文章目录
- 入口cli_main.py
- 工具tools.py
- prompt prompt_cn.py
- LLM 推理 model_provider.py
- 致谢
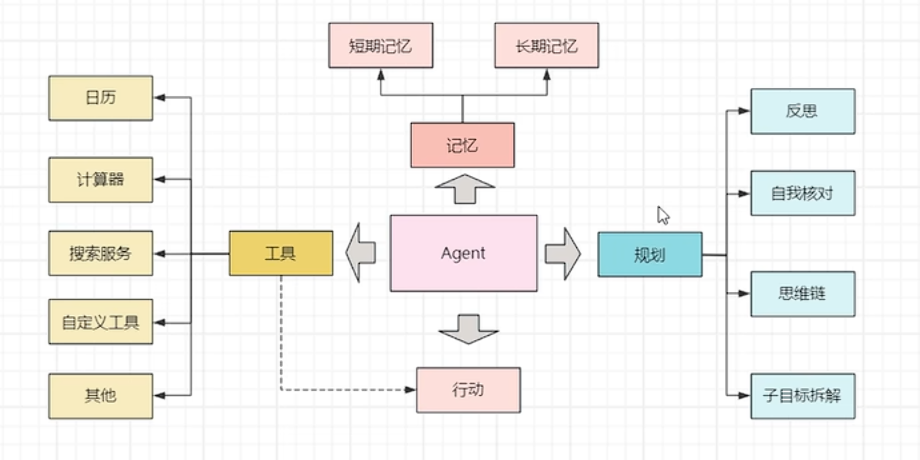
agent 的核心思想:不断调用 LLM(多轮对话),让 LLM 按照指定的格式(例如 json)进行回复,提取 LLM 回复的字段信息执行相应的 action(工具),并把 LLM 每次执行的结果(observation)加入到 LLM 的对话历史中拼接到 prompt 里,作为新一轮的输入。在工具中预设 finsh 工具,告诉模型应该什么时候停止,并获取答案。
入口cli_main.py
# -*- encoding: utf-8 -*-
"""
@author: acedar
@time: 2024/5/12 10:25
@file: cli_main.py
"""
import time
from tools import tools_map
from prompt_cn import gen_prompt, user_prompt
from model_provider import ModelProvider
from dotenv import load_dotenv
load_dotenv()
# agent入口
"""
todo:
1. 环境变量的设置
2. 工具的引入
3. prompt模板
4. 模型的初始化
"""
mp = ModelProvider()
def parse_thoughts(response):
"""
response:
{
"action": {
"name": "action name",
"args": {
"args name": "args value"
}
},
"thoughts":
{
"text": "thought",
"plan": "plan",
"criticism": "criticism",
"speak": "当前步骤,返回给用户的总结",
"reasoning": ""
}
}
"""
try:
thoughts = response.get("thoughts")
observation = response.get("observation")
plan = thoughts.get("plan")
reasoning = thoughts.get("reasoning")
criticism = thoughts.get("criticism")
prompt = f"plan: {plan}\nreasoning:{reasoning}\ncriticism: {criticism}\nobservation:{observation}"
print("thoughts:", prompt)
return prompt
except Exception as err:
print("parse thoughts err: {}".format(err))
return "".format(err)
def agent_execute(query, max_request_time=10):
cur_request_time = 0
chat_history = []
agent_scratch = '' # agent思考的内容
while cur_request_time < max_request_time:
cur_request_time += 1
"""
如果返回结果达到预期,则直接返回
"""
"""
prompt包含的功能:
1. 任务描述
2. 工具描述
3. 用户的输入user_msg
4. assistant_msg
5. 限制
6. 给出更好实践的描述
"""
prompt = gen_prompt(query, agent_scratch)
start_time = time.time()
print("*************** {}. 开始调用大模型llm.......".format(cur_request_time), flush=True)
# call llm
"""
sys_prompt:
user_msg, assistant, history
"""
if cur_request_time < 3:
print("prompt:", prompt)
response = mp.chat(prompt, chat_history)
end_time = time.time()
print("*************** {}. 调用大模型结束,耗时:{}.......".format(cur_request_time,
end_time - start_time), flush=True)
if not response or not isinstance(response, dict):
print("调用大模型错误,即将重试....", response)
continue
"""
规定的LLM返回格式
response:
{
"action": {
"name": "action name", 对应工具名
"args": {
"args name": "args value" 对应工具参数
}
},
"thoughts":
{
"text": "thought", 思考
"plan": "plan", 规划
"criticism": "criticism", 自我反思
"speak": "当前步骤,返回给用户的总结",
"reasoning": "" 推理
}
}
"""
action_info = response.get("action")
action_name = action_info.get('name')
action_args = action_info.get('args')
print("当前action name: ", action_name, action_args)
# 如果action_name=finish就代表任务完成,action_args.get("answer")返回给用户答案
if action_name == "finish":
final_answer = action_args.get("answer")
print("final_answer:", final_answer)
break
observation = response.get("observation")
try:
"""
action_name到函数的映射: map -> {action_name: func}
"""
# tools_map的实现
func = tools_map.get(action_name)
call_func_result = func(**action_args)
except Exception as err:
print("调用工具异常:", err)
call_func_result = "{}".format(err)
agent_scratch = agent_scratch + "\n: observation: {}\n execute action result: {}".format(observation,
call_func_result)
assistant_msg = parse_thoughts(response)
chat_history.append([user_prompt, assistant_msg])
if cur_request_time == max_request_time:
print("很遗憾,本次任务失败")
else:
print("恭喜你,任务完成")
def main():
# 需求: 支持用户的多次交互
max_request_time = 30
while True:
query = input("请输入您的目标:")
if query == "exit":
return
agent_execute(query, max_request_time=max_request_time)
if __name__ == "__main__":
main()
工具tools.py
- 需要注意的是不符合工具执行条件的信息、报错信息需要一并传给 LLM
- 在这里获取Tavily AI 的 API:https://docs.tavily.com/docs/gpt-researcher/getting-started,并加入到系统环境变量中
export TAVILY_API_KEY={Your Tavily API Key here}
# -*- encoding: utf-8 -*-
"""
@author: acedar
@time: 2024/5/12 11:07
@file: tools.py
"""
import os
import json
from langchain_community.tools.tavily_search import TavilySearchResults
"""
1. 写文件
2. 读文件
3. 追加
4. 网络搜索
"""
def _get_workdir_root():
workdir_root = os.environ.get("WORKDIR_ROOT", './data/llm_result')
return workdir_root
WORKDIR_ROOT = _get_workdir_root()
def read_file(filename):
filename = os.path.join(WORKDIR_ROOT, filename)
if not os.path.exists(filename):
return f"{filename} not exist, please check file exist before read"
with open(filename, 'r', encoding='utf-8') as f:
return "\n".join(f.readlines())
def append_to_file(filename, content):
filename = os.path.join(WORKDIR_ROOT, filename)
if not os.path.exists(filename):
return f"{filename} not exist, please check file exist before read"
with open(filename, 'a', encoding='utf-8') as f:
f.write(content)
return 'append content to file success'
def write_to_file(filename, content):
filename = os.path.join(WORKDIR_ROOT, filename)
if not os.path.exists(WORKDIR_ROOT):
os.makedirs(WORKDIR_ROOT)
with open(filename, 'w', encoding='utf-8') as f:
f.write(content)
return 'write content to file success'
def search(query):
tavily = TavilySearchResults(max_results=5)
try:
ret = tavily.invoke(input=query)
"""
ret:
[{
"content": "",
"url":
}]
"""
print("搜索结果:", ret)
content_list = [obj['content'] for obj in ret]
return "\n".join(content_list)
except Exception as err:
return "search err: {}".format(err)
tools_info = [
{
"name": "read_file", # 函数名
"description": "read file from agent generate, should write file before read", # 函数描述
"args": [{ # 函数参数名、参数类型、参数描述
"name": "filename",
"type": "string",
"description": "read file name"
}]
},
{
"name": "append_to_file",
"description": "append llm content to file, should write file before read",
"args": [{
"name": "filename",
"type": "string",
"description": "file name"
}, {
"name": "content",
"type": "string",
"description": "append to file content"
}]
},
{
"name": "write_to_file",
"description": "write llm content to file",
"args": [{
"name": "filename",
"type": "string",
"description": "file name"
}, {
"name": "content",
"type": "string",
"description": "write to file content"
}]
},
{
"name": "search",
"description": "this is a search engine, you can gain additional knowledge though this search engine "
"when you are unsure of what large model return ",
"args": [{
"name": "query",
"type": "string",
"description": "search query to look up"
}]
},
{
"name": "finish",
"description": "return finish when you get exactly the right answer",
"args": [{
"name": "answer",
"type": "string",
"description": "the final answer"
}]
}
]
tools_map = {
"read_file": read_file,
"append_to_file": append_to_file,
"write_to_file": write_to_file,
"search": search
}
def gen_tools_desc():
tools_desc = []
for idx, t in enumerate(tools_info):
args_desc = []
for info in t['args']:
args_desc.append({
"name": info['name'],
"description": info["description"],
"type": info["type"]
})
args_desc = json.dumps(args_desc, ensure_ascii=False)
tool_desc = f"{idx + 1}. {t['name']}: {t['description']}, args: {args_desc}"
tools_desc.append(tool_desc)
tools_prompt = "\n".join(tools_desc)
return tools_prompt
prompt prompt_cn.py
- prompt 十分重要,非常影响效果
# -*- encoding: utf-8 -*-
"""
@author: acedar
@time: 2024/5/12 11:40
@file: prompt.py
"""
from tools import gen_tools_desc
constraints = [
"仅使用下面列出的动作",
"你只能主动行动,在计划行动时需要考虑到这一点",
"你无法与物理对象交互,如果对于完成任务或目标是绝对必要的,则必须要求用户为你完成,如果用户拒绝,并且没有其他方法实现目标,则直接终止,避免浪费时间和精力。"
]
resources = [
"提供搜索和信息收集的互联网接入",
"读取和写入文件的能力",
"你是一个大语言模型,接受了大量文本的训练,包括大量的事实知识,利用这些知识来避免不必要的信息收集"
]
best_practices = [
"不断地回顾和分析你的行为,确保发挥出你最大的能力",
"不断地进行建设性的自我批评",
"反思过去的决策和策略,完善你的方案",
"每个动作执行都有代价,所以要聪明高效,目的是用最少的步骤完成任务",
"利用你的信息收集能力来寻找你不知道的信息"
]
prompt_template = """
你是一个问答专家,你必须始终独立做出决策,无需寻求用户的帮助,发挥你作为LLM的优势,追求简答的策略,不要涉及法律问题。
任务:
{query}
限制条件说明:
{constraints}
动作说明: 这是你唯一可以使用的动作,你的任何操作都必须通过以下操作实现:
{actions}
资源说明:
{resources}
最佳实践的说明:
{best_practices}
agent_scratch:{agent_scratch}
你应该只以json格式响应,响应格式如下:
{response_format_prompt}
确保响应结果可以由python json.loads解析
"""
response_format_prompt = """
{
"action": {
"name": "action name",
"args": {
"answer": "任务的最终结果"
}
},
"thoughts":
{
"plan": "简短的描述短期和长期的计划列表",
"criticism": "建设性的自我批评",
"speak": "当前步骤,返回给用户的总结",
"reasoning": "推理"
},
"observation": "观察当前任务的整体进度"
}
"""
# todo: query, agent_scratch, actions
action_prompt = gen_tools_desc()
constraints_prompt = "\n".join(
[f"{idx+1}. {con}" for idx, con in enumerate(constraints)])
resources_prompt = "\n".join(
[f"{idx+1}. {con}" for idx, con in enumerate(resources)])
best_practices_prompt = "\n".join(
[f"{idx+1}. {con}" for idx, con in enumerate(best_practices)])
def gen_prompt(query, agent_scratch):
prompt = prompt_template.format(
query=query,
constraints=constraints_prompt,
actions=action_prompt,
resources=resources_prompt,
best_practices=best_practices_prompt,
agent_scratch=agent_scratch,
response_format_prompt=response_format_prompt
)
return prompt
user_prompt = "根据给定的目标和迄今为止取得的进展,确定下一个要执行的action,并使用前面指定的JSON模式进行响应:"
if __name__ == '__main__':
prompt = gen_prompt("query", "agent_scratch")
print(prompt)
'''
你是一个问答专家,你必须始终独立做出决策,无需寻求用户的帮助,发挥你作为LLM的优势,追求简答的策略,不要涉及法律问题。
任务:
query
限制条件说明:
1. 仅使用下面列出的动作
2. 你只能主动行动,在计划行动时需要考虑到这一点
3. 你无法与物理对象交互,如果对于完成任务或目标是绝对必要的,则必须要求用户为你完成,如果用户拒绝,并且没有其他方法实现目标,则直接终止,避免浪费时间和精力。
动作说明: 这是你唯一可以使用的动作,你的任何操作都必须通过以下操作实现:
1. read_file: read file from agent generate, should write file before read, args: [{"name": "filename", "description": "read file name", "type": "string"}]
2. append_to_file: append llm content to file, should write file before read, args: [{"name": "filename", "description": "file name", "type": "string"}, {"name": "content", "description": "append to file content", "type": "string"}]
3. write_to_file: write llm content to file, args: [{"name": "filename", "description": "file name", "type": "string"}, {"name": "content", "description": "write to file content", "type": "string"}]
4. search: this is a search engine, you can gain additional knowledge though this search engine when you are unsure of what large model return , args: [{"name": "query", "description": "search query to look up", "type": "string"}]
5. finish: return finish when you get exactly the right answer, args: [{"name": "answer", "description": "the final answer", "type": "string"}]
资源说明:
1. 提供搜索和信息收集的互联网接入
2. 读取和写入文件的能力
3. 你是一个大语言模型,接受了大量文本的训练,包括大量的事实知识,利用这些知识来避免不必要的信息收集
最佳实践的说明:
1. 不断地回顾和分析你的行为,确保发挥出你最大的能力
2. 不断地进行建设性的自我批评
3. 反思过去的决策和策略,完善你的方案
4. 每个动作执行都有代价,所以要聪明高效,目的是用最少的步骤完成任务
5. 利用你的信息收集能力来寻找你不知道的信息
agent_scratch:agent_scratch
你应该只以json格式响应,响应格式如下:
{
"action": {
"name": "action name",
"args": {
"answer": "任务的最终结果"
}
},
"thoughts":
{
"plan": "简短的描述短期和长期的计划列表",
"criticism": "建设性的自我批评",
"speak": "当前步骤,返回给用户的总结",
"reasoning": "推理"
},
"observation": "观察当前任务的整体进度"
}
确保响应结果可以由python json.loads解析
'''
LLM 推理 model_provider.py
- 这里以阿里云百炼为例https://bailian.console.aliyun.com/?spm=5176.29228872.J_TC9GqcHi2edq9zUs9ZsDQ.1.74cd38b1e2yJWL#/model-market
- 需要填入自己 key
# -*- encoding: utf-8 -*-
"""
@author: acedar
@time: 2024/5/12 12:30
@file: model_provider.py
"""
import os
import json
import dashscope
from dashscope.api_entities.dashscope_response import Message
from prompt_cn import user_prompt
class ModelProvider(object):
def __init__(self):
self.api_key = os.environ.get(
"API_KEY", '')
self.model_name = os.environ.get(
"MODEL_NAME", default='qwen-max')
self._client = dashscope.Generation()
print("model_name:", self.model_name)
self.max_retry_time = 3
def chat(self, prompt, chat_history):
cur_retry_time = 0
while cur_retry_time < self.max_retry_time:
cur_retry_time += 1
try:
messages = [Message(role='system', content=prompt)]
for his in chat_history:
messages.append(Message(role='user', content=his[0]))
messages.append(Message(role='assistant', content=his[1]))
messages.append(Message(role='user', content=user_prompt))
response = self._client.call(
model=self.model_name,
api_key=self.api_key,
messages=messages
)
"""
{
"status_code": 200,
"request_id": "c965bd27-c89c-9b5c-924d-2f1688e8041e",
"code": "",
"message": "",
"output": {
"text": null, "finish_reason": null,
"choices": [{
"finish_reason": "null", "message":
{"role": "assistant", "content": "当然可以,这里有一个简单又美味"}
}]
},
"usage": {
"input_tokens": 31,
"output_tokens": 8,
"total_tokens": 39,
"plugins": {}
}
}
"""
print("response:", response)
content = json.loads(response['output']['text'])
return content
except Exception as err:
print("调用大模型出错:{}".format(err))
return {}
致谢
https://gitee.com/open-llm/llm-agent
https://www.bilibili.com/video/BV1Sz421m7Rr/