上节内容的网页是hello world的字符串,但实际上网页应该是html格式的这种超文本标记语言,这一节完善一下网页的各种格式和内容
分文件
实际服务器中,网页的界面应该单独放一个文件,服务器从文件里读取网页的内容
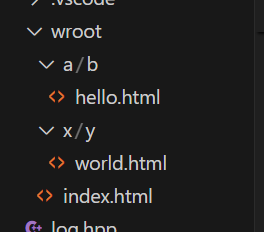
先创建一个wroot文件夹专门用来放网页文件,创建主页,index.html。一个网址网页肯定不止一个,再创建两个分页,分别放在a/b目录和x/y目录下
网页的显示根据用户请求的url,请求哪个网页显示哪个。所以要对用户的请求反序列化,得到各部分的内容。为了得到url,请求行每部分内容都要取到。创建一个包含各个内容的类
成员变量包含报头部分和正文部分,报头部分的请求方法,url,请求版本,再将url分割出请求的路径
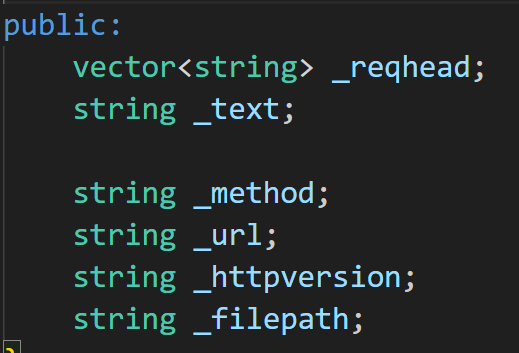
成员函数将报文内容解析为两部分。参数是报文字符串,先找第一个\r\n,找到的就是请求行,加入到reqhead的0下标,然后不停找\r\n,没找到一个就是一行报文,加入到reqhead,接着删除读取到的内容,继续后面的内容。如果这行内容是空,就是到了空行。剩下的内容就是正文,放入text
void deserialize(string message)
{
while (true)
{
size_t pos = message.find(seq);
if (pos == string::npos)
{
break;
}
string temp = message.substr(0, pos);
if (temp.empty())
{
break;
}
_reqhead.push_back(temp);
// pos + seq
message.erase(0, pos + seq.size());
}
_text = message;
}
将报头内容的请求行分离出来,得到url,获取到用户请求的网页路径
stringstream可以自动按空格分隔内容,流符号提取到变量中。wroot变量是目录初始常量

filepath先赋值为初始量,如果url是根目录,拼上主页的内容。如果是分页,拼接上url
void parse()
{
stringstream s(_reqhead[0]);
s >> _method >> _url >> _httpversion;
_filepath = wroot;
// wroot/index.html
if (_url == "/" || _url == "/index.html")
{
_filepath += "/";
_filepath += homepage;
}
else
{
// 用户/a/b 文件./wroot/a/b
_filepath += _url;
}
}
debugprint函数将成员变量的值都打印显示
void debugprint()
{
for (auto &line : _reqhead)
{
cout << "---------------------------" << endl;
cout << line << "\n";
}
cout << "method:" << _method << endl;
cout << "url:" << _url << endl;
cout << "http-version:" << _httpversion << endl;
cout << "file_path:" << _filepath << endl;
cout << _text << endl;
}
在收到报文后,实例Request类调用函数得到变量值
text的内容用函数获取,传入用户访问的哪个文件,读取内容返回字符串

ReadHtmlContent
文件打开失败返回404,成功读取所有内容返回
static string ReadHtmlContent(const string htmlpath)
{
ifstream in(htmlpath);
if (!in.is_open())
{
return "404";
}
string line;
string content;
while (getline(in, line))
{
content += line;
}
in.close();
return content;
}
html基本格式
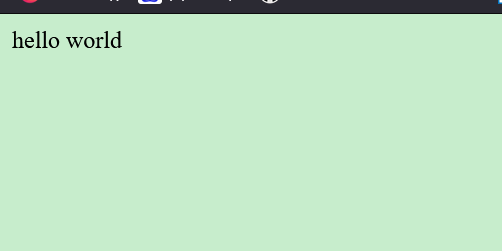
首先用<html></html>表明是html格式,<head></head>中可以设置中文编码为utf-8,不然中文会乱码。<body></body>内容中是网页主体内容,将hello world改为下面格式
<!DOCTYPE html>
<html html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
hello world
</body>
</html>
开启服务端,访问
标题
一共有六级标题,h1-h6
<h1>内容</h1>

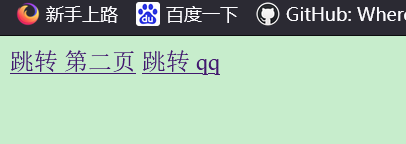
跳转
在网页中,点击某几个字就会跳转到新的网页
<a href=url>显示内容</a>
将a/b文件夹下的hello.html作为第二张网页,x/y下的world.html作为第三张网页。主页可以跳转第二张,第二张可以返回主页或跳转第三页,第三页返回主页
以主页的跳转举例:


也可以直接访问web其他目录,/的格式拼到后面
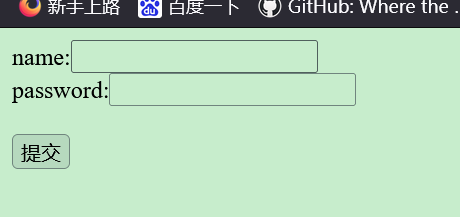
获取输入
在百度还是其他登录网页中,需要输入内容,服务器获取到提供对应的服务,这个需要用到表单
<form action="action_page.php" method="GET">
First name:<br>
<input type="text" name="firstname" value="Mickey">
<br>
Last name:<br>
<input type="text" name="lastname" value="Mouse">
<br><br>
<input type="submit" value="Submit">
</form>
GET
方法默认是get
action是将输入内容传递给谁,可以是一个程序,收到内容后程序替换执行登录验证,提交方法有get和post,下面的name是url后输入值的变量名。value是默认显示值。type是输入框类型
<!DOCTYPE html>
<html html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<form action="/a/b/hello.html" method="GET">
name:<input type="text" name="name"><br>
password:<input type="password" name="pass">
<br><br>
<input type="submit" value="提交">
</form>
</body>
</html>

url的 ?号前面是访问路径,后面是刚填入提交的参数
POST
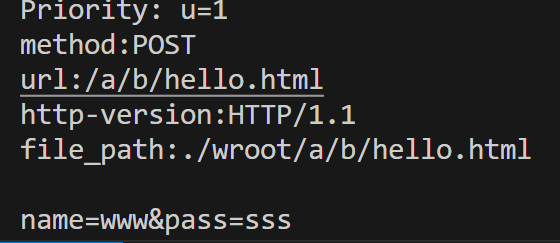
post方法的提交内容在正文里
GET方法通过URL进行提参,参数数量受限的,不私密
POST方法也支持参数提交,采用请求的正文提交参数,更私密一些
安全问题都会存在,安全可以在加密方面完善
HTTP的方法
| 方法 | 说明 | 支持的版本 |
|---|---|---|
| GET | 获取资源 | 1.0、1.1 |
| POST | 传输实体主体 | 1.0、1.1 |
| PUT | 传输文件 | 1.0、1.1 |
| HEAD | 获得报文首部 | 1.0、1.1 |
| DELETE | 删除文件 | 1.0、1.1 |
| OPTIONS | 询问支持的方法 | 1.1 |
| TRACE | 追踪路径 | 1.1 |
| CONNECT | 要求用隧道协议连接代理 | 1.1 |
| LINK | 建立和资源之间的联系 | 1.0 |
| UNLINK | 断开连接关系 | 1.0 |
大部分方法用的都是GET和POST,CONNECT一般是中间连接使用的方法,其他有的浏览器禁止使用
HTTP的状态码
| 状态码 | 类别 | 原因短语 |
|---|---|---|
| 1XX | Informational(信息性状态码) | 接收的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
最常见的状态码,比如200(OK),404(Not Found),302(Redirect,重定向),502(Bad Gateway)
错误页面
上面的网页如果用户访问不存在的网页会打不开,实际上,如京东,如果访问的网页不存在,会提示自己的404页面,未找到网页,同时可以返回主页。我们也需要制作自己的404页面,如果访问的不存在,则显示这个页面
创建一个err页面,显示错误内容
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>404 Not Found</title>
<style>
body {
text-align: center;
padding: 150px;
}
h1 {
font-size: 50px;
}
body {
font-size: 20px;
}
a {
color: #008080;
text-decoration: none;
}
a:hover {
color: #005F5F;
text-decoration: underline;
}
</style>
</head>
<body>
<div>
<h1>404</h1>
<p>页面未找到<br></p>
<p>
您请求的页面可能已经被删除、更名或者您输入的网址有误。<br>
请尝试使用以下链接或者自行搜索:<br><br>
<a href="https://www.baidu.com">百度一下></a>
</p>
</div>
</body>
</html>
如果读到的网页内容是空,说明是错误页面。重新读取刚刚创建的错误页面返回
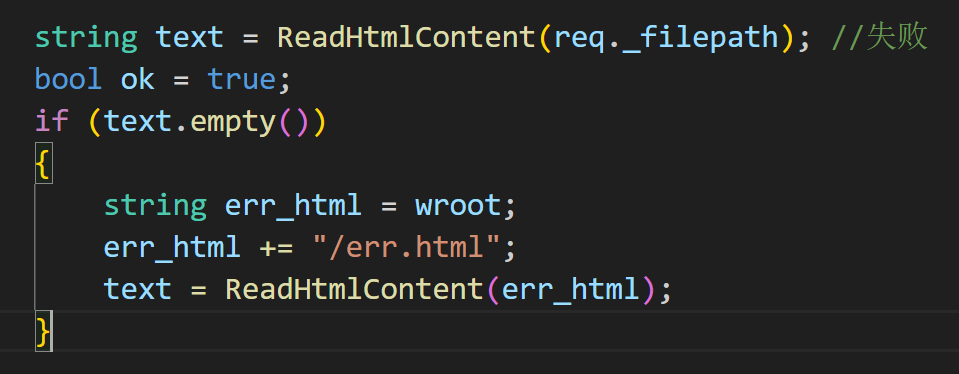
响应行也得修改
页面显示如下:

响应内容

HTTP常见Header
Content-Type:数据类型(text/html等)
Content-Length:Body的长度
Host:客户端告知服务器,所请求的资源是在哪个主机的端口上
User-Agent:声明用户的操作系统和浏览器版本信息
referer:当前页面是从哪个页面跳转过来的
location:搭配3xx状态码使用,告诉客户端接下来要去访问哪里
Cookie:用于在客户端存储少量信息,通常用于实现会话(session)功能
重定向
3XX状态码是重定向,重定向用于服务器暂时维护,引导客户到新的网页。或者服务网址已更换,引导旧用户去新地址

浏览器访问服务器,服务器返回3xx和新服务,浏览器再次对新服务发起访问
永久重定向:301,308
临时重定向:302,303, 307
其他重定向:304
报头也得添加location字段,重定向到导航页


这时访问就会跳转到目标网页

长短连接
一个网页中会有很多图片视频等,每一个都算一个资源,连接每次只能获取一个资源,再获取资源必须重新请求,这是短连接这样一个网页有100张图片就要请求一百次,显然是低效的。建立一个tcp连接,发送和返回多个http的request和response,就是长连接
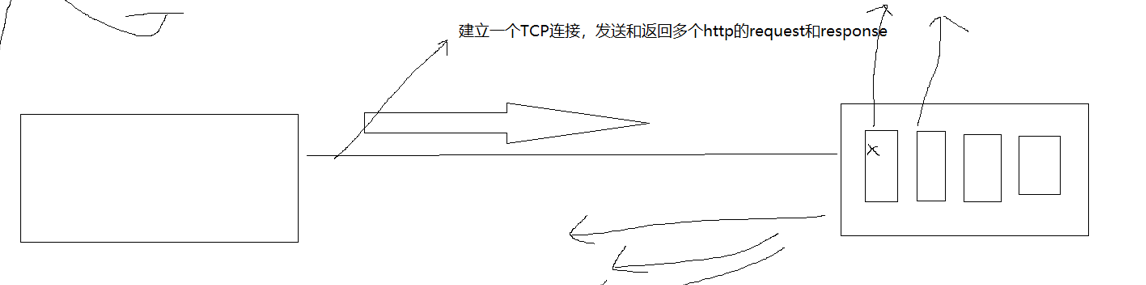
长连接需要添加Connection:keep-alive报头
图片
要在服务器里加载图片,报头里需要加入图片的类型,content-type字段对应数据类型,.html是网页文件后缀,.jpg就是图片类型,对应类型加入报头的内容如下:
text/html : HTML格式
text/plain :纯文本格式
text/xml : XML格式
image/gif :gif图片格式
image/jpeg :jpg图片格式
image/png:png图片格式
image/jpg:jpg图片格式
image/pdf:pdf格式
找几张图片,放在wroot文件夹下的image文件夹里。在网页文件中加入图片格式内容
html图片格式:

src是文件路径,alt是图片加载不出来显示的文字

长连接会根据src自动发起后续的请求
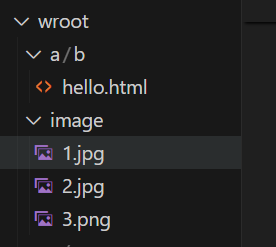
想在报头中添加content,需要从url中获得对应类型的协议内容,所以request类里添加一个成员后缀,从url中分割出.后面的文件类型

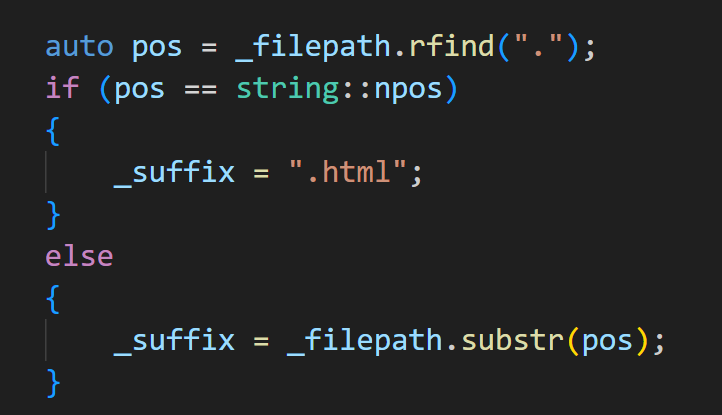
有了后缀需要一个对照表,返回对应类型的内容,用一个map类型,初始化插入几个基本类型

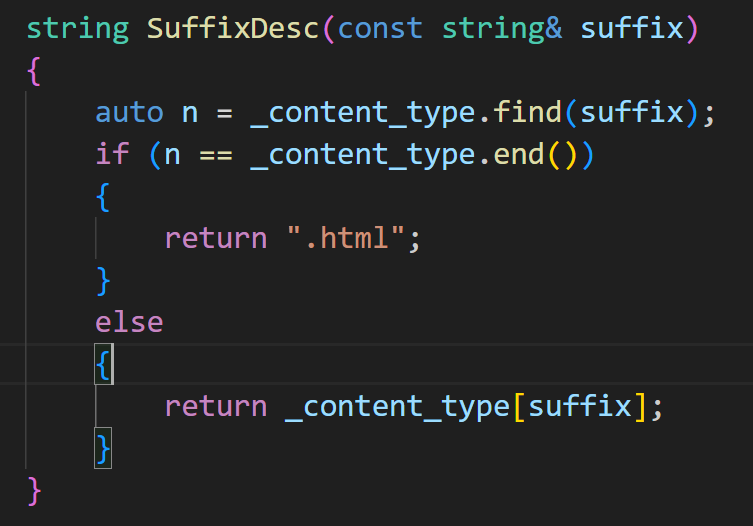
提供函数,用参数对应表返回格式内容:
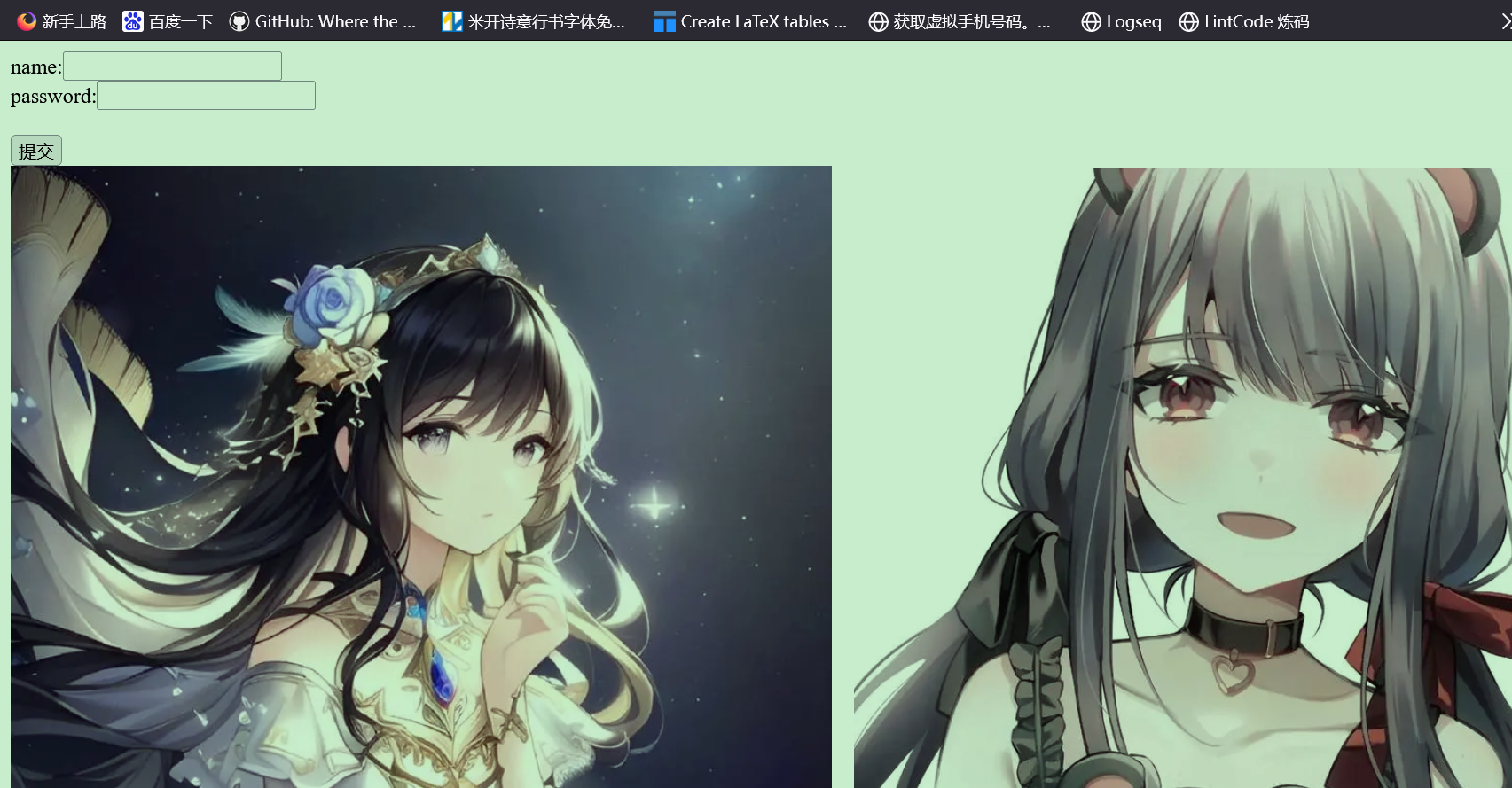
显示效果:
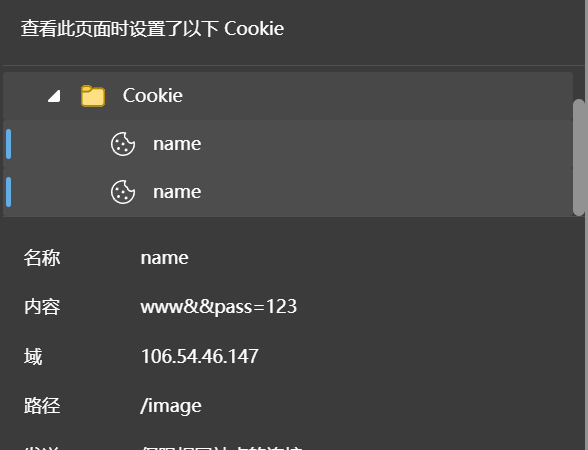
cookie
这个是用来登录用户的会话保持功能,浏览器在访问一个网页时,需要登录,登录成功后往浏览器写入cookie文件,当下一次打开这个网页时,用户会自动登录。cookie分为文件及和内存级,内存级的关闭浏览器就会失效。cookie有时间限制,如果不设置就由浏览器管理

加入cookie

以后每次访问,访问会自动带上cookie:
全代码
server.hpp
#include <fstream>
#include <pthread.h>
#include <vector>
#include <sstream>
#include <unordered_map>
#include "Socket.hpp"
const uint16_t port = 8000;
const string wroot = "./wroot";
const string seq = "\r\n";
const string homepage = "index.html";
class server;
class ThreadData
{
public:
int _sockfd;
server *_this;
};
class Request
{
public:
void deserialize(string message)
{
while (true)
{
size_t pos = message.find(seq);
if (pos == string::npos)
{
break;
}
string temp = message.substr(0, pos);
if (temp.empty())
{
break;
}
_reqhead.push_back(temp);
// pos + seq
message.erase(0, pos + seq.size());
}
_text = message;
}
void parse()
{
stringstream s(_reqhead[0]);
s >> _method >> _url >> _httpversion;
_filepath = wroot;
// wroot/index.html
if (_url == "/" || _url == "/index.html")
{
_filepath += "/";
_filepath += homepage;
}
else
{
// 用户/a/b 文件./wroot/a/b
_filepath += _url;
}
auto pos = _filepath.rfind(".");
if (pos == string::npos)
{
_suffix = ".html";
}
else
{
_suffix = _filepath.substr(pos);
}
}
void debugprint()
{
for (auto &line : _reqhead)
{
cout << "---------------------------" << endl;
cout << line << "\n";
}
cout << "method:" << _method << endl;
cout << "url:" << _url << endl;
cout << "http-version:" << _httpversion << endl;
cout << "file_path:" << _filepath << endl;
cout << "content-type: " << _suffix << endl;
cout << _text << endl;
}
public:
vector<string> _reqhead;
string _text;
string _method;
string _url;
string _httpversion;
string _filepath;
string _suffix;
};
class server
{
public:
void ContentTable()
{
_content_type.insert({".html", "text/html"});
_content_type.insert({".jpg", "image/jpeg"});
_content_type.insert({".png", "image/png"});
}
void start()
{
ContentTable();
_listensock.Socket();
_listensock.Bind(port);
_listensock.Listen();
cout << "server init done" << endl;
for (;;)
{
string ip;
uint16_t port;
int sockfd = _listensock.Accept(&ip, &port);
if (sockfd > 0)
{
cout << "get a new link:" << ip << "," << port << endl;
pthread_t tid;
ThreadData *data = new ThreadData;
data->_sockfd = sockfd;
data->_this = this;
pthread_create(&tid, nullptr, routine, data);
}
}
}
static void *routine(void *args)
{
pthread_detach(pthread_self());
ThreadData *dat = static_cast<ThreadData *>(args);
dat->_this->HandlerHttp(dat->_sockfd);
close(dat->_sockfd);
delete dat;
return nullptr;
}
string SuffixDesc(const string& suffix)
{
auto n = _content_type.find(suffix);
if (n == _content_type.end())
{
return ".html";
}
else
{
return _content_type[suffix];
}
}
void HandlerHttp(int sockfd)
{
char buff[1024];
ssize_t n = recv(sockfd, buff, sizeof(buff) - 1, 0);
if (n > 0)
{
buff[n] = 0;
// 假设读到了完整报文
// 分割请求,获取请求文件
Request req;
req.deserialize(buff);
req.parse();
req.debugprint();
// 响应内容
string text = ReadHtmlContent(req._filepath); //失败
bool ok = true;
if (text.empty())
{
ok = false;
string err_html = wroot;
err_html += "/err.html";
text = ReadHtmlContent(err_html);
}
string response_line;
if (ok)
{
response_line = "HTTP/1.0 200 OK\r\n";
}
else
{
response_line = "HTTP/1.0 404 Not Found\r\n";
}
//response_line = "HTTP/1.0 302 Found\r\n";
string response_head = "Content-Length: ";
response_head += to_string(text.size());
response_head += "\r\n";
//response_head += "location: https://home.firefoxchina.cn/\r\n";
response_head += "Content-Type: ";
response_head += SuffixDesc(req._suffix);
//cout << "Content-Type: " << SuffixDesc(req._suffix) << endl;
response_head += "\r\n";
response_head += "Set-Cookie: name=www&&pass=123\r\n";
string block_line = "\r\n";
string response = response_line;
response += response_head;
response += block_line;
response += text;
//cout << response << endl;
send(sockfd, response.c_str(), response.size(), 0);
}
}
// 读取html
static string ReadHtmlContent(const string htmlpath)
{
// 图片数据需要二进制读取
ifstream in(htmlpath, ios::binary);
in.seekg(0, ios_base::end);
std::streampos len = in.tellg();
in.seekg(0, ios_base::beg);
string content;
content.resize(len);
in.read((char *)content.c_str(), content.size());
// if (!in.is_open())
// {
// return "";
// }
// string line;
// string content;
// while (getline(in, line))
// {
// content += line;
// }
in.close();
return content;
}
private:
Sock _listensock;
unordered_map<string, string> _content_type;
};
index,html
<!-- <!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
#header {
background-color: black;
color: white;
text-align: center;
padding: 5px;
}
#nav {
line-height: 30px;
background-color: #eeeeee;
height: 300px;
width: 100px;
float: left;
padding: 5px;
}
#section {
width: 350px;
float: left;
padding: 10px;
}
#footer {
background-color: black;
color: white;
clear: both;
text-align: center;
padding: 5px;
}
</style>
</head>
<body>
<div id="header">
<h1>City Gallery</h1>
</div>
<div id="nav">
London<br>
Paris<br>
Tokyo<br>
</div>
<div id="section">
<h2>London</h2>
<p>
London is the capital city of England. It is the most populous city in the United Kingdom,
with a metropolitan area of over 13 million inhabitants.
</p>
<p>
Standing on the River Thames, London has been a major settlement for two millennia,
its history going back to its founding by the Romans, who named it Londinium.
</p>
</div>
<a href="http://106.54.46.147:8000/a/b/hello.html">跳转 第二页</a>
<a href="https://im.qq.com">跳转 qq</a>
<div id="footer">
Copyright ? W3Schools.com
</div>
</body>
</html> -->
<!-- <!DOCTYPE html>
<html html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<a href="http://106.54.46.147:8000/a/b/hello.html">跳转 第二页</a>
<a href="https://im.qq.com">跳转 qq</a>
</body>
</html> -->
<!DOCTYPE html>
<html html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<form action="/a/b/hello.html" method="POST">
name:<input type="text" name="name"><br>
password:<input type="password" name="pass">
<br><br>
<input type="submit" value="提交">
</form>
<img src="/image/1.jpg" alt="1.jpg" width="617" height="816"> <!--根据src自动发起第二次请求-->>
<img src="/image/2.jpg" alt="2.jpg" width="574" height="815">
<img src="/image/3.png" alt="3.png" width="617" height="816">
</body>
</html>
hello.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<h1>hello</h1>
<h1>hello</h1>
<h1>hello</h1>
<h1>hello</h1>
<h1>hello</h1>
<h1>hello</h1>
<h1>这是第一张网页</h1>
<a href="http://106.54.46.147:8000/x/y/world.html">跳转 第三页</a>
<a href="http://106.54.46.147:8000">返回主页</a>
</body>
</html>
world.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<h1>wrold</h1>
<h1>wrold</h1>
<h1>wrold</h1>
<h1>wrold</h1>
<h1>wrold</h1>
<h1>wrold</h1>
<h1>这是第二张网页</h1>
<a href="http://106.54.46.147:8000">返回主页</a>
</body>
</html>