测试模型
- 1.导入新图片名称
- 2.加载新的图片
- 3.加载图片
- 4.使用模型进行预测
- 5.获取最可能的类别
- 6.显示图片和预测的标签名称
- 7.图像加载失败输出
导入新的图像,显示图像和预测的类别标签。
1.导入新图片名称
new_image_path = '456.jpg'
2.加载新的图片
new_image = cv2.imread(new_image_path)
3.加载图片
# 检查图片是否成功加载
if new_image is not None:
# 将图片转换为RGB格式
new_image = cv2.cvtColor(new_image, cv2.COLOR_BGR2RGB)
# 调整图片大小到模型期望的大小
new_image = cv2.resize(new_image, (150, 150))
# 将图片数组扩展一个维度,因为模型期望输入形状为 (None, 150, 150, 3)
new_image = np.expand_dims(new_image, axis=0)
4.使用模型进行预测
predictions = model.predict(new_image)
model:这是之前创建和编译的Keras模型。
predict:这是Keras模型中的一个方法,用于对新的输入数据进行预测。
new_image:这是要进行预测的图像数据,它是一个NumPy数组。
5.获取最可能的类别
predicted_class_index = np.argmax(predictions[0])
predictions[0]:这是模型对new_image的预测结果,它是一个NumPy数组。由于模型通常会为每个输入生成一个预测结果,因此predictions是一个包含多个预测结果的列表,而predictions[0]表示对第一个输入的预测。
np.argmax(predictions[0]):这个函数调用用于找到predictions[0]中的最大值对应的索引。在多类分类任务中,这个索引表示模型认为最可能的类别。
predicted_class_index:这个变量存储了模型预测的最可能类别的索引。
predicted_class = classes[predicted_class_index]
classes:这是一个包含所有可能类别的列表。
classes[predicted_class_index]:这个索引操作符用于根据predicted_class_index变量中存储的索引,从classes列表中获取对应的类别名称。
predicted_class:这个变量存储了模型预测的最可能类别的名称。
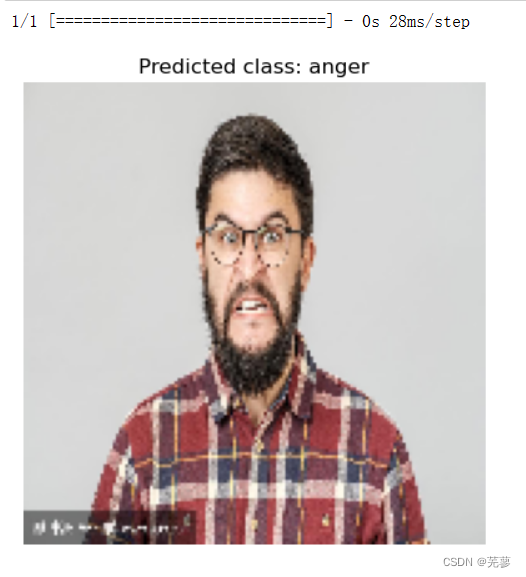
6.显示图片和预测的标签名称
plt.imshow(new_image[0])
plt.title(f"Predicted class: {predicted_class}")
plt.axis('off')
plt.show()
7.图像加载失败输出
else:
"Image not loaded successfully."
运行结果:

我们还可以多导入几张图片进行测试,只需要把导入新图片名称改了就可以。