文章目录
- 前言
- MergeTree存储引擎的三大特点
- MergeTree 的数据组织
- MergeTree的文件组织
- 数据文件、元数据文件、索引文件和其他文件
- 分区
- 数据库和表
- 索引
- 与事务数据库存储引擎的对比
- 存储引擎如何影响查询速度
- MergeTree存储引擎的工作过程
前言
存储引擎是ClickHouse非常重要的一个组件,MergeTree表引擎又是 Clickhouse 引擎中最流行的,同时 Clickhouse 之所以查询速度快,与它又密切相关。
本文将对 Clickhouse 中的 MergeTree 表引擎架构设计进行说明,进而了解该引擎加速查询的原理,最后将列举 SQL 说明 MergeTree 表引擎的工作过程。
MergeTree存储引擎的三大特点
三级数据组织
- 按照3个层级组织数据及数据文件,分别是数据库、数据表、数据分区。
- 数据库由一个或多个数据表组成。
- 数据表由一个或多个数据分区组成。
- 数据只能被放到数据分区内,如果用户没有明确指定分区,则数据存储于默认名为all的分区。
数据不可变
- MergeTree中的数据一旦写入,就不能再修改。
- Clickhouse 中数据不可变的原因是为了提升并发能力,减少数据操作竞争。
密集堆放
- 数据在内存和文件中都被密集堆放,应尽可能减少控制信息,以降低磁盘I/O、内存占用,提高查询速度。
MergeTree 的数据组织
数据组织说明
- 数据组织主要描述用户保存的数据是如何在数据文件中保存的。
- 数据组织是存储引擎的基础,相同的数据可以以不同的数据组织形式写入数据文件。
- 不同的数据组织形式会带来不同的效果,例如在数据的写入速度、读取速度、检索速度、事务能力等多个方面直接影响着上层计算引擎的功能及运作效率。
数据最小单位
- Clickhouse 中数据的最小组织单位是**块,**块的大小默认为8192行,即ClickHouse一次性处理8192行数据。
数据堆放方式
- Clickhouse 是列式存储,不同的列会存储在不同的数据文件中,因此在ClickHouse中只需要考虑数据如何按行堆放。
- 其中不同的数据类型又决定了数据的堆放方式:定长数据类型和变长数据类型。
- 定长数据类型的堆放方式类似于数组,可以通过下标访问元素,实现简单、随机取数效率高、空间利用率高、算法实现简单。
- 变长数据类型的堆放方式有三种堆叠方式:
- 使用固定的分隔符
- 在另一个数组中记录每个元素的长度
- 将数据写入额外的数据文件,在当前数据文件中记录定长的偏移量
其中 Clickhouse 使用的是第二种方式,变长数据类型在内存中会维护两个数组:一个是存储数据的字节数组;另一个是存储元素长度的定界数组。
数据压缩
- Clickhouse 将数据堆叠成块后,会对数据进行压缩,默认支持3种压缩方式:LZ4、LZ4HC、zstd。ClickHouse默认使用LZ4压缩。
- 压缩是为了减少磁盘 I/O,提升查询速度,使用 CPU 计算来弥补 磁盘 I/O 瓶颈问题。
MergeTree的文件组织
前边说到的只是 Clickhouse 的数据组织方式,MergeTree 并没有将元数据信息保存到块中。
Clickhouse 将 MergeTree 数据写入文件,以文件组织作为元数据信息管理。
在MergeTree中,数据库、数据表和数据分区都被物化为文件夹表示,数据由一组不同类型的文件组成。MergeTree的文件组织形式如下图所示: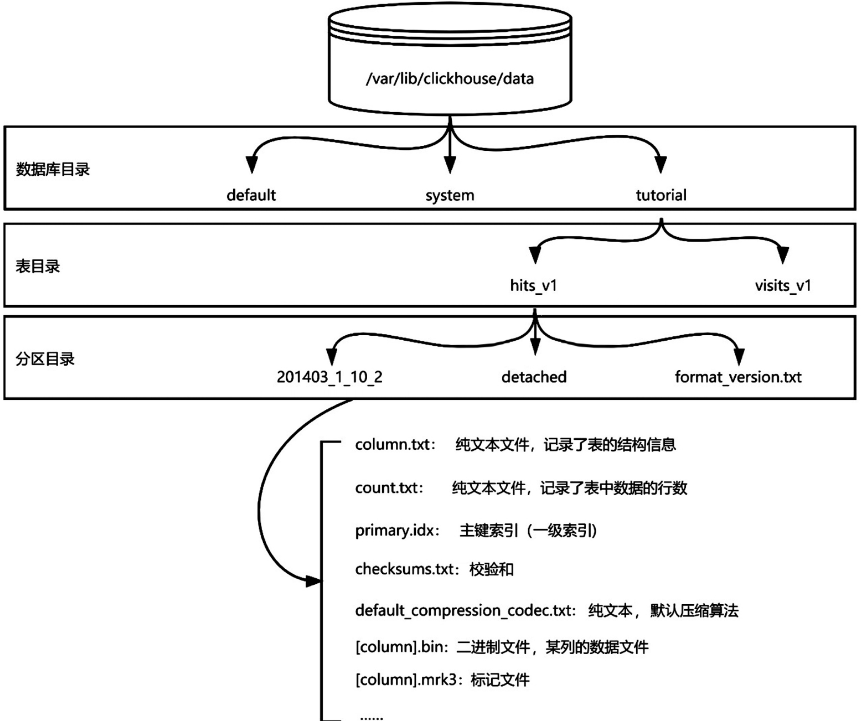
数据文件、元数据文件、索引文件和其他文件
MergeTree的数据由3种文件组成,分别是数据(bin)文件、索引文件和标记文件。这3种文件是MergeTree进行读取和写入时不可缺少的文件,丢失任意一个文件,都会造成数据损坏,无法读取。除此之外,还有一些辅助文件用于校验、加速查询等功能,这类文件的丢失不会导致数据损坏,可以依据数据进行重建。
数据文件
数据文件的结构如下图所示:
- 以
.bin结尾的文件,包含多个块,可以通过该文件获取块字节数据,但是无法对数据进行解析。 - 每个块数据中包括压缩信息数据和保存实际数据。
元数据文件
- 元数据文件中存储表结构、字段数据类型、字段数据长度等元数据信息。
- 文件名固定为
Columns.txt,可以直接打开查看相关元信息。 - 数据文件必须配合元数据文件才能被正确解析。
索引文件
- 索引文件由索引和标记文件共同组成,分别对应
idx和mrk后缀.
其他文件
- checksums.txt:一个二进制文件,存储整个分区数据的校验和。用于快速校验数据是否被篡改。
- count.txt:文本文件,存储该分区下的行数,可以用文本编辑器打开。在执行select count() from xxx命令时,会直接返回该文件的内容,而不需要遍历数据。
- default_compression_codec.txt:ClickHouse新版本增加的一个文件,该文件是一个文本文件,存储了数据文件中使用的压缩编码器。ClickHouse提供了多种压缩算法供用户选择,默认使用LZ4。
分区
传统的大数据系统也会使用到分区来加速查询,比如说 Hive。但是在 Clickhouse 中的分区并不是为了加速查询而设计的,而是便于对数据的管理。
相反,在使用 Clickhouse 的时候过多的分区反而会降低查询速度,因为过多的分区意味着更多的文件夹(需要打开更多的文件描述符),在 Clickhouse 中不是通过分区加速查询,是通过索引来加速查询的。
在 Clickhouse 中大部分情况下是不需要创建分区的,创建完分区,分区下对应的文件和子目录说明如下:
- 分区目录的格式为分区ID_最小数据块编号_最大数据块编号_层级。
- 数据块编号从1开始自增,新创建的数据库最大和最小编号相同,当发生合并时会将其修改为合并的数据块编号。同时每次合并都会将层级增加1。
数据库和表
ClickHouse中的数据库和表都被组织为文件夹。
每个数据库都会在ClickHouse的data目录中创建一个子目录,ClickHouse默认携带default和system两个数据库。
default就是默认数据库,system是存储ClickHouse服务器相关信息的数据库,例如连接数、资源占用等。
索引
索引机制是ClickHouse查询速度快的一个很重要的原因,Clickhouse 通过主键索引和标记快速查找目标。
主键索引
- 记录每个块的首个值(最小值),索引数据存储于primary.idx文件。
- Clickhouse 在插入数据的时候,会通过 LSM 算法保证插入数据的顺序按照用户定义的顺序排列,这样每个块就是有序的,就可以通过主键索引快速定位到数据在哪个块。
主键索引只能定位到数据在哪个块,但是块的位置需要通过标记确定。
标记
- 通过索引文件和标记文件,才能共同确定一个数据所在的文件位置。
- 在查询时,首先通过索引确认数据所在的块,然后依据标记确认块所在的物理地址,最后通过物理地址从硬盘上读取数据。
与事务数据库存储引擎的对比
| Clickhouse | 事物数据库 | |
|---|---|---|
| 基本单位 | - 最小单位是块,块的大小一般在64KB~1MB之间 - 通过一次性操作整个块以提高I/O效率 | - 基本单位是页,大小一般为4KB或8KB - 对行的操作记录到内存页中,定期以页为单位写入磁盘,以提高I/O效率 |
| 数据顺序 | - 对数据按照表结构进行排序并写入存储设备 | - 事务数据库则按照事务的先后顺序写入存储设备 |
| 索引方式 | - 使用稀疏索引,且数据在写入时已经完成了排序,足以支撑快速的范围查询 | - 使用B+树建立稠密索引,将索引进行排序后以实现更快的范围查询 |
| 控制信息 | - 控制信息占用数据量小 - 不适合点查 | - 控制信息占用数据量大 - 适合点查 |
| 压缩 | - MergeTree将数据压缩后写入存储设备 - 查询瓶颈在于磁盘I/O | - 不对数据压缩 - 通过锁机制和MVCC实现原子性和隔离性,通过WAL机制实现持久性,通过完整性约束提供一致性保证 |
存储引擎如何影响查询速度
Clickhouse 在对数据进行保存的时候就以便利查询为目的进行保存,因此 Clickhouse 可以快速查询到数据所在位置,Clickhouse 查询大量的时间消耗在磁盘 I/O 上,因此如何减少磁盘 I/O 就是存储引擎要做的事情。
预排序
- Clickhouse 在写入数据时会对数据进行排序,这样在进行范围查询的时候就可以将随机读转换为顺序读,提高 I/O 效率。
- 预排序虽然提升了查询性能,相对的降低了写入性能。
- Clickhouse 使用修改过的 LSM 算法实现预排序,不允许数据修改,降低了传统 LSM 算法读放大效应,进一步缩短了磁盘 I/O 时间。
列存
- 列式存储中每一列的数据是在同一个文件中保存着的,在磁盘上数据是连续的,特别适合 OLAP 查询。
- 由于列存的保存方式,表中列的增加不会带来额外的开销,因此 Clickhouse 特别适合创建大宽表,便于查询分析。
压缩
- 压缩可以减少读取和写入的数据量,从而减少I/O时间,由于列存数据相关性很高,因此 Clickhouse 对于数据压缩支持很好,拥有比较大的压缩比。
- ClickHouse的最小处理单元是块,块一般由8192行数据组成,ClickHouse进行一次压缩针对的是8192行数据,这就极大降低了CPU的压缩和解压缩时间。
MergeTree存储引擎的工作过程
数据库、数据表的创建过程
- 数据库和数据表在MergeTree存储引擎中对应一个文件夹,当执行下列SQL语句时,本质上就是由MergeTree存储引擎在磁盘上的数据目录中创建一个对应的文件夹。
create database xxx; create table xxx (xxx string ...)
数据插入过程
- 插入操作会在表所在的文件夹下创建一个新的分区文件夹
- 然后按照MergeTree的文件组织原则在分区文件夹中创建对应的数据文件、元数据文件、索引文件和其他文件。
分区合并和删除过程
- Clickhouse 存在两种分区:逻辑分区和物理分区,逻辑分区是按照用户建表时所设置的规则进行的分区,物理分区是MergeTree存储引擎在实现内部算法时,不可避免地对用户逻辑分区进行物理拆分而得到的分区。
- MergeTree的分区合并指的是物理分区的合并,不支持对逻辑分区进行合并。
- MergeTree的分区删除指的是逻辑分区的合并,不支持对物理分区进行删除。
- 分区合并是MergeTree引擎自行启动的,而分区删除是按照用户指令启动的,用户无法直接操作物理分区,只能通过控制逻辑分区,间接控制物理分区
数据读取过程
- Clickhouse 通过索引进行加速查询,在写入数据的时候会预排序,MergeTree引擎的查询加速效果与表结构密切相关,同一条查询语句,在不同的表结构上有着不同的表现。
我们在定义表的时候一定要注意 ORDER BY的使用,假设有一张用户信息表如下:
| id | sex | age |
|---|---|---|
| 1 | Male | 27 |
| 2 | Femal | 33 |
查询 SQL 如下:
SELECT AVG(age) FROM tb1 WHERE sex = 'Male';
-
sex作为唯一排序键(主键)
CREATE TABLE tb1 ( id UInt 64, sex String comment '性别', age int comment '年龄' )ENGINE = MergeTree() ORDER BY sex; -
sex作为联合排序键(主键)之一且在最左侧
-- Clickhouse 的索引匹配也满足最左侧匹配原则,下边的建表方式查询时也会走索引 CREATE TABLE tb1 ( id UInt 64, sex String comment '性别', age int comment '年龄' )ENGINE = MergeTree() ORDER BY sex,age; -
sex作为联合排序键(主键)之一且不在最左侧
CREATE TABLE tb1 ( id UInt 64, sex String comment '性别', age int comment '年龄' )ENGINE = MergeTree() ORDER BY age,sex;使用上边SQL语句创建tbl表。在这种情况下,tbl表中的sex列作为排序键之一且不在最左侧,需要依据主键左侧列和sex列的数据分布进行判断,是一个不确定的场景。
最好的情况是左侧主键和sex存在很强的相关性,此时性能接近于sex作为联合排序键(主键)之一且在最左侧的情况。
最差的情况是完全独立的两个列,且sex分布于每一个块中,此时会触发全表扫描,性能接近于未将sex作为排序键的情况。 -
sex不属于排序键(主键)
-- 上边的查询会触发全表扫描,性能最差 CREATE TABLE tb1 ( id UInt 64, sex String comment '性别', age int comment '年龄' )ENGINE = MergeTree() ORDER BY age;