浅谈配置元件之CSV 数据文件设置
为了增强测试的真实性和多样性,JMeter 提供了多种数据参数化的方式,其中 CSV 数据文件设置(CSV Data Set Config)是一种常用且强大的功能,它允许测试脚本从外部CSV文件中动态读取数据,从而模拟不同用户的输入或场景。
CSV 数据文件设置概述
CSV(Comma-Separated Values,逗号分隔值)文件是一种常见的、轻量级的文件格式,用于存储表格数据。每行代表一条记录,而记录中的每个字段由逗号分隔。在JMeter中,通过CSV Data Set Config元件,可以方便地从这样的文件中读取数据,并将这些数据作为变量参数化地注入到HTTP请求、SQL查询等测试步骤中。
CSV 数据文件设置配置步骤
- 添加CSV 数据文件设置元件
- 打开JMeter测试计划,在测试计划树的“线程组”(或任何你需要参数化的取样器的父级)下,右键选择“添加” > “配置元件” > “CSV 数据文件设置”。
2 配置CSV 数据文件设置属性
● 文件名:指定CSV文件的完整路径。如果是相对路径,它是相对于JMeter的bin目录。确保在跨平台使用时路径正确无误。
● 文件编码:选择CSV文件的字符编码。对于包含非ASCII字符(如中文),推荐使用UTF-8编码。
● 变量名称:列出CSV文件中每一列对应的变量名,多个变量名之间以逗号分隔。这些变量名将在测试脚本中作为参数引用。
● 忽略首行:选择以后可以明确首行是否忽略,如果是True则忽略,如果不是则不忽略
● 分隔符:默认为逗号(,), 但可以根据实际文件中的分隔符进行修改,如制表符(\t)。
● 是否允许带引号:如果CSV值被双引号包围,选中此选项会保留引号;否则,引号将被去除。
● 遇到文件结束符再次循环:当所有数据读完后,是否重新开始读取CSV文件。
● 遇到文件结束符停止线程:当所有数据读完后,是否停止线程。
● 线程共享模式:可以分为所有线程、当前线程组、当前线程
不同线程共享模式在测试脚本中引用CSV数据的结果
实践示例
在HTTP请求、断言或其他需要参数的地方,可以通过${变量名}的形式引用CSV中的数据。例如,如果变量名为user,则在请求体或URL中使用${user}来动态替换值。
假设你有一个CSV文件users.csv,内容如下:
username,password
user1,pwd1
user2,pwd2
user3,pwd3
user4,pwd4
配置CSV Data Set Config如下:
● 文件名:/path/to/users.csv
● 变量名称:user,pwd
● 忽略首行:True
然后,在HTTP请求的登录接口中,将用户名和密码参数分别设置为${username}和${password},JMeter将在每次迭代中依次使用CSV文件中的不同用户信息发起请求。
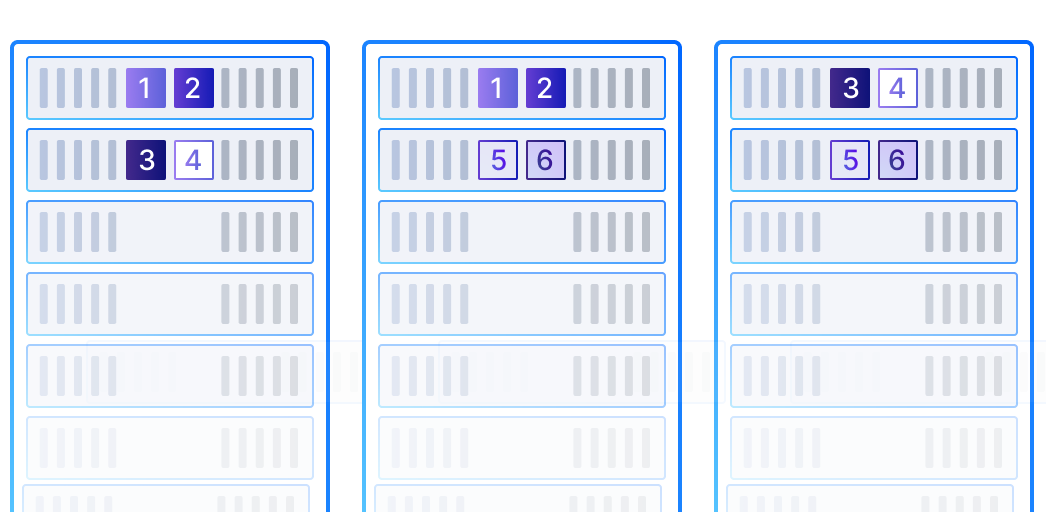
在JMeter的CSV Data Set Config元件中,“线程更新模式”(Sharing Mode)是一个关键配置,它决定了CSV文件中的数据是如何在不同的线程(用户)之间共享的。这一设置对于控制数据分配和确保测试的准确性和现实性至关重要。以下是三种线程更新模式的区别:
1.所有线程(All threads)
● 描述:在这种模式下,CSV文件的数据被所有线程共享。这意味着所有线程将顺序读取CSV文件中的数据行,不论它们属于哪个线程组。一旦数据被一个线程读取,其他线程将不会再次读取同样的数据(除非设置了循环或再次循环文件)。
● 适用场景:当你的测试设计要求所有虚拟用户共享同一数据序列,或者数据量足够大以至于每个线程都能得到独特数据时,可以选择这种模式。
● 注意点:可能会导致线程之间的数据竞争,特别是在高并发测试中,需谨慎使用。
● 实例:
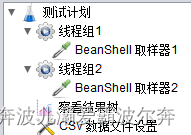
①线程组1中保持默认的设置,即线程数,Ramp-Up以及循环次数都是1,并且BeanShell 取样器1中设置的内容如下
log.info("线程组1:User:${user},Passwd:${pwd}");
②线程组2中保持默认的设置,即线程数,Ramp-Up以及循环次数都是1,并且BeanShell 取样器2中设置的内容如下
log.info("线程组2:User:${user},Passwd:${pwd}");
③CSV 数据文件设置中设置的线程共享模式为“所有线程”,进行脚本运行,我们可以看到脚本内容打印的信息内容如下
2024-05-27 14:48:58,768 INFO o.a.j.u.BeanShellTestElement: 线程组1:User:user1,Passwd:pwd1
2024-05-27 14:48:58,768 INFO o.a.j.u.BeanShellTestElement: 线程组2:User:user2,Passwd:pwd2
2.当前线程组(Current thread group)
● 描述:仅线程组内的线程共享CSV数据。如果测试计划中包含多个线程组,并且每个线程组需要独立处理CSV数据,那么应该选择此模式。每个线程组内的线程将按照自己的顺序读取数据行,不同线程组间不会共享数据行。
● 适用场景:适用于多用户组测试场景,每个组有独立的数据集,比如模拟不同用户群体的行为。
● 优势:增加了测试的隔离性和精确度,避免了不同测试逻辑间的干扰。
● 实例:
①线程组1中保持默认的设置,即线程数,Ramp-Up以及循环次数都是1,取样器中内容不变
②线程组2中保持默认的设置,即线程数,Ramp-Up以及循环次数都是1,取样器中内容不变
③CSV 数据文件设置中设置的线程共享模式为“当前线程组”,进行脚本运行,我们可以看到脚本内容打印的信息内容如下
2024-05-27 14:55:59,870 INFO o.a.j.u.BeanShellTestElement: 线程组1:User:user1,Passwd:pwd1
2024-05-27 14:55:59,886 INFO o.a.j.u.BeanShellTestElement: 线程组2:User:user1,Passwd:pwd1
3.当前线程(Current thread)
● 描述:最严格的隔离级别,每个线程都有自己独立的CSV数据读取指针。即使在同一个线程组内,每个线程也会从CSV文件的开头独立开始读取数据,互不影响。
● 适用场景:当每个虚拟用户需要从头到尾独立遍历整个数据集,或者数据量不足以支持每个线程拥有独立数据行时,此模式非常有用。
● 优势:提供了最大程度的数据隔离,适合需要高度并行和独立性的测试场景。
● 实例:
①线程组1中设置线程数为2,Ramp-Up为1,循环次数都是2,并且BeanShell 取样器1中设置的内容如下
log.info("线程组1:User:${user},Passwd:${pwd},当前的线程组序号:${__jm__线程组1__idx}");
②线程组2中设置线程数为2,Ramp-Up为1,循环次数都是2,并且BeanShell 取样器2中设置的内容如下
log.info("线程组2:User:${user},Passwd:${pwd},当前的线程组序号:${__jm__线程组2__idx}");
③CSV 数据文件设置中设置的线程共享模式为“当前线程”,进行脚本运行,我们可以看到脚本内容打印的信息内容如下
2024-05-27 15:03:58,989 INFO o.a.j.u.BeanShellTestElement: 线程组1:User:user1,Passwd:pwd1,当前的线程组序号:0
2024-05-27 15:03:58,990 INFO o.a.j.u.BeanShellTestElement: 线程组1:User:user2,Passwd:pwd2,当前的线程组序号:1
2024-05-27 15:03:59,008 INFO o.a.j.u.BeanShellTestElement: 线程组2:User:user1,Passwd:pwd1,当前的线程组序号:0
2024-05-27 15:03:59,009 INFO o.a.j.u.BeanShellTestElement: 线程组2:User:user2,Passwd:pwd2,当前的线程组序号:1
2024-05-27 15:03:59,488 INFO o.a.j.u.BeanShellTestElement: 线程组1:User:user1,Passwd:pwd1,当前的线程组序号:0
2024-05-27 15:03:59,490 INFO o.a.j.u.BeanShellTestElement: 线程组1:User:user2,Passwd:pwd2,当前的线程组序号:1
2024-05-27 15:03:59,510 INFO o.a.j.u.BeanShellTestElement: 线程组2:User:user1,Passwd:pwd1,当前的线程组序号:0
2024-05-27 15:03:59,511 INFO o.a.j.u.BeanShellTestElement: 线程组2:User:user2,Passwd:pwd2,当前的线程组序号:1
选择合适的线程更新模式对于确保测试的有效性和准确性至关重要。理解不同模式的工作原理可以帮助你更好地设计测试计划,模拟真实的用户交互场景,同时避免数据冲突和资源竞争问题。在设计复杂测试场景时,应根据测试目标和数据量仔细考虑这三种模式的适用性。
注意事项
● 确保CSV文件的路径在所有执行测试的机器上都是可访问的,尤其是在分布式测试环境中。
● 当测试计划中有多个线程同时读取CSV文件时,考虑数据并发读取的同步问题,避免数据错乱。
● 对于大型数据集,考虑CSV文件的读取效率和内存占用,适当调整JMeter的内存配置。
通过以上步骤,你可以有效地利用CSV数据文件设置增强JMeter测试脚本的灵活性和实用性,模拟多样化的用户行为和数据输入,提高测试覆盖率和准确性。