aiohttp异步爬虫实战
- 1. 案例介绍
- 2. 准备工作
- 3. 页面分析
- 4. 实现思路
- 5. 基本配置
- 6. 爬取列表页
- 7. 爬取详情页
- 8. 总结
1. 案例介绍
- 本例要爬取的网站是https://spa5.scrape.center/,数据量相对大,所以用到了异步爬虫,主要学习这种方法是如何提高效率的。网站界面如图。
- 居然有500多页,老师辛苦了。
- 这是一个图书网站,里面包含数千条图书信息,网站数据是JavaScript渲染而得。数据可以通过Ajax接口获取,并且为了学习用,接口没有设置任何措施和加密参数。也是因为这个网站数据量大,才更适合做异步爬取。
- 本节我们要完成的目标:
- 🍏 使用aiohttp爬取全栈的图书数据。
- 🍏 将数据通过异步的方式保存到MongoDB中。
2. 准备工作
- 开始完成本节任务前,要有做如下准备。
- 安装好了Python3.7以上。
- 了解Ajax爬取的知识。
- 了解异步爬虫的知识和asyncio库的用法。
- 了解aiohttp库的用法。
- 安装并运行了MongoDB数据库,并安装了异步爬虫库motor。
3. 页面分析
-
前面学习了Ajax的方法,按照同样的逻辑,我们分析本站的情况。
-
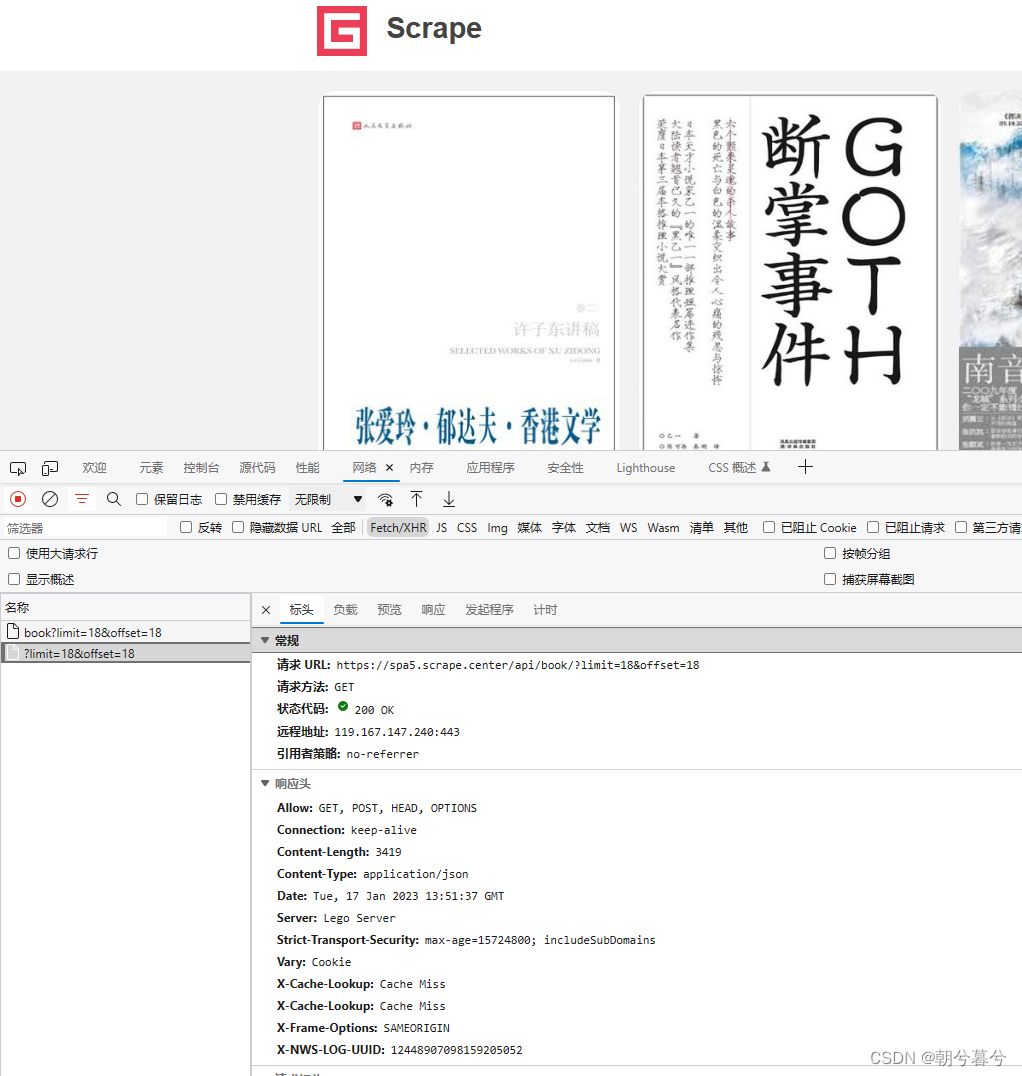
列表页的Ajax请求地址格式为https://spa5.scrape.center/api/book/?limit=18&offset={offset}。其中limit的值是每页包含的书的数量;offset的值是换页之后的增量值。计算公式为offset = limit*(page-1)。如下图。
-
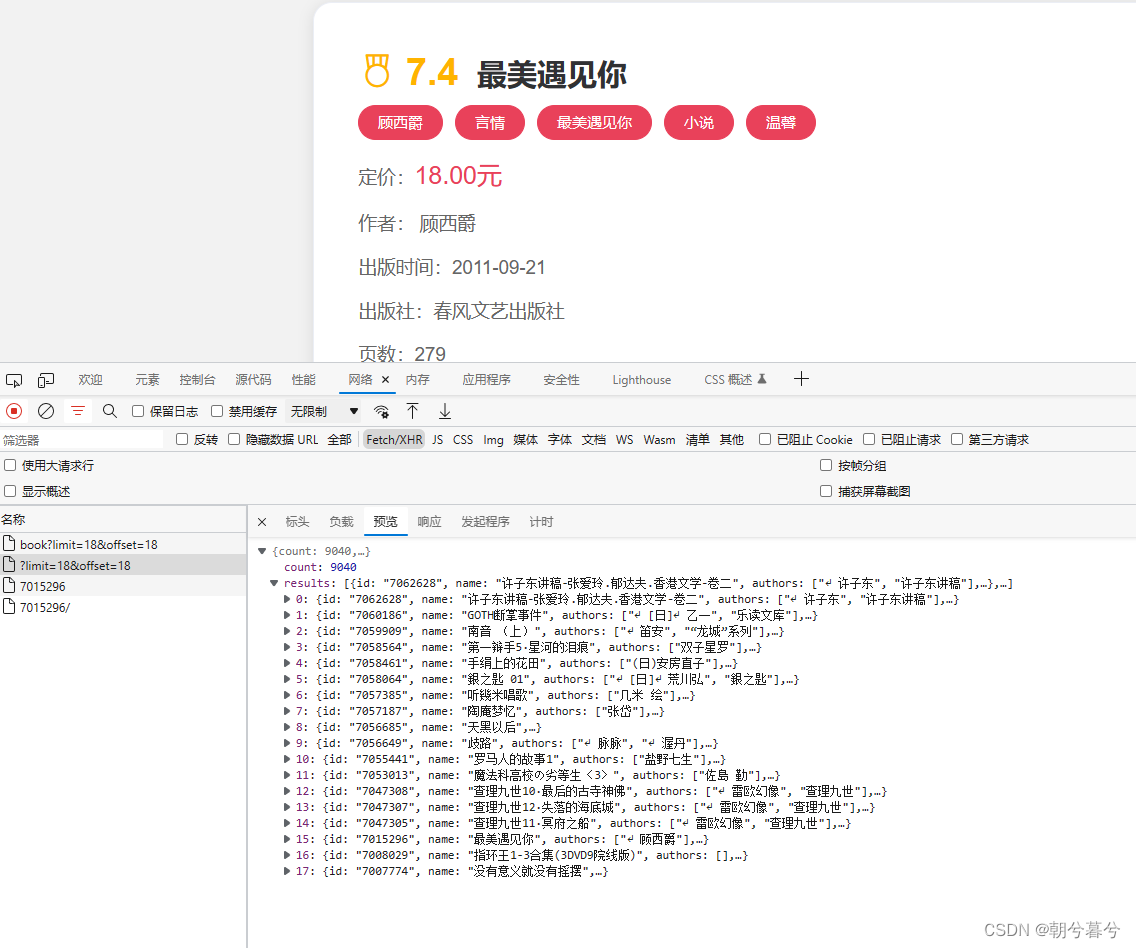
在列表页Ajax接口返回的数据里,results字段包含当前页里18本图书的信息。
-
其中每本书的数据里面包含一个id字段,这个id字段就是图书本身的ID,可以用来进一步请求详情页。如下图。
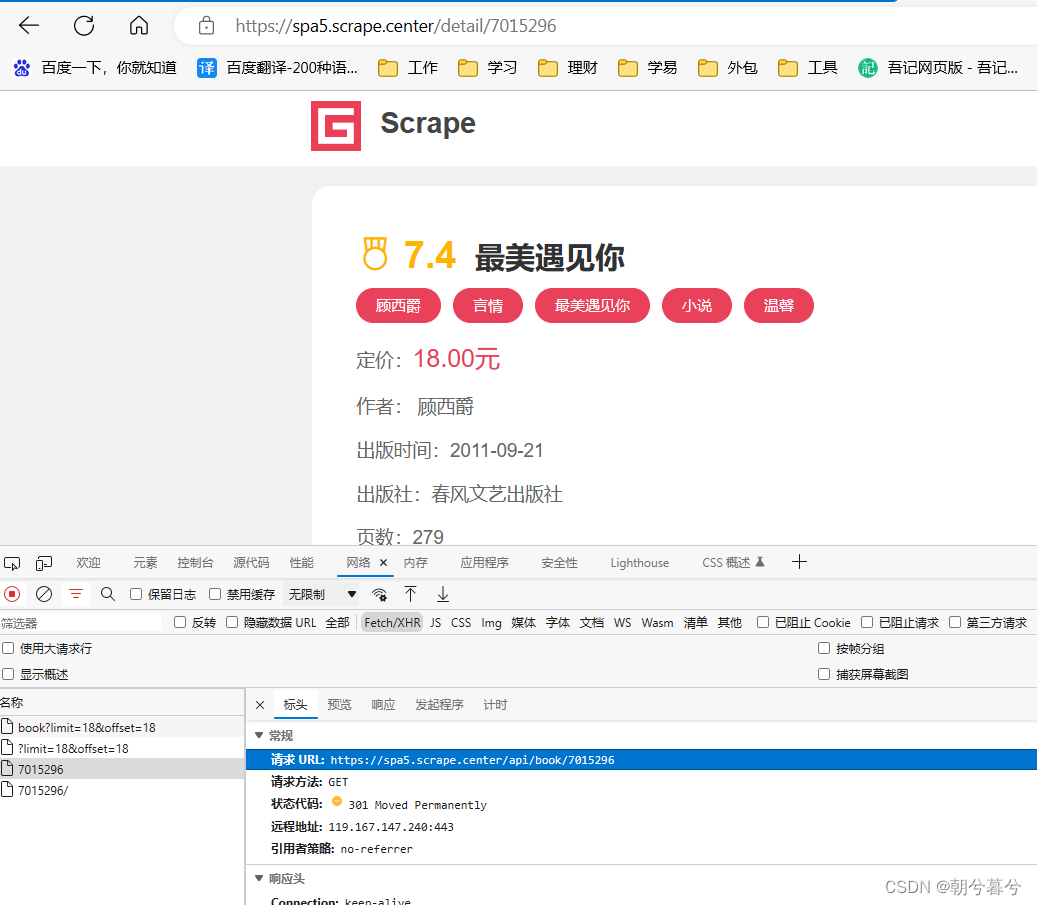
-
因此,详情页的Ajax请求地址格式为https://spa5.scrape.center/api/book/{id}。其中的id即为详情页对应图书的ID,可以从列表页Ajax接口的返回结果中获取内容。
4. 实现思路
- 一个完善的异步爬虫应该能够充分利用等待的时间进行最大并发量的爬取处理。
- 这里我们相实现的相对简单,分为两部分:(1)爬取列表页(2)爬取详情页。具体如下:
- 第一步,异步爬取所有列表页,再把这些列表页作为列表,形成一个task,再进行异步爬取。
- 第二步,把上面所有列表页的内容解析,找到所有的详情页的信息,再把这些详情页的信息作为列表,形成一个task,再进行异步爬取,并把结果放入MongoDB数据库中。
5. 基本配置
- 首先,先配置一些基本的变量并引入一些必需的库,代码如下:
import asyncio
import aiohttp
import logging
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s:%(message)s')
INDEX_URL = 'https://spa5.scrape.center/api/book/?limit=18&offset={offset}'
DETAIL_URL = 'https://spa5.scrape.center/api/book/{id}'
PAGE_SIZE = 18
PAGE_NUMBER = 100
CONCURRENCY = 5
- 这里我们导入了asyncio、aiohttp、logging三个库然后定义了logging在基本配置,接着定义了URL、当前页面中的元素PAGE_SIZE 、数量爬取页码数量PAGE_NUMBER 、并发量CONCURRENCY 等信息。
6. 爬取列表页
- 第一阶段,先爬取列表页。
- 先定义一个通用的爬取方法。代码如下:
""" 爬取列表页"""
# 设定一个并发限制,信号量为5
semaphore = asyncio.Semaphore(CONCURRENCY)
session = None
# 定义一个函数,引入信号量
async def scrape_api(url):
async with semaphore:
try:
logging.info('scraping %s', url)
# 调用session的get方法,返回json格式的数据
async with session.get(url) as response:
return await response.json()
except aiohttp.ClientError:
logging.error('error occurred while scraping %s',
url, exc_info=True)
- 这里声明一个并发量,用来控制最大并发量。
- 接着,定义了scrape_api方法,接收一个参数url。该方法首先使用async with语句引入信号量(并发量)作为上下文,接着调用session的get方法请求这个url,然后返回响应的JSON格式的结果。另外,这里还进行了异常处理,捕获了ClientError,如果出现错误,就会输出异常信息。
- 然后,爬取列表页,实现代码如下:
# 定义爬取列表页的函数
async def scrape_index(page):
url = INDEX_URL.format(offset=PAGE_SIZE * (page-1))
return await scrape_api(url)
- 显然,这里定义的scrape_index方法接收一个参数page,用于爬取列表页。先构造完整的url,再传给上面的scrape_api函数。这里面再次用async定义为异步方法,而且返回时调用scrape_api方法前面再加await,是因为scrape_api调用之后,会返回一个协程对象,它的作用就是暂时等待。最后的结果JSON格式,也是我们想要的。
- 接下来,我们定义main方法。
async def main():
global session
session = aiohttp.ClientSession()
scrape_index_tasks = [asyncio.ensure_future(
scrape_index(page)) for page in range(1, PAGE_NUMBER + 1)]
results = await asyncio.gather(*scrape_index_tasks)
logging.info('results %s', json.dumps(
results, ensure_ascii=False, indent=2))
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())
- 这里定义的scrape_index_tasks,是用于爬取列表页的所有task完成的JSON结果集组成的列表。然后调用asyncio的gather(聚集)方法,将这个task列表作为其参数,将结果赋值给results,那么这个results最后再由主入口程序中的loop对象的run_until_complete方法注册到事件循环,启动完成。
- main方法中,用全局变量声明了session变量,方便使用。
- 把上面代码全部放入一个py文件中执行,在VSCode中,发现一个问题。如图。
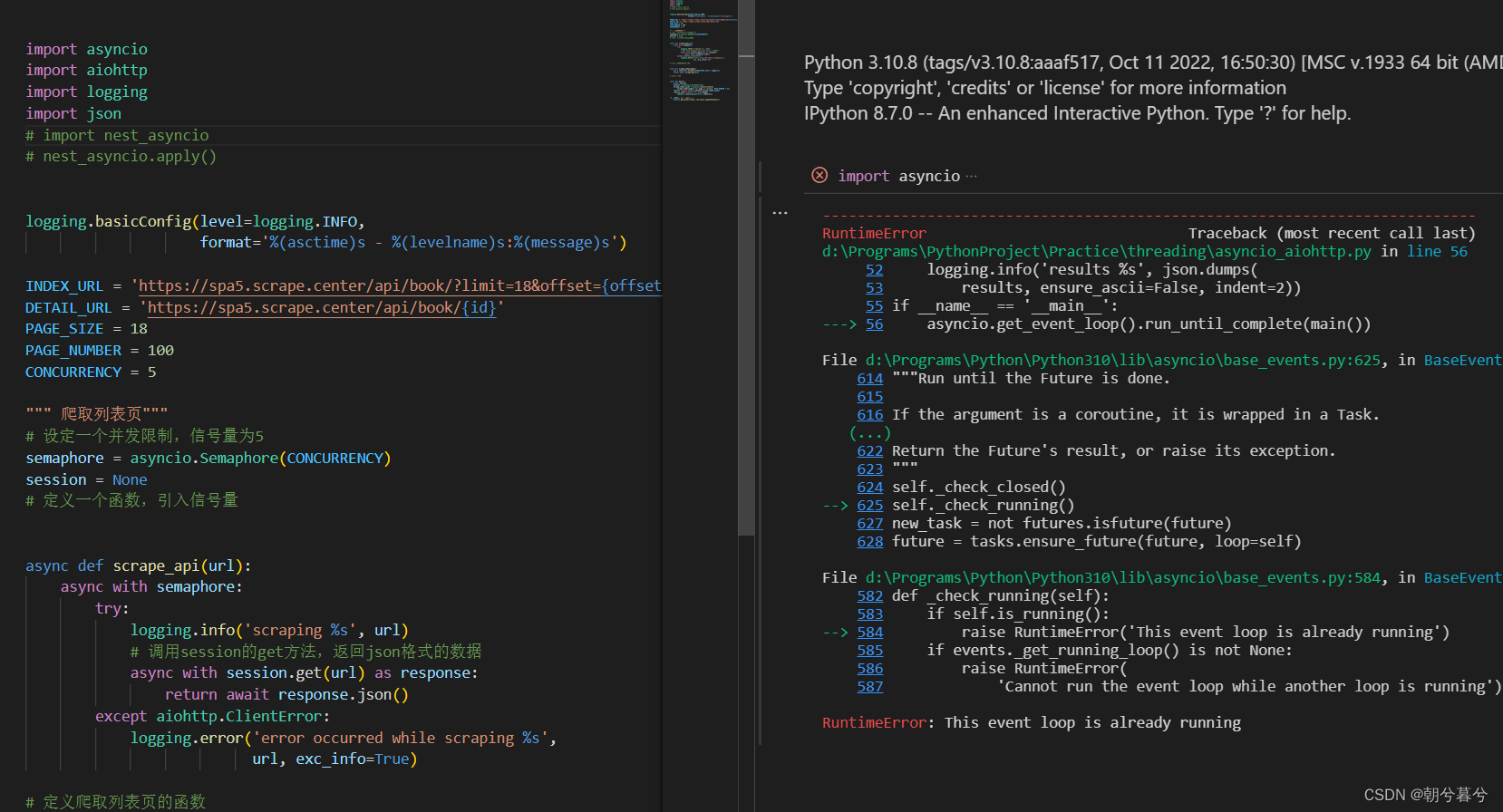
- 搜索了下百度,找到了答案。说是VScode调试Runtime error报错是因为解释器里面已经有loop循环事件。所以把上面
import nest_asyncio
nest_asyncio.apply()
- 这两行加入,就解决了。
- 运行结果如下:
PS D:\Programs\PythonProject\Practice\threading> & D:/Programs/Python/Python310/python.exe d:/Programs/PythonProject/Practice/threading/asyncio_aiohttp.py
2023-01-17 22:54:38,037 - INFO:scraping https://spa5.scrape.center/api/book/?limit=18&offset=0
2023-01-17 22:54:38,063 - INFO:scraping https://spa5.scrape.center/api/book/?limit=18&offset=18
2023-01-17 22:54:38,063 - INFO:scraping https://spa5.scrape.center/api/book/?limit=18&offset=36
2023-01-17 22:54:38,064 - INFO:scraping https://spa5.scrape.center/api/book/?limit=18&offset=54
2023-01-17 22:54:38,064 - INFO:scraping https://spa5.scrape.center/api/book/?limit=18&offset=72
2023-01-17 22:54:38,537 - INFO:scraping https://spa5.scrape.center/api/book/?limit=18&offset=90
2023-01-17 22:54:39,161 - INFO:scraping https://spa5.scrape.center/api/book/?limit=18&offset=108
2023-01-17 22:54:39,177 - INFO:scraping https://spa5.scrape.center/api/book/?limit=18&offset=126
2023-01-17 22:54:39,472 - INFO:scraping https://spa5.scrape.center/api/book/?limit=18&offset=144
2023-01-17 22:54:40,067 - INFO:scraping https://spa5.scrape.center/api/book/?limit=18&offset=162
2023-01-17 22:54:40,077 - INFO:scraping https://spa5.scrape.center/api/book/?limit=18&offset=180
2023-01-17 22:54:40,668 - INFO:scraping https://spa5.scrape.center/api/book/?limit=18&offset=198
2023-01-17 22:54:40,676 - INFO:scraping https://spa5.scrape.center/api/book/?limit=18&offset=216
2023-01-17 22:54:41,173 - INFO:scraping https://spa5.scrape.center/api/book/?limit=18&offset=234
2023-01-17 22:54:41,672 - INFO:scraping https://spa5.scrape.center/api/book/?limit=18&offset=252
2023-01-17 22:54:42,064 - INFO:scraping https://spa5.scrape.center/api/book/?limit=18&offset=270
2023-01-17 22:54:42,073 - INFO:scraping https://spa5.scrape.center/api/book/?limit=18&offset=288
………………
7. 爬取详情页
- 第二阶段,再爬取详情页,并保存数据。
- 在main方法里面加入解析功能的代码。
ids = []
for index_data in results:
if not index_data:continue
# 因为都是json数据,所以以键取值
for item in index_data.get('results'):
ids.append(item.get('id'))
- 得到所有的id以后,就可以构造详情页的地址,从而形成对应的task,再进行异步爬取。
- 这里再定义两个方法,用于爬取详情页。如下:
from motor.motor_asyncio import AsyncIOMotorClient
MONGO_CONNECTION_STRING = 'MongoDB://localhost:27017'
MONGO_DB_NAME = 'scrape_book'
MONGO_COLLECTION_NAME = 'books'
client = AsyncIOMotorClient(MONGO_CONNECTION_STRING)
db = client(MONGO_DB_NAME)
collection = db[MONGO_COLLECTION_NAME]
async def save_data(data):
logging.info('saving data %s', data)
if data:
return await collection.update_one({
'id' : data.get('id')
},{
'$set' : data
}, upsert=True)
async def scrape_detail(id):
url = DETAIL_URL.format(id=id)
data = await scrape_api(url)
await save_data(data)
- 这里定义了scrape_detail方法用于爬取详情页数据,并调用save_data方保存到MongoDB里面。
- 这里用到了支持异步的MongoDB存储库motor。motor的声明和pymongo类似,不过方法是异步方法。
- 接着,再在main方法里面加入对scrape_detail的调用,完成详情页的爬取。代码如下 。
# 加入对scrape_detail方法的调用,用来爬取详情页,并保存到数据库
scrape_detail_tasks = [asyncio.ensure_future(scrape_detail(id)) for id in ids]
await asyncio.wait(scrape_detail_tasks)
await session.close()
8. 总结
- 结论就是,在爬取数据量大的网站时,优先使用异步爬虫。