楼赛 第30期 Python 模块大比拼
提取电影信息
介绍
JSON(JavaScript Object Notation, /ˈdʒeɪsən/)是一种轻量级的数据交换格式,最初是作为 JavaScript 的子集被发明的,但目前已独立于编程语言之外,成为了通用的数据格式,绝大部分编程语言都有专门处理 JSON 数据的函数或工具。
目标
实验环境中,/home/project 目录下有一个包含 100 部电影信息的 JSON 文件 movies.json,每个电影信息的结构如下:
{
"id": 1,
"name": "霸王别姬",
"alias": "Farewell My Concubine",
"categories": [
"剧情",
"爱情"
],
"published_at": "1993-07-26",
"minute": 171,
"score": 9.5,
"regions": [
"中国内地",
"中国香港"
]
}
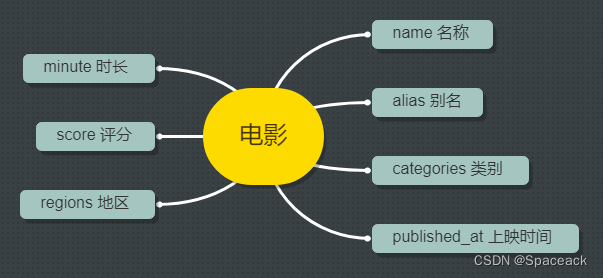
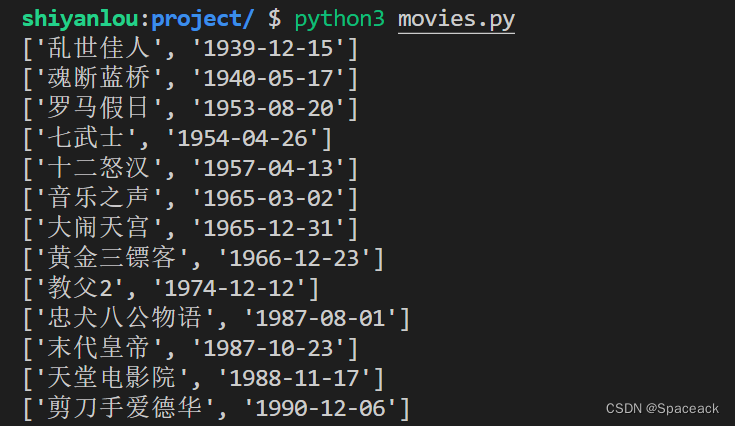
本节挑战,我们需要从 JSON 文件中提取出电影的名称和上映时间,然后按照电影上映日期升序打印输出(输出效果参考要求)。
### 要求
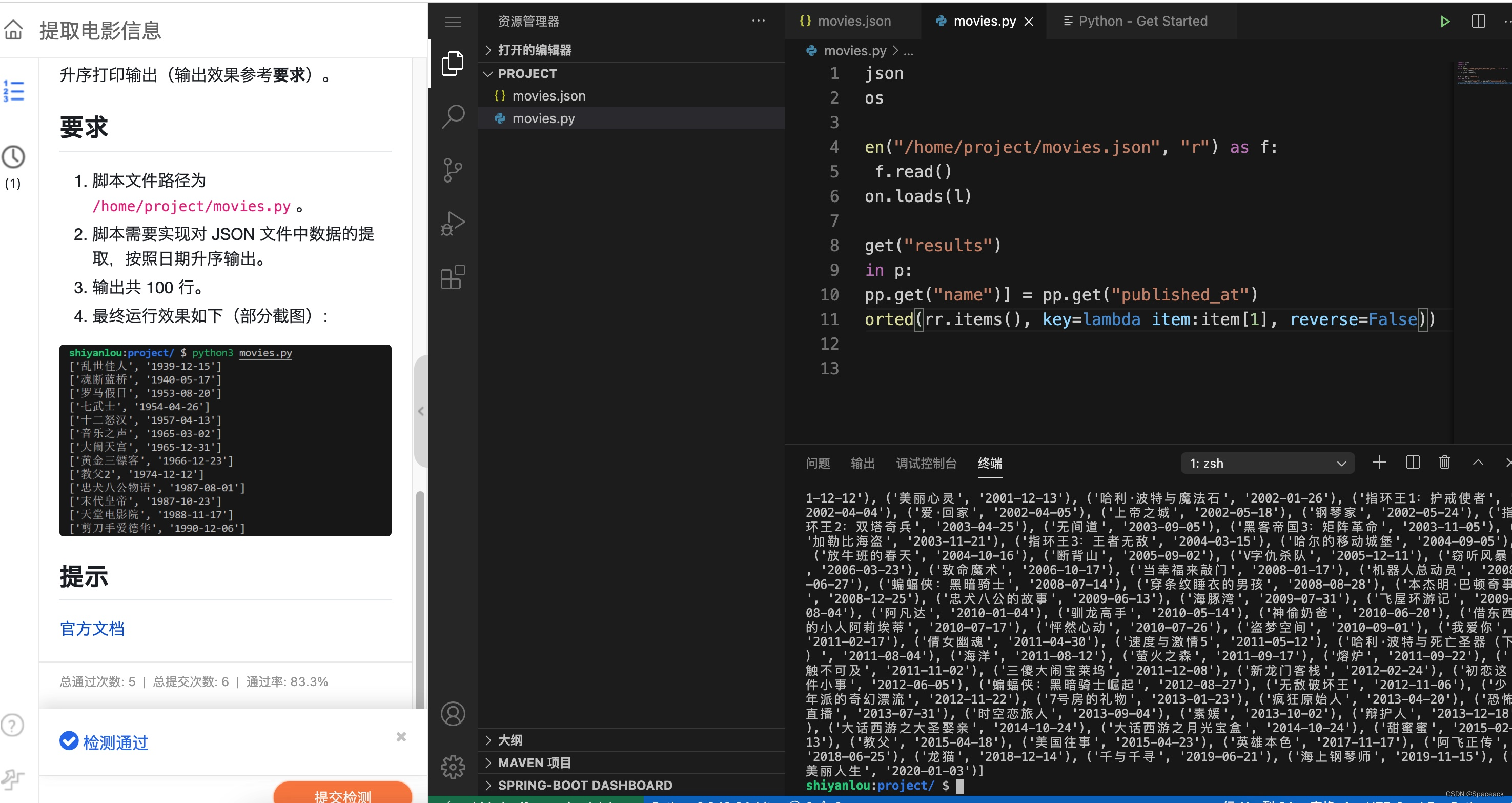
1. 脚本文件路径为 /home/project/movies.py 。
2. 脚本需要实现对 JSON 文件中数据的提取,按照日期升序输出。
3. 输出共 100 行。
4. 最终运行效果如下(部分截图):
### 题解:
```python
import json
import os
rr = {}
with open("/home/project/movies.json", "r") as f:
l = f.read()
ll = json.loads(l)
p = ll.get("results")
for pp in p:
rr[pp.get("name")] = pp.get("published_at")
print(sorted(rr.items(), key=lambda item:item[1], reverse=False))