Transformer 模型最早由 Vaswani 等人在 2017 年论文 Attention Is All You Need 中提出,并已广泛应用于自然语言处理。
2021年,Dosovitsky 等人在论文An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale中提出将 Transformer 用于计算机视觉任务,与卷积网络相比取得了优异的结果。
在本文中,我将从头开始构建一个视觉 Transformer 模型,并在 MNIST 数据集上进行测试。这对于算法本身的理解和算法面试大有好处

喜欢本文记得收藏、点赞、关注,希望大模型技术交流的加入我们。
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了算法面试和技术交流群,相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:来自CSDN + 技术交流
通俗易懂讲解大模型系列
-
重磅消息!《大模型面试宝典》(2024版) 正式发布!
-
重磅消息!《大模型实战宝典》(2024版) 正式发布!
-
做大模型也有1年多了,聊聊这段时间的感悟!
-
用通俗易懂的方式讲解:大模型算法工程师最全面试题汇总
-
用通俗易懂的方式讲解:不要再苦苦寻觅了!AI 大模型面试指南(含答案)的最全总结来了!
-
用通俗易懂的方式讲解:我的大模型岗位面试总结:共24家,9个offer
-
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
-
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
-
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
-
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
-
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
-
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
-
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
-
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
-
用通俗易懂的方式讲解:一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
-
用通俗易懂的方式讲解:LlamaIndex 官方发布高清大图,纵览高级 RAG技术
-
用通俗易懂的方式讲解:为什么大模型 Advanced RAG 方法对于AI的未来至关重要?
-
用通俗易懂的方式讲解:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法
导入库和模块
import torch
import torch.nn as nn
import torchvision.transforms as T
from torch.optim import Adam
from torchvision.datasets.mnist import MNIST
from torch.utils.data import DataLoader
import numpy as np
我们将使用PyTorch来构建我们的视觉Transformer,因此我们需要导入PyTorch库及其他将在本教程中使用的库。
首先,我们导入PyTorch和其神经网络模块:
import torch
import torch.nn as nn
我们还需要导入torchvision.transforms以调整输入图像的大小并将其转换为张量。调整输入图像的大小是可选的,只需确保图像尺寸可以被patch的尺寸整除。
import torchvision.transforms as T
我们将使用Adam作为优化器,因此需要从torch.optim中导入它。
from torch.optim import Adam
我们将从torchvision中导入本教程使用的MNIST数据集。我们将使用PyTorch的DataLoader来帮助加载数据,因此也需要导入它。
from torchvision.datasets.mnist import MNIST
from torch.utils.data import DataLoader
最后,我们需要导入numpy,在创建位置编码时,我们将使用它来执行sin和cos计算。
import numpy as np
Patch Embeddings
class PatchEmbedding(nn.Module):
def __init__(self, d_model, img_size, patch_size, n_channels):
super().__init__()
self.d_model = d_model # 模型维度
self.img_size = img_size # 图像尺寸
self.patch_size = patch_size # Patch尺寸
self.n_channels = n_channels # 通道数
self.linear_project = nn.Conv2d(self.n_channels, self.d_model, kernel_size=self.patch_size, stride=self.patch_size)
# B: 批量大小
# C: 图像通道
# H: 图像高度
# W: 图像宽度
# P_col: Patch列
# P_row: Patch行
def forward(self, x):
x = self.linear_project(x) # (B, C, H, W) -> (B, d_model, P_col, P_row)
x = x.flatten(2) # (B, d_model, P_col, P_row) -> (B, d_model, P)
x = x.transpose(1, 2) # (B, d_model, P) -> (B, P, d_model)
return x
创建视觉Transformer的第一步是将输入图像拆分为patch,并创建这些patch的线性嵌入序列。我们可以使用PyTorch的Conv2d方法实现这一点。
Conv2d方法将输入图像拆分为patch,并提供与模型宽度相等的线性投影。通过将kernel_size和stride设置为patch的大小,我们确保patch的尺寸正确且没有重叠。
self.linear_project = nn.Conv2d(self.n_channels, self.d_model, kernel_size=self.patch_size, stride=self.patch_size)
在forward方法中,我们通过linear_project/Conv2D方法传递形状为(B, C, H, W)的输入,并接收形状为(B, d_model, P_col, P_row)的输出。
def forward(self, x):
x = self.linear_project(x) # (B, C, H, W) -> (B, d_model, P_col, P_row)

我们使用 flatten 方法将补丁列和补丁行维度组合成一个补丁维度,使其形状变为 (B, d_model, P)
x = x.flatten(2) # (B, d_model, P_col, P_row) -> (B, d_model, P)

最后,我们使用 transpose 方法将 d_model 和补丁维度交换,使其形状变为 (B, P, d_model)。
x = x.transpose(-2, -1) # (B, d_model, P) -> (B, P, d_model)

类 Token 和位置编码
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length):
super().__init__()
self.cls_token = nn.Parameter(torch.randn(1, 1, d_model)) # 分类 Token
# 创建位置编码
pe = torch.zeros(max_seq_length, d_model)
for pos in range(max_seq_length):
for i in range(d_model):
if i % 2 == 0:
pe[pos][i] = np.sin(pos / (10000 ** (i / d_model)))
else:
pe[pos][i] = np.cos(pos / (10000 ** ((i - 1) / d_model)))
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x):
# 扩展以使每个图像在批处理中都有分类 Token
tokens_batch = self.cls_token.expand(x.size()[0], -1, -1)
# 将分类 Token 添加到每个嵌入的开头
x = torch.cat((tokens_batch, x), dim=1)
# 将位置编码添加到嵌入中
x = x + self.pe
return x
视觉 Transformer 模型使用标准方法将可学习的分类 Token 添加到补丁嵌入中以进行分类。
self.cls_token = nn.Parameter(torch.randn(1, 1, d_model))

与 LSTM 等模型顺序地接收嵌入不同,Transformer 并行地接收嵌入。虽然这提高了速度,但 Transformer 并不了解序列的顺序。这是一个问题,因为改变图像补丁的顺序很可能会改变图像的内容及其所表示的内容。一个例子是图 5,它显示了改变图像补丁顺序可以将图像从一个 O 改变为更像 X 的东西。
为了解决这个问题,需要将位置编码添加到补丁嵌入中。每个位置编码都是唯一的,表示它所代表的位置,这使得模型能够识别每个嵌入应该放在哪个位置。为了将位置编码添加到嵌入中,它们必须具有相同的维度,即 d_model。我们通过使用图 6 中的方程来获取位置编码。

pe = torch.zeros(max_seq_length, d_model)
for pos in range(max_seq_length):
for i in range(d_model):
if i % 2 == 0:
pe[pos][i] = np.sin(pos / (10000 ** (i / d_model)))
else:
pe[pos][i] = np.cos(pos / (10000 ** ((i - 1) / d_model)))
self.register_buffer('pe', pe.unsqueeze(0))
在 forward 方法中,输入是多个图像的补丁嵌入的批量。因为这个原因,我们需要使用 expand 函数来使用 self.cls_token 为批量中的每个图像创建分类 token。
def forward(self, x):
tokens_batch = self.cls_token.expand(x.size()[0], -1, -1)
这些分类 token 然后通过使用 torch.cat 方法添加到每个补丁嵌入的开头。
x = torch.cat((tokens_batch, x), dim=1)
位置编码在输出前添加。
x = x + self.pe
return x
注意力头
class AttentionHead(nn.Module):
def __init__(self, d_model, head_size):
super().__init__()
self.head_size = head_size
self.query = nn.Linear(d_model, head_size)
self.key = nn.Linear(d_model, head_size)
self.value = nn.Linear(d_model, head_size)
def forward(self, x):
# 获取 Queries, Keys 和 Values
Q = self.query(x)
K = self.key(x)
V = self.value(x)
# Queries 和 Keys 的点积
attention = Q @ K.transpose(-2, -1)
# 缩放
attention = attention / (self.head_size ** 0.5)
attention = torch.softmax(attention, dim=-1)
attention = attention @ V
return attention

视觉 Transformer 使用注意力机制,这是一种通信机制,允许模型关注图像的重要部分。注意力得分可以使用图 8 中的公式计算。
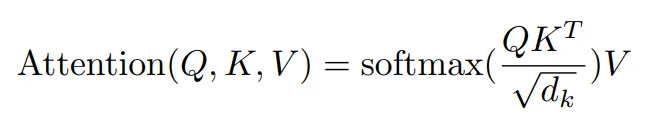
计算注意力的第一步是获取令牌的查询、键和值。令牌的查询表示该令牌所寻找的内容,键表示该令牌所包含的内容,而值表示令牌之间传递的信息。可以通过将令牌传递给线性模块来计算查询、键和值。
def forward(self, x):
# 获取查询、键和值
Q = self.query(x)
K = self.key(x)
V = self.value(x)
我们可以通过获取查询和键的点积来得到序列中令牌之间的关系。
# 查询和键的点积
attention = Q @ K.transpose(-2, -1)
我们需要对这些值进行缩放,以控制初始化时的方差,从而使令牌能够从多个其他令牌中聚合信息。缩放通过将点积除以注意力头大小的平方根来实现。
attention = attention / (self.head_size ** 0.5)
然后,我们需要对缩放后的点积应用软最大化。
attention = torch.softmax(attention, dim=-1)
最后,我们需要获取软最大化和值矩阵之间的点积。这本质上是传递相应令牌之间的信息。
attention = attention @ V
return attention
多头注意力
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
self.head_size = d_model // n_heads
self.W_o = nn.Linear(d_model, d_model)
self.heads = nn.ModuleList([AttentionHead(d_model, self.head_size) for _ in range(n_heads)])
def forward(self, x):
# 合并注意力头
out = torch.cat([head(x) for head in self.heads], dim=-1)
out = self.W_o(out)
return out
多头注意力是在并行运行多个自注意力头并将它们组合在一起。我们可以通过将注意力头添加到模块列表中来实现这一点,
self.heads = nn.ModuleList([AttentionHead(d_model, self.head_size) for _ in range(n_heads)])
然后通过输入并连接结果。
def forward(self, x):
# 合并注意力头
out = torch.cat([head(x) for head in self.heads], dim=-1)
out = self.W_o(out)
return out
Transformer编码器
class TransformerEncoder(nn.Module):
def __init__(self, d_model, n_heads, r_mlp=4):
super().__init__()
self.d_model = d_model
self.n_heads = n_heads
# 子层1归一化
self.ln1 = nn.LayerNorm(d_model)
# 多头注意力
self.mha = MultiHeadAttention(d_model, n_heads)
# 子层2归一化
self.ln2 = nn.LayerNorm(d_model)
# 多层感知器
self.mlp = nn.Sequential(
nn.Linear(d_model, d_model * r_mlp),
nn.GELU(),
nn.Linear(d_model * r_mlp, d_model)
)
def forward(self, x):
# 子层1后的残差连接
out = x + self.mha(self.ln1(x))
# 子层2后的残差连接
out = out + self.mlp(self.ln2(out))
return out
Transformer编码器由两个子层组成:第一个子层执行多头注意力,第二个子层包含一个多层感知器。多头注意力子层在令牌之间进行通信,而多层感知器子层允许令牌单独“思考”传递给它们的信息。
层归一化是一种优化技术,它独立地对批次中的每个输入进行特征归一化。对于我们的模型,我们将在每个子层的开始通过一个层归一化模块。
# 子层1归一化
self.ln1 = nn.LayerNorm(d_model)
# 子层2归一化
self.ln2 = nn.LayerNorm(d_model)
MLP将由两个线性层和一个GELU层组成。使用GELU而不是RELU是因为它没有RELU在零点不可微的局限性。
# 编码器多层感知器
self.mlp = nn.Sequential(
nn.Linear(width, width * r_mlp),
nn.GELU(),
nn.Linear(width * r_mlp, width)
)
在编码器的forward方法中,输入首先通过第一个层归一化模块,然后执行多头注意力。原始输入加上多头注意力的输出,创建一个残差连接。
然后,这个结果通过另一个层归一化模块,再输入到MLP中。通过将MLP的输出加到第一个残差连接的输出中,创建另一个残差连接。
残差连接用于帮助防止梯度消失问题,通过创建一个梯度可以不受阻碍地反向传播到原始输入的路径。
def forward(self, x):
# 子层1后的残差连接
out = x + self.mha(self.ln1(x))
# 子层2后的残差连接
out = out + self.mlp(self.ln2(out))
return out
视觉Transformer
class VisionTransformer(nn.Module):
def __init__(self, d_model, n_classes, img_size, patch_size, n_channels, n_heads, n_layers):
super().__init__()
assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, "img_size的维度必须能被patch_size的维度整除"
assert d_model % n_heads == 0, "d_model必须能被n_heads整除"
self.d_model = d_model # 模型维度
self.n_classes = n_classes # 类别数量
self.img_size = img_size # 图片大小
self.patch_size = patch_size # patch大小
self.n_channels = n_channels # 通道数量
self.n_heads = n_heads # 注意力头数量
self.n_patches = (self.img_size[0] * self.img_size[1]) // (self.patch_size[0] * self.patch_size[1])
self.max_seq_length = self.n_patches + 1
self.patch_embedding = PatchEmbedding(self.d_model, self.img_size, self.patch_size, self.n_channels)
self.positional_encoding = PositionalEncoding(self.d_model, self.max_seq_length)
self.transformer_encoder = nn.Sequential(*[TransformerEncoder(self.d_model, self.n_heads) for _ in range(n_layers)])
# 分类MLP
self.classifier = nn.Sequential(
nn.Linear(self.d_model, self.n_classes),
nn.Softmax(dim=-1)
)
def forward(self, images):
x = self.patch_embedding(images)
x = self.positional_encoding(x)
x = self.transformer_encoder(x)
x = self.classifier(x[:, 0])
return x
在创建视觉Transformer类时,我们首先需要确保输入图像可以均匀地分割成patch大小的块,并且模型的维度可以被注意力头的数量整除。
assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, "img_size的维度必须能被patch_size的维度整除"
assert d_model % n_heads == 0, "d_model必须能被n_heads整除"
我们还需要计算位置编码的最大序列长度,该长度等于patch的数量加一。可以通过将输入图像的高度和宽度的乘积除以patch大小的高度和宽度的乘积来找到patch的数量。
self.n_patches = (self.img_size[0] * self.img_size[1]) // (self.patch_size[0] * self.patch_size[1])
self.max_seq_length = self.n_patches + 1
视觉Transformer还需要能够包含多个编码器模块。这可以通过将一系列编码器层放入顺序包装器中实现。
self.encoder = nn.Sequential(*[TransformerEncoder(self.d_model, self.n_heads) for _ in range(n_layers)])
视觉Transformer模型的最后部分是MLP分类头。这由一个线性层和一个softmax层组成。
self.classifier = nn.Sequential(
nn.Linear(self.d_model, self.n_classes),
nn.Softmax(dim=-1)
)
在forward方法中,输入图像首先通过patch嵌入层,将图像分割成patch并获取这些patch的线性嵌入序列。然后,它们通过位置编码层添加分类令牌和位置编码,再通过编码器模块。分类令牌然后通过分类MLP确定图像的类别。
def forward(self, images):
x = self.patch_embedding(images)
x = self.positional_encoding(x)
x = self.encoder(x)
x = self
.classifier(x[:, 0])
return x
我们完成了模型的构建。现在我们需要训练和测试它。
训练参数
d_model = 9
n_classes = 10
img_size = (32, 32)
patch_size = (16, 16)
n_channels = 1
n_heads = 3
n_layers = 3
batch_size = 128
epochs = 5
alpha = 0.005
加载MNIST数据集
transform = T.Compose([
T.Resize(img_size),
T.ToTensor()
])
train_set = MNIST(
root="./../datasets", train=True, download=True, transform=transform
)
test_set = MNIST(
root="./../datasets", train=False, download=True, transform=transform
)
train_loader = DataLoader(train_set, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_set, shuffle=False, batch_size=batch_size)
训练
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using device: ", device, f"({torch.cuda.get_device_name(device)})" if torch.cuda.is_available() else "")
transformer = VisionTransformer(d_model, n_classes, img_size, patch_size, n_channels, n_heads, n_layers).to(device)
optimizer = Adam(transformer.parameters(), lr=alpha)
criterion = nn.CrossEntropyLoss()
for epoch in range(epochs):
training_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = transformer(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
training_loss += loss.item()
print(f'Epoch {epoch + 1}/{epochs} loss: {training_loss / len(train_loader) :.3f}')
测试
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = transformer(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'\nModel Accuracy: {100 * correct // total} %')
结果
使用此模型,我们在仅训练5个epoch后,在MNIST数据集上实现了约92%的准确率。这个示例展示了自注意力可以作为深度卷积网络的替代方案。