A Method on Searching Better Activation Functions
公众号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)

目录
0. 摘要
3. 动机
4. 方法论
4.1 问题设定
4.1.1 贝叶斯错误率和信息熵
4.1.2 激活函数和信息熵
4.2 具有边界条件的最差激活函数 (WAFBC)
4.3 基于熵的激活函数优化 (EAFO)
4.4 修正正则化 ReLU (CRReLU):从 ReLU 到更优
5. 实验
6. 局限性和未来工作
0. 摘要
人工神经网络(artificial neural networks,ANN)的成功在很大程度上依赖于激活函数的明智选择,这引入了网络的非线性能力,使其能够建模数据中的复杂关系。然而,过去对激活函数的搜索主要依赖于经验知识,缺乏理论指导,这阻碍了更有效激活函数的识别。在这项工作中,我们为这一问题提供了一个恰当的解决方案。首先,我们从信息熵的角度理论证明了具有边界条件的最差激活函数(the worst activation function with boundary conditions,WAFBC)的存在。此外,受信息熵泛函泰勒展开形式(Taylor expansion form of information entropy functional)的启发,我们提出了基于熵的激活函数优化(Entropy-based Activation Function Optimization,EAFO)方法。EAFO 方法为设计深度神经网络中的静态激活函数提供了一种新颖的视角,并具有在迭代训练过程中动态优化激活的潜力。利用 EAFO 方法,我们从 ReLU 导出了一种新的激活函数,称为修正正则化 ReLU(Correction Regularized ReLU,CRReLU)。在CIFAR-10、CIFAR-100 和 ImageNet-1K 数据集上,使用 ViT 及其变体进行的实验表明,CRReLU 优于现有的ReLU 修正。在大语言模型(LLM)微调任务上的广泛实证研究中,CRReLU 表现出比 GELU 更优越的性能,表明其在实际应用中的更广泛潜力。
3. 动机
研究人员已经投入了大量努力探索改进的激活函数,这些激活函数被广泛认为对深度学习的发展具有重要意义。然而,我们也注意到,这些激活函数的提出缺乏理论框架,这表明这样的搜索在某种程度上是低效且盲目的。
GELU(Gaussian Error Linear Unit)[24] 首次提出于 2016 年,自那时起在多个领域取得了显著成功,尤其是在近年来大语言模型的出现中。它已成功应用于多种前沿神经网络架构中,如 BERT [25]、ViT [4]、GPT-4 [10] 等,展示了其多功能性和有效性。在 Lee [26](2023)的工作中,GELU 的数学性质得到了深入揭示,包括其可微性、有界性、平稳性和光滑性。因此,新的激活函数所表现出的优越性能通常缺乏数学解释。理解往往仅限于其表现出更好的性能,这妨碍了对更好激活函数的探索和神经网络的可解释性。
鉴于上述挑战,我们的工作旨在提出一种方法来搜索更好的激活函数,不仅能发现改进的激活函数,还能阐明其优越性能背后的原因。
4. 方法论
4.1 问题设定
4.1.1 贝叶斯错误率和信息熵
一个深度神经网络可以简化为包含一个特征提取层,随后是一个全连接层进行最终分类。从概率的角度来看,在二元分类中,特征提取层可以被概念化为转换混合分布(mixture distribution)的形状,从而使最终的全连接层能够用超平面分离两个分布。因此,两个分布的重叠越多,贝叶斯错误率越高,分类性能越差。此外,信息熵越低,形成两个独立峰的可能性越大(即分类不确定性越小,越容易分类);两个分布的重叠增加也会导致信息熵的增加(即分类不确定性越大,越难分类)。上述论述可以扩展到多类分类,这里不再详细说明。
4.1.2 激活函数和信息熵
假设激活函数的反函数为 y(x),且激活函数是单调递增的。许多以前的激活函数,如 Sigmoid 和Tanh [17],满足函数在整个定义域内具有反函数的假设。此外,当激活函数不满足该假设时,我们可以变换满足该假设的部分,如 ReLU 的正值部分。
然后我们设定在通过激活函数之前的数据分布服从分布 p(x)。因此,通过激活函数后的数据分布为 q(x) = p(y(x))y'(x)(注,此处已换元,变量 x 与 p(x) 中的 x 不是同一个。下文中依然如此,请自行根据语境理解 x 所表示的含义),其中 y'(x) 代表 y(x) 的导数。因此,我们可以将信息熵表示为:
![]()
因此,信息熵可以视为一个泛函(functional),它以函数 y(x) 为输入,产生一个实数作为输出。
4.2 具有边界条件的最差激活函数 (WAFBC)
首先,我们希望确定泛函 H(y(x)) 的极值(无论是最大值还是最小值)。为了进一步推导,考虑最简单的泛函,例如设定
![]()
为了研究函数 y(x) 变化带来的影响,我们对函数 y(x) 施加一个小扰动 ϵη(x),然后泛函 H(y(x)+ϵη(x)) 的形式如下:
![]()
我们对泛函 H(y(x)+ϵη(x)) 进行泰勒展开,可以得到以下方程:
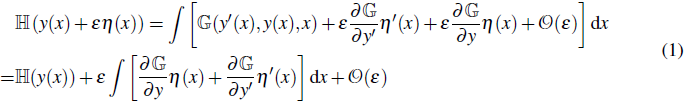
如 4.1.2 节所示,经过激活函数后的数据分布为 q(x)=p(y(x))y′(x)。我们可以容易地得出,对于激活函数的反函数 y(x),当 x 接近下界时(例如初始激活函数值接近下界),y(x) 应该接近负无穷;而当 x 接近上界时(例如初始激活函数值接近上界),y(x) 应该接近正无穷。由于 ϵη(x) 是施加到 y(x) 上的小扰动,我们可以得出结论 η(x) 在边界处必须为 0。
利用分部积分法和方程 1 的边界条件,我们可以得到以下结果:
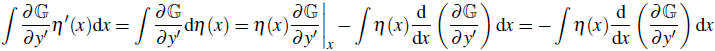
因此,H(y(x)+ϵη(x)) 的表达式为:
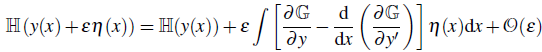
类似于普通函数的极值,期望在极值点的一阶项应为 0。这种对任意 η(x) 的要求导致了欧拉-拉格朗日方程:

命题1:如果 G 与 x 无关,即 G=G(y,y′),基于方程 2 中表示的欧拉-拉格朗日方程,我们有:
![]()
命题 1 的详细证明见附录 A。
将 G = p(y(x))y′(x)·log(p(y(x))y′(x)) 代入方程 3 并进行计算,最终结果是:
![]()
同时对方程的两边进行积分,最终解为:
![]()
根据方程 (3) 得到的解,由于 y(x) 是激活函数的反函数,第一个积分方程最终可以通过获得激活函数的形式来解出:
![]()
其中,C_1 和 C_2 是基于激活函数的上界和下界的两个常数。方程 (5) 显示了具有边界条件的最差激活函数的解析形式。我们在附录 B 中对此形式进行了进一步讨论。通过上述推导,确定了泛函的极值。此外,我们想推导出它是最大值还是最小值。将 Legendre 条件应用于泛函极值,那么我们有:
![]()
因此,所得到的极值是一个最大极值,实际上是一个全局最大极值,这意味着推导出的激活函数具有最差的性能。实际上,WAFBC 具有一些有趣的性质,例如,它本质上具有上下界,这可以解释为什么像 Sigmoid 和 Tanh 这样的有界激活函数不如像 ReLU 这样的无界函数表现得好。
4.3 基于熵的激活函数优化 (EAFO)
在第 4.2 节中,我们推导了泛函的极值,展示了方程 (5) 中的解析形式。然而,所获得的解是全局最大值,而不是最小值。如果我们想获得最佳激活函数,则需要泛函的最小值。然而,根据计算,实际情况是该泛函只有一个全局最大值,但不存在全局最小值。因此,没有最佳激活函数,只有更好的激活函数。在这种情况下,WAFBC 代表了泛函的全局最大值,这意味着激活函数的性能从 WAFBC 到任何替代激活函数都会持续改善。因此,我们提出了以下问题:是否有一种方法可以从现有的高性能激活函数开始,随后开发出具有更高性能的激活函数?
让我们重新考虑泛函的泰勒展开:
![]()
为了最小化新激活函数的信息熵,建议减少泰勒展开的一阶项。为了确保新激活函数的信息熵确实减少,我们希望将 η(x) 设置为与
![]()
的相反符号,这意味着我们设置:
![]()
将泛函 G(y′(x),y(x)) 的解析形式代入方程 (6),进行计算,我们可以得到以下方程:
![]()
其中,p(x) 是数据分布在通过激活函数前的概率密度函数 (PDF);p′(x) 是 PDF 的一阶导数;y(x) 是激活函数的逆函数;y′(x) 是 y(x) 的一阶导数;y′′(x) 是 y(x) 的二阶导数。因此,我们推导出一个能够减少信息熵的修正项,其通用形式如方程 7 所示。随后,我们可以得到优化激活函数的逆函数,表示为 g(x) = y(x) + η(x)。最后,通过推导 g(x) 的逆函数可以获得优化的激活函数。
EAFO 方法概要。总结而言,我们将理论上的 EAFO 方法论表述如下:
- 利用方程 7 并根据数据分布 p(y) 和激活函数的逆函数 y(x) 推导修正项 η(x)。
- 将修正项与逆函数相加得到优化函数的逆函数,即 g(x) = y(x) + η(x)。
- 推导 g(x) 的严格或近似逆函数,得到优化的激活函数。
此外,EAFO 方法还显示了在迭代训练过程中动态优化激活函数的潜力。我们认识到具有多层感知器 (MLP) 架构的神经网络的激活函数通常是固定的。最近的研究,如刘等人 [27] 的工作,建议在创新的网络架构 (Kolmogorov-Arnold Networks) 中优化激活函数。此外,针对真实数据分布 p(y),利用 EAFO 方法论,我们可以在多层感知器 (MLP) 架构下,通过数值方法实际连续优化激活 y(x)。理论上,通过数值方法优化信息熵泛函,也可以使用梯度下降优化激活函数;然而,我们也意识到,这会导致大型神经网络中的计算复杂性爆炸,因此需要实际高效的算法。因此,EAFO 方法论目前仍处于理论阶段,为计算更好的激活函数的解析形式提供指导。
4.4 修正正则化 ReLU (CRReLU):从 ReLU 到更优
如第 4.2 节所述,从理论上讲,最差的激活函数确实存在,我们可以确定其确切形式。实际上,从最差激活函数开始,函数 G 的值持续下降,表明激活函数的性能得到改善。这揭示了搜索改进激活函数的可行性,这构成了 “优化” 的关键。在第 4.3 节中,提出了 EAFO 作为优化方法。因此,我们可以轻松地想到从 WAFBC 优化以获得性能更好的激活函数。虽然这种想法是可行的,但我们也观察到 WAFBC 本身采用了变上限积分的形式,这产生了复杂的 η(x) 形式,使得推导结果在实际意义上并不显著。此外,从 WAFBC 开始的优化也导致了缓慢的进展。因此,在实际应用中,我们倾向于从已经表现出相对较好性能的激活函数开始。
在这里,我们希望从 ReLU [1–3] 开始,展示找到更好激活函数的过程。在推导之前,我们也注意到 ReLU 在整个定义域上缺乏逆函数。在本节中,我们希望利用以下策略来缓解上述困境:初始激活函数只需在特定区域内有逆函数;而在没有逆函数的部分,我们可以采用实际的近似方法。因此,我们首先检查 ReLU 中 x 为正的区域。如方程 7 所示,修正项 η(x) 的推导仅需要原始分布 p(y) 和激活函数的逆函数 y(x)。激活函数的知识很容易获得,而原始分布仍未被探索。然而,在实际实验中,实验数据的原始分布肯定会表现出相当大的形态变异,因此缺乏完美的解析形式。因此,我们假设网络足够大,根据中心极限定理,网络处理的数据可以近似为高斯分布 [28–31][32]。当然,这种假设在实际实验的网络中并不总是成立;然而,对逆函数的近似解和可学习参数 ε 的存在显著减轻了这种假设的影响,这也可以通过第 5 节中显示的 CRReLU 对数据分布的不敏感性得到证明。
现在,让我们考虑从 ReLU 到 CRReLU 的推导。为了简洁起见,我们重新书写数据分布和数据分布的导数:
![]()
此外,ReLU 的数学函数定义为 y = x 当 x 为正时,这意味着我们有 y(x) = x, y′(x) = 1 和 y′′(x) = 0。因此,
![]()
最终,通过将
![]()
代入方程 7,我们可以得到:
![]()
此外,我们将常数 C 设为一个可学习参数 ε,以实现网络中的自我优化。根据 EAFO 方法,我们可以得到修正激活函数的逆函数如下:
![]()
最终,通过推导 g(x) 的逆函数,可以获得优化后的激活函数 CRReLU。然而,使用常规方法获得方程 (8) 的逆函数存在挑战;因此,我们使用以下函数作为实际近似形式:
![]()
在命题 2 中,我们展示了使用方程 (9) 作为方程 (8) 的近似逆函数的合理性和可靠性。
命题 2:已知
![]()
g(f(x)) 和 x 之间的误差绝对值有以下界限:
![]()
命题 2 的详细证明见附录 C。
如第 4.2 节所述,εη(x) 是一个小扰动;因此,从理论上讲,我们可以将 εη(x) 设为一个无穷小。此外,在这种情况下,考虑到 η(x) 是一个有界函数,我们可以很容易地推断出 ε 也是一个无穷小。因此,g(f(x)) 和 x 之间的误差绝对值是一个高阶无穷小。在实践中,我们通常将 ε 初始化为一个小值,例如 0.01(如第 5 节所述),这意味着误差绝对值是一个小值。
最后,让我们考虑 x 为负的部分。当 x 为负时,ReLU 的逆函数可以看作是一条从原点发出并延伸到无穷远的射线,具有无限斜率;当 x 为正时,它是一条斜率为 1 的射线。因此,正负 x 值的修正项解可以认为是相同的,仅在常数 C 上有所不同。在方程 (9) 和命题 2 中,表明将修正项引入线性激活函数可以通过减少信息熵产生有益效果。因此,我们可以得到修正正则化 ReLU 的完整形式:
![]()
对引入的可学习参数 ε 的讨论。在第 4.2 节中,我们成功证明了最差激活函数的存在,从最差激活函数开始,无论采取哪个方向,它总是朝着改进方向前进。然而,从特定激活函数(如 ReLU)开始,并不总是会在所有方向上改进,即某些优化路径可能导致结果恶化。因此,从实际角度出发,我们引入可学习参数 ε,以实现网络的自我优化。从另一个角度看,在从 ReLU 到 CRReLU 的推导过程中,我们假设数据遵循高斯分布,但在实际实验中可能不成立。可学习参数 ε 的存在在某种程度上也削弱了这一假设。
最后,我们在附录 D 中提供了 CRReLU 的更多细节,包括附录 D.1 中类似 Python 的 CRReLU 伪代码,以及附录 D.2 中对 CRReLU 特性的进一步讨论。

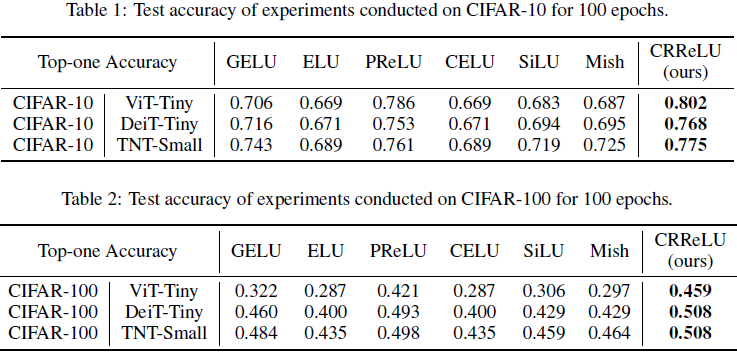
5. 实验


6. 局限性和未来工作
我们的发现提出了一些未来工作中的重要问题。
首先,如何将 EAFO 框架系统地推广到不可逆激活函数?在 EAFO 方法论的初始设置中,激活函数的选择局限于具有可逆对应物的函数。尽管 ReLU 是一个没有逆函数的突出例子,我们利用 EAFO 推导出了 CRReLU;然而,这个推导也在一定程度上受益于 ReLU 的形式简单和几种启发式方法。
其次,在神经网络训练过程中如何有效地实现激活函数迭代优化?尽管已经证明了在神经网络训练过程中进行迭代激活函数优化的可行性,但目前受到计算复杂性的限制,特别是在大规模神经网络中。EAFO 方法论在优化其他网络结构(如 Kolmogorov-Arnold Networks,KANs)中的激活函数的适用性也值得进一步深入研究。
因此,开发实用和高效的算法是未来工作的一个激动人心的方向。最后,虽然我们已经从实证角度验证了 CRReLU 在图像分类任务和大型语言模型微调任务中的出色性能,但其在其他任务中的性能仍有待探索,因此需要进一步的调查。







![二维前缀和[模版]](https://img-blog.csdnimg.cn/direct/9ea5fd5df1204ece952d5d5523a6a4fd.png)