本博客需要对位置编码有一定了解,但不熟悉代码实现的老哥看。
正弦位置编码(sinusoidal)
在介绍RoPE之前,先回顾一下正弦位置编码。
数学表达
P
E
(
p
o
s
,
2
i
)
=
s
i
n
(
p
o
s
1000
0
2
i
/
d
m
o
d
e
l
)
PE(pos, 2i) = sin({pos \over 10000^{2i/d_{model}}})
PE(pos,2i)=sin(100002i/dmodelpos)
P
E
(
p
o
s
,
2
i
+
1
)
=
c
o
s
(
p
o
s
1000
0
2
i
/
d
m
o
d
e
l
)
PE(pos, 2i+1) = cos({pos \over 10000^{2i/d_{model}}})
PE(pos,2i+1)=cos(100002i/dmodelpos)
上面两个公式是正弦位置编码的数学表达式,其中
- p o s pos pos表示位置,比如长度为68的序列, p o s ∈ [ 0 , 67 ) pos \in [0,67) pos∈[0,67)
- d m o d e l d_{model} dmodel表示位置编码的维度(模型的宽度、模型的特征维度、模型隐藏层的维度),比如设置位置编码的维度是100。
- i i i表示位置编码在 d m o d e l d_{model} dmodel维度上两两分组的编号, i ∈ [ 0 , d m o d e l / / 2 − 1 ] i \in [0, d_{model}//2-1] i∈[0,dmodel//2−1],一定要强化这个概念, i i i表示的是 d m o d e l d_{model} dmodel维度上两两分组的编号。
- 可以命名 θ i = 1 1000 0 2 i / d m o d e l = 1 1000 0 i / ( d m o d e l / 2 ) \theta_{i} = {1 \over 10000^{2i/d_{model}}} = {1 \over 10000^{i/(d_{model}/2)}} θi=100002i/dmodel1=10000i/(dmodel/2)1,所以上面两个公式可以看做是位置 p o s pos pos和分组变量 i i i的函数。
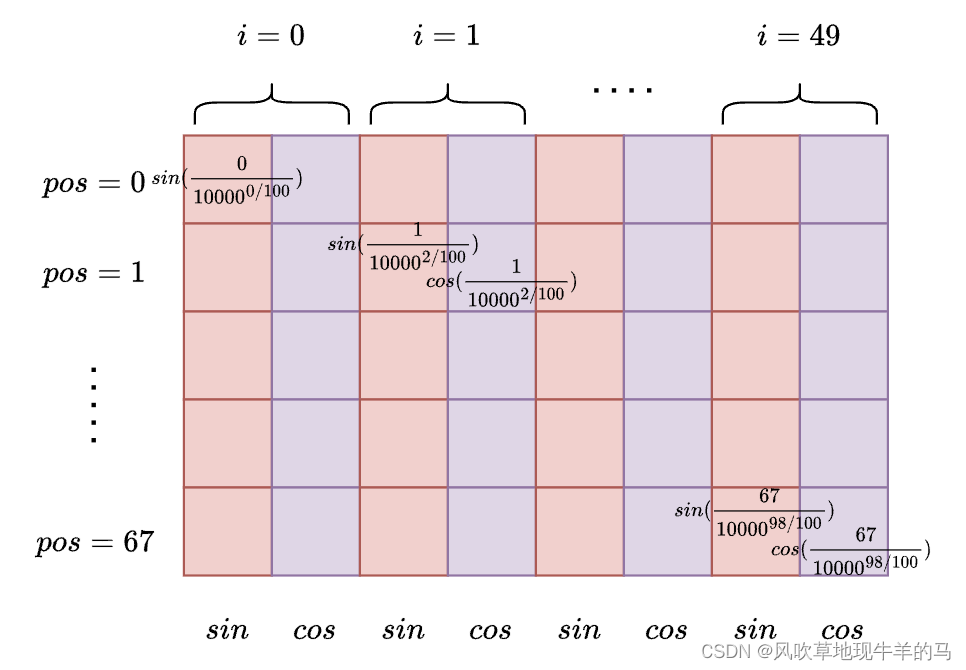
可以将上述两个公式看做是二维平面,比如,将 i i i看做横坐标,将 p o s pos pos看做纵坐标。并且需要注意,上述矩阵,每一个位置都是有值的。
代码实现
import torch
import torch.nn as nn
def get_SinPositionEncoding(max_sequence_length, d_model, base=10000):
# [max_sequence_length, d_model]
pe = torch.zeros(max_sequence_length, d_model, dtype=torch.float)
# [0, 1, 2, ... ,d_model//2-1] shape = [d_model//2]
ids_x = torch.arange(d_model // 2, dtype=torch.float) # 获得相当于x维度的ids,取值是 [0, d_model//2-1]
exp_value = ids_x / (d_model / 2) # 获得base的指数幂次
alpha = 1 / (base ** exp_value)
# a^x = e^{x*ln(a)}
# alpha = torch.exp(torch.arange(0, self.d_model, 2) * -(math.log(self.base) / self.d_model))
# [0, 1, 2, ..., max_sequence_length-1] shape = [max_sequence_length]
pos_y = torch.arange(max_sequence_length, dtype=torch.float)
inputs = pos_y[:, None] @ alpha[None, :] # @表示矩阵乘法,*表示对应元素乘
embedding_sin = torch.sin(inputs)
embedding_cos = torch.cos(inputs)
pe[:, 0::2] = embedding_sin # 偶数位置设置为sin
pe[:, 1::2] = embedding_cos # 奇数位置设置为cos
return pe
RoPE位置编码
数学表达
在介绍RoPE的数学表达之前,需要了解,RoPE是应用在计算attention scores之前的一步进行的。RoPE通过在q和k向量上应用RoPE,使得应用RoPE之后的q和k有位置信息。
- 未应用RoPE的query和key向量记为: q , k q, k q,k
- 应用RoPE之后的query和key向量记为: q r o p e , k r o p e q_{rope}, k_{rope} qrope,krope,有 q r o p e = R o P E ( q ) , k r o p e = R o P E ( k ) q_{rope} = RoPE(q), k_{rope} = RoPE(k) qrope=RoPE(q),krope=RoPE(k)
- 计算attention score:
a t t e n t i o n s c o r e = q r o p e k r o p e T attention\ score = q_{rope}k^{T}_{rope} attention score=qropekropeT
这里计算的attention score里面就融合了相对位置信息,之后的计算流程和传统的self attention的计算流程无差别。
接下来看下,前面提到的RoPE函数如何实现?在正弦位置编码那一节提到,正弦位置编码其实是位置 p o s pos pos和分组变量 i i i的函数,那么RoPE也是如此。
假设第
m
m
m个token(位置是
m
m
m)的query和key向量分别是
q
和
k
q和k
q和k,对于
d
d
d维的
q
q
q向量来说,
q
r
o
p
e
q_{rope}
qrope是通过下面的公式获得的:

- 在上式中,左侧矩阵记为 R θ q R_{\theta}^{q} Rθq,其维度是 d ∗ d d*d d∗d维的矩阵,右侧列向量表示query向量。
- 红色框,表示一组分组,编号记为 i i i, i ∈ [ 0 , d / / 2 − 1 ] i \in [0, d//2-1] i∈[0,d//2−1]
- θ i = 1 1000 0 2 i / d m o d e l = 1 1000 0 i / ( d m o d e l / 2 ) \theta_{i} = {1 \over 10000^{2i/d_{model}}} = {1 \over 10000^{i/(d_{model}/2)}} θi=100002i/dmodel1=10000i/(dmodel/2)1 ,该定义与正弦位置编码一节的定义相同。
本博客没有涉及到复数运算等数学内容,从结果到原因,若需要由原因到结果,网络上有很多讲解清楚的博客。
由于矩阵的稀疏性,会造成计算上的浪费,所以在计算时采用逐位相乘再相加的方式进行:
[
q
0
q
1
q
2
q
3
.
.
q
d
−
2
q
d
−
1
]
∗
[
c
o
s
m
θ
0
c
o
s
m
θ
0
c
o
s
m
θ
1
c
o
s
m
θ
1
.
.
c
o
s
m
θ
d
/
2
−
1
c
o
s
m
θ
d
/
2
−
1
]
+
[
−
q
1
q
0
−
q
3
q
2
.
.
−
q
d
−
1
q
d
−
2
]
∗
[
s
i
n
m
θ
0
s
i
n
m
θ
0
s
i
n
m
θ
1
s
i
n
m
θ
1
.
.
s
i
n
m
θ
d
/
2
−
1
s
i
n
m
θ
d
/
2
−
1
]
(
1
)
\begin{bmatrix} %该矩阵一共3列,每一列都居中放置 q_0\\ %第一行元素 q_1\\ %第二行元素 q_2 \\ q_3 \\ .. \\ q_{d-2}\\ q_{d-1} \end{bmatrix} * \begin{bmatrix} %该矩阵一共3列,每一列都居中放置 cosm\theta_0\\ %第一行元素 cosm\theta_0\\ %第二行元素 cosm\theta_1 \\ cosm\theta_1 \\ .. \\ cosm\theta_{d/2-1}\\ cosm\theta_{d/2-1} \end{bmatrix} + \begin{bmatrix} %该矩阵一共3列,每一列都居中放置 -q_1\\ %第一行元素 q_0\\ %第二行元素 -q_3 \\ q_2 \\ .. \\ -q_{d-1}\\ q_{d-2} \end{bmatrix} * \begin{bmatrix} %该矩阵一共3列,每一列都居中放置 sinm\theta_0\\ %第一行元素 sin m\theta_0\\ %第二行元素 sinm\theta_1 \\ sinm\theta_1 \\ .. \\ sinm\theta_{d/2-1}\\ sinm\theta_{d/2-1} \end{bmatrix} \ \ \ \ \ \ \ \ \ \ \ \ (1)
q0q1q2q3..qd−2qd−1
∗
cosmθ0cosmθ0cosmθ1cosmθ1..cosmθd/2−1cosmθd/2−1
+
−q1q0−q3q2..−qd−1qd−2
∗
sinmθ0sinmθ0sinmθ1sinmθ1..sinmθd/2−1sinmθd/2−1
(1)
- 在公式(1)中,记
c
o
s
cos
cos那一列是
c
o
s
(
m
,
θ
)
cos(m,\theta)
cos(m,θ),
s
i
n
sin
sin那一列是
s
i
n
(
m
,
θ
)
sin(m, \theta)
sin(m,θ),第三列query那一列记为
q
i
n
v
q_{inv}
qinv,
所以,最终, R o P E RoPE RoPE的实现非常简单,
q ∗ c o s ( m , θ ) + q i n v ∗ s i n ( m , θ ) ( 2 ) q*cos(m, \theta) + q_{inv}*sin(m, \theta) \ \ \ \ \ \ \ \ \ \ (2) q∗cos(m,θ)+qinv∗sin(m,θ) (2)
那么如何获得对于的
c
o
s
(
m
,
θ
)
cos(m, \theta)
cos(m,θ)与
s
i
n
(
m
,
θ
)
sin(m, \theta)
sin(m,θ)?
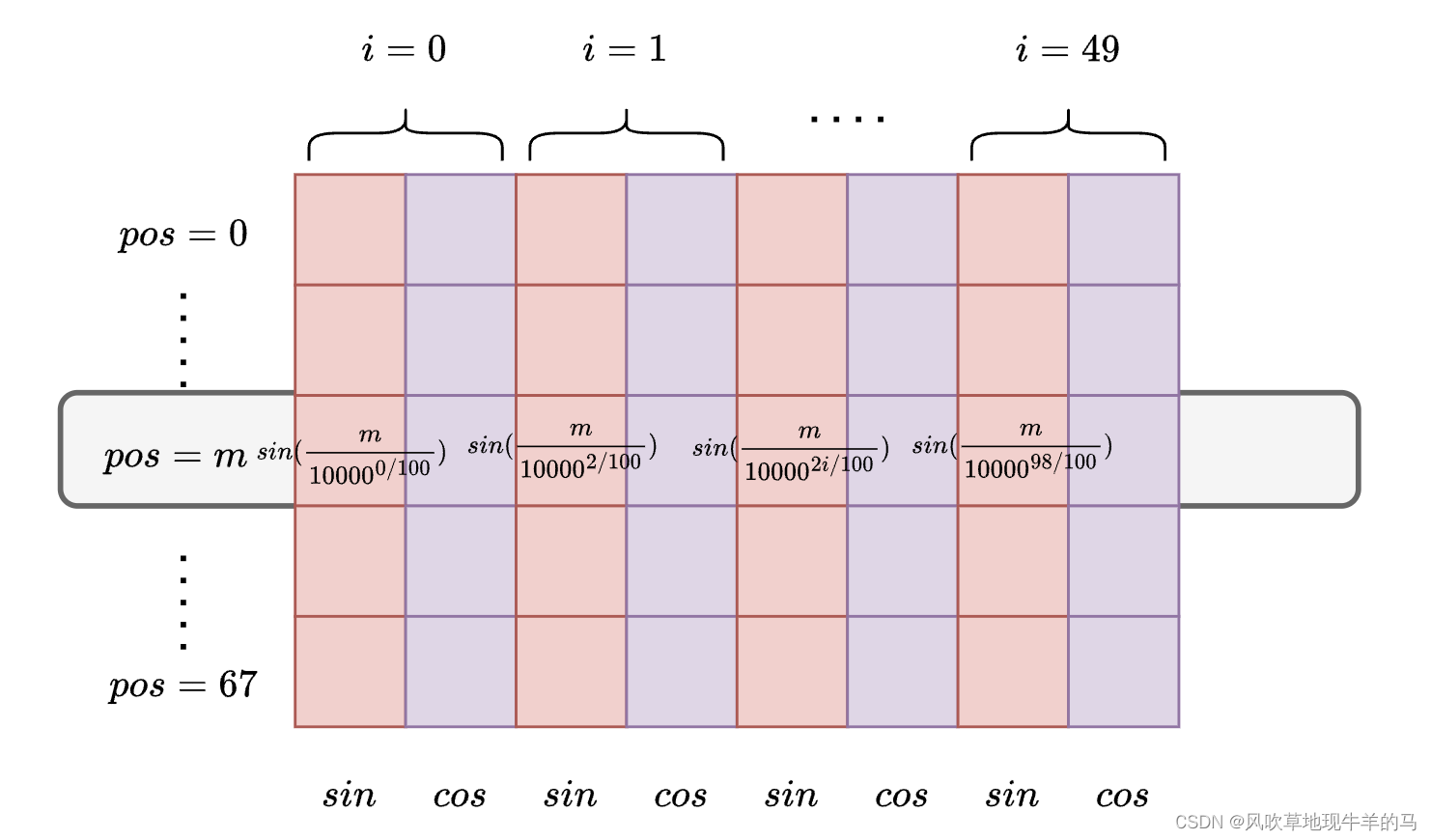
回顾正弦位置编码那一节的二维平面图,即可发现,
s
i
n
(
m
,
θ
)
sin(m, \theta)
sin(m,θ)即是上图中的第
m
m
m行中的偶数列,而
c
o
s
(
m
,
θ
)
cos(m, \theta)
cos(m,θ)即是上图中的第
m
m
m行的奇数列,所以,我们可以借助正弦位置编码那一节中的
g
e
t
_
S
i
n
P
o
s
i
t
i
o
n
E
n
c
o
d
i
n
g
get\_SinPositionEncoding
get_SinPositionEncoding函数,提前获得这样的一个矩阵,然后再按需取对应的行列,组成
s
i
n
(
m
,
θ
)
sin(m, \theta)
sin(m,θ)和
c
o
s
(
m
,
θ
)
cos(m, \theta)
cos(m,θ)。
注意,
- 这里的上图中的 s i n ( m , θ ) sin(m, \theta) sin(m,θ)与公式(2)中的略有区别,公式(2)中的 s i n ( m , θ ) sin(m, \theta) sin(m,θ)是 d d d维的,而这里的从矩阵取出的 s i n ( m , θ ) sin(m, \theta) sin(m,θ)是 d / / 2 d//2 d//2维的。
- 回想一下,要将一个二维向量旋转,可以将其用乘以 c o s ( θ ) 和 s i n ( θ ) cos(\theta)和sin(\theta) cos(θ)和sin(θ)的式子表示,这里的 c o s ( θ ) 和 s i n ( θ ) cos(\theta)和sin(\theta) cos(θ)和sin(θ)记为旋转矩阵, θ \theta θ表示相对与基向量的旋转角度。见二维向量旋转。
所以,对于RoPE来说,位置 m m m的第 i i i个分组,其旋转角度就是 m θ i m\theta_{i} mθi。
因此,最终attention score的计算公式也可以表达为下面的式子:
a
t
t
e
n
t
i
o
n
s
c
o
r
e
=
R
o
P
E
(
q
,
m
)
∗
R
o
P
E
(
k
,
n
)
T
=
R
e
[
∑
i
=
0
d
/
2
−
1
q
[
2
i
:
2
i
+
1
]
k
[
2
i
:
2
i
+
1
]
∗
e
i
(
m
−
n
)
θ
i
]
(
3
)
attention\ score = RoPE(q, m)*RoPE(k, n)^{T} \\ = Re[\sum_{i=0}^{d/2-1}q_{[2i:2i+1] }k^{*}_{[2i:2i+1]}e^{\mathbf{i}(m-n)\theta_{i}}] \ \ \ \ \ \ \ \ \ (3)
attention score=RoPE(q,m)∗RoPE(k,n)T=Re[i=0∑d/2−1q[2i:2i+1]k[2i:2i+1]∗ei(m−n)θi] (3)
在上式中, R e Re Re表示实部, i \mathbf{i} i表示虚数单位。公式(3)在下面还要介绍,公式(3)具有的一些周期性,对于LLM的上下文扩展具有重要的作用。
非LLaMa代码实现
公式
import torch
import torch.nn as nn
def get_SinPositionEncoding(max_sequence_length, d_model, base=10000):
# [max_sequence_length, d_model]
pe = torch.zeros(max_sequence_length, d_model, dtype=torch.float)
# [0, 1, 2, ... ,d_model//2-1] shape = [d_model//2]
ids_x = torch.arange(d_model // 2, dtype=torch.float) # 获得相当于x维度的ids,取值是 [0, d_model//2-1]
exp_value = ids_x / (d_model / 2) # 获得base的指数幂次
alpha = 1 / (base ** exp_value)
# 下面的这行公式同理,但是可以避免数值溢出,数学原理是:a^x = e^{x*ln(a)}
# alpha = torch.exp(torch.arange(0, self.d_model, 2) * -(math.log(self.base) / self.d_model))
# [0, 1, 2, ..., max_sequence_length-1] shape = [max_sequence_length]
pos_y = torch.arange(max_sequence_length, dtype=torch.float)
inputs = pos_y[:, None] @ alpha[None, :] # @表示矩阵乘法,*表示对应元素乘
embedding_sin = torch.sin(inputs)
embedding_cos = torch.cos(inputs)
pe[:, 0::2] = embedding_sin # 偶数位置设置为sin
pe[:, 1::2] = embedding_cos # 奇数位置设置为cos
return pe
def RoPE(q, k):
# q,k: (bs, head, max_len, output_dim)
batch_size = q.shape[0]
nums_head = q.shape[1]
max_len = q.shape[2]
d_model = q.shape[-1]
# (max_len, d_model)
pos_emb = get_SinPositionEncoding(max_len, d_model)
# (1, 1, max_len, d_model)
pos_emb = pos_emb.unsqueeze(0).unsqueeze(0)
# cos_pos,sin_pos: (bs, nums_head, max_len, d_model)
# 看rope公式可知,相邻cos,sin之间是相同的,所以复制一遍。如(1,2,3)变成(1,1,2,2,3,3)
cos_pos = pos_emb[..., 1::2].repeat_interleave(2, dim=-1) # 将奇数列信息抽取出来也就是cos 拿出来并复制
sin_pos = pos_emb[..., 0::2].repeat_interleave(2, dim=-1) # 将偶数列信息抽取出来也就是sin 拿出来并复制
# q,k: (bs, head, max_len, d_model)
q_inv = torch.stack([-q[..., 1::2], q[..., ::2]], dim=-1)
q_inv = q_inv.reshape(q.shape) # reshape后就是正负交替了
# 更新q, *对应位置相乘
q = q * cos_pos + q_inv * sin_pos
k_inv = torch.stack([-k[..., 1::2], k[..., ::2]], dim=-1)
k_inv = k_inv.reshape(k.shape)
# 更新k, *对应位置相乘
k = k * cos_pos + k_inv * sin_pos
return q, k
q = torch.randn(2, 6, 13, 4)
k = torch.randn(2, 6, 13, 4)
q,k = RoPE(q, k)
LLaMA3代码实现(transformers库中的实现)
LLaMA3对于RoPE的实现,与上面的实现有所不同,但是两种方式得到的 q r o p e 与 k r o p e q_{rope}与k_{rope} qrope与krope的向量内积结果是一样的。
[
q
0
q
1
q
2
.
.
q
d
/
2
−
2
q
d
/
2
−
1
q
d
/
2
q
d
/
2
+
1
.
.
q
d
−
2
q
d
−
1
]
∗
[
c
o
s
m
θ
0
c
o
s
m
θ
1
c
o
s
m
θ
2
.
.
c
o
s
m
θ
d
/
2
−
2
c
o
s
m
θ
d
/
2
−
1
c
o
s
m
θ
0
c
o
s
m
θ
1
.
.
c
o
s
m
θ
d
/
2
−
2
c
o
s
m
θ
d
/
2
−
1
]
+
[
−
q
d
/
2
−
q
d
/
2
+
1
−
q
d
/
2
+
2
.
.
−
q
d
−
2
−
q
d
−
1
q
0
q
1
.
.
q
d
/
2
−
2
q
d
/
2
−
1
]
∗
[
s
i
n
m
θ
0
s
i
n
m
θ
1
s
i
n
m
θ
2
.
.
s
i
n
m
θ
d
/
2
−
2
s
i
n
m
θ
d
/
2
−
1
s
i
n
m
θ
0
s
i
n
m
θ
1
.
.
s
i
n
m
θ
d
/
2
−
2
s
i
n
m
θ
d
/
2
−
1
]
(
4
)
\begin{bmatrix} %该矩阵一共3列,每一列都居中放置 q_0\\ %第一行元素 q_1\\ %第二行元素 q_2 \\ .. \\ q_{d/2-2} \\ q_{d/2-1} \\ q_{d/2} \\ q_{d/2+1} \\ .. \\ q_{d-2}\\ q_{d-1} \end{bmatrix} * \begin{bmatrix} %该矩阵一共3列,每一列都居中放置 cosm\theta_0\\ %第一行元素 cosm\theta_1\\ %第二行元素 cosm\theta_2 \\ .. \\ cosm\theta_{d/2-2}\\ cosm\theta_{d/2-1} \\ cosm\theta_0\\ %第一行元素 cosm\theta_1\\ %第二行元素 .. \\ cosm\theta_{d/2-2}\\ cosm\theta_{d/2-1} \end{bmatrix} + \begin{bmatrix} %该矩阵一共3列,每一列都居中放置 -q_{d/2} \\ -q_{d/2+1} \\ -q_{d/2+2} \\ .. \\ -q_{d-2}\\ -q_{d-1} \\ q_0\\ %第一行元素 q_1\\ %第二行元素 .. \\ q_{d/2-2} \\ q_{d/2-1} \\ \end{bmatrix} * \begin{bmatrix} %该矩阵一共3列,每一列都居中放置 sinm\theta_0\\ %第一行元素 sinm\theta_1\\ %第二行元素 sinm\theta_2 \\ .. \\ sinm\theta_{d/2-2}\\ sinm\theta_{d/2-1} \\ sinm\theta_0\\ %第一行元素 sinm\theta_1\\ %第二行元素 .. \\ sinm\theta_{d/2-2}\\ sinm\theta_{d/2-1} \end{bmatrix} \ \ \ \ \ \ \ \ \ \ \ \ (4)
q0q1q2..qd/2−2qd/2−1qd/2qd/2+1..qd−2qd−1
∗
cosmθ0cosmθ1cosmθ2..cosmθd/2−2cosmθd/2−1cosmθ0cosmθ1..cosmθd/2−2cosmθd/2−1
+
−qd/2−qd/2+1−qd/2+2..−qd−2−qd−1q0q1..qd/2−2qd/2−1
∗
sinmθ0sinmθ1sinmθ2..sinmθd/2−2sinmθd/2−1sinmθ0sinmθ1..sinmθd/2−2sinmθd/2−1
(4)
公式(1)与公式(4)有下面几点不同:
- 公式(1)中,cos和sin列是两两重复,公式(4)中,cos和sin列是拼接
- 公式(1)中, q i n v q_{inv} qinv列是奇偶、负正交错,公式(4)中,是 q q q后半部分为负与前半部分拼接在一起。
import torch
import torch.nn as nn
class LlamaRotaryEmbedding(nn.Module):
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
super().__init__()
self.scaling_factor = scaling_factor
self.dim = dim
self.max_position_embeddings = max_position_embeddings
self.base = base
inv_freq = 1.0 / (self.base ** (torch.arange(0, self.dim, 2, dtype=torch.int64).float().to(device) / self.dim))
self.register_buffer("inv_freq", inv_freq, persistent=False)
# For BC we register cos and sin cached
self.max_seq_len_cached = max_position_embeddings
@torch.no_grad()
def forward(self, x, position_ids):
# x: [bs, num_attention_heads, seq_len, head_size]
# position_ids: [bs, seq_len]
# [bs, dim//2, 1]
inv_freq_expanded = self.inv_freq[None, :, None].float().expand(position_ids.shape[0], -1, 1)
# [bs, 1, seq_len]
position_ids_expanded = position_ids[:, None, :].float()
# Force float32 since bfloat16 loses precision on long contexts
# See https://github.com/huggingface/transformers/pull/29285
device_type = x.device.type
device_type = device_type if isinstance(device_type, str) and device_type != "mps" else "cpu"
with torch.autocast(device_type=device_type, enabled=False):
# [bs, seq_len, dim//2]
freqs = (inv_freq_expanded.float() @ position_ids_expanded.float()).transpose(1, 2)
# [bs, seq_len, dim]
emb = torch.cat((freqs, freqs), dim=-1)
cos = emb.cos()
sin = emb.sin()
return cos.to(dtype=x.dtype), sin.to(dtype=x.dtype)
def rotate_half(x):
"""Rotates half the hidden dims of the input."""
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
return torch.cat((-x2, x1), dim=-1)
def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
"""Applies Rotary Position Embedding to the query and key tensors.
Args:
q (`torch.Tensor`): The query tensor.
k (`torch.Tensor`): The key tensor.
cos (`torch.Tensor`): The cosine part of the rotary embedding.
sin (`torch.Tensor`): The sine part of the rotary embedding.
position_ids (`torch.Tensor`, *optional*):
Deprecated and unused.
unsqueeze_dim (`int`, *optional*, defaults to 1):
The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
Returns:
`tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
"""
cos = cos.unsqueeze(unsqueeze_dim)
sin = sin.unsqueeze(unsqueeze_dim)
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
RoPE的性质
RoPE的特性
这里需要再次回顾一下公式(3)
a
t
t
e
n
t
i
o
n
s
c
o
r
e
=
R
o
P
E
(
q
,
m
)
∗
R
o
P
E
(
k
,
n
)
T
=
R
e
[
∑
i
=
0
d
/
2
−
1
q
[
2
i
:
2
i
+
1
]
k
[
2
i
:
2
i
+
1
]
∗
e
i
(
m
−
n
)
θ
i
]
(
3
)
attention\ score = RoPE(q, m)*RoPE(k, n)^{T} \\ = Re[\sum_{i=0}^{d/2-1}q_{[2i:2i+1] }k^{*}_{[2i:2i+1]}e^{\mathbf{i}(m-n)\theta_{i}}] \ \ \ \ \ \ \ \ \ (3)
attention score=RoPE(q,m)∗RoPE(k,n)T=Re[i=0∑d/2−1q[2i:2i+1]k[2i:2i+1]∗ei(m−n)θi] (3)
在上式中,我们需要关注的是
e
i
(
m
−
n
)
θ
i
e^{\mathbf{i}(m-n)\theta_{i}}
ei(m−n)θi,
θ
i
=
1
b
a
s
e
2
i
/
d
m
o
d
e
l
\theta_{i}={1 \over base^{2i/d_{model}}}
θi=base2i/dmodel1,默认情况下,
b
a
s
e
=
10000
base=10000
base=10000。
令
f
(
b
a
s
e
,
i
,
m
−
n
)
=
e
i
(
m
−
n
)
θ
i
(
5
)
f(base, i, m-n) = e^{\mathbf{i}(m-n)\theta_{i}} \ \ \ \ \ \ \ \ \ \ (5)
f(base,i,m−n)=ei(m−n)θi (5)
对于
f
f
f函数来说,其可以用欧拉公式(
e
i
ϕ
=
c
o
s
(
ϕ
)
+
i
s
i
n
(
ϕ
)
e^{\mathbf i \phi}=cos(\phi)+\mathbf{i}sin(\phi)
eiϕ=cos(ϕ)+isin(ϕ))进行变换,对于第
i
i
i组分量来说(也就是当
i
i
i和
b
a
s
e
base
base固定时),
f
f
f函数其实就是单位圆上的一个点,这个点会随着
m
−
n
m-n
m−n在圆上转圈,如下图所示。
θ
i
\theta_{i}
θi决定了转圈的速度快慢(也就是周期)。
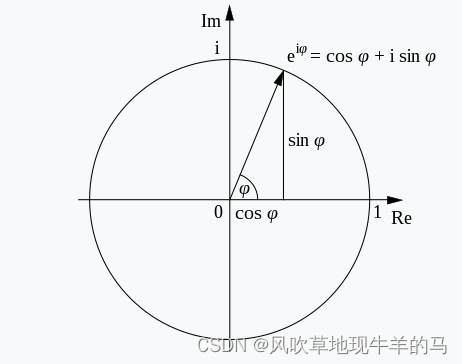
周期和频率有下面的特性:
- 当
i
i
i固定时
- b a s e ↑ base \uparrow base↑时, θ i ↓ \theta_{i} \downarrow θi↓,转圈越慢、周期越长、频率越低。
- b a s e ↓ base \downarrow base↓时, θ i ↑ \theta_{i} \uparrow θi↑,转圈越快、周期越短、频率越高。
- 当
b
a
s
e
base
base固定时
- i ↑ i \uparrow i↑时, θ i ↓ \theta_{i} \downarrow θi↓(趋于0),转圈越慢、周期越长、频率越低。
- i ↓ i \downarrow i↓时, θ i ↑ \theta_{i} \uparrow θi↑(趋于1),转圈越快、周期越短、频率越高。
当base固定时,我们也可以看下面的图,下面的图表示了不同的分量的变化。
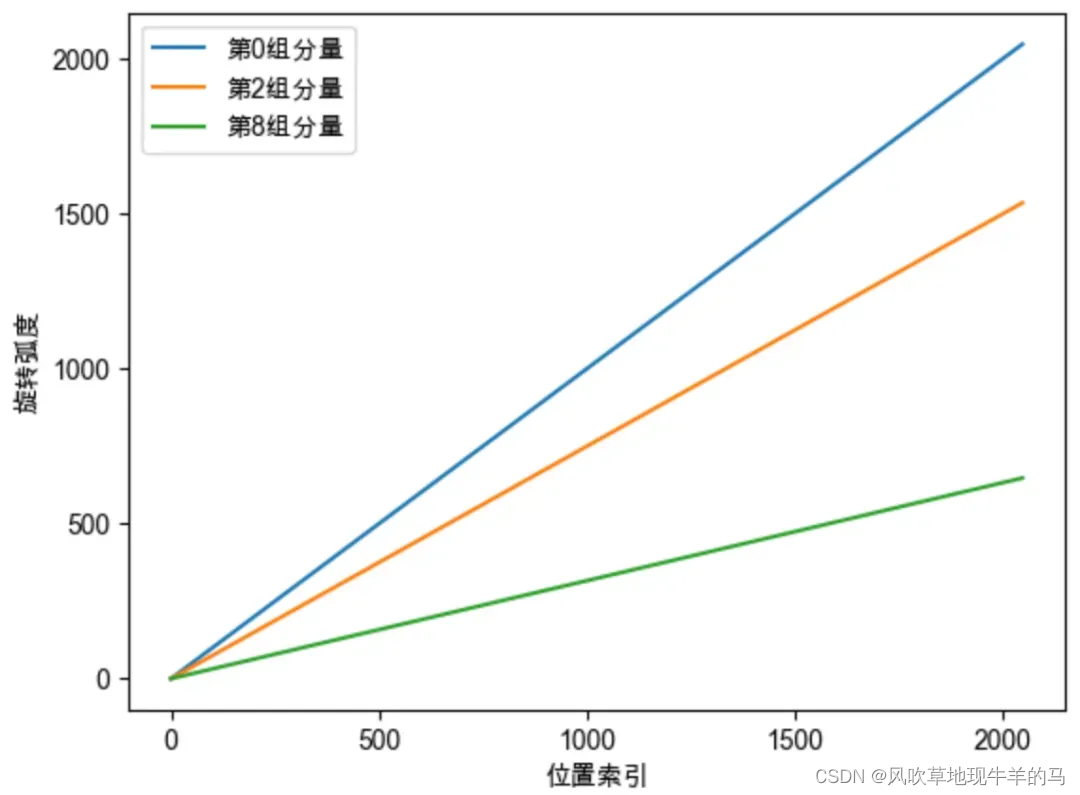
- 横坐标表示位置,纵坐标表示旋转弧度。不同的颜色,表示同一位置的不同分组的旋转弧度。
- 在rope中,位于同一位置时,越靠前的分量,旋转周期越短(高频),越靠后的分量,旋转周期越长(低频)。
位置编码外推与内插的含义
位置编码的外推与内插总结一句话:高频外推、低频内插。
那么分析了上述
f
f
f函数的特性有什么作用呢?假设训练长度为
L
t
r
a
i
n
L_{train}
Ltrain,那么
m
−
n
∈
[
0
,
L
t
r
a
i
n
−
1
]
m-n \in [0, L_{train}-1]
m−n∈[0,Ltrain−1],对于靠前的分量(
比如第
0
组分量
比如第0组分量
比如第0组分量),旋转周期快、频率高,在
m
−
n
m-n
m−n从
0
0
0到
L
t
r
a
i
n
−
1
L_train-1
Ltrain−1期间,已经转了很多圈,也就是说圈上的每一个点几乎都被训练过,因此这些
θ
i
\theta_{i}
θi几乎不存在OOD问题,可以直接进行外推;相反,对于靠后的分量(
比如第
20
组分量
比如第20组分量
比如第20组分量),旋转周期慢、频率低,在
m
−
n
m-n
m−n从
0
0
0到
L
t
r
a
i
n
−
1
L_train-1
Ltrain−1期间,可能只旋转了很小的角度,被训练过的点顶多是圆上的一段弧线,如果测试的更长的
L
t
e
s
t
L_{test}
Ltest,没有落在被训练过的弧度的范围内,就会出现无法预估的表现,因此需要通过内插的方法缩放到原本训练过的弧度范围内。下面的图解释了上面文本的含义。
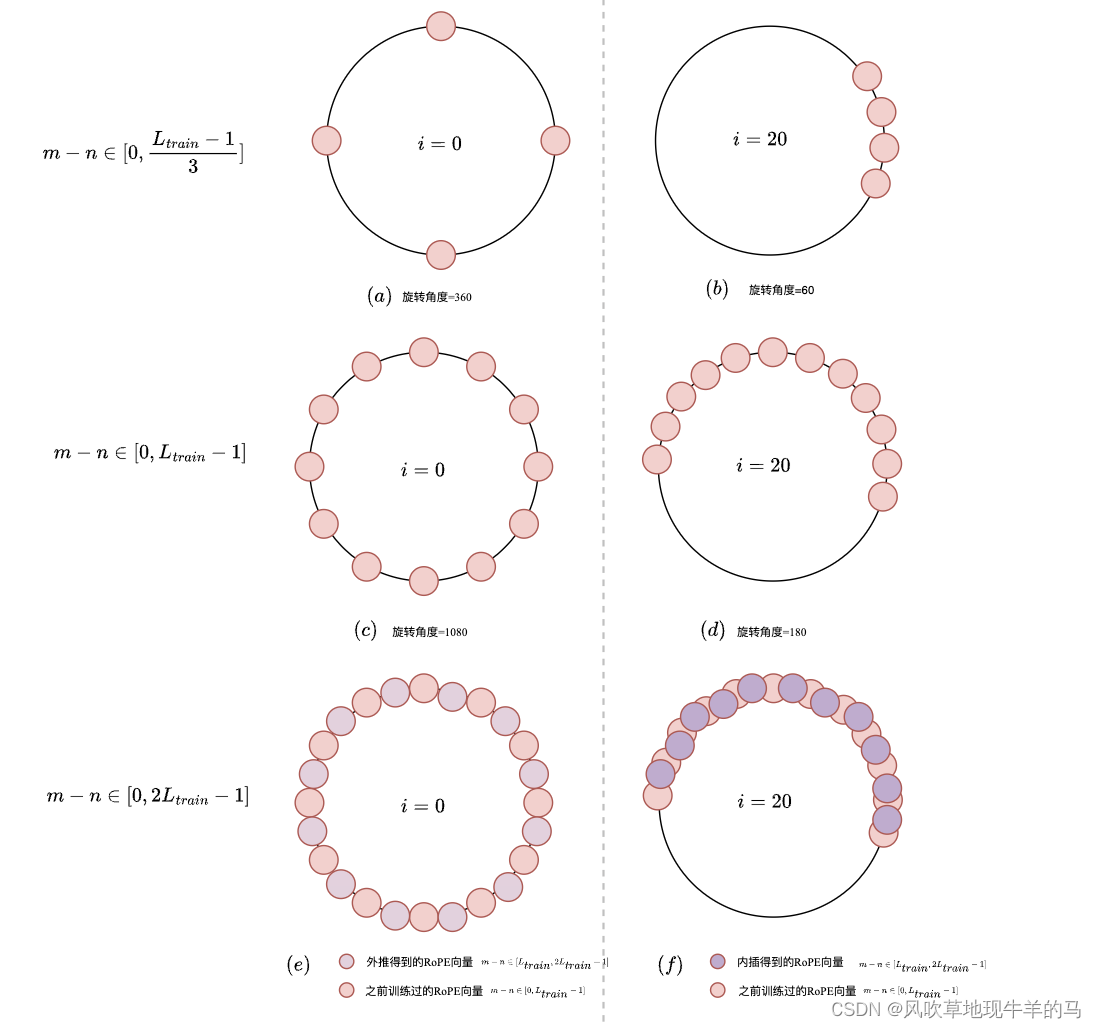
参考文献:
https://spaces.ac.cn/archives/9948
https://blog.csdn.net/v_JULY_v/article/details/134085503
https://blog.csdn.net/v_JULY_v/article/details/135072211