前言:有幸能够收到一块梦寐以求的 AI 边缘计算开发板 OrangePi AIpro,非常感谢官方大大给予的宝贵机会。OrangePi AIpro是香橙派官方跟华为昇腾合作的新一代边缘计算产品,其使用华为昇腾 AI 技术路线,搭配集成图像处理器,拥有 8GB/16GB LPDDR4X,是一款非常优秀的 Artificial intelligence(AI) 开发板。 本篇博客将以 OrangePi AIpro 开发板进行全面测评与部署实战,希望帮助读者朋友去全面且深入了解这款强大的 AI 边缘计算开发板,加速推进 AI 部署国产化进程。
香橙派 AIpro实物:

香橙派 AIpro案例:

OrangePi AIpro资料推荐网址:
香橙派官网:香橙派(Orange Pi)-Orange Pi官网-香橙派开发板
昇腾官网:昇腾社区-官网丨昇腾万里 让智能无所不及 (hiascend.com)
一、香橙派 AIPro概述
1.1 香橙派 AIPro介绍
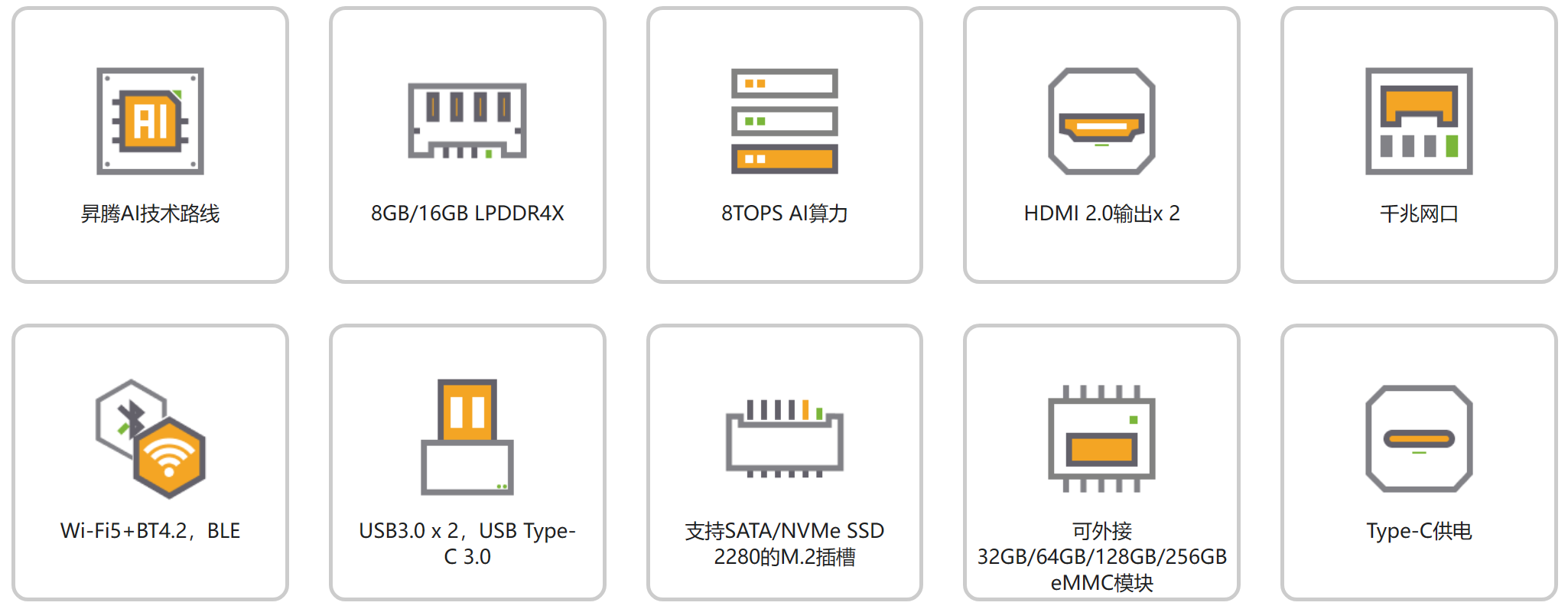
香橙派 AIpro是目前市场上首款搭载华为昇腾 AI 芯片的开发板,OrangePi AIpro拥有极佳的颜值与性能,其香橙派官方也给予了非常优秀的技术服务支持。搭载华为昇腾 AI 芯片的香橙派 AIpro拥有超强的 8/20 TOPS AI算力,能够满足各种人工智能算法部署的算力需求。8GB/16GB LPDDR4X 的运行内存,使得 OrangePi AIpro 可以满足长时间高性能的部署任务。其支持外接 32GB/64GB/128GB/256GB的 EMMC 模块,使得 OrangePi AIpro 满足超大数据与程序存储的需求。

OrangePi AIpro硬件总结:
1、CPU与AI算力:搭载 4 核 64 位处理器 + AI 处理器(华为自研的 Ascend310 芯片),提供 8/20TOPS 的AI算力,能够有效地加速目标识别、图像分类等 AI 应用。
2、内存和存储:支持 8/16GB LPDDR4X运行内存,并可以外接 32GB/64GB/128GB/256GB EMMC 模块。此外,香橙派AI Pro还支持 SATA/NVMe SSD 2280 的 M.2 插槽,提供更多的存储选项。
3、丰富的接口:包括两个 HDMI 输出、GPIO 接口、Type-C 电源接口、TF插槽、千兆网口、两个 USB3.0、一个 USB Type-C 3.0、一个 Micro USB(串口打印调试功能)、两个 MIPI 摄像头接口和一个 MIPI 屏接口。
4、操作系统支持:支持 Ubuntu 和 openEuler 操作系统,适合大多数AI算法原型验证和推理应用开发。
5、应用场景:适用于 AI 边缘计算、深度视觉学习、视频流 AI 分析、自然语言处理、智能小车、机械臂、人工智能、无人机、云计算、AR/VR、智能安防、智能家居等领域。
6、配套开发工具:提供 MindStudio 全流程开发工具链,以及一键镜像烧录工具和模型适配工具,方便开发者快速上手和使用。
1.2 香橙派 AIpro算力评估
算力测试:作者分别使用 ResNet50 和 Yolov8n 进行实验,这两种神经网络模型是图像识别和目标检测的热门模型。并分别在两台机器上部署 “INT8 量化的模型”,测试 NPU 的性能差异。此外还请出了 NVIDIA 的非常优秀的显卡产品 RTX2060,4年前的产品。如今NVIDIA RTX2060 在二级市场的售价与 香橙派 AIpro & RK3588 价值相当。

Artificial intelligence 模型推断速度:
| 香橙派 AIpro | RK3588 | RK3588(多任务) | RTX2060 | |
| 推理平台 | MindX(INT8) | RKNN(INT8) | RKNN | Tensorrt(fp16) |
| NPU调用 | - | 第1个核心 | 3个核心 | - |
| 进程数 | 1 | 1 | 3进程任务分配 | 1 |
| ResNet50速度 | 291 | 110 | 307 | 1034 |
| Yolov8n速度 | 87 | 21 | 67 | 652 |
算力测试概述:
- 单任务场景下(用户一般场景),香橙派 AIpro 都比 RK3588 更快。此时 RK3588 只有 1 个 NPU 核心在运行。ResNet50 推断中,香橙派 AIpro 是 2.7x 速度提升;YOLOv8n 是 3.9x 速度提升(RK3588的单核心只有最高 2TOPS 算力)。
- 任务可以并行的情况,香橙派 AIpro 和 RK3588 各有胜负。RK3588 的 3 个 NPU 都充分利用。RK3588 在 Resnet50 中稍快,香橙派AI Pro在 YOLOv8n 快的更明显。
- YOLOv8n 的模型并没有满载香橙派 AIpro 和 RK3588 的NPU算力。两个机器的NPU利用率都卡在 30-55% 的瓶颈上,即使使用多线程加塞,也不能提升 NPU 利用率。 RTX2060 利用率任维持 90%。因此 NPU 的利用率上不去既有模型算法问题,也有平台原因。
- NVIDIA RTX2060 的推理速度相比于部署 AI 开发板快很多,是香橙派 AIpro 的 3.5x (Resnet)和 7.5x (YOLOv8n) 速度提升。此时 RTX2060 还没开启 INT8 量化,量化之后,领先的幅度可能会更拉开。作者搞不定 tensorrt 的量化,也就没进一步测试了。
1.3 香橙派 AIpro系统烧录
香橙派 AIpro 提供了两种烧录系统版本,作者这里使用 Ubuntu 版本进行烧录
Ubuntu:百度网盘(ubuntu) 请输入提取码 (baidu.com)
OpenEuler:百度网盘(OpenEuler) 请输入提取码 (baidu.com)
1、打开香橙派官网:
Orange Pi官网-香橙派(Orange Pi)开发板,开源硬件,开源软件,开源芯片,电脑键盘
2、打开香橙派 AIpro,这里的官方工具可以点击下载:
3、在该网址页面内,下载官方提供的 Ubuntu 系统;

4、打开刚刚下载的官方工具中的 BalenaEtcher;
5、将镜像系统文件 img 烧录到 SD 卡上,且插入香橙派 AIpro;
1.4 香橙派 AIpro初体验
1、香橙派 AIpro上电启动,稍等一会屏幕将被点亮,如下;

2、输入密码:Mind@123(默认密码);

3、打开香橙派 AIpro终端,输入以下代码:npu-smi info;
npu-smi info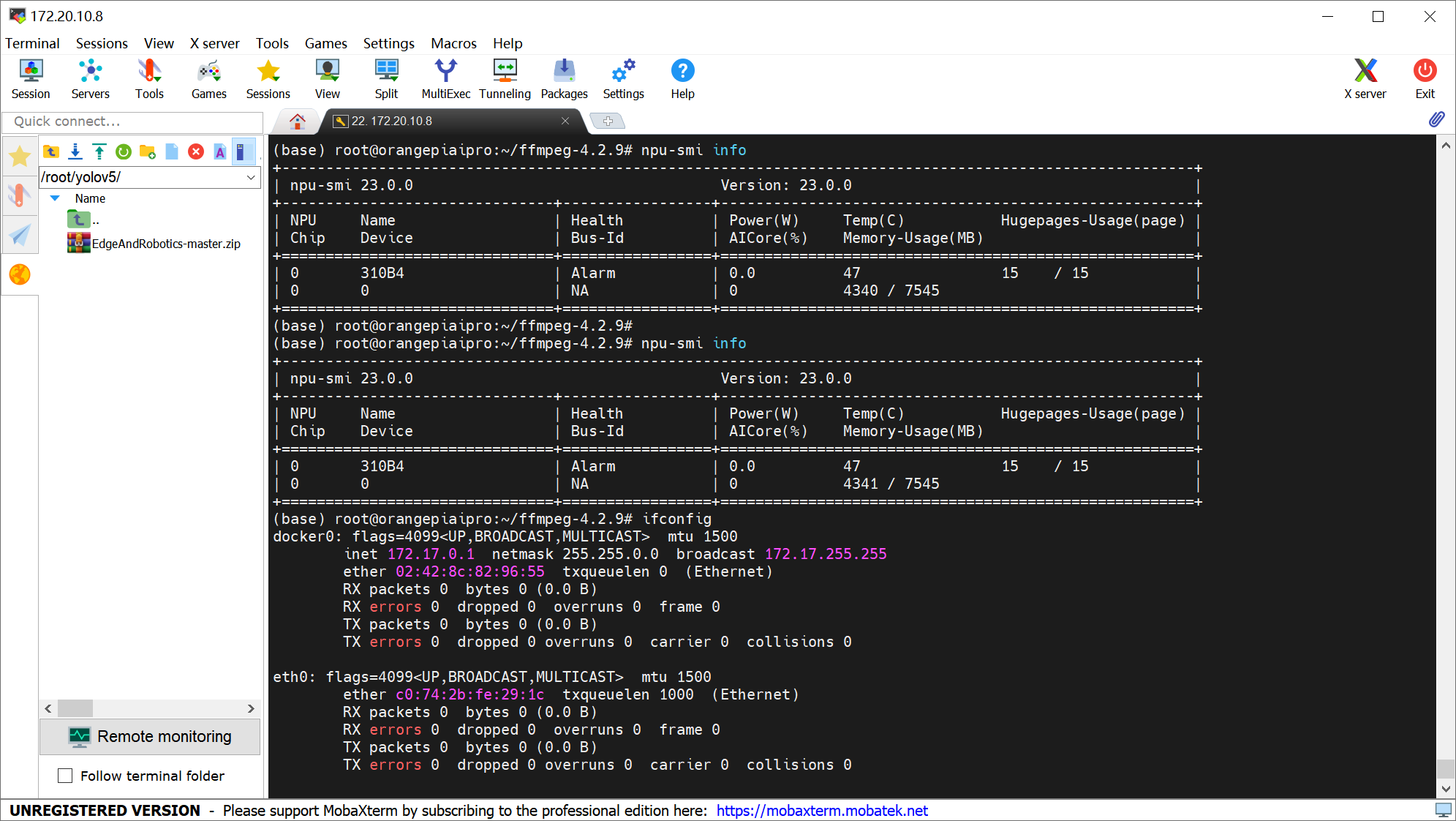
利用 npu-smi info 可以查看昇腾芯片 NPU 卡的信息,上图显示,Device为310B4,芯片温度为47度,总内存为7.6G,已使用4.3G左右。
4、利用 ifconfig 可以查看到 有线网卡 eth0 的 IP 地址信息,也可以查到无线网卡 wlan0 的信息,并接入无线网;
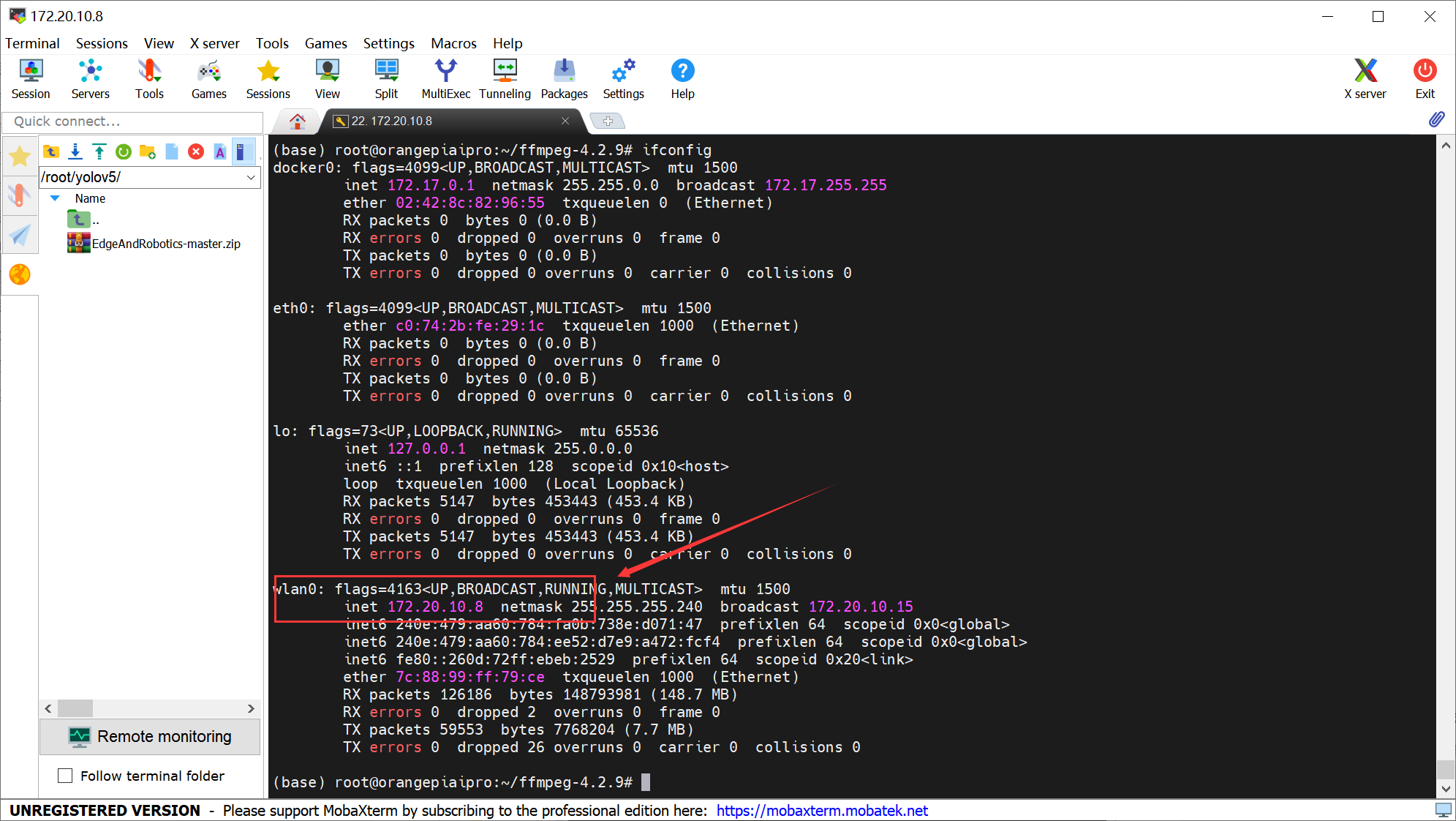
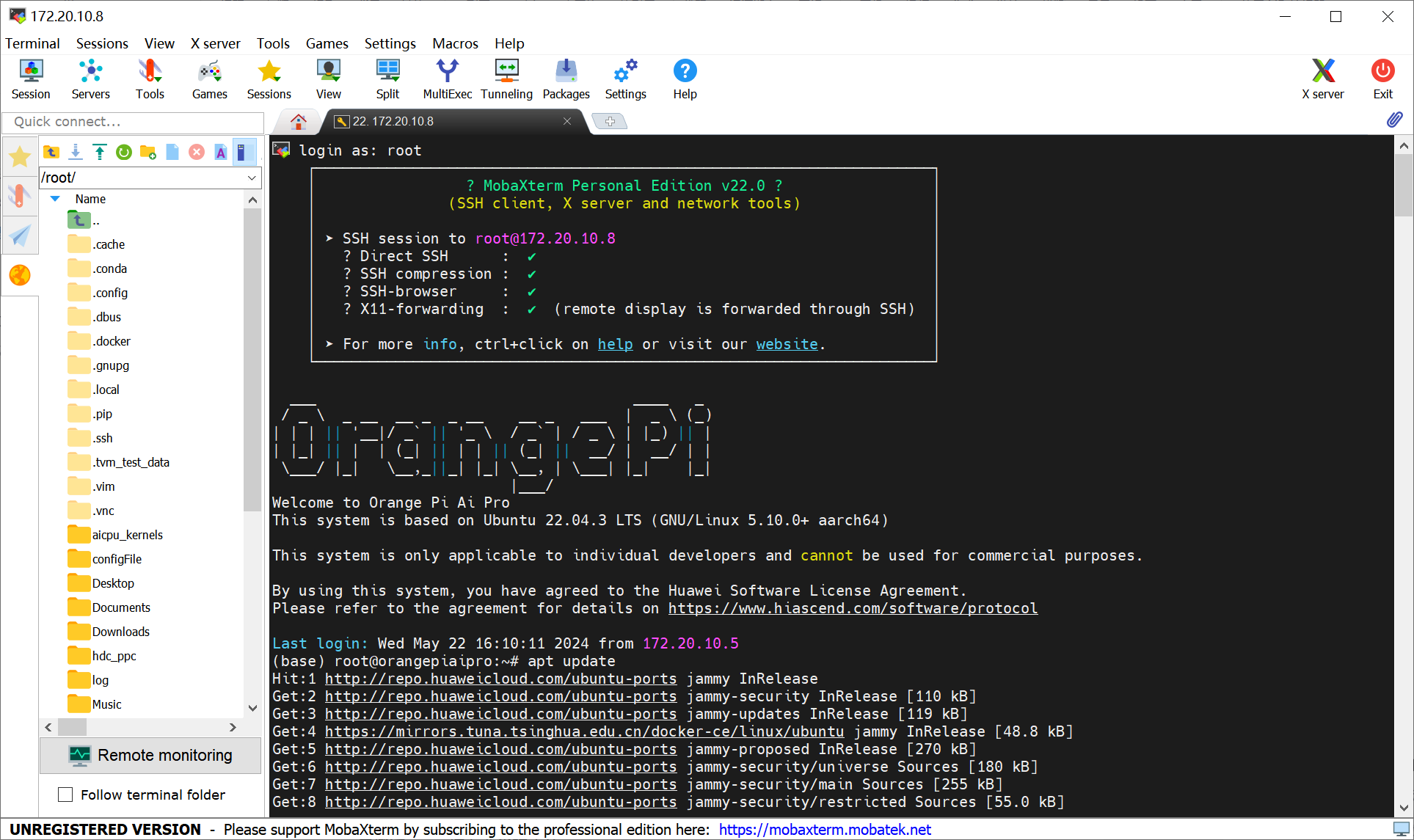
5、利用 MobaXterm 连接该地址,从而实现远程登入开发板:
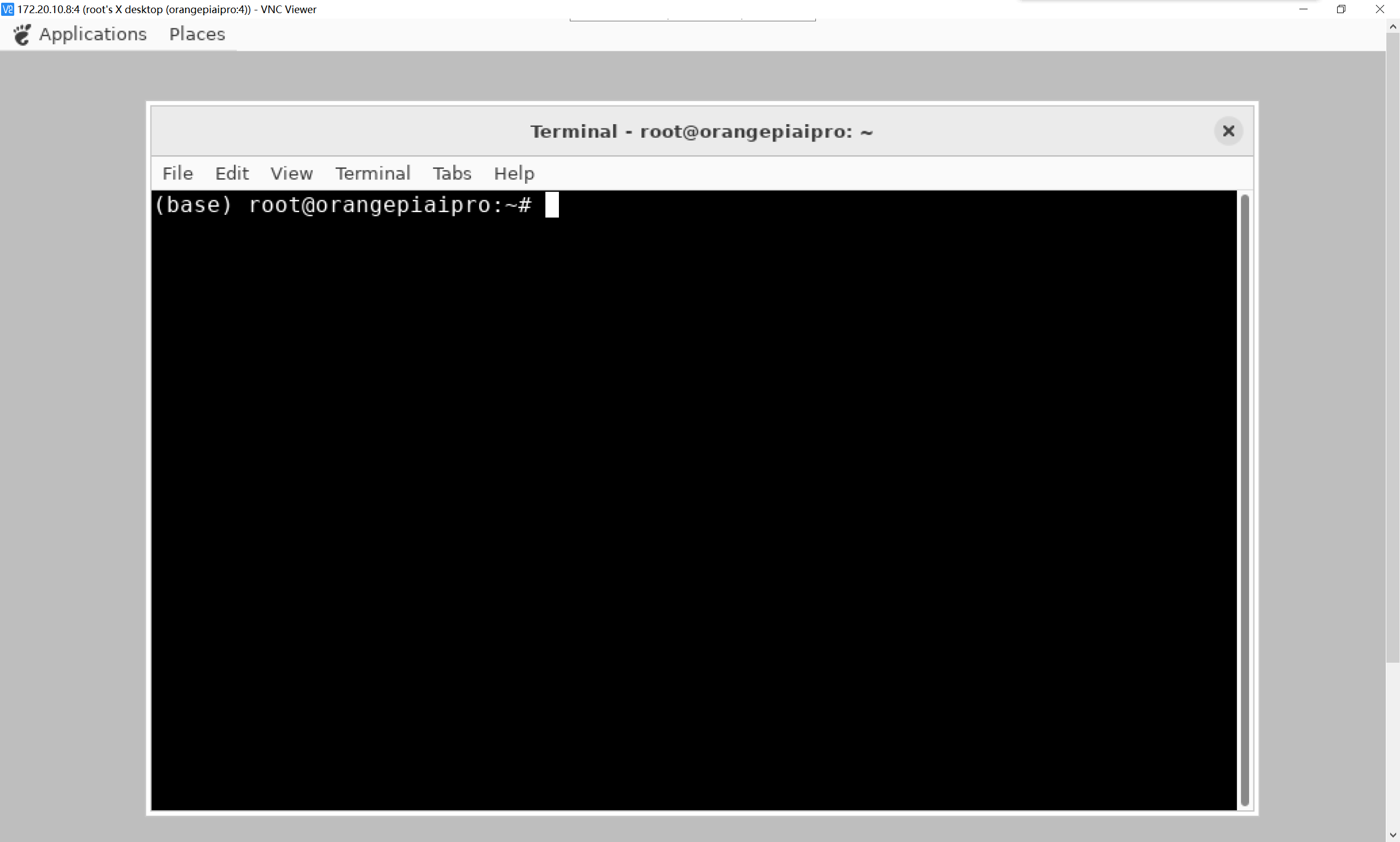
6、VNC Viewer图形化远程控制,操作如下;
使用Ubuntu Focal,VNC登录灰屏幕。原因是 Focal 默认图形界面是 gnome,和香橙派 AIpro官方镜像适配有所不同。
解决办法:
sudo apt-get install gnome-panel gnome-settings-daemon metacity nautilus gnome-terminal
vim ~/.vnc/xstartup添加以下内容:
#!/bin/bash
export $(dbus-launch) # 主要是这句
export XKL_XMODMAP_DISABLE=1
unset SESSION_MANAGER
gnome-panel &
gnome-settings-daemon &
metacity &
nautilus &
gnome-terminal &
# [ -x /etc/vnc/xstartup ] && exec /etc/vnc/xstartup
# [ -r $HOME/.Xresources ] && xrdb $HOME/.Xresources
xsetroot -solid grey
vncconfig -iconic &
x-terminal-emulator -geometry 80x24+10+10 -ls -title "$VNCDESKTOP Desktop" &
gnome-session &
貌似香橙派 AIpro与传统的 VNC 远程图形化一直存在不适配问题,但是,如果一定想借助图形化操作的同学可以尝试使用 NoMachine 软件,这款远程图形化工具的适配性很好。
二、香橙派 AIpro外设
2.1 引脚功能介绍
香橙派 AIpro拥有非常强大的外设与引脚功能,包含 40 个Pin脚,如下图所示:

40 Pin接口使用注意事项如下所示:
(1)、40 Pin接口中总共有 26 个 GPIO 口,但 8 号和 10 号引脚默认是用于调试串口功能的,并且这两个引脚和 MicroUSB 调试串口是连接在一起的,所以这两个引脚请不要设置为 GPIO 等功能。
(2)、所有的 GPIO 口的电压都是 3.3v。
(3)、40 Pin接口中 27 号和 28 号引脚只有 I2C 的功能,没有 GPIO 等其他复用功能,另外这两个引脚的电压默认都为 1.8v。
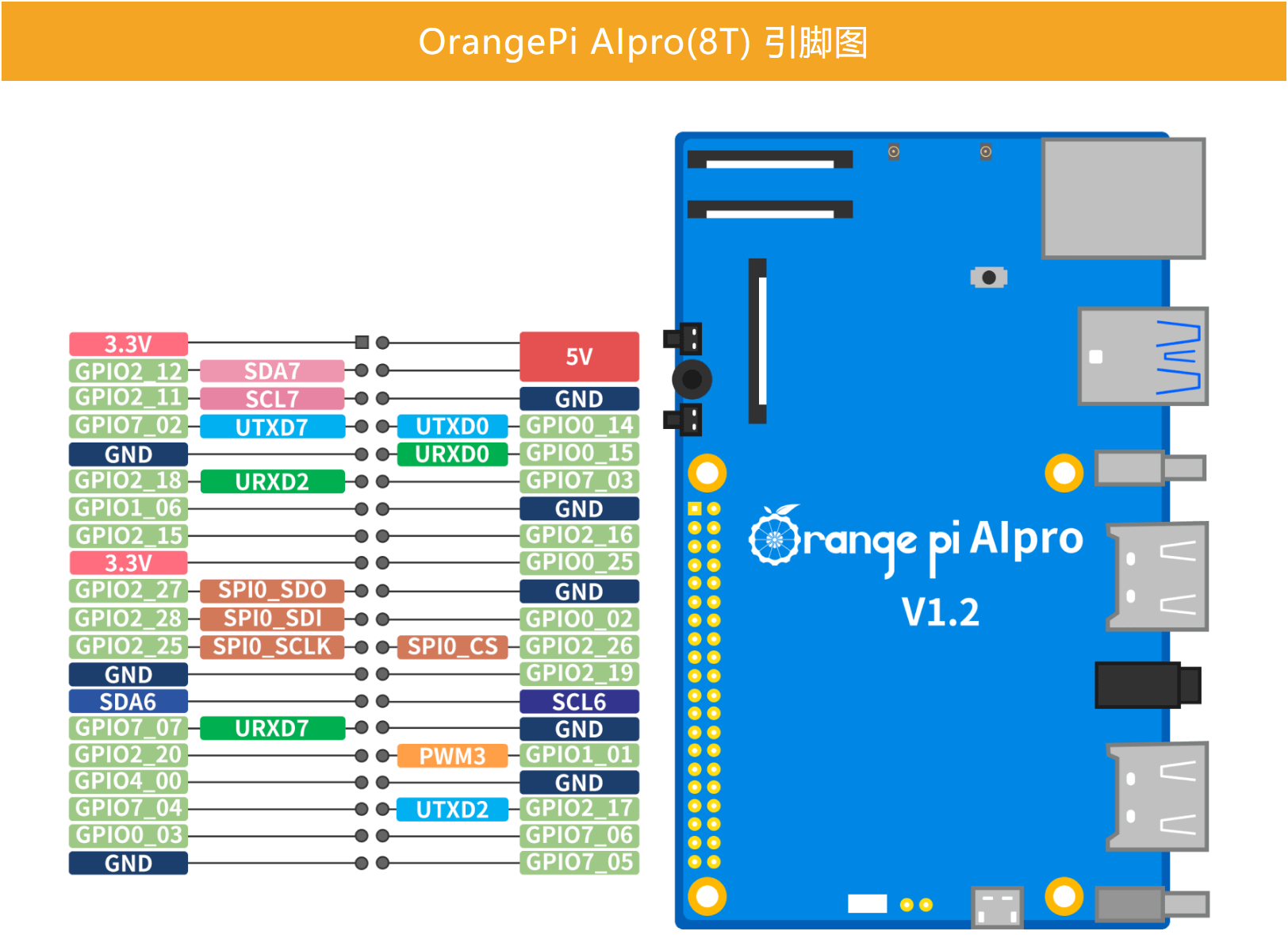
香橙派 AIpro的 40 Pin引脚提供了丰富的外设资源,包含:GPIO、I2C、UART、SPI 和 PWM等功能。借助这 40 Pin引脚,各位创客或是工程师可以实现超级多的奇思妙想。Linux 镜像中预装了 gpio_operate 工具用于设置 GPIO 管脚的输入与输出方向,也可将每个 GPIO 管脚独立的设为 0 或 1。各位工程师朋友通过在官网下载香橙派 AIpro用户技术手册来运用 gpio_operate 工具进行高效开发。
2.2 香橙派 AIpro与STM32通信
工程案例:将香橙派 AIpro 与 STM32 进行串口通信操作
该案例是智能产品研发过程中常使用的框架,即 NPU+MCU 的黄金搭档组合,该框架下将充分发挥香橙派 AIpro的 AI 算力,并结合 STM32 这类微控制器的强大控制能力,能够研制出各种高科技产品。例如:SLAM小车、视觉机械臂、仿生机器人等。
1、首先确定香橙派 AIpro的 UART 是否正常,指令:ls /dev/ttyAMA*

2、进行 serial 程序测试,香橙派 AIpro拥有 3 个serial,普通使用者可以使用serial2和serial3;
sudo -i
cd/opt/opi_test/uart
./serial/dev/ttyAMA1作者这里使用ttyAMA1(UART2)与 STM32 进行通信 ;


代码重构,将官方提供的 serial 代码修改成需要的代码,操作如下:
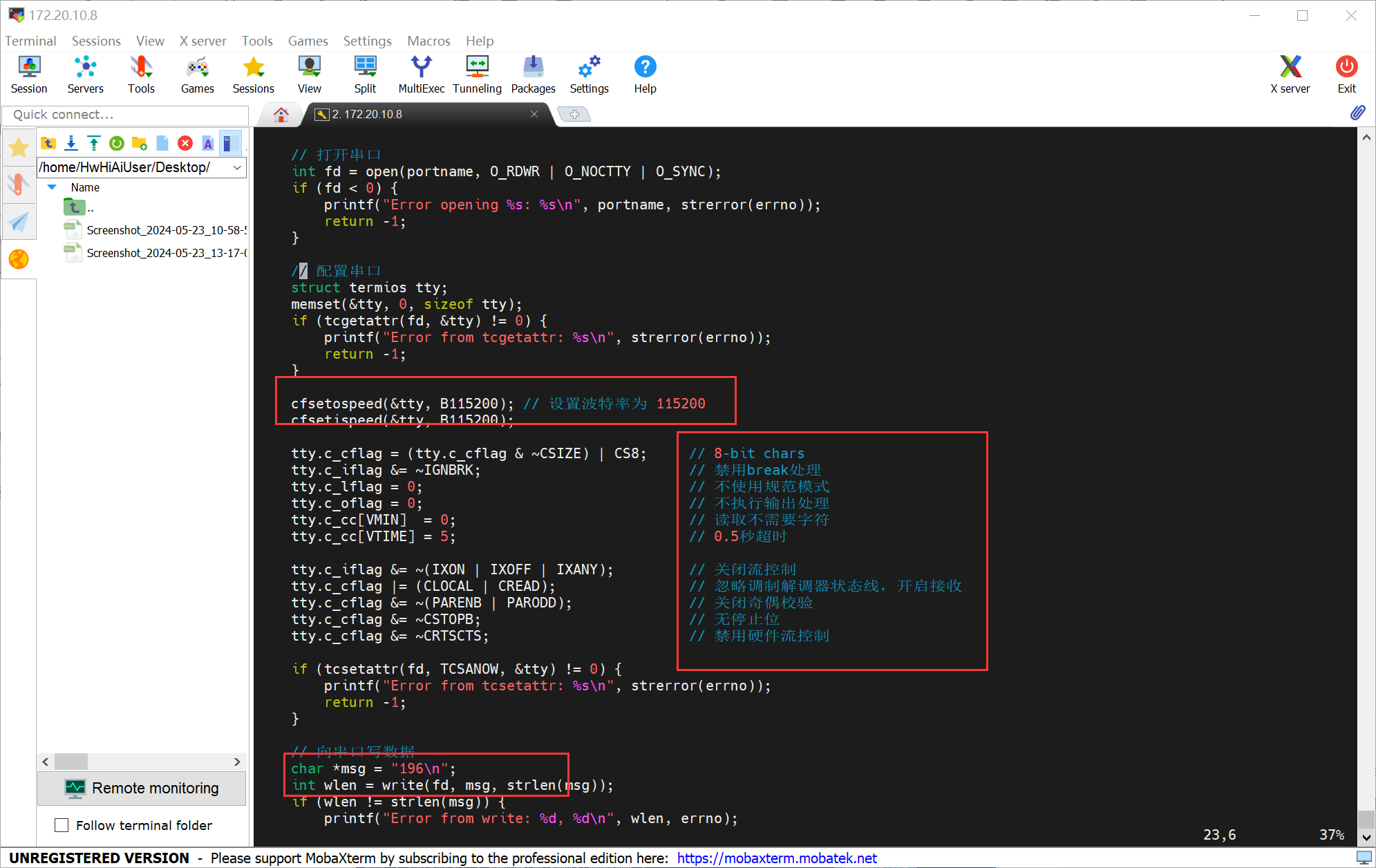
上述红框区域是串口通信的设置,需要与下位机的 STM32 保持一致,我们让香橙派 AIpro持续打印196这个数值;
3、编写STM32端代码,本篇博客使用 STM32CubeMX 工具进行生成初始代码;
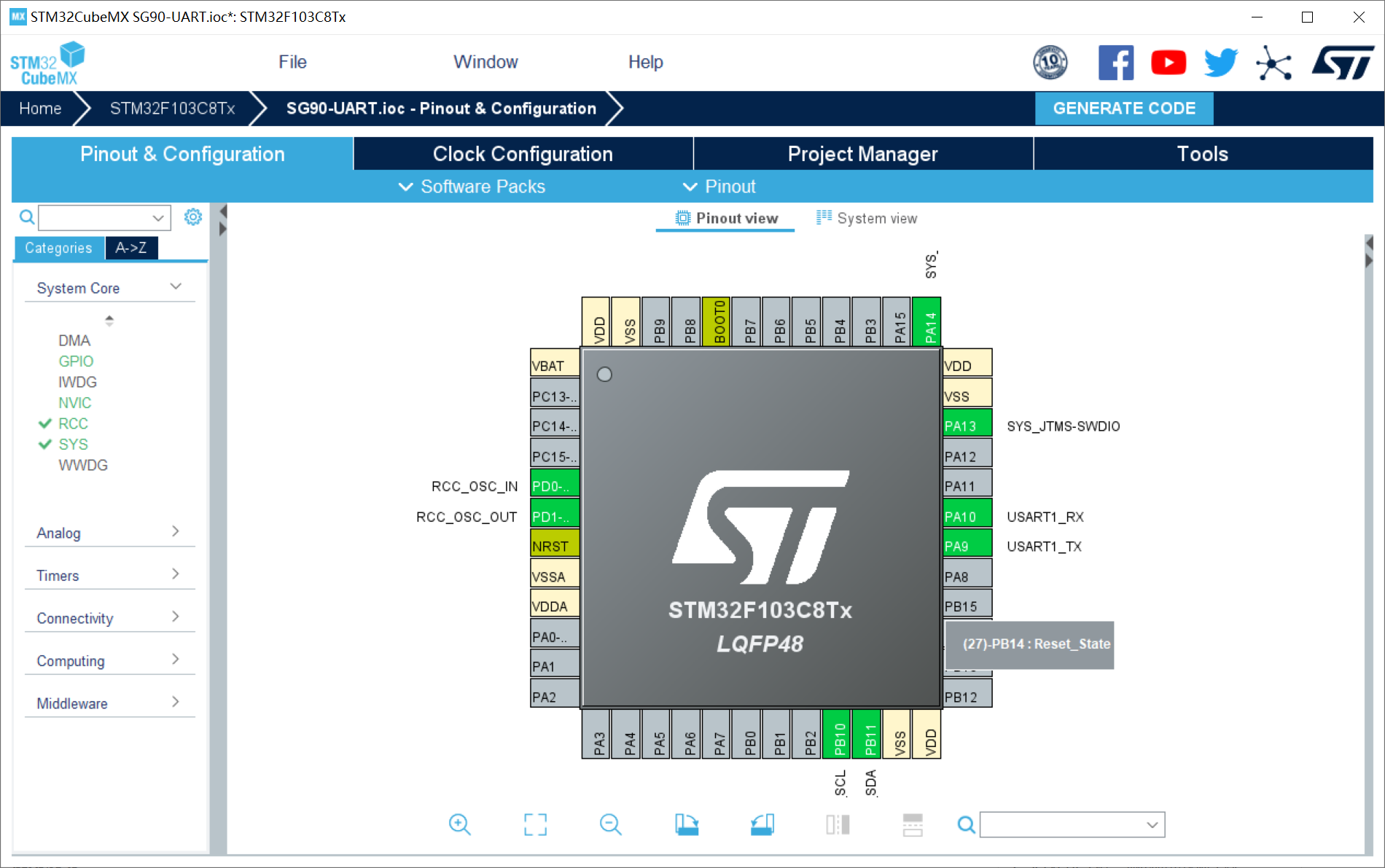
uart.h:
#ifndef __UART_H
#define __UART_H
#include "stm32f1xx_hal.h"
extern UART_HandleTypeDef huart1;
#define USART1_REC_LEN 600
extern int USART1_RX_BUF[USART1_REC_LEN];
extern uint16_t USART1_RX_STA;
extern int USART1_NewData;
void HAL_UART_RxCpltCallback(UART_HandleTypeDef *huart);
#endifuart.c:
作者这里仅通过 STM32 的串口中断进行数据接收操作,且假设接收到的数据为
#include "uart.h"
#include "oled.h"
int USART1_RX_BUF[USART1_REC_LEN]; //目标数据
uint16_t USART1_RX_STA=2;
int USART1_NewData;
extern int num; //百位
extern int num2; //十位
extern int num3; //个位
void HAL_UART_RxCpltCallback(UART_HandleTypeDef *huart)
{
if(huart ==&huart1)
{
USART1_RX_BUF[USART1_RX_STA&0X7FFF]=USART1_NewData;
USART1_RX_STA++;
if(USART1_RX_STA>(USART1_REC_LEN-1))USART1_RX_STA=0;
//num = USART1_RX_BUF[USART1_RX_STA];
HAL_UART_Receive_IT(&huart1,(uint8_t *)&USART1_NewData,1);
num = USART1_RX_BUF[USART1_RX_STA-1];
num2 = USART1_RX_BUF[USART1_RX_STA-2];
num3 = USART1_RX_BUF[USART1_RX_STA-3];
}
}2.3 香橙派 AIpro引脚功能演示
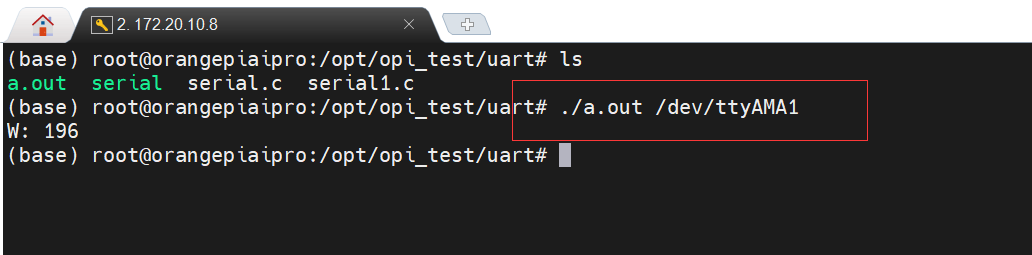

该应用案例是简单的香橙派 AIpro与STM32的简单通信,难度非常低,但是稍加改进就可以作为一个成熟的项目框架使用。综上所述,利用香橙派 AIpro与传统 MCU 进行联动是非常简单易操作的,这也极大地降低了利用香橙派 AIpro进行产品研发的难度。
三、香橙派 AIpro的AI部署实战
3.1 YOLOv5S概述
YOLOv5 网络模型算是 YOLO 系列迭代后特别经典的一代网络模型,作者为:Glenn Jocher。部分学者可能认为YOlOv5的创新性不足,其是否称得上 YOLOv5 而议论纷纷。作者认为 YOLOv5 可以算是对 YOLO 系列之前的一次集大成者的总结和突破,其属于非常优秀经典的网络模型框架,各种网络结构和 trick 是非常值得借鉴的!
代码地址:ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite (github.com)
Yolov5 官方代码中,给出的目标检测网络中一共有4个版本,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型。作者仅以 Yolov5s 的网络结构为对象进行讲解,其他版本的读者朋友可以参考其他博客!
Yolov5s 网络是 Yolov5 系列中深度最小(最适合 AI 部署的版本),特征图的宽度最小的网络。后面的 3 种都是在此基础上不断加深,不断加宽。Yolov5 的网络结构图如下:
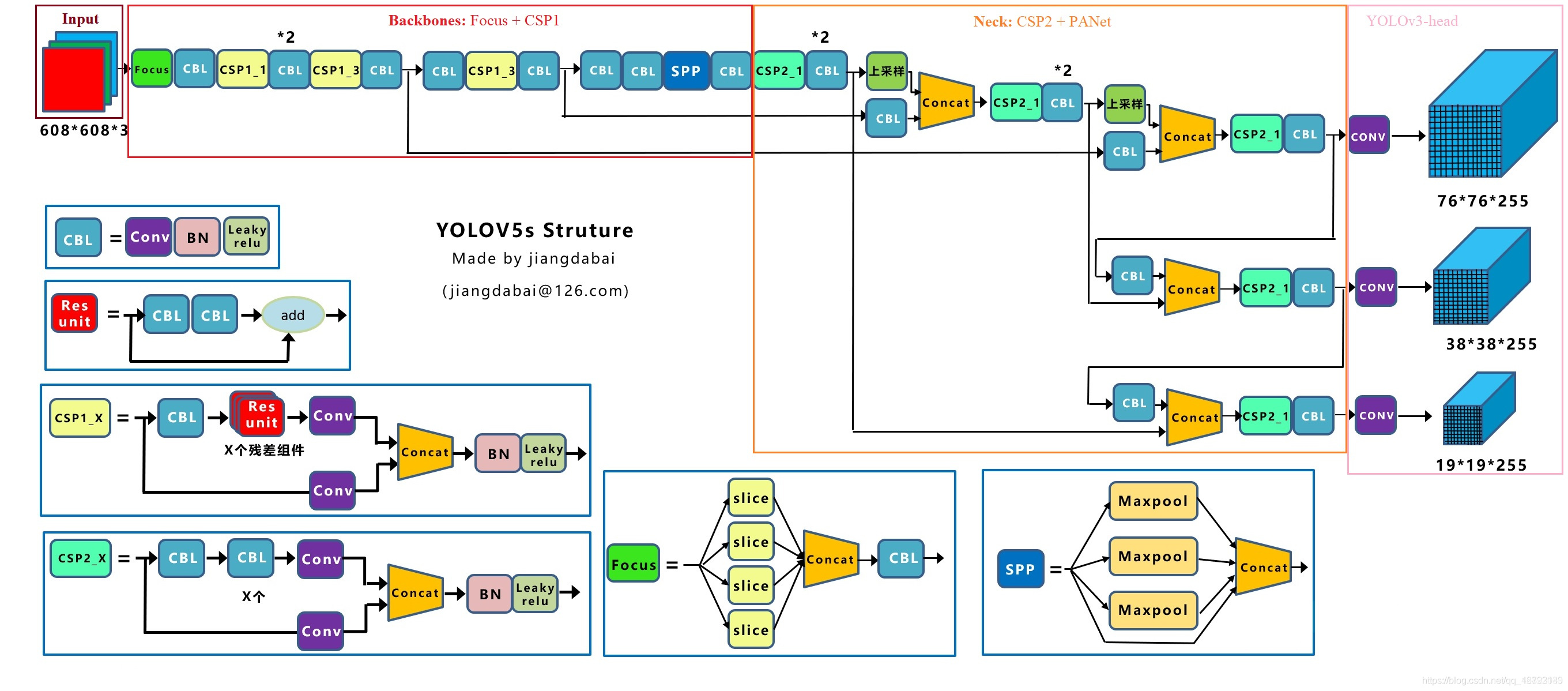
上图即 Yolov5 的网络结构图,可以看出,还是分为Input、Backbone、Neck、Prediction四个部分。
(1)Input:Mosaic数据增强、自适应锚框计算、自适应图片缩放
(2)Backbone:Focus结构,CSP结构
(3)Neck:FPN+PAN结构
(4)Prediction:GIOU_Loss
上述四部分都是属于如今很常见的模块与Trick了,受限于博客篇幅,各部分的详解就不与读者朋友好好分析和交流了。建议对 YOLO 系列陌生的朋友可以去好好看看其他博主的博客亦或是去B站看视频教学!
下面丢上 Yolov5 作者的算法性能测试图:
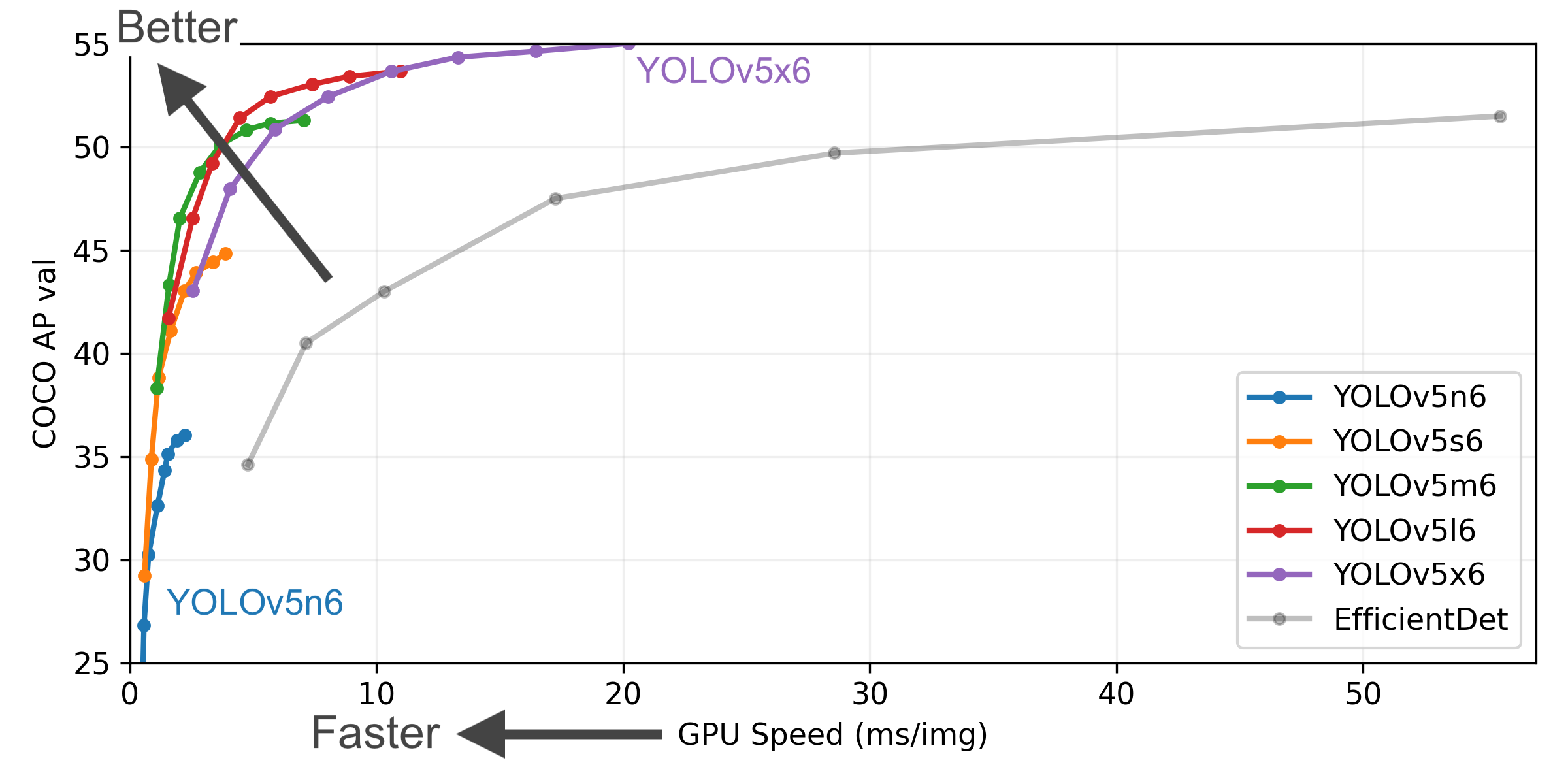
到现在为止,Yolov5 已经更新迭代到 v7.0 版本了,科研学术圈以 Yolov5 为基础框架进行魔改的论文数不胜数。通过上述作者的概述读者朋友可能对 Yolov5 有了一个大致的了解,不难发现 Yolov5 是非常优秀的神经网络模型。
3.2 香橙派 AIpro的YOLOv5S部署
进入官方Gitee仓库地址:Ascend/EdgeAndRobotics (gitee.com)
本篇博客以 YOLOv5S 神经网络模型进行目标检测
一、执行准备
1. 确认已安装带桌面的镜像且HDMI连接的屏幕正常显示;
2. 以HwHiAiUser用户登录开发板;
3. 设置环境变量;
# 配置程序编译依赖的头文件与库文件路径
export DDK_PATH=/usr/local/Ascend/ascend-toolkit/latest
export NPU_HOST_LIB=$DDK_PATH/runtime/lib64/stub4. 安装ACLLite库:ACLLite仓安装ACLLite库。
二、代码下载
1. 使用命令行方式下载
# 登录开发板,HwHiAiUser用户命令行中执行以下命令下载源码仓。
cd ${HOME}
git clone https://gitee.com/ascend/EdgeAndRobotics.git
# 切换到样例目录
cd EdgeAndRobotics/Samples/YOLOV5USBCamera
三、 YOLOv5S代码修改与部署
1、下载官方的测试视频;
请从以下链接获取该样例的测试视频,放在data目录下;
cd ../data
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/yolov5s/test.mp4 --no-check-certificate使用指令:ffplay -autoexit test.mp4 播放测试视频(利用该指令也可以测试ffmpeg是否正确安装)
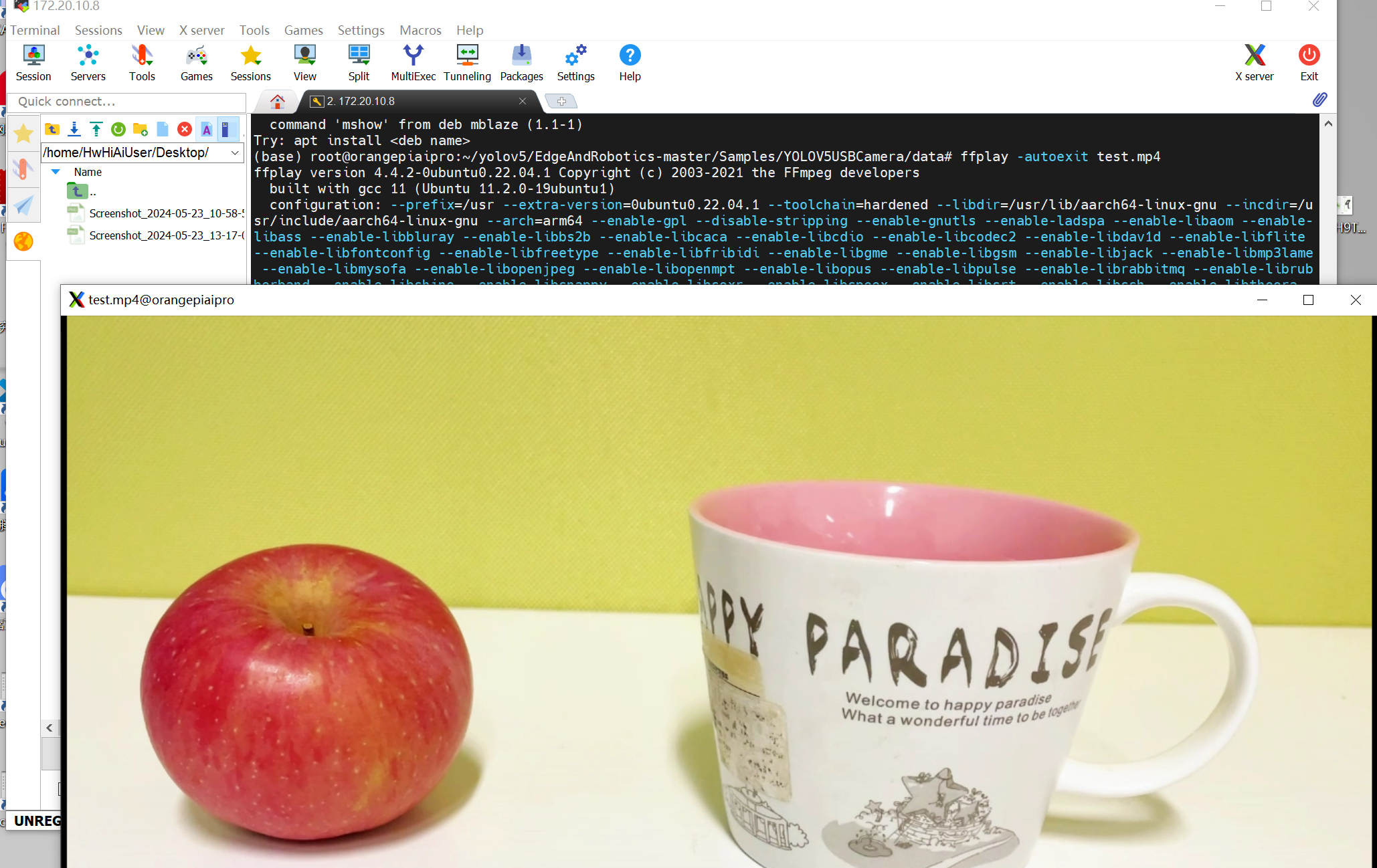
注:**若需更换测试视频,则需自行准备测试视频,并将测试视频放到data目录下。
2、获取PyTorch框架的Yolov5模型(*.onnx),并转换为昇腾AI处理器能识别的模型(*.om);
★当设备内存小于 8G 时,可设置如下两个环境变量减少atc模型转换过程中使用的进程数,减小内存占用。
export TE_PARALLEL_COMPILER=1
export MAX_COMPILE_CORE_NUMBER=1★为了方便下载,在这里直接给出原始模型下载及模型转换命令,可以直接拷贝执行。
cd model
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/yolov5s/yolov5s.onnx --no-check-certificate
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/yolov5s/aipp.cfg --no-check-certificate
atc --model=yolov5s.onnx --framework=5 --output=yolov5s --input_shape="images:1,3,640,640" --soc_version=Ascend310B4 --insert_op_conf=aipp.cfgatc命令中各参数的解释如下,详细约束说明请参见《ATC模型转换指南》。
--model:Yolov5网络的模型文件的路径。
--framework:原始框架类型。5表示ONNX。
--output:yolov5s.om模型文件的路径。请注意,记录保存该om模型文件的路径,后续开发应用时需要使用。
--input_shape:模型输入数据的shape。
--soc_version:昇腾AI处理器的版本。
3、编译样例源码。;
到这里 YOLOv5S 的部署准备工作就已经完成了,作者这里针对没有配备 USB 摄像头的读者朋友提供代码修改,直接对步骤 1 中下载的视频进行 YOLOv5S的目标检测,操作步骤如下:
使用 vim main.cpp 进行 main 函数的修改,将线程操作改为获取视频输入

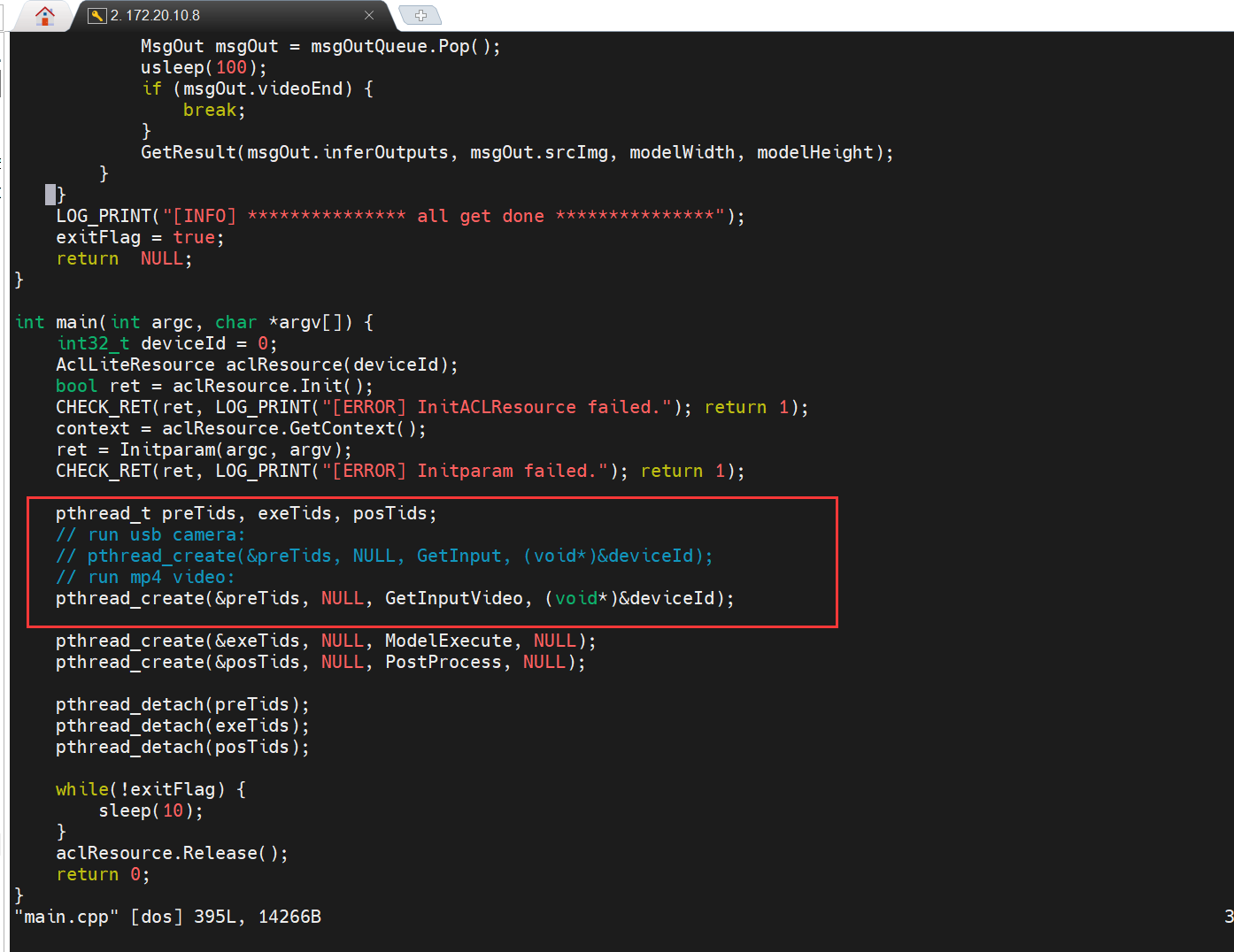
接下重新编译代码, 执行以下命令编译样例源码。
cd ../scripts
bash sample_build.sh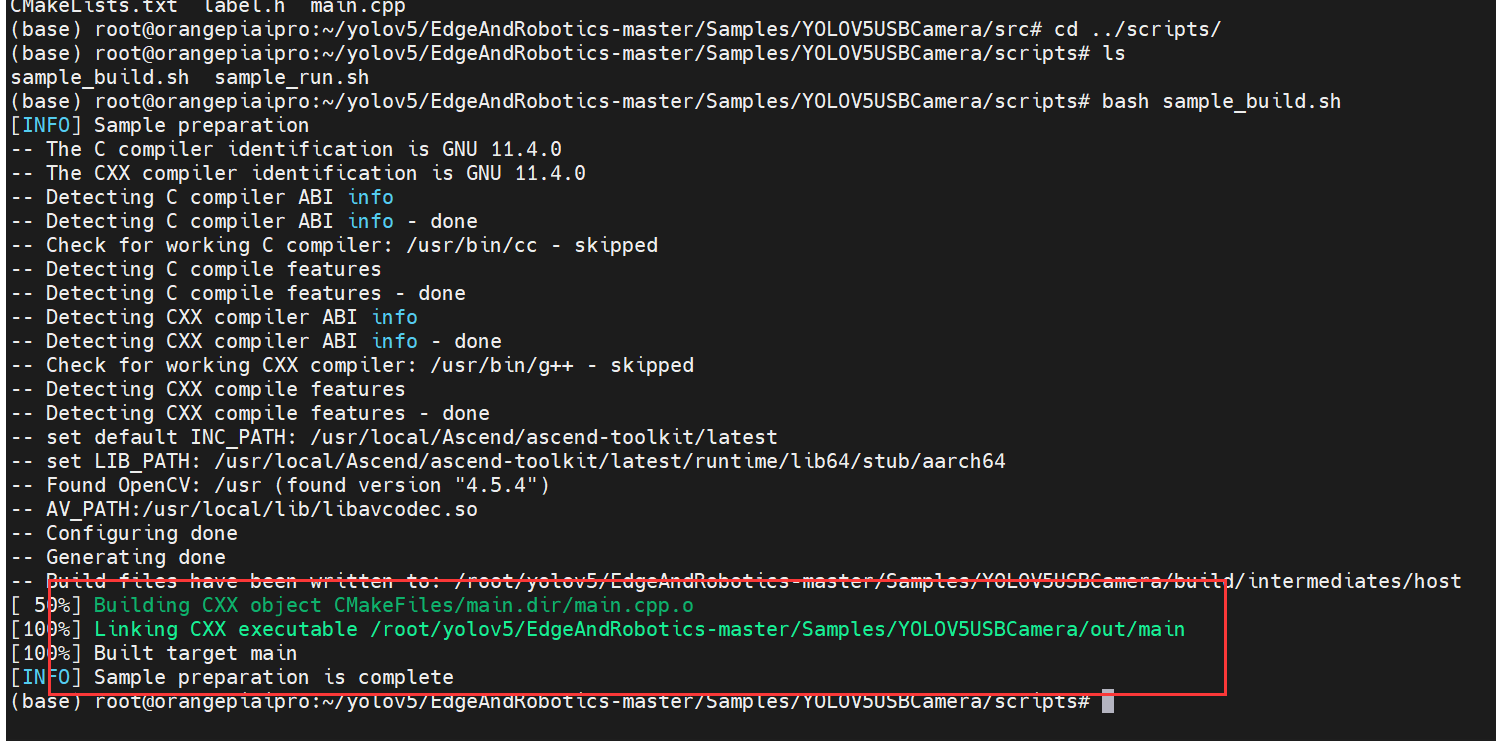
4、运行 YOLOv5S代码
bash sample_run.sh imshow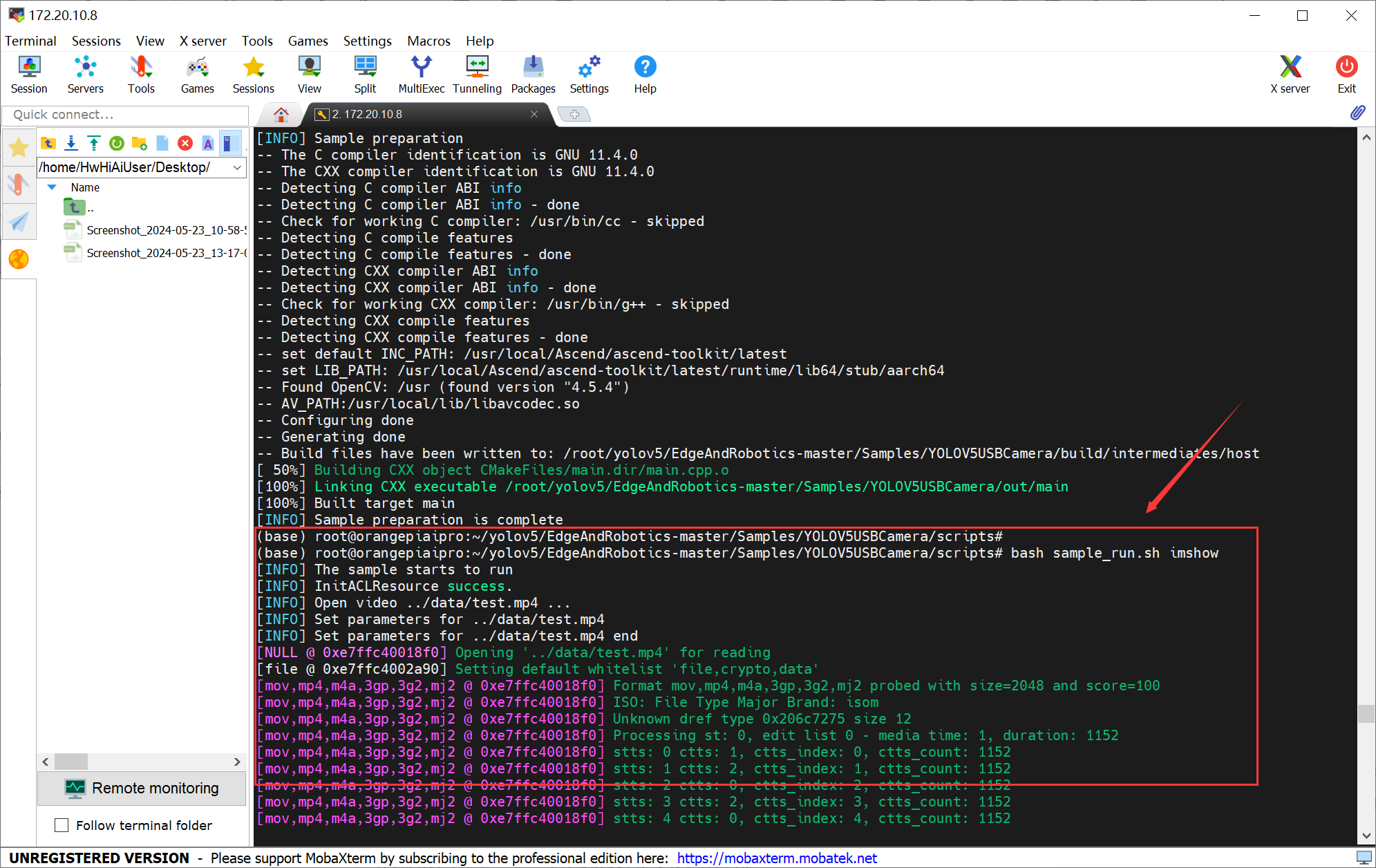
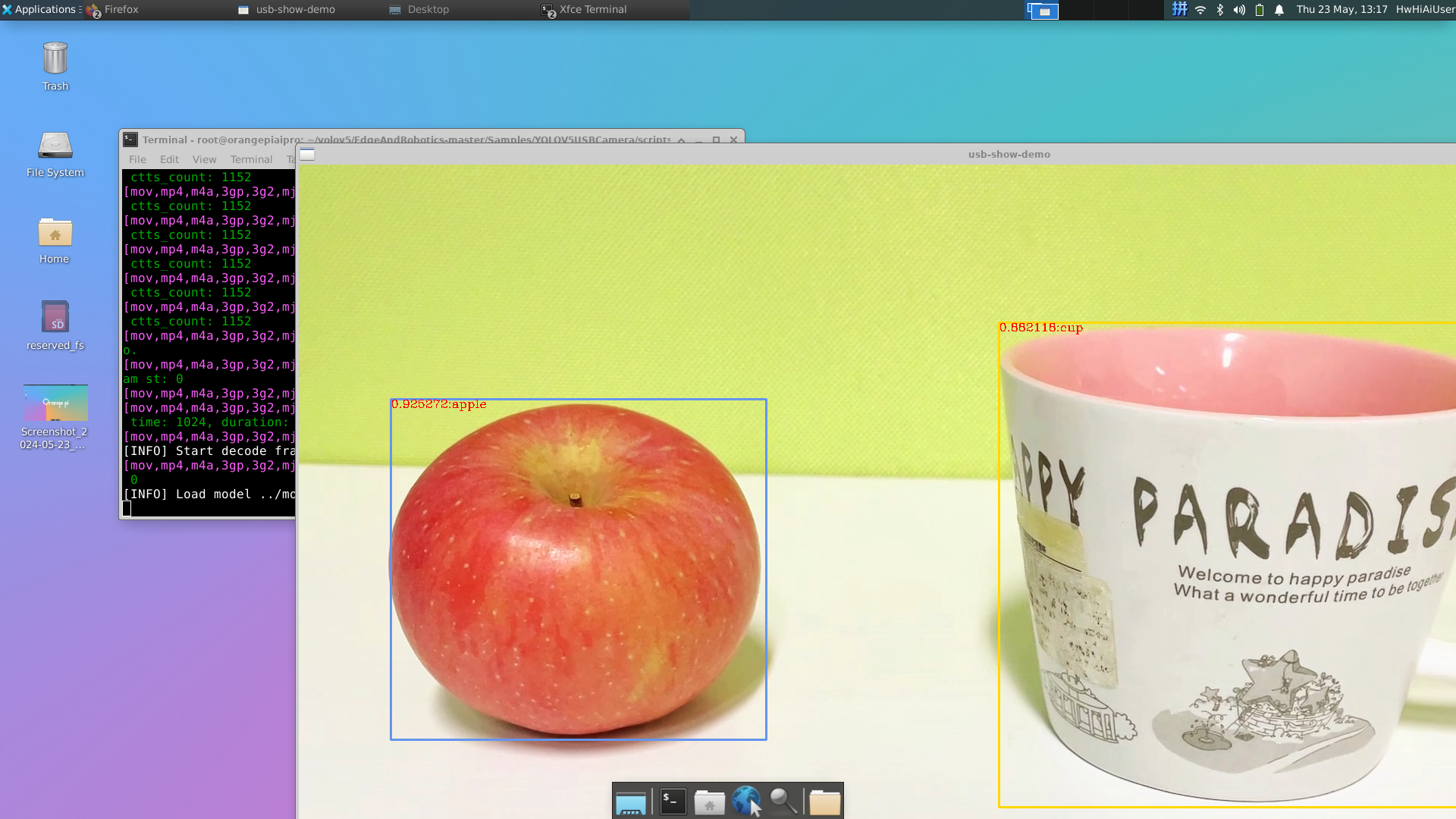
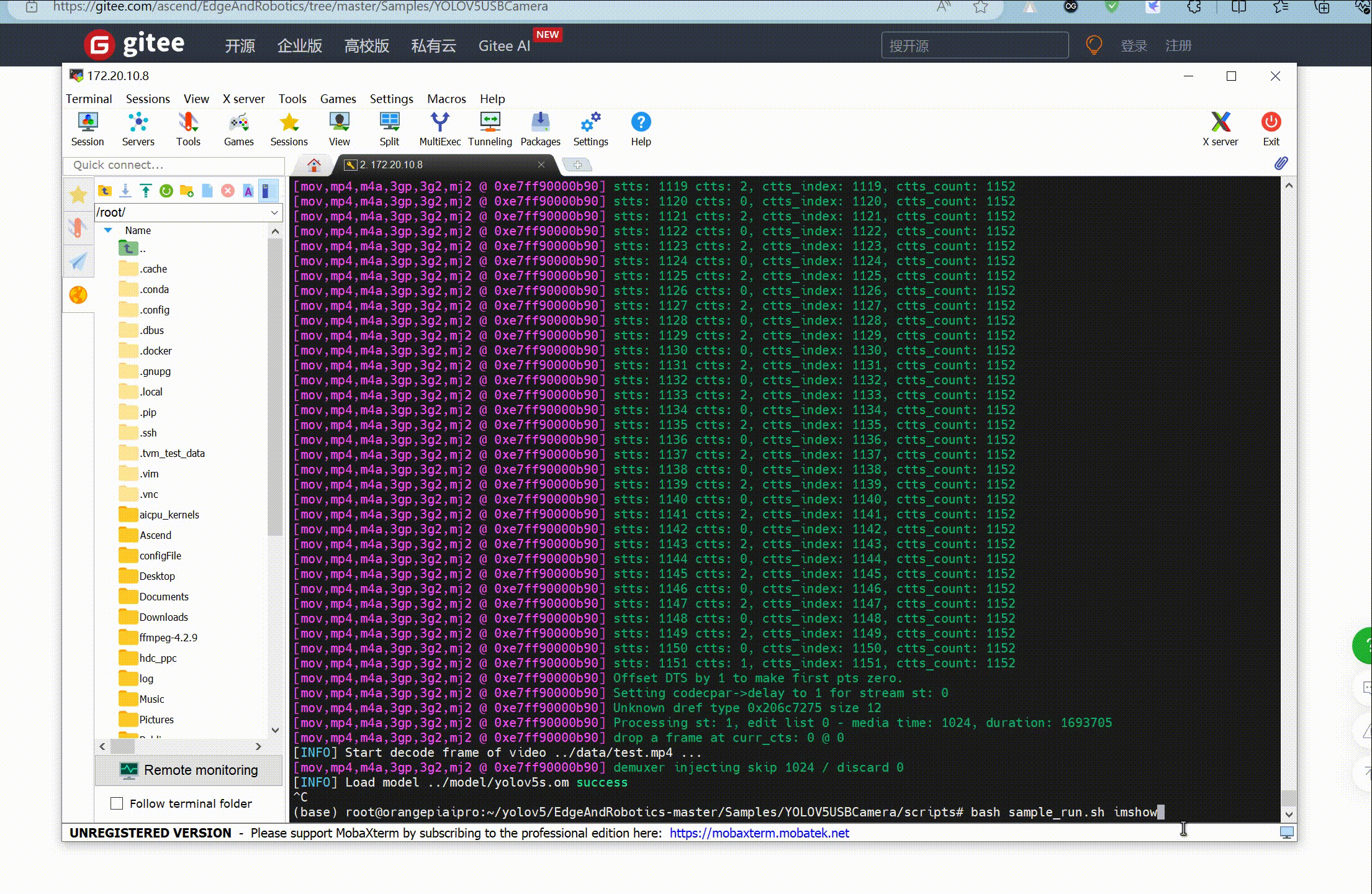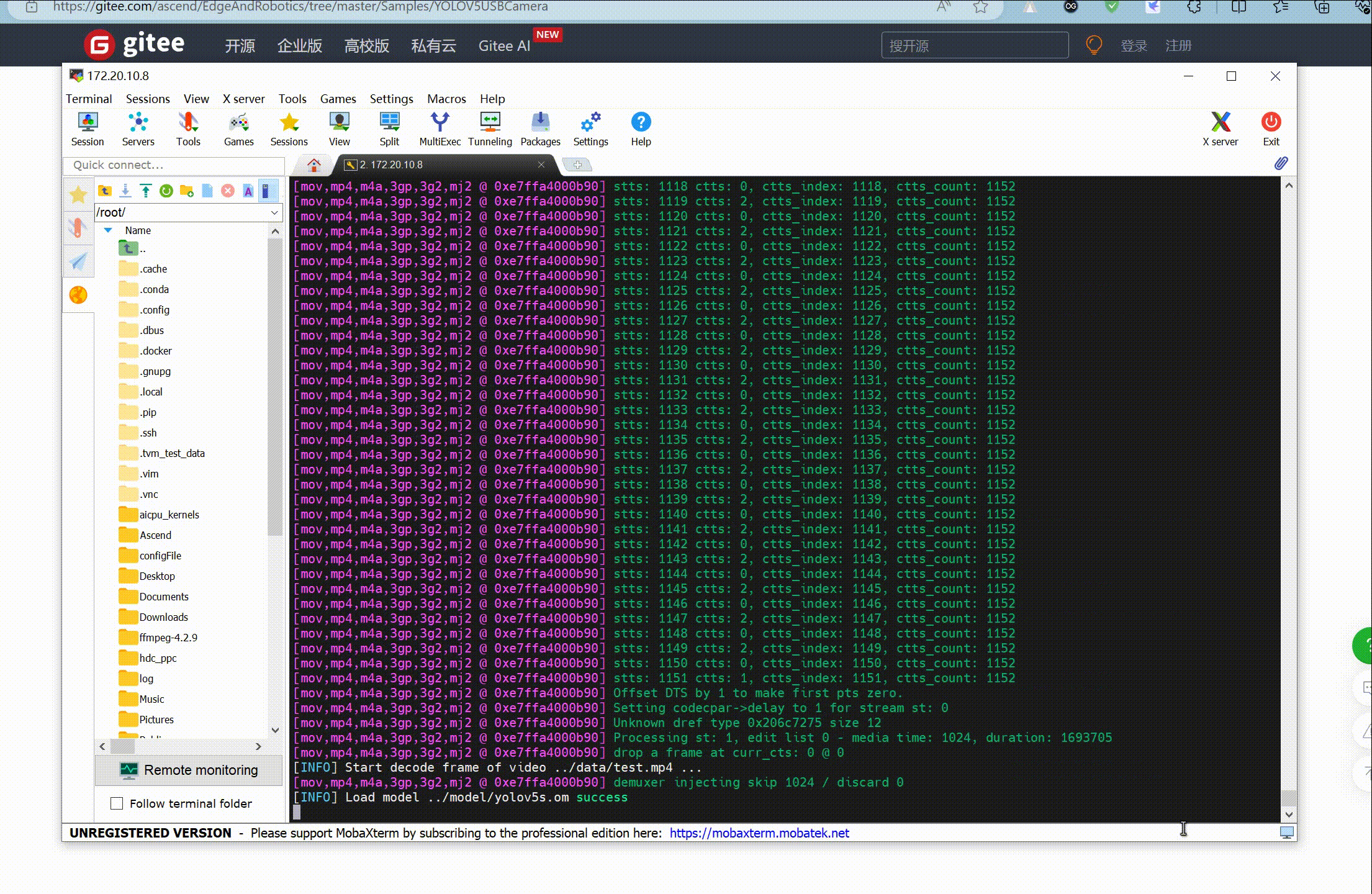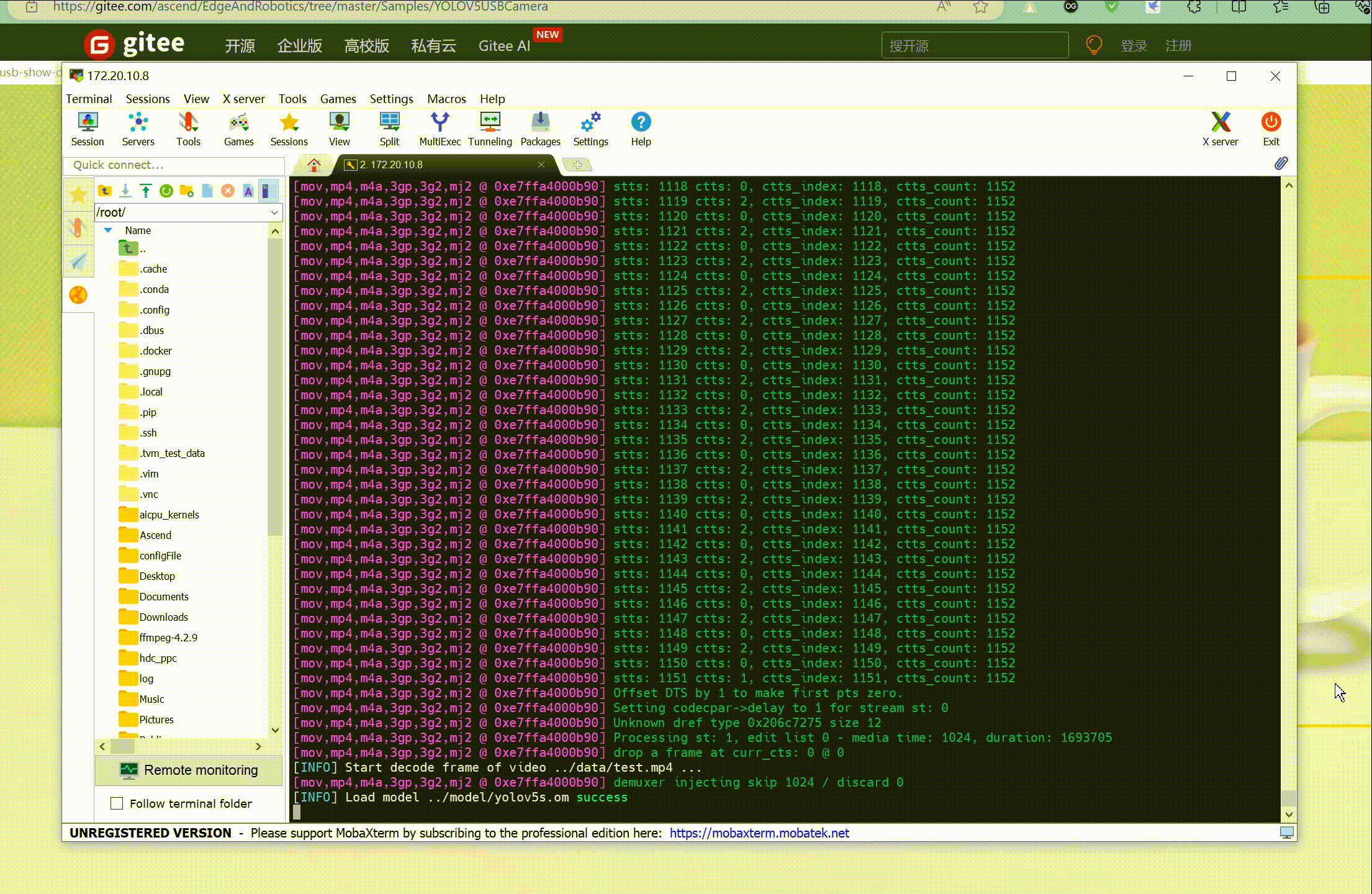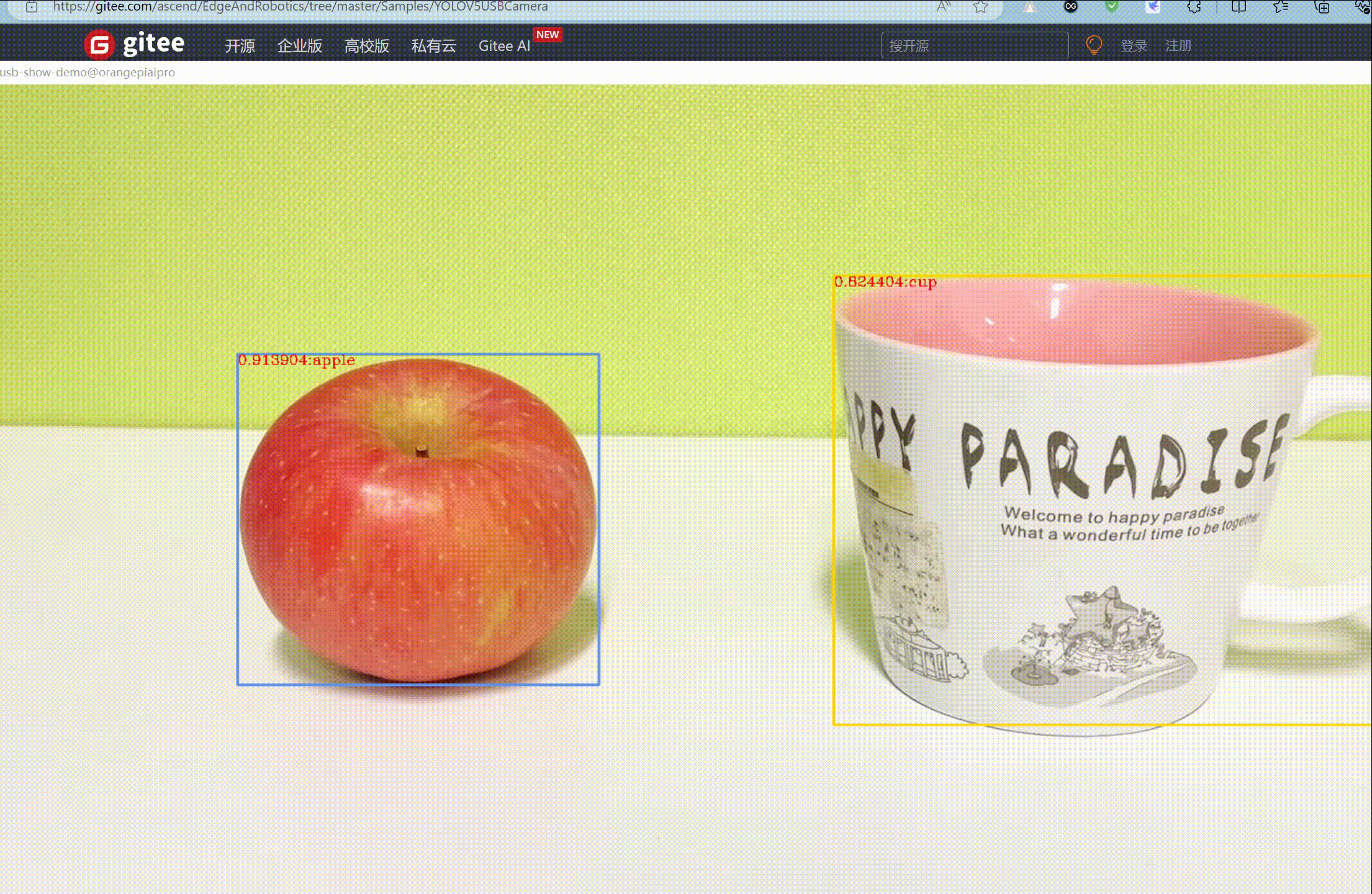
3.3 香橙派 AIpro的YOLOv5S演示
作者没有在香橙派 AIpro上安装视频剪辑和录像软件,故在 MobaXterm 软件上使用网络窗口拉取了 YOLOv5S 的推理情况。实际在香橙派 AIpro 接入的显示器上,运行的 YOLOv5S 模型推理帧率非常的高。
四、各种其他应用案例
4.1 香橙派 AIpro丰富案例
凭借华为昇腾 B310 芯片强大算力的加持下,香橙派 AIpro 可以满足各种各样的产品工程需求。例如:安全检查门、自动贩卖机、智能门锁、目标追踪飞行器、视觉机械臂以及SLAM小车等。

4.2 AI部署开发板综合评述
作者作为一名嵌入式工程师,如今手上的 AI 边缘计算开发板是非常多的,包括:香橙派 AIpro、RK3588、Jeston Nano、树莓派4B、RV1126、OpenMV以及K210等。

1、香橙派AIpro:这款边缘计算开发板是作者本人上手最舒服的,配套的资料完善,部署流程方便且快捷(得益于华为昇腾芯片)。8TOPS的强大算力,完全满足企业级产品亦或是个人创客作品研发的需求。香橙派 AIpro的售价也是非常香的,预算足够还是推荐大家首选 16GB 运行内存版本的香橙派 AIpro。更大的数据吞吐能力,可以得到更好的产品体验!
2、RK3588: 这款 AI 部署开发板可能是业内人员必接触的版型之一,但是相较于香橙派 AIpro的单线程推理算力可能稍逊,多任务推理下的表现情况依旧很好。
3、Jeston Nano:这款 AI 边缘计算开发板是 NVIDIA 家的常青树级别产品,市场普及度以及认可度非常高,CUDA硬件加速的适配促使这款产品在企业级产品中成为常客。但是,仅从算力方面来看,其表现远不如香橙派 AIpro。而算力高于香橙派 AIpro的Orin 系列,其售价高的惊人,一般也是极高端产品才会使用 Orin 系列。
4、树莓派4B:社区资料和氛围很好,各种各样的开源项目层出不穷。但是,售价偏高且固件封装太死导致产品研发具有一定局限性,且算力很低。YOLOv5S的帧率仅能维持在 8 FPS左右,难以满足实际工程项目中对视觉帧率的需求。
5、OpenMV与K210:只适合创客亦或是学生去实现自己的 DIY 产品,Python语言导致代码运行效率底下,算力表现非常一般。优点是容易上手,但其局限性也很大。
作者有话
综上所述,香橙派 AIpro是一款非常优秀 AI 边缘计算开发板,其推进了 AI 部署的国产化进程。香橙派 AIpro这款 AI 边缘计算开发板的算力是完全满足商业级产品需求的(利用视觉进行控制判断,需要每秒至少 25 帧以上,香橙派面对正常的多视频流推理依旧可以完美满足),作者将在未来的一段时间内,使用香橙派 AIpro与 STM32 进行联动开源一款视觉机械臂项目,感兴趣的朋友可以关注一下之后的昇腾社区与作者的博客!
实话实说,香橙派 AIpro这款新品 AI 边缘计算开发板真的让人眼前一亮。作者手上的 AI 部署开发板也不在少数,比如:树莓派5B,Jeston Nano以及RK3588。但香橙派 AIpro绝对是这类产品中的王者,超给力的算力搭配详细的技术手册,给予创客和工程师很大的个人发挥空间!
OrangePi AIpro 让 AI 创造无限可能!!!



![[数据集][目标检测]RSNA肺炎检测数据集VOC+YOLO格式6012张1类别](https://img-blog.csdnimg.cn/direct/3f2ce27ec2fc42c68b0f72690450df84.png)
![[集群聊天服务器]----(十一) 使用Redis实现发布订阅功能](https://img-blog.csdnimg.cn/direct/33b71c90e4bb4ebfac49fe8dac3c59c7.png)