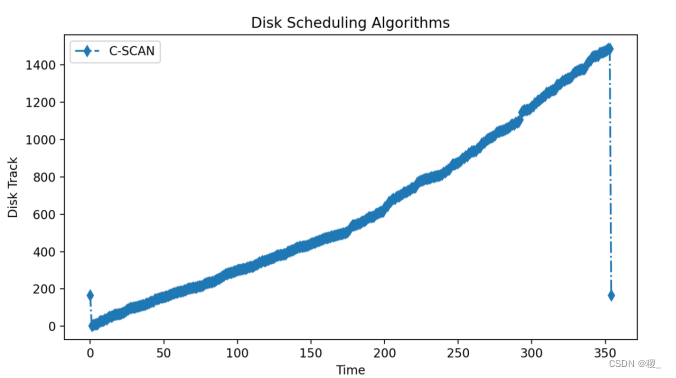
参考:LViT:语言与视觉Transformer在医学图像分割-CSDN博客
背景
- 标注成本过高而无法获得足够高质量标记数据
- 医学文本注释被纳入以弥补图像数据的质量缺陷
- 半监督学习:引导生成质量提高的伪标签
- 医学图像中不同区域之间的边界往往是模糊的,边界附近的灰度值差很小,很难提取出高精度的分割边界
贡献
- 指数伪标签迭代机制(EPI):帮助像素级注意模块(PLAM)----在半监督LViT设置下保持局部图像特征
- LV (Language-Vision)损失被设计用来直接使用文本信息监督未标记图像的训练
- 构建了包含x射线和CT图像的三个多模态医学分割数据集(图像+文本)
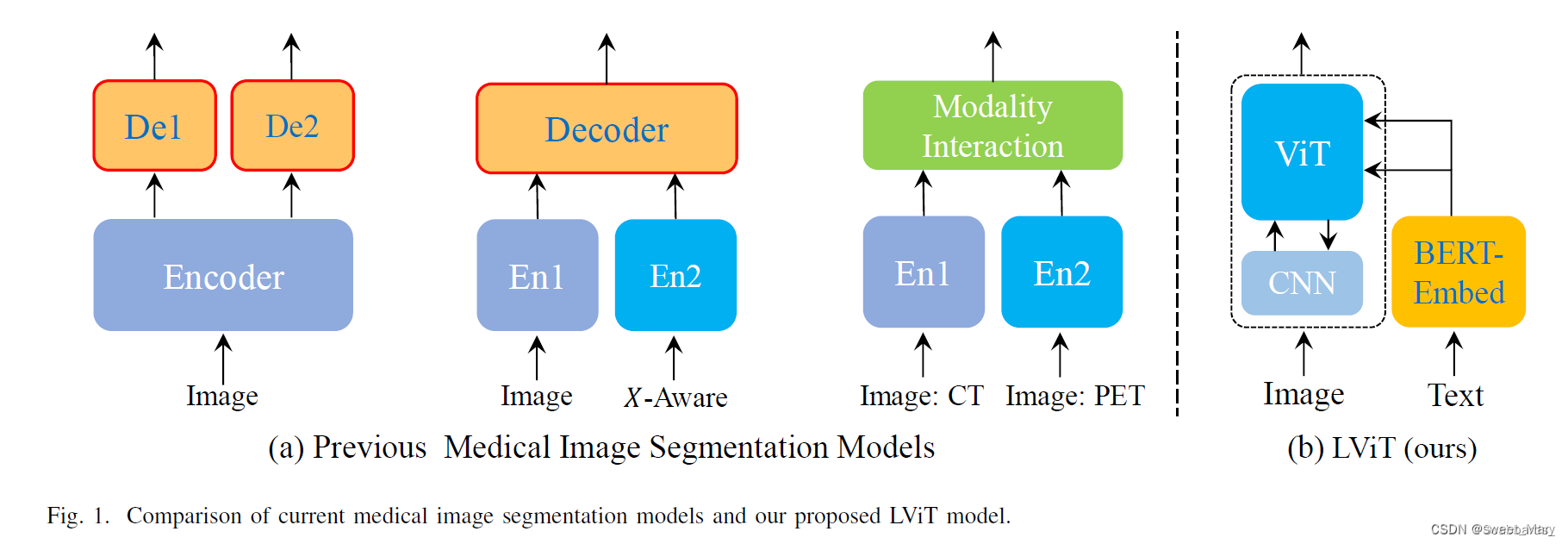
- 模型
- CNN (卷积神经网络):处理输入的图像,提取局部特征。
- ViT (视觉Transformer):利用Transformer结构,处理从CNN提取的特征,并结合来自文本嵌入的特征。
- BERT-Embed (BERT嵌入):利用BERT模型对输入的文本进行嵌入,提取语义信息。
- 如何利用已有的图像-文本信息提高分割性能
- 使用嵌入层代替文本编码器获得文本特征向量(减少模型中参数的数量)
- 具有像素级注意模块(PLAM)的混合CNNTransformer结构能够更好地合并文本信息(CNN:局部特征;transformer:全局特征)
- 如何充分利用文本信息,保证伪标签的质量
- 伪标签迭代机制(Exponential Pseudo label Iteration mechanism, EPI)
- 利用标记数据的标签信息和未标记数据的潜在信息
- EPI间接结合文本信息,以指数移动平均线(EMA)的方式逐步完善伪标签[10]
- LV (Language-Vision) loss的设计目的是直接利用文本信息来监督未标记医学图像的训练。
- 伪标签迭代机制(Exponential Pseudo label Iteration mechanism, EPI)
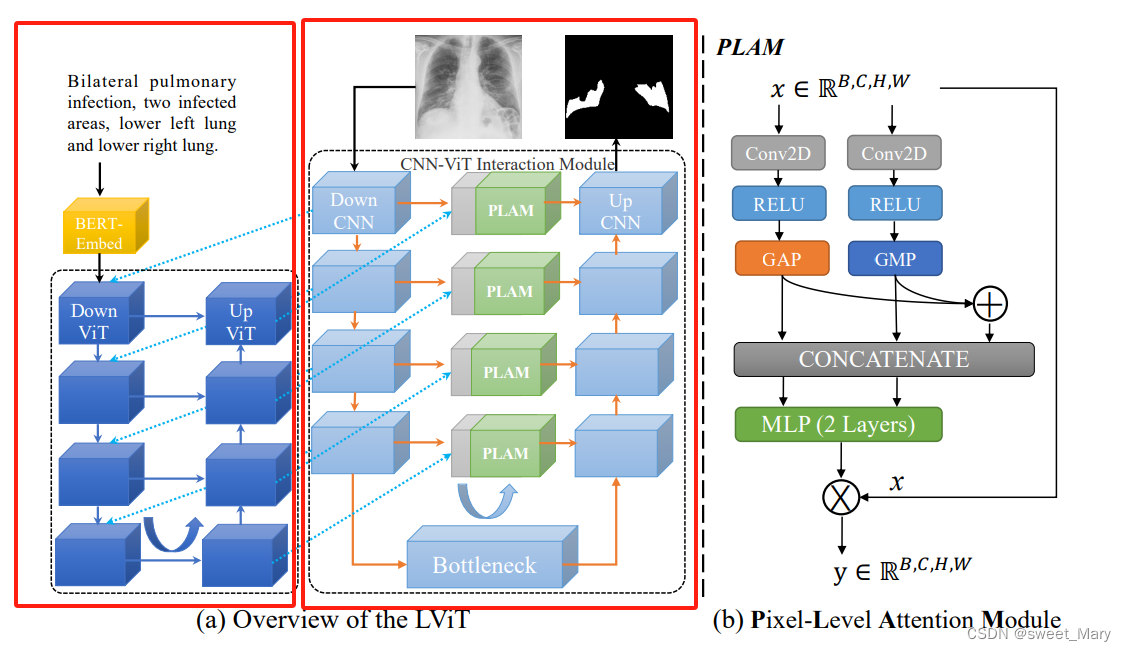
模型
双u型结构:u型CNN支路+u型Transformer支路
左面的红方框是Transformer支路,右面的红方框是CNN支路。
- CNN分支作为信息输入源和预测输出的分割头
- ViT分支用于图像和文本信息的合并(Transformer处理跨模态信息的能力)
- u型CNN分支的跳接位置设置一个像素级注意模块(PLAM)----保留图像的局部特征信息
U形CNN分支
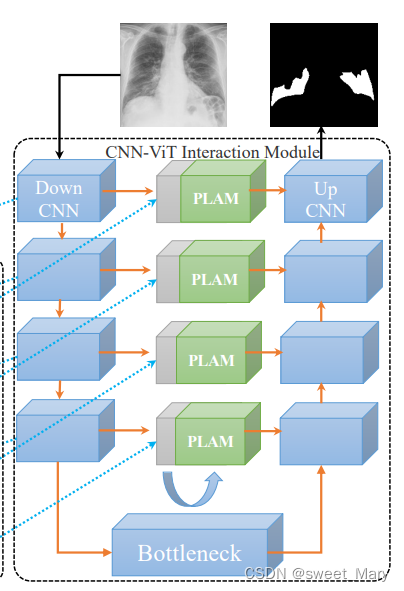
- 每个CNN模块:Conv、BatchNorm(BN)和ReLU激活层
- Maxpool对图像特征进行下采样(老规矩了)
- CNN-ViT交互模块:使用了上采样等方法来对齐来自ViT的特征。重构后的ViT特征通过残差与CNN特征连接,形成CNN-ViT交互特征。
- 提高局部特征的分割能力:跳接处设计了PLAM,将CNN-ViT交互特征输入到PLAM中,再将交互特征传递到UpCNN模块,逐层向上给出信息。
U形Vit分支

- 用于合并图像特征和文本特征
- 第一层DownViT模块接收BERT-Embed输入的文本特征和第一层DownCNN模块输入的图像特征。
- BERT-Embed的预训练模型是BERT_12_768_12模型,它可以将单个单词转换为768维的单词向量。
- 跨模态特征合并操作

- CTBN块还包括Conv层、BatchNorm层和ReLU激活层,用于对齐
、1和
的特征维度。
- ViT由多头自注意组成
- LN表示归一化层
- 第2层、第3层和第4层的后续DownViT模块既接收上层DownViT模块的特征,又接收相应层的DownCNN模块的特征
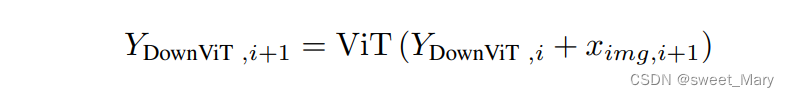
- CTBN块还包括Conv层、BatchNorm层和ReLU激活层,用于对齐
PLAM

- 旨在保留图像的局部特征,并进一步融合文本中的语义特征
- 并行分支:Global Average Pooling (GAP),Global Max Pooling (GMP)
- 加法操作:合并具有相似语义的相应通道特征并节省计算
- 连接操作:更直观地整合特征信息,并有助于保留每个部分的原始特征
- 使用MLP结构和乘法操作来帮助对齐特征大小
- PLAM通过增强局部特征来缓解Transformer带来的对全局特征的偏好
- PLAM采用通道注意和空间注意相结合的方式(我的理解是通道注意力机制:PLAM,空间注意力机制:Transformer)
指数伪标签迭代机制
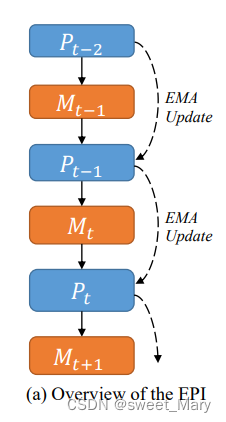

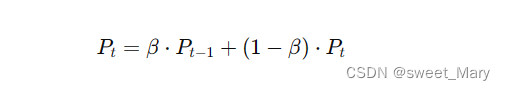
更新后的伪标签将用于无标签数据的训练,使得无标签数据可以像有标签数据一样为模型提供监督信息。这种方式能够有效利用大量的无标签数据,提高模型的泛化能力和鲁棒性。
-
初始生成:
- 使用有标签数据训练初始模型,生成伪标签。初始模型可以通过图中的Down CNN和Up CNN部分进行训练。
-
预测和更新:
- 在每一轮训练中,使用当前模型(例如图中的LViT模型)对无标签数据进行预测,生成新的伪标签。
- 通过EPI机制更新伪标签,逐步提高其质量。这一过程在图中没有具体表示,但它是数据处理的一部分。
-
再训练:
- 使用更新后的伪标签对模型进行再训练。模型结构可以包括图中的Down ViT和Up ViT部分,以及中间的PLAM模块。
LV (Language-Vision) Loss
- 结构化的文本信息来形成相应的掩码(对比标签)
- 计算文本之间的余弦相似度
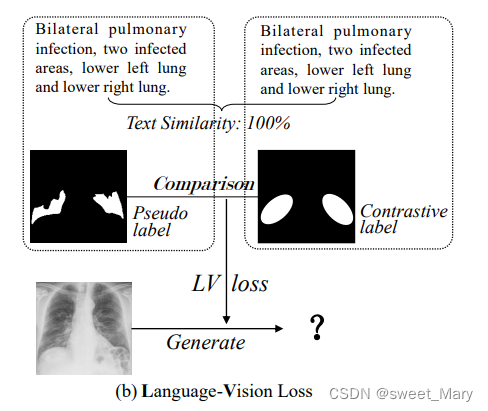
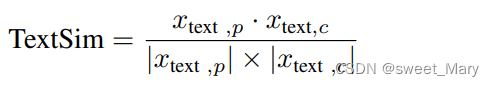
表示伪标签对应的文本特征向量
表示对比标签对应的文本特征向量