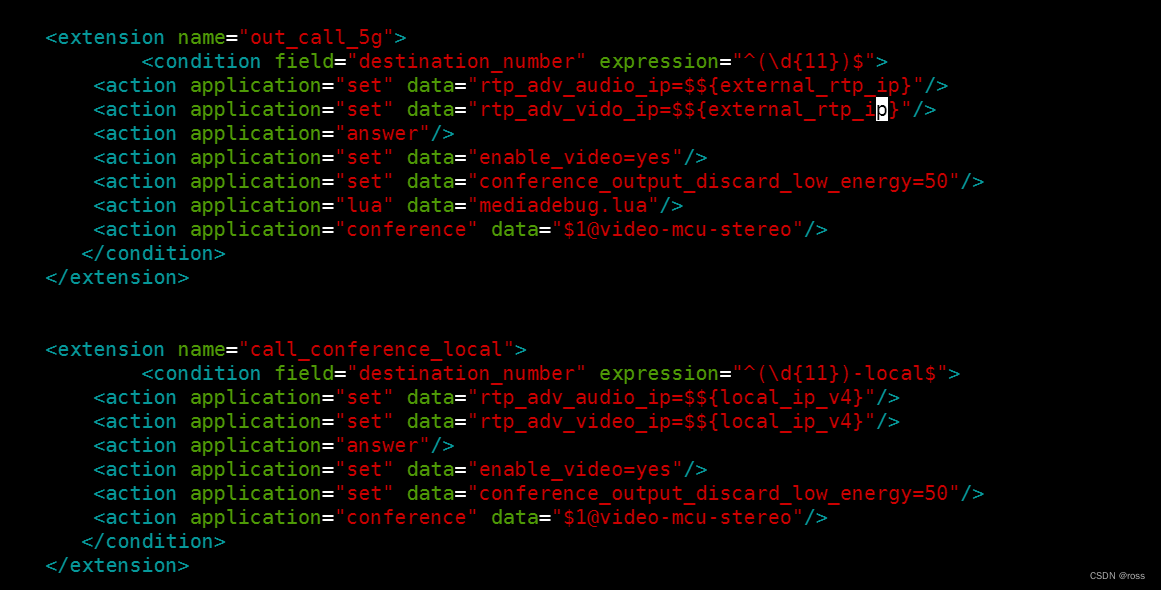
目录
前言
一、历史数据获取
1、关于天气后报
2、信息界面分析
二、数据的提取开发
1、PageVo的定义
2、属性定义
3、实际信息抓取
三、信息抓取调试以及可能的问题
1、信息获取成果
2、关于超时的问题
四、总结
前言
这篇文章主要来源于一个我们家小朋友的一个作业,作业的主要内容是要求小朋友做一个统计,在上半学期学习了统计知识,然后要结合生活实际进行统计应用,因此有了这个作业。具体要求是在一定时间范围内(一个月),要求小朋友制作一个表格,需要记录一个月内每一天的天气情况,比如阴晴雨雪。然后在这个记录之上,要求统计出这个月不同的天气有多少天?比如晴天多少天,雨天多少天,然后根据统计结果,计算这个月最多的天气是什么?最少的是什么。这题目本身不难,只要每天都进行记录的话,基本也就没什么问题。然而,中间因为小朋友身体原因。没有及时记录,中间有一段时间没有及时记录。于是我们想,只能到网上查一下历史天气。
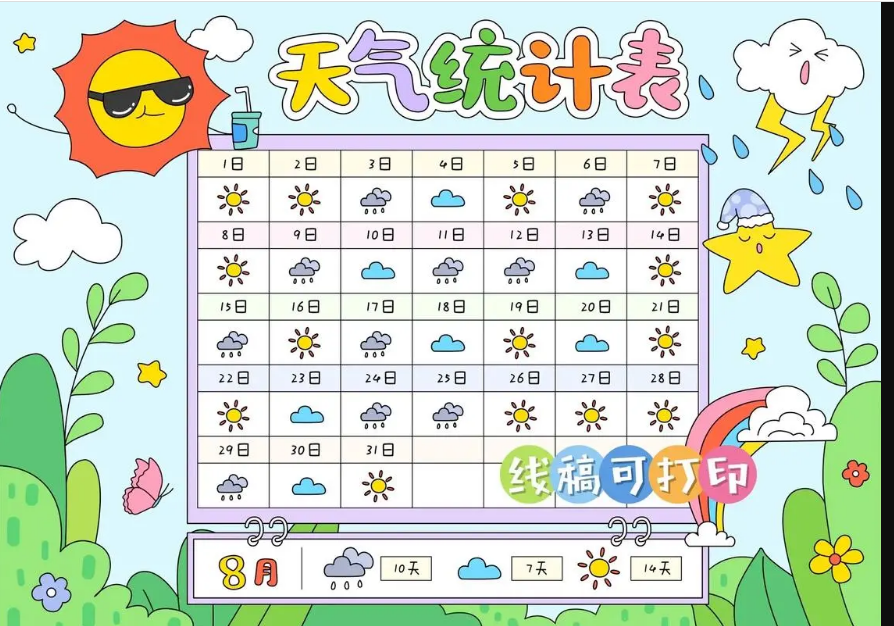
然而我发现,小朋友中间有好几天都忘了记录,数据都有空缺。于是只能按照遗忘的日期来进行补数据。虽然最后把缺失的数据都补回来了。当时在想,还好只是一个月的数据,如果要三个月,半年,甚至是一年的数据,我还能一天一天的找数据不成。作为技术人,需要用一点技术手段来解决这个问题。
本文主要讲解使用Java开发语言,使用XxlCrawler框架进行智能的某城市月度天气抓取实践开发。文章首先介绍目标网站的相关页面及目标数据的元素,然后讲解在信息获取过程的一些参数配置以及问题应对,最后结合实际代码实际抓取一个城市(以长沙为例)某月度天气数据。通过本文,您可以更加了解XxlCrawler的具体使用,知道如何解决页面返回慢的情况下如何通过超时参数来控制数据返回的问题,如果您是气象人,需要气象数据,则可以通过本文来获取想研究的地域的历史天气数据。
一、历史数据获取
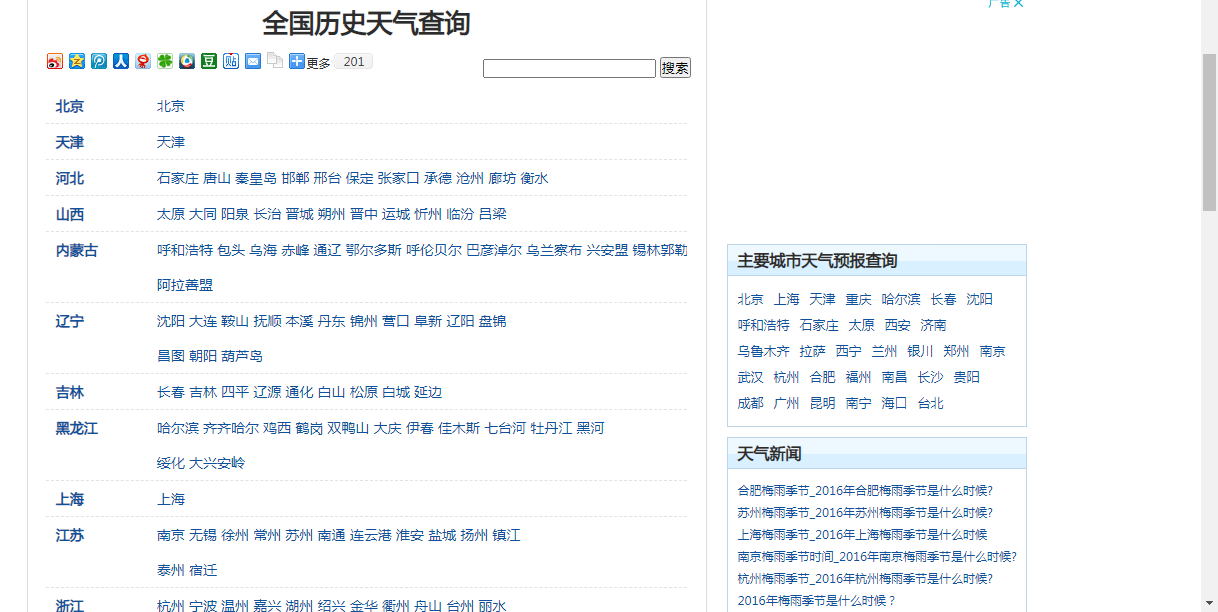
由于我们需要历史数据,因此需要找到历史数据源网站。关于天气的数据有很多网站可以提供。比较权威的就是国家的官方网站。这里呢,分享一个天气后报网站天气后报网,这个网站上可以提供城市的天气信息。本节主要介绍这个网站的内容和具体月度天气的页面。为下一步的信息获取做准备。
1、关于天气后报
在浏览器中,输入它的官方网站:http://www.tianqihoubao.com/。可以看到它的官方界面。

在上方的导航栏中,点击历史天气,可以切换到历史天气查询列表,默认按照行政区划列表的形式展示。
根据我们的需要,比如(长沙),点击我们感兴趣的城市,打开城市历史天气列表:

然后打开对应的月度天气连接,24年4月份。
http://www.tianqihoubao.com/lishi/changsha/month/202404.html这是实际的网页地址,请注意这个地址,这里其实有两个变量,第一个是城市,也就是地址信息中的changsha,另外一个是时间即202404,通过网站静态化之后,这些信息都是有规律的。因此我们可以采用XxlCrawler来自动获取。
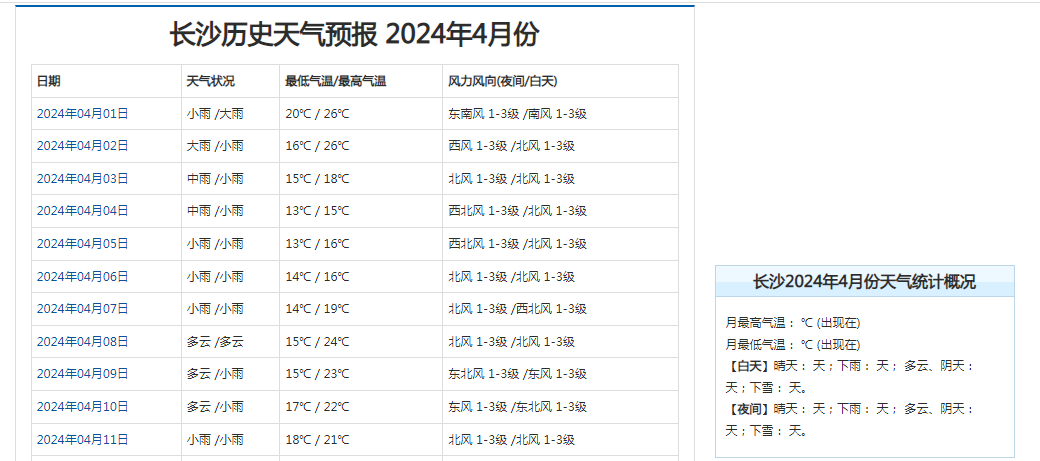
2、信息界面分析
在找到了信息源之后,我们需要分析一些网页的结构,网页信息很多,我们只关心目标数据。这里只需要把表格中的几个关键信息提取出来即可。比如日期、天气状况、气温信息、风力风向信息。这些关键的信息都是在一个表格中展示出来的。在页面中打开调试窗口,来看一下结构:
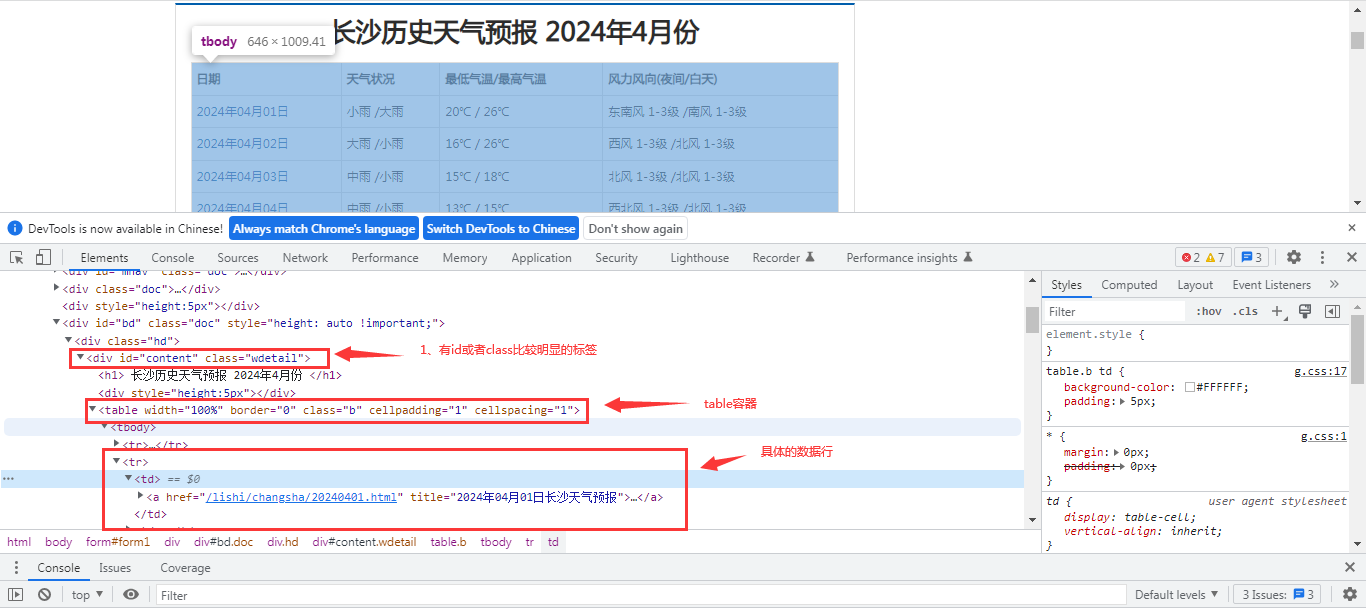
首先来看一下网页结构,其主要的div是绑定在一个id='content'的网页元素下的。同时下面的数据是存在在标准的table中,因此我们只需要将table中的tr中循环提取出来即可。
二、数据的提取开发
在明确了数据来源的网页结构之后,这一节我们来进行实际的数据提取的开发。通过XxlCrawler组件来获取信息。本小节着重讲解代码的设计与实现。
1、PageVo的定义
熟悉XxlCrawler的朋友知道,PageVO是解析页面的一个对象。框架在读取到页面的信息后,会自动的将信息按照PageVO的配置,解析到实体类中。因此需要对PageVO进行定义。
@PageSelect(cssQuery = "#content >table >tbody >tr")
@AllArgsConstructor
@NoArgsConstructor
public static class PageVo {
@PageFieldSelect(cssQuery=" >td:eq(0)")
@Excel(name = "日期")
private String day;
@PageFieldSelect(cssQuery = ">td:eq(1)")
@Excel(name = "天气状况")
private String weatherInfo;
@PageFieldSelect(cssQuery = ">td:eq(2)")
@Excel(name = "最低气温/最高气温")
private String weatherTemp;
@PageFieldSelect(cssQuery = ">td:eq(3)")
@Excel(name = "风力风向(夜间/白天)")
private String weatherWind;
}在PageVO的定义过程中,我们使用了三个注解,第一个是@PageSelect(cssQuery = "#content >table >tbody >tr"),这个注解是用来进行页面抓取绑定的。第二个是@PageFieldSelect(cssQuery=" >td:eq(0)"),这个主要是用来进行具体的属性信息绑定,即解析哪个信息,设置到哪个属性当中去,在循环中特别好用。不用向之前那样,自己去解析。第三个是@Excel(name = "日期"),这个跟信息获取关系不大,只是用来最后将获取的信息写入到Excel表格中。当然,结合实际的需求,您可以把数据写入到数据库中,这样子可以在后期在需要的时候进行查询进行分析。
2、属性定义
按照JavaOOP的设计思想,这里我们将一些信息封装起来,比如User-Agent还有公共的请求地地址等统一定义,在进行信息抓取时可以直接使用。关键代码如下:
private static final String USER_AGENT = "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36";
private List<PageVo> weatherList = new ArrayList<PageVo>();
private static final String COMMON_URL = "http://www.tianqihoubao.com/lishi/changsha/month/";weatherList就是用来保存所有的天数数据的,在程序的最后可以用来保存数据或者持久化的作用。
3、实际信息抓取
这里来定义实际信息抓取对象的配置,以及实际启动逻辑。
@Test
public void fetchWeaterInfo() {
int year = 2023;
int month = 9; // 月份从 0 开始,3 表示4月份
String monthStr = "";
monthStr += month < 10 ? "0" + month : month;
String targetUrl = COMMON_URL + year + monthStr + ".html";
System.out.println(targetUrl);
// 构造爬虫
XxlCrawler crawler = new XxlCrawler.Builder()
.setUrls(targetUrl)
.setAllowSpread(false)// 不允许扩散爬取
.setThreadCount(3)
.setPauseMillis(3000)
.setUserAgent(USER_AGENT)//设置user_agent
.setIfPost(false)
.setFailRetryCount(3)// 重试三次
.setTimeoutMillis(1000 * 12)//超时时间,有些网站加载慢,一定要加这个时间
.setPageParser(new PageParser<PageVo>() {
@Override
public void parse(Document html, Element pageVoElement, PageVo pageVo) {
//System.out.println(pageVoElement);
weatherList.add(pageVo);
}
}).build();
crawler.start(true);// 启动
// excel工具包
weatherList.remove(0);//把第一行表头移除掉
ExcelUtil<PageVo> util = new ExcelUtil<PageVo>(PageVo.class);
util.exportExcel(weatherList, year + "年" + month + "月天气情况表");
System.out.println("finished...");
}这里需要注意的是,信息抓取器,每次得到的一个tbody中的一行,即tr的数据。我们需要将所有的数据解析完成之后,统一存放到一个List当中。实现月度的数据搜集,同时第一行是表头数据。需要剔除。因此,在写入到Excel之前,要将第一行删除,
weatherList.remove(0);//把第一行表头移除掉三、信息抓取调试以及可能的问题
这里分享实际的信息获取结果,对抓取的信息进行综合展示。同时这里简单分享在信息获取过程中可能遇到的问题和解决方案。
1、信息获取成果
将上述代码运行后,可以在控制中看到以下输出信息:
http://www.tianqihoubao.com/lishi/changsha/month/202309.html
09:42:29.027 [main] INFO com.xuxueli.crawler.rundata.strategy.LocalRunData - >>>>>>>>>>> xxl-crawler addUrl success, link: http://www.tianqihoubao.com/lishi/changsha/month/202309.html
09:42:29.035 [main] INFO com.xuxueli.crawler.XxlCrawler - >>>>>>>>>>> xxl crawler start ...
09:42:29.038 [pool-1-thread-1] INFO com.xuxueli.crawler.thread.CrawlerThread - >>>>>>>>>>> xxl crawler, process link : http://www.tianqihoubao.com/lishi/changsha/month/202309.html
09:42:33.634 [pool-1-thread-1] INFO com.xuxueli.crawler.XxlCrawler - >>>>>>>>>>> xxl crawler is finished.
09:42:33.635 [pool-1-thread-2] INFO com.xuxueli.crawler.thread.CrawlerThread - >>>>>>>>>>> xxl crawler thread LocalRunData.getUrl interrupted.
09:42:33.635 [pool-1-thread-3] INFO com.xuxueli.crawler.thread.CrawlerThread - >>>>>>>>>>> xxl crawler thread LocalRunData.getUrl interrupted.
09:42:33.635 [pool-1-thread-1] INFO com.xuxueli.crawler.XxlCrawler - >>>>>>>>>>> xxl crawler stop.
09:42:33.636 [pool-1-thread-1] INFO com.xuxueli.crawler.thread.CrawlerThread - >>>>>>>>>>> xxl crawler thread LocalRunData.getUrl interrupted.
finished...
这里提示,信息抓取完成,同时我们将数据写入到了Excel当中,找到目标文件夹,来看一下实际的效果。
| 日期 | 天气状况 | 最低气温/最高气温 | 风力风向(夜间/白天) |
| 2024年04月01日 | 小雨 /大雨 | 20℃ / 26℃ | 东南风 1-3级 /南风 1-3级 |
| 2024年04月02日 | 大雨 /小雨 | 16℃ / 26℃ | 西风 1-3级 /北风 1-3级 |
| 2024年04月03日 | 中雨 /小雨 | 15℃ / 18℃ | 北风 1-3级 /北风 1-3级 |
| 2024年04月04日 | 中雨 /小雨 | 13℃ / 15℃ | 西北风 1-3级 /北风 1-3级 |
| 2024年04月05日 | 小雨 /小雨 | 13℃ / 16℃ | 西北风 1-3级 /北风 1-3级 |
| 2024年04月06日 | 小雨 /小雨 | 14℃ / 16℃ | 北风 1-3级 /北风 1-3级 |
| 2024年04月07日 | 小雨 /小雨 | 14℃ / 19℃ | 北风 1-3级 /西北风 1-3级 |
| 2024年04月08日 | 多云 /多云 | 15℃ / 24℃ | 北风 1-3级 /北风 1-3级 |
| 2024年04月09日 | 多云 /小雨 | 15℃ / 23℃ | 东北风 1-3级 /东风 1-3级 |
| 2024年04月10日 | 多云 /小雨 | 17℃ / 22℃ | 东风 1-3级 /东北风 1-3级 |
| 2024年04月11日 | 小雨 /小雨 | 18℃ / 21℃ | 北风 1-3级 /北风 1-3级 |
| 2024年04月12日 | 阴 /小雨 | 18℃ / 25℃ | 东南风 1-3级 /东南风 1-3级 |
| 2024年04月13日 | 中雨 /小雨 | 20℃ / 26℃ | 东南风 1-3级 /南风 1-3级 |
| 2024年04月14日 | 小雨 /多云 | 20℃ / 28℃ | 东北风 1-3级 /东南风 1-3级 |
| 2024年04月15日 | 小雨 /中雨 | 21℃ / 31℃ | 南风 1-3级 /东南风 1-3级 |
| 2024年04月16日 | 暴雨 /中雨 | 20℃ / 26℃ | 西风 1-3级 /西风 1-3级 |
| 2024年04月17日 | 小雨 /阴 | 19℃ / 23℃ | 西北风 1-3级 /北风 1-3级 |
| 2024年04月18日 | 多云 /小雨 | 19℃ / 27℃ | 东南风 1-3级 /东南风 1-3级 |
| 2024年04月19日 | 中雨 /阴 | 18℃ / 24℃ | 东南风 1-3级 /北风 1-3级 |
| 2024年04月20日 | 小雨 /小雨 | 19℃ / 24℃ | 北风 1-3级 /西北风 1-3级 |
| 2024年04月21日 | 阴 /多云 | 17℃ / 24℃ | 东风 1-3级 /北风 1-3级 |
| 2024年04月22日 | 小雨 /阴 | 19℃ / 24℃ | 西北风 1-3级 /西北风 1-3级 |
| 2024年04月23日 | 多云 /多云 | 18℃ / 27℃ | 北风 1-3级 /北风 1-3级 |
| 2024年04月24日 | 多云 /小雨 | 19℃ / 27℃ | 东北风 1-3级 /东风 1-3级 |
| 2024年04月25日 | 中雨 /多云 | 19℃ / 25℃ | 东风 1-3级 /东风 1-3级 |
| 2024年04月26日 | 多云 /多云 | 19℃ / 30℃ | 西北风 1-3级 /东南风 1-3级 |
| 2024年04月27日 | 中雨 /小雨 | 20℃ / 28℃ | 东北风 1-3级 /西南风 1-3级 |
| 2024年04月28日 | 多云 /小雨 | 20℃ / 29℃ | 北风 1-3级 /东北风 1-3级 |
| 2024年04月29日 | 中雨 /大雨 | 18℃ / 25℃ | 西风 1-3级 /西北风 1-3级 |
| 2024年04月30日 | 小雨 /多云 | 14℃ / 18℃ | 北风 1-3级 /北风 1-3级 |
大家可以对比原来的网页地址,可以看到表格获取的信息与网页一致。这里的实例仅提供一个例子,抛砖引玉,大家可以结合自己的实际工作。获取更多的天气信息。
2、关于超时的问题
XxlCrawler的默认超时时间是5秒(5000ms),即5秒钟内数据没有返回则超时。其定义如下:
private volatile int timeoutMillis = XxlCrawlerConf.TIMEOUT_MILLIS_DEFAULT; // 超时时间,毫秒
// timeout default, ms
public static final int TIMEOUT_MILLIS_DEFAULT = 5*1000;在默认的情况下,页面经常超时,请求时会报以下的错误:
http://www.tianqihoubao.com/lishi/changsha/month/202404.html
11:03:27.685 [main] INFO com.xuxueli.crawler.rundata.strategy.LocalRunData - >>>>>>>>>>> xxl-crawler addUrl success, link: http://www.tianqihoubao.com/lishi/changsha/month/202404.html
11:03:27.693 [main] INFO com.xuxueli.crawler.XxlCrawler - >>>>>>>>>>> xxl crawler start ...
11:03:27.695 [pool-1-thread-2] INFO com.xuxueli.crawler.thread.CrawlerThread - >>>>>>>>>>> xxl crawler, process link : http://www.tianqihoubao.com/lishi/changsha/month/202404.html
11:03:32.697 [main] INFO com.xuxueli.crawler.XxlCrawler - >>>>>>>>>>> xxl crawler still running ...
11:03:33.456 [pool-1-thread-2] ERROR com.xuxueli.crawler.util.JsoupUtil - Read timeout
java.net.SocketTimeoutException: Read timeout
at org.jsoup.internal.ConstrainableInputStream.read(ConstrainableInputStream.java:58)
at sun.nio.cs.StreamDecoder.readBytes(Unknown Source)
at sun.nio.cs.StreamDecoder.implRead(Unknown Source)
at sun.nio.cs.StreamDecoder.read(Unknown Source)
at java.io.InputStreamReader.read(Unknown Source)
at java.io.BufferedReader.fill(Unknown Source)
at java.io.BufferedReader.read1(Unknown Source)
at java.io.BufferedReader.read(Unknown Source)
at org.jsoup.parser.CharacterReader.bufferUp(CharacterReader.java:87)
at org.jsoup.parser.CharacterReader.current(CharacterReader.java:246)
at org.jsoup.parser.TokeniserState$1.read(TokeniserState.java:12)
at org.jsoup.parser.Tokeniser.read(Tokeniser.java:62)
at org.jsoup.parser.TreeBuilder.runParser(TreeBuilder.java:86)
at org.jsoup.parser.TreeBuilder.parse(TreeBuilder.java:61)
at org.jsoup.parser.Parser.parseInput(Parser.java:51)
at org.jsoup.helper.DataUtil.parseInputStream(DataUtil.java:218)
at org.jsoup.helper.HttpConnection$Response.parse(HttpConnection.java:962)
at org.jsoup.helper.HttpConnection.get(HttpConnection.java:355)
at com.xuxueli.crawler.util.JsoupUtil.load(JsoupUtil.java:77)
at com.xuxueli.crawler.loader.strategy.JsoupPageLoader.load(JsoupPageLoader.java:17)
at com.xuxueli.crawler.thread.CrawlerThread.processPage(CrawlerThread.java:167)
at com.xuxueli.crawler.thread.CrawlerThread.run(CrawlerThread.java:84)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
在网页中验证以下请求时间,请注意打开F12进行页面请求的时间跟踪:

可以看到页面 ,页面加载大约花了11.93秒,接近12秒。因此其默认的5秒超时设置是不够的。具体的响应时间,请按照大家的实际情况合理设置。把超时时间延长后,就不会出现这个错误了。
四、总结
以上就是本文的主要内容,本文主要讲解使用Java开发语言,使用XxlCrawler框架进行智能的某城市月度天气抓取实践开发。文章首先介绍目标网站的相关页面及目标数据的元素,然后讲解在信息获取过程的一些参数配置以及问题应对,最后结合实际代码实际抓取一个城市(以长沙为例)某月度天气数据。通过本文,您可以更加了解XxlCrawler的具体使用,知道如何解决页面返回慢的情况下如何通过超时参数来控制数据返回的问题,如果您是气象人,需要气象数据,则可以通过本文来获取想研究的地域的历史天气数据。行文仓促,定有不足之处,欢迎各位专家朋友在评论区中批评指正,万分荣幸。技术人通过自己的技术来解决一点生活问题,技术让生活更美好。