框架简介
WebMagic是一个基于Java的开源网络爬虫框架,它提供了很多简单易用的API接口,可以帮助使用者快速构建出高效、可扩展的网络爬虫程序,WebMagic由四个组件(Downloader、PageProcessor、Scheduler、Pipeline)构成,核心代码非常简单,主要是将这些组件结合并完成多线程的任务
WebMagic的结构分为Downloader、PageProcessor、Scheduler、Pipeline四大组件,并由Spider将它们彼此组织起来。这四大组件对应爬虫生命周期中的下载、处理、管理和持久化等功能。WebMagic的设计参考了Scapy,但是实现方式更Java化一些。
而Spider则将这几个组件组织起来,让它们可以互相交互,流程化的执行,可以认为Spider是一个大的容器,它也是WebMagic逻辑的核心。
爬取时的主要流程:
- 首先初始化Spider,设置初始url地址,并注册PageProcessor和其他配置,随后Spider从Scheduler中取出一个待抓取的URL,
- Downloader根据该URL发起HTTP请求,获取网页内容并生成一个`ResultItems`对象和对应的`Request`对象。
- 再PageProcessor处理该`Request`对象,抽取数据并填充到`ResultItems`中,同时可能会发现新的链接并添加到Scheduler中。
- 抽取后的结果通过Pipeline传递出去,进行持久化或其他处理。
- 循环继续,直到Scheduler中的URL被全部抓取完毕,或者达到预设的抓取条件。
过多的就不介绍了,对框架感兴趣强烈推荐去看框架的官方文档
Introduction · WebMagic Documents
爬取网站信息
爬取内容
我本人是河北大学的学生,因此这里就爬取本校官网上的一个新闻板块——河大要闻。
页面如下:

该页面下有多个新闻,点进去之后可以看到新闻的详细信息。例如:
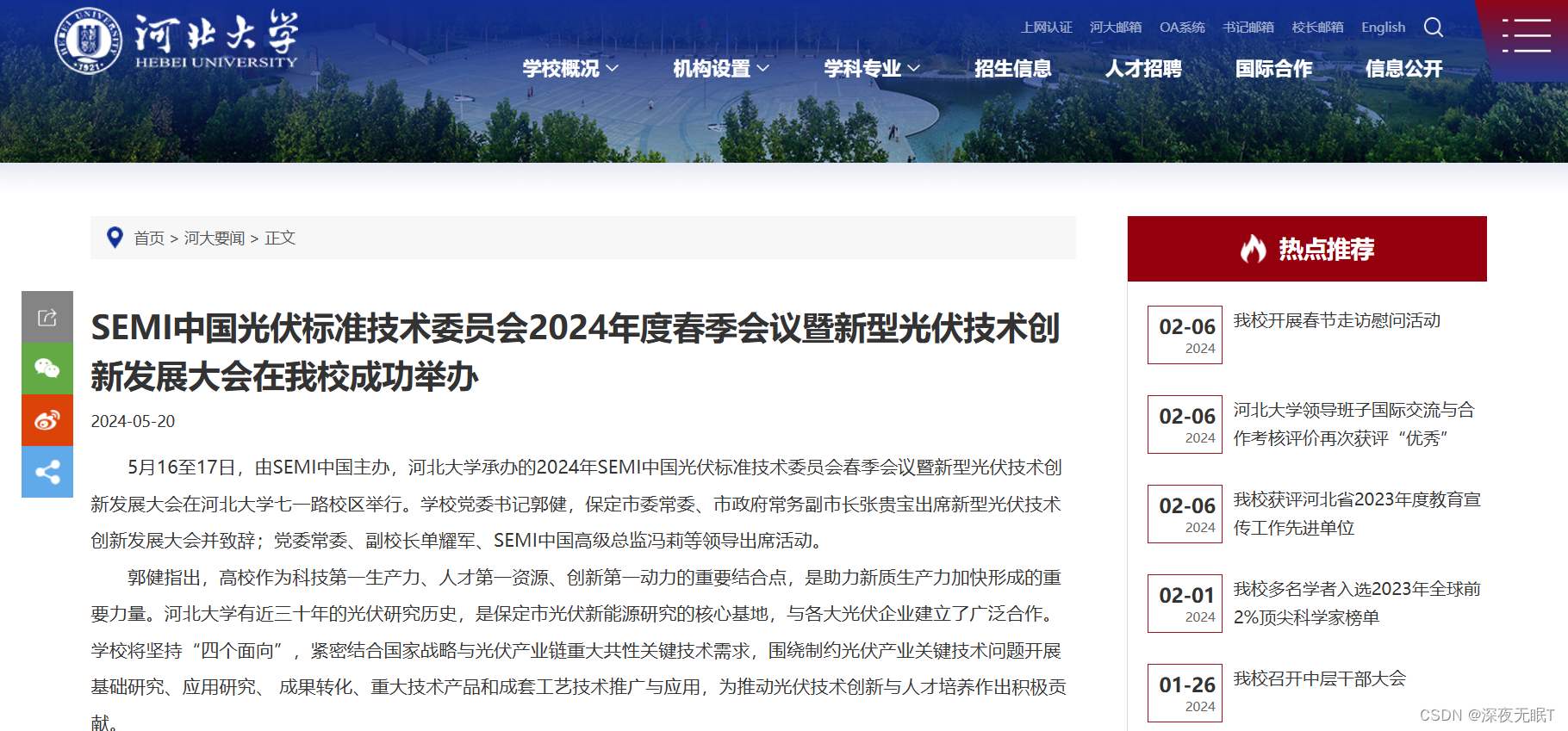
因此我想要爬取该模块内的所有新闻的详细信息,包括新闻的标题,时间,以及内容。
具体实现
基础配置我们直接略过,来看代码如何实现?
首先创建一个HBUNew类,让其实习PageProcessor接口,并实现其全部方法。
这里的setRetryTimes(4).setSleepTime(500)是指下载的尝试次数,一次下载失败会重新尝试,并设置每次爬取的时间间隔,这里设置的每0.5秒爬取一次。
public class HBUNew implements PageProcessor {
private Site site = Site.me().setRetryTimes(4).setSleepTime(500);
@Override
public void process(Page page) {
}
public Site getSite() {
return site;
}
public static void main(String[] args) {
}
}
接下来编写process方法,用来抽取所有我们想要的信息。
具体代码如下:
public void process(Page page) {
if (!page.getUrl().regex("https://www.hbu.edu.cn/info.*").match()) {
//获取新闻URL
List<String> all = page.getHtml().xpath("/html/body/div[@class='g-row']/div[1]/div[@class='col_r']/ul[@class='ul-study']/li/a").links().all();
String nextPage = page.getHtml().xpath("/html/body/div[@class='g-row']/div[1]/div[@class='col_r']/div[@class='pb_sys_common pb_sys_normal pb_sys_style1']/span[2]/span[@class='p_next p_fun']/a").links().get();
all.add(nextPage);
//添加
page.addTargetRequests(all);
} else {//新闻详情页
String url = page.getUrl().toString();
String title = page.getHtml().xpath("/html/body/div[@class='g-row']/div[1]/div[@class='col-l']/form/div[1]/h1/text()").get();
String date = page.getHtml().xpath("/html/body/div[@class='g-row']/div[1]/div[@class='col-l']/form/div[1]/div[@class='date']/text()").get();
String content = page.getHtml().xpath("/html/body/div[@class='g-row']/div[1]/div[@class='col-l']/form/div[1]/div[@class='txt']/allText()").get();
//存储结果
page.putField("地址", url);
page.putField("标题", title);
page.putField("日期", date);
page.putField("内容", content);
}
}首先使用
page.getUrl().regex("https://www.hbu.edu.cn/info.*").match()判断当前页面的URL是否与指定的正则表达式匹配。如果不匹配,则表示该页面不是目标新闻页面,而是列表页面。
如果是列表页那就使用xpath()方法获取该页中的所有详细页地址和下一页地址用来找到下一页。
详细页地址:

下一页地址:

如果是详细页依旧是使用Xpath来获取页面内的信息

最后在主方法中创建Spider,添加初始地址,并添加自定义的Pipeline,让其结果以json文件的形式储存在HBUnews文件夹下。
public static void main(String[] args) {
Spider.create(new HBUNew())
//初始访问url地址
.addUrl("https://www.hbu.edu.cn/index/hdyw1.htm")
.setDownloader(new HttpClientDownloader())
.addPipeline(new JsonFilePipeline("HBUnews/"))
.thread(5)
.run();
}结果展示
最后结果全部在HBUnews文件下

文件内容如下:可以看到成功爬取到了所有的新闻信息。