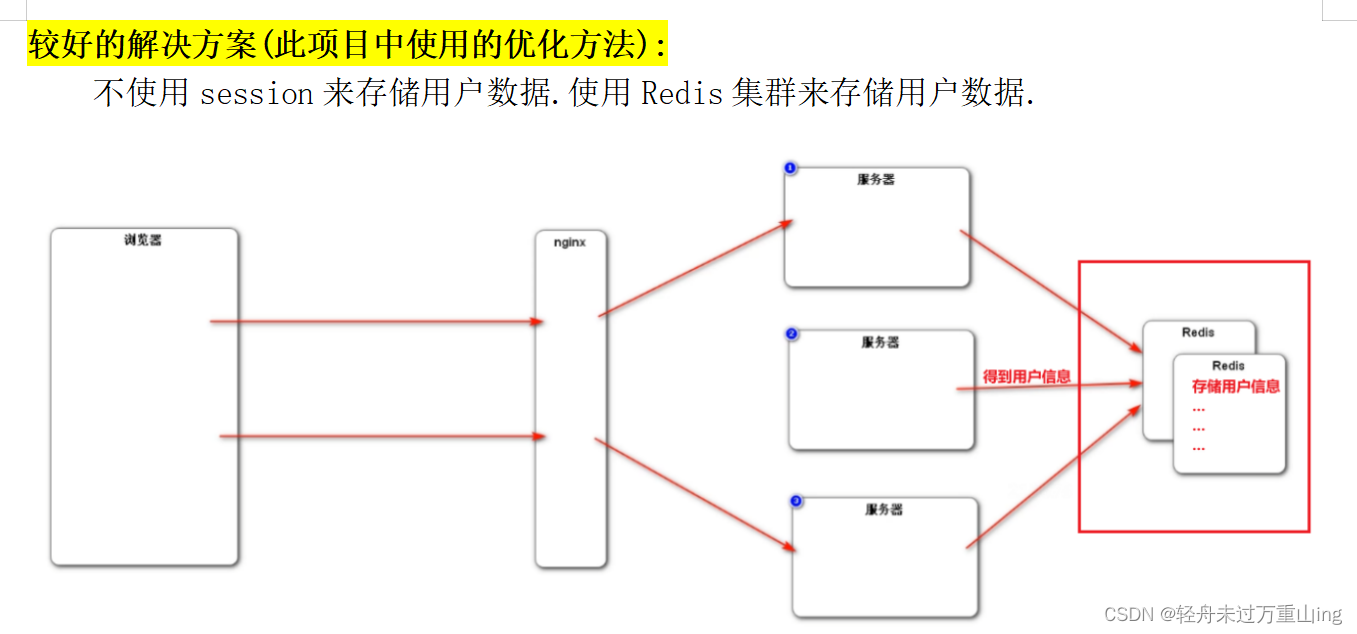
系列篇章💥
AI大模型探索之路-实战篇4:深入DB-GPT数据应用开发框架调研
AI大模型探索之路-实战篇5:探索Open Interpreter开放代码解释器调研
AI大模型探索之路-实战篇6:掌握Function Calling的详细流程
AI大模型探索之路-实战篇7:Function Calling技术实战自动生成函数
AI大模型探索之路-实战篇8:多轮对话与Function Calling技术应用
AI大模型探索之路-实战篇9:探究Agent智能数据分析平台的架构与功能
目录
- 系列篇章💥
- 前言
- 一、安装MySQL数据库
- 二、数据集获取
- 三、数据处理
- 1、拆分数据集
- 2、噪声数据填充
- 四、生成文件
- 五、业务数据入库
- 1、建表
- 2、加载业务数据
- 结语
前言
在当今数据驱动的商业环境中,一个高效且智能的数据分析平台对于企业的成功至关重要。本系列文章已经介绍了Agent智能数据分析平台的基础架构和核心功能,本文将深入探讨平台的数据预处理步骤,这一步骤是实现高质量数据分析的关键。我们将重点讨论如何获取、处理并存储数据,以提升分析的效率和准确性。
一、安装MySQL数据库
步骤1:安装MySQL数据库
sudo apt-get update
sudo apt-get install mysql-server
sudo service mysql start
步骤2:创建数据库用户
CREATE USER 'iquery_agent'@'localhost' IDENTIFIED BY 'iquery_agent';
步骤3:给数据库用户赋权限
GRANT ALL PRIVILEGES ON *.* TO 'iquery_agent'@'localhost';
FLUSH PRIVILEGES;
二、数据集获取
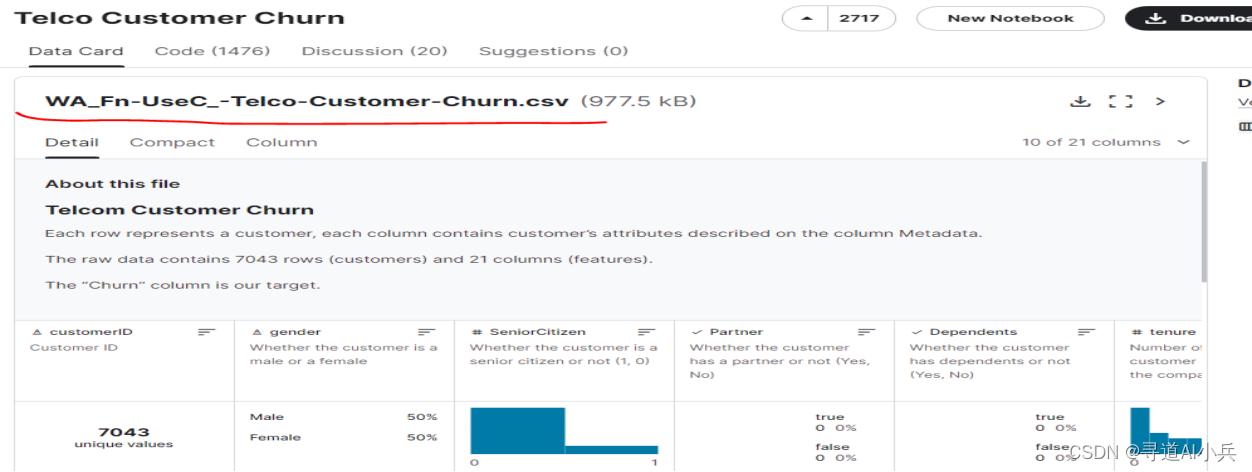
在构建智能数据分析平台的过程中,获取并预处理高质量的数据集是确保后续分析有效性的关键步骤。为此,我们从Kaggle上选取了IBM提供的一个涉及客户流失率和服务信息的公开数据集,这份数据集不仅规模庞大,而且包含了丰富的客户行为数据和服务使用情况。
地址:https://www.kaggle.com/datasets/blastchar/telco-customer-churn
三、数据处理
1、拆分数据集
数据处理阶段是构建智能数据分析平台中至关重要的一环,它直接影响到最终分析结果的准确性和可靠性。在这一阶段,我们主要关注两个核心操作:拆分数据集和噪声数据填充。
1)查看数据集信息
import pandas as pd
#加载数据集
dataset = pd.read_csv('源数据/WA_Fn-UseC_-Telco-Customer-Churn.csv')
pd.set_option('max_colwidth',200)
#查看前5条数据
dataset.head(5)
输出:
2)查看数据集字段信息
dataset.info()
输出:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7043 entries, 0 to 7042
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 customerID 7043 non-null object
1 gender 7043 non-null object
2 SeniorCitizen 7043 non-null int64
3 Partner 7043 non-null object
4 Dependents 7043 non-null object
5 tenure 7043 non-null int64
6 PhoneService 7043 non-null object
7 MultipleLines 7043 non-null object
8 InternetService 7043 non-null object
9 OnlineSecurity 7043 non-null object
10 OnlineBackup 7043 non-null object
11 DeviceProtection 7043 non-null object
12 TechSupport 7043 non-null object
13 StreamingTV 7043 non-null object
14 StreamingMovies 7043 non-null object
15 Contract 7043 non-null object
16 PaperlessBilling 7043 non-null object
17 PaymentMethod 7043 non-null object
18 MonthlyCharges 7043 non-null float64
19 TotalCharges 7043 non-null object
20 Churn 7043 non-null object
dtypes: float64(1), int64(2), object(18)
memory usage: 1.1+ MB
3)数据集拆分
将数据集拆分为训练集数据和测试集数据,以备后面做数据分析有用
## 分离训练集数据和测试集数据,以备后面做数据分析有用
from sklearn.model_selection import train_test_split
train_data, test_data = train_test_split(dataset, test_size=0.20, random_state=42)
train_data = train_data.reset_index(drop=True)
test_data = test_data.reset_index(drop=True)
4)查看训练数据集
train_data.head()
输出:
5)查看测试数据集
test_data.head()
6)训练数据提取拆分
# 1. User Demographics(用户特征)
user_demographics_train = train_data[['customerID', 'gender', 'SeniorCitizen', 'Partner', 'Dependents']]
# 2. User Services(用户服务)
user_services_train = train_data[['customerID', 'PhoneService', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport',
'StreamingTV', 'StreamingMovies']]
# 3. User Payments(用户支付记录)
user_payments_train = train_data[['customerID', 'Contract', 'PaperlessBilling', 'PaymentMethod', 'MonthlyCharges', 'TotalCharges']]
# 4. User Churn(用户流失)
user_churn_train = train_data[['customerID', 'Churn']]
7)测试数据集提前拆分
# 1. User Demographics
user_demographics_test = test_data[['customerID', 'gender', 'SeniorCitizen', 'Partner', 'Dependents']]
# 2. User Services
user_services_test = test_data[['customerID', 'PhoneService', 'MultipleLines', 'InternetService',
'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport',
'StreamingTV', 'StreamingMovies']]
# 3. User Payments
user_payments_test = test_data[['customerID', 'Contract', 'PaperlessBilling', 'PaymentMethod', 'MonthlyCharges', 'TotalCharges']]
# 4. User Churn
user_churn_test = test_data[['customerID', 'Churn']]
8)数据检查
user_demographics_train.head()
2、噪声数据填充
在现实中,获取的数据往往包含一定程度的噪声,这些噪声可能由于数据采集、记录过程中的错误或遗漏造成。为了确保分析结果的准确性,我们需要对这些噪声数据进行处理。处理的方式可以多样,包括但不限于填充缺失值、平滑异常值或者基于算法预测合理的数据点。在这一环节中,我们模拟了一些噪声数据的生成,并展示了如何通过技术手段处理这些数据,从而提升数据的整体质量。
处理步骤如下:
- 在 user_demographics 表中随机删除一些行,总共删除5%条数据;
- 在 user_services 表中添加一些不在其他表中的客户ID,总共添加100个新用户ID;
- 在 user_payments 表中随机添加一些缺失值,总共删除100个值;
- 为 user_churn 表添加一些新的客户ID,总共添加50个新用户,其中25个记录为流失用户,25个记录为未流失用户。
import numpy as np
# Random seed for reproducibility
np.random.seed(42)
# 1. Remove some rows from user_demographics
drop_indices = np.random.choice(user_demographics_train.index, size=int(0.05 * len(user_demographics_train)), replace=False)
user_demographics_train = user_demographics_train.drop(drop_indices)
# 2. Add some new customer IDs to user_services
new_ids = ["NEW" + str(i) for i in range(100)]
new_data_train = pd.DataFrame({'customerID': new_ids})
user_services_train = pd.concat([user_services_train, new_data_train], ignore_index=True)
# 3. Add missing values to user_payments
for _ in range(100):
row_idx = np.random.randint(user_payments_train.shape[0])
col_idx = np.random.randint(1, user_payments_train.shape[1]) # skipping customerID column
user_payments_train.iat[row_idx, col_idx] = np.nan
# 4. Add new customer IDs to user_churn
new_ids_churn_train = ["NEWCHURN" + str(i) for i in range(50)]
new_data_churn_train = pd.DataFrame({'customerID': new_ids_churn_train, 'Churn': ['Yes'] * 25 + ['No'] * 25})
user_churn_train = pd.concat([user_churn_train, new_data_churn_train], ignore_index=True)
数据查看
user_demographics_train
获取DataFrame的维度信息,返回一个元组,第一个元素表示行数,第二个元素表示列数
user_demographics_train.shape, user_services_train.shape, user_payments_train.shape, user_churn_train.shape

四、生成文件
经过预处理的数据需要被有效地存储和管理。为了实现这一点,我们使用Python来编写脚本,自动化地将清洗后的数据保存到CSV文件中。
import os
# 创建目标文件夹,如果它还不存在
if not os.path.exists('业务数据'):
os.makedirs('业务数据')
# 保存 DataFrame 为 CSV 文件
user_demographics_train.to_csv('业务数据/user_demographics_train.csv', index=False)
user_services_train.to_csv('业务数据/user_services_train.csv', index=False)
user_payments_train.to_csv('业务数据/user_payments_train.csv', index=False)
user_churn_train.to_csv('业务数据/user_churn_train.csv', index=False)
user_demographics_test.to_csv('业务数据/user_demographics_test.csv', index=False)
user_services_test.to_csv('业务数据/user_services_test.csv', index=False)
user_payments_test.to_csv('业务数据/user_payments_test.csv', index=False)
user_churn_test.to_csv('业务数据/user_churn_test.csv', index=False)
五、业务数据入库
1、建表
create database iquery;
CREATE TABLE user_demographics (
customerID VARCHAR(255) PRIMARY KEY,
gender VARCHAR(255),
SeniorCitizen INT,
Partner VARCHAR(255),
Dependents VARCHAR(255)
);
CREATE TABLE user_demographics_new (
customerID VARCHAR(255) PRIMARY KEY,
gender VARCHAR(255),
SeniorCitizen INT,
Partner VARCHAR(255),
Dependents VARCHAR(255)
);
CREATE TABLE user_services (
customerID VARCHAR(255) PRIMARY KEY,
PhoneService VARCHAR(255),
MultipleLines VARCHAR(255),
InternetService VARCHAR(255),
OnlineSecurity VARCHAR(255),
OnlineBackup VARCHAR(255),
DeviceProtection VARCHAR(255),
TechSupport VARCHAR(255),
StreamingTV VARCHAR(255),
StreamingMovies VARCHAR(255)
);
CREATE TABLE user_services_new (
customerID VARCHAR(255) PRIMARY KEY,
PhoneService VARCHAR(255),
MultipleLines VARCHAR(255),
InternetService VARCHAR(255),
OnlineSecurity VARCHAR(255),
OnlineBackup VARCHAR(255),
DeviceProtection VARCHAR(255),
TechSupport VARCHAR(255),
StreamingTV VARCHAR(255),
StreamingMovies VARCHAR(255)
);
CREATE TABLE user_payments (
customerID VARCHAR(255) PRIMARY KEY,
Contract VARCHAR(255),
PaperlessBilling VARCHAR(255),
PaymentMethod VARCHAR(255),
MonthlyCharges FLOAT,
TotalCharges VARCHAR(255)
);
CREATE TABLE user_payments_new (
customerID VARCHAR(255) PRIMARY KEY,
Contract VARCHAR(255),
PaperlessBilling VARCHAR(255),
PaymentMethod VARCHAR(255),
MonthlyCharges FLOAT,
TotalCharges VARCHAR(255)
);
CREATE TABLE user_churn (
customerID VARCHAR(255) PRIMARY KEY,
Churn VARCHAR(255)
);
CREATE TABLE user_churn_new (
customerID VARCHAR(255) PRIMARY KEY,
Churn VARCHAR(255)
);
2、加载业务数据
接下来,将这些CSV文件导入到之前建立的MySQL数据库表中。这一步骤是通过加载数据操作来实现的,确保了数据按照预期的结构被准确地存储和索引,便于后续的查询和分析。
## 往数据库里导入数据
LOAD DATA LOCAL INFILE '/root/autodl-tmp/iquery项目/data/业务数据/user_demographics_train.csv'
INTO TABLE user_demographics
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;
LOAD DATA LOCAL INFILE '/root/autodl-tmp/iquery项目/data/业务数据/user_services_train.csv'
INTO TABLE user_services
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;
LOAD DATA LOCAL INFILE '/root/autodl-tmp/iquery项目/data/业务数据/user_payments_train.csv'
INTO TABLE user_payments
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;
LOAD DATA LOCAL INFILE '/root/autodl-tmp/iquery项目/data/业务数据/user_churn_train.csv'
INTO TABLE user_churn
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;
## 添加测试表的数据
LOAD DATA LOCAL INFILE '/root/autodl-tmp/iquery项目/data/业务数据/user_demographics_test.csv'
INTO TABLE user_demographics_new
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;
LOAD DATA LOCAL INFILE '/root/autodl-tmp/iquery项目/data/业务数据/user_services_test.csv'
INTO TABLE user_services_new
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;
LOAD DATA LOCAL INFILE '/root/autodl-tmp/iquery项目/data/业务数据/user_payments_test.csv'
INTO TABLE user_payments_new
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;
LOAD DATA LOCAL INFILE '/root/autodl-tmp/iquery项目/data/业务数据/user_churn_test.csv'
INTO TABLE user_churn_new
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n'
IGNORE 1 ROWS;
结语
通过本文的介绍和指导,我们已经能够构建出一个具备完整数据处理流程的Agent智能数据分析平台。从数据的预处理到存储管理,每一步都旨在提升数据的质量及分析的准确性。随着技术的不断进步,这个平台将在未来发挥更大的作用,帮助企业在数据波涛中稳扬帆行,捕捉每一个商机。我们期待与读者共同见证这个平台在未来数据分析和决策支持领域中的成长与突破。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!