT", **kwargs) def delete(self, url, **kwargs): return self.request(url, "DELETE", **kwargs) def request(self, url, method, **kwargs): self.request_log(url, method, **kwargs) if method == "GET": return self.session.get(self.api_root_url + url, **kwargs) if method == "POST": return self.session.post(self.api_root_url + url, **kwargs) if method == "PUT": return self.session.put(self.api_root_url + url, **kwargs) if method == "DELETE": return self.session.delete(self.api_root_url + url, **kwargs) def request_log(self, url, method, **kwargs): data = dict(**kwargs).get("data") json_data = dict(**kwargs).get("json") params = dict(**kwargs).get("params") headers = dict(**kwargs).get("headers") logger.info("接口请求的地址--> {}".format(self.api_root_url + url)) logger.info("接口请求的方法--> {}".format(method)) if data is not None: logger.info("接口请求的data参数-->\n{}".format(json.dumps(data, ensure_ascii=False, indent=2))) if json_data is not None: logger.info("接口请求的json参数-->\n{}".format(json.dumps(json_data, ensure_ascii=False, indent=2))) if params is not None: logger.info("接口请求的params参数-->\n{}".format(json.dumps(params, ensure_ascii=False, indent=2))) if headers is not None: logger.info("接口请求的headers参数-->\n{}".format(json.dumps(headers, ensure_ascii=False, indent=2)))通过二次封装打印在控制台,我们可以很清楚的看到接近请求的地址,方法,参数和返回的body,如图:
(5) data
这个文件下主要存放用户的一些请求参数,比如登录接口所需要的用户名和密码,可以创建一个yaml文件来存放,并且配合Pytest里面的@pytest.mark.parametrize注解去解析yaml文件的数据(此方法一般用于频繁使用参数的时候,好处就是不需要在每个函数下去写请求参数,每次调用只要通过注解去拿数据就好了,视具体业务场景去使用)代码示例:
test_login: - [ 2xxxxxxxxxxx@qq.com,ee587a8b54152ad77d9a4267dd5d99e5 ]@allure.title("用户登录") # 读取yaml里面的数据 @pytest.mark.parametrize("email,pwd",base_data.read_data()['test_login']) @pytest.mark.run(order=1) def test_login(self,email,pwd): try: result = login(email,pwd) assert result.success is True print(result) # 断言返回的code是否是200 assert result.body['code'] == 200 except Exception as e: print("异常了",e)
(6) log
这个文件下就是存放每次运行完之后的日志信息,自动生成的文件;
(7) message // TODO
项目和Jenkins结合实现CI/CD,这个文件夹下主要存放通知工作群的代码,比如你可以编写与飞书,钉钉或者企微,通过webhook去连接,将每次自动化的结果定时下发到工作群,后续更新;
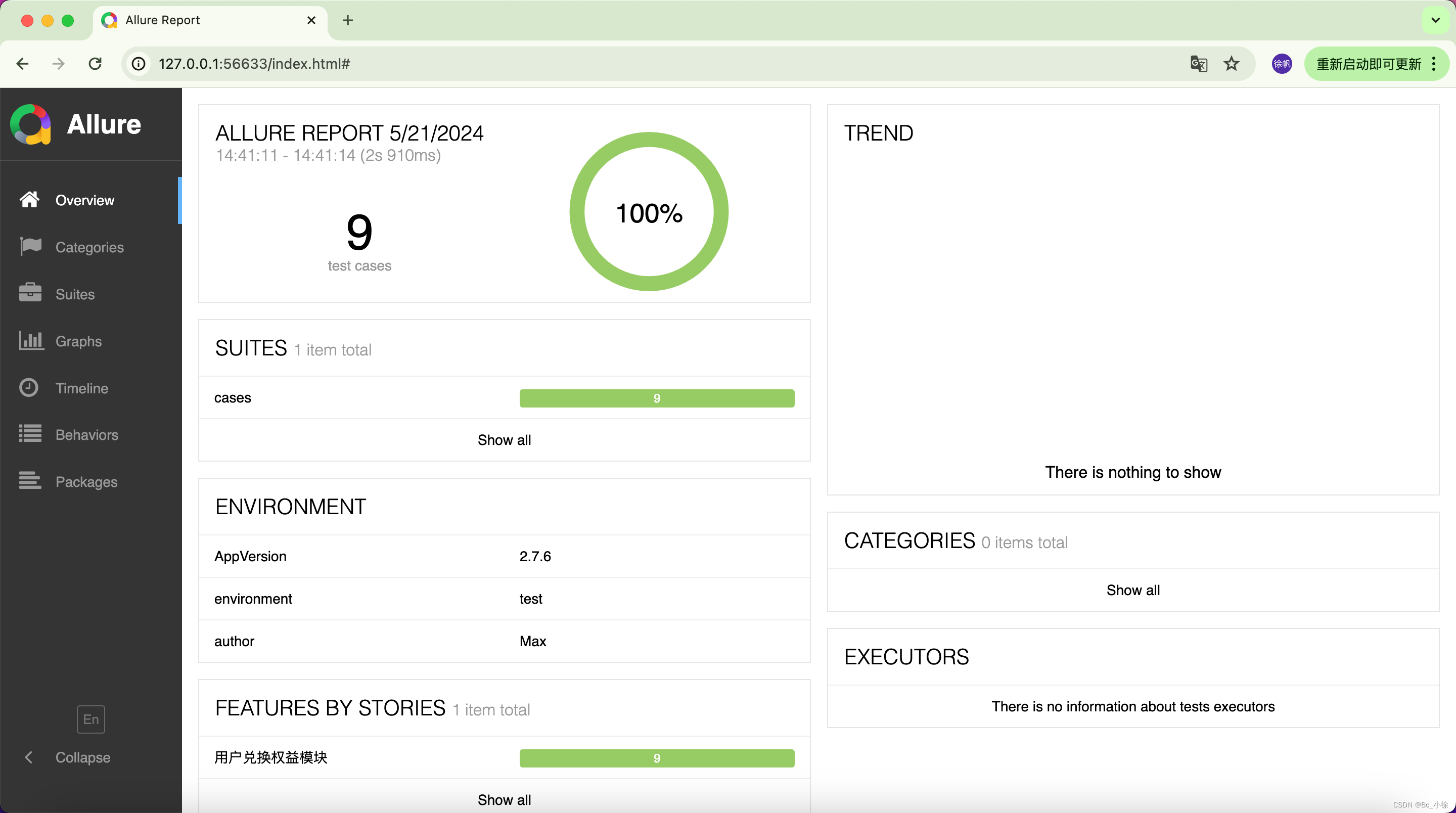
(8) report
项目结合Allure生成测试报告,这个文件夹是存放每次输出的测试报告,也是自动生成的文件,截图如下:
(9) utils
这个文件夹写的东西就非常多了,凡是在做自动化的时候需要用到的一些工具,都可以放到这个文件夹下,比如数据库连接,动态获取token,接口返回数据的异常打印,日志打印等等;示例代码:数据库连接和打印日志统一处理:
# 数据库连接 import logging import pymysql from utils.log_util import logger from utils.read_data import base_data data = base_data.read_ini()['mysql'] DB_CONF = { "host": data['MYSQL_HOST'], "port": int(data['MYSQL_PORT']), "user": data['MYSQL_USER'], "password": data['MYSQL_PASSWD'], "db": data['MYSQL_DB'] } class Mysql: def __init__(self): # 建立 mysql 连接 self.conn = pymysql.connect(**DB_CONF, autocommit=True) self.cur = self.conn.cursor(cursor=pymysql.cursors.DictCursor) # 释放资源 def __del__(self): self.cur.close() self.conn.close() # 查询一条 def select_db_one(self, sql): # 获取数据 logger.info(f'执行sql:{sql}') self.cur.execute(sql) result = self.cur.fetchone() logger.info(f'sql执行结果:{result}') return result # 查询多条 def select_db_all(self, sql): # 获取数据 logger.info(f'执行sql:{sql}') self.cur.execute(sql) result = self.cur.fetchall() logger.info(f'执行结果:{result}') return result def execute_db(self, sql): # sql 可能会报错,try一下 try: logger.info(f'执行sql:{sql}') self.cur.execute(sql) self.conn.commit() except Exception as e: logging.info("sql执行出错{}".format(e)) db = Mysql() if __name__ == '__main__': db = Mysql() # result = db.select_db_one( # "select code from users_verifycode where mobile = 'xxxxxxx' order by id desc limit 1;") # print(result['code'])# 日志打印统一处理 import os import logging import time # 找到根目录 root_path = os.path.dirname(os.path.dirname(os.path.realpath(__file__))) # print(root_path) # 和log文件夹进行关联 log_path = os.path.join(root_path, 'log') # print(log_path) class Logger: def __init__(self): #定义日志位置和文件名 self.logname = os.path.join(log_path,"{}.log".format(time.strftime("%Y-%m-%d"))) #定义一个日志容器 self.logger = logging.getLogger("log") #设置日志打印的级别 self.logger.setLevel(logging.DEBUG) #创建日志输入的格式 self.formatter = logging.Formatter('[%(asctime)s][%(filename)s %(lineno)d][%(levelname)s]: %(message)s') #创建日志处理器,用来存放日志文件 self.filelogger = logging.FileHandler(self.logname, mode='a', encoding="UTF-8") #创建日志处理器,在控制台打印 self.console = logging.StreamHandler() #设置控制台打印日志界别 self.console.setLevel(logging.DEBUG) #文件存放日志级别 self.filelogger.setLevel(logging.DEBUG) #文件存放日志格式 self.filelogger.setFormatter(self.formatter) #控制台打印日志格式 self.console.setFormatter(self.formatter) #将日志输出渠道添加到日志收集器中 self.logger.addHandler(self.filelogger) self.logger.addHandler(self.console) logger = Logger().logger if __name__ == '__main__': logger.info("--测试开始--") logger.debug("--测试结束--")
三. 总结
整体下来这个框架通俗易懂,其实真正在做自动化的时候我们只需要对用例的脚本进行编写就行了,我会附上自己的代码仓库地址,大伙可以拉下来看看,自己尝试实践一下,遇到啥问题可以私信我看到随时解答,关于第二篇就是主要去说下如何通过Git+Linux+Jenkins去部署项目,从而达到一个CI/CD的流水线工作流程,本文欢迎技术大佬指点相互学习,期待下次相遇~
项目地址:pytest: 从0到1搭建接口自动化框架