第5讲 requests添加Cookies与正则表达式
整体课程知识点查看 :https://blog.csdn.net/j1451284189/article/details/128713764
本讲总结
request代理使用
request SSL
request添加Cookies
数据解析方法简介
数据解析:正则表达式讲解
一、requests 代理
def day5_requests_proxy():
url = 'https://www.baidu.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:106.0) Gecko/20100101 Firefox/106.0',
}
#添加免费代理
free_proxy = {
'http': '120.77.249.46:8080'
}
response = requests.get(url,headers=headers,proxies=free_proxy)
print(response.status_code)
二、requests SSL
def day5_requests_ssl():
url = 'http://www.icbc.com.cn/icbc/'
# https需第三方证书认证 SSL
# 12306是自己的证书
# 解决方法:告诉web忽略证书,直接访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:106.0) Gecko/20100101 Firefox/106.0',
}
# verify 忽略证书
response = requests.get(url,headers=headers,verify=False)
print(response.status_code)
with open('baidu.html', 'w', encoding='utf-8') as f:
f.write(response.content.decode())
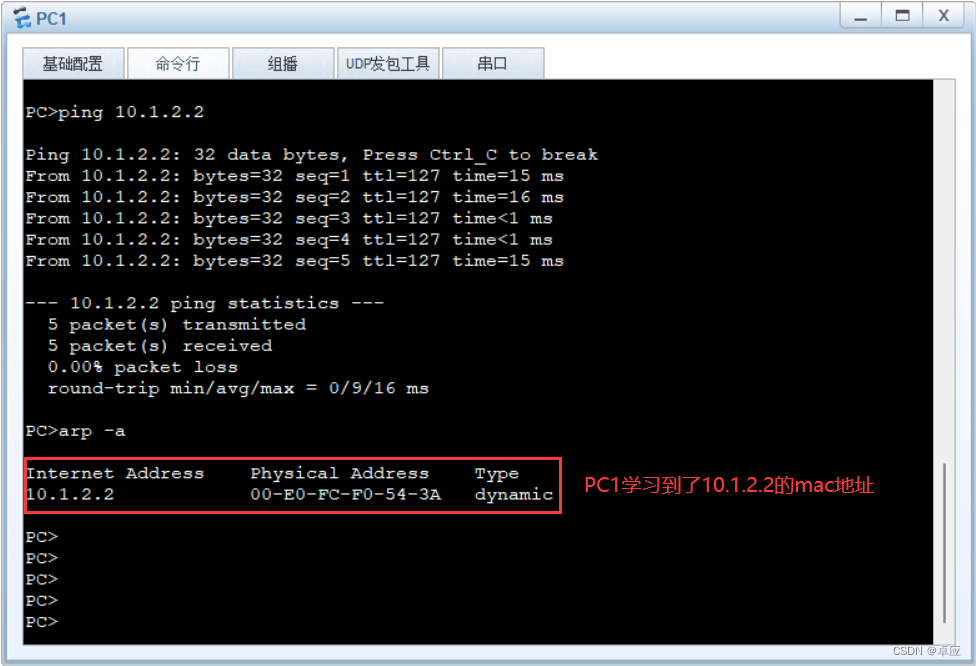
三、requests Cookies
cookie字符串转字典
cookie 复制后是字符串,但
cookies = 'BAIDUID=9E7C2D060E38585B188986F0EF0CA99E:SL=0:NR=10:FG=1;BIDUPSID=314F6F32BDBB7DC43ED777384251421C;'方法1:正则匹配 自己替换
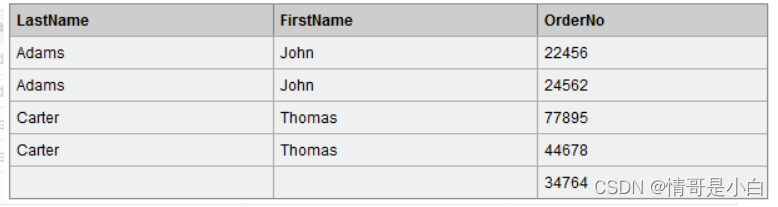
替换 ;为\n
替换如图:

方法二:函数处理
cookie_dict = {} cookie_list = cookies.split('; ') for cookie in cookie_list: cookie_dict[cookie.split('=')[0]] = cookie.split('=')[1]方法三:字典推导式
cookie_dict = {cookie.split('=')[0] : cookie.split('=')[1],for cookie in cookies.split('; ')}
携带Cookie访问权限信息
def day5_requests_cookies():
url = ' https://www.baidu.com/my/index'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:106.0) Gecko/20100101 Firefox/106.0',
}
#方法一:传参给cookies 需要的传参类型是字典
# cookies = 'BAIDUID=9E7C2D060E38585B188986F0EF0CA99E:SL=0:NR=10:FG=1; BIDUPSID=314F6F32BDBB7DC43ED777384251421C; PSTM=1631362136'
# cookie_dict = {cookie.split('=')[0] : cookie.split('=')[1] for cookie in cookies.split('; ')}
# print(cookie_dict)
# response = requests.get(url, headers=headers, cookies=cookie_dict)
# with open('baidu.html', 'w', encoding='utf-8') as f:
# f.write(response.content.decode())
# 方法二 传参给headers
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:106.0) Gecko/20100101 Firefox/106.0',
'Cookie':'BAIDUID=9E7C2D060E38585B188986F0EF0CA99E:SL=0:NR=10:FG=1; BIDUPSID=314F6F32BDBB7DC43ED777384251421C; PSTM=1631362136;'
}
response = requests.get(url, headers=headers)
with open('baidu.html', 'w', encoding='utf-8') as f:
f.write(response.content.decode())
自动登录获取Cookie
def day5_auto_login():
#session 类似于cookiejar 自动保存cookie
session = requests.session()
url = 'https://www.zcbbe.com/member.php?mod=logging&action=login&loginsubmit=yes&infloat=yes&lssubmit=yes&inajax=1'
login_header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:106.0) Gecko/20100101 Firefox/106.0',
# 'Host':'bpoyg.zdzhiheng.com.cn:8000',
# 'Origin':'http://bpoyg.zdzhiheng.com.cn:8000',
# 'Referer':'http://bpoyg.zdzhiheng.com.cn:8000/login',
}
login_form_data = {
"username": "jml",
"password": "j*******",
"quickforward": 'yes',
"handlekey": 'ls',
}
# 登录操作,获得cookie
response = session.post(url=url,headers=login_header,data=login_form_data)
print(response.content)
# 直接获取权限信息
center_url = 'https://www.zcbbe.com/plugin.php?id=dc_vip&moblie=no&mobile=no'
response = session.get(center_url,headers=login_header)
with open('baidu.html', 'w', encoding='utf-8') as f:
f.write(response.content.decode())
四、数据解析简介
正则
xpath
bs4
html
xml (json) 数据交互格式,字符串或字典
五、正则表达式
规则简介
| 字符 | 含义 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| | | A|B表示:匹配正则表达式条件A或B |
| ^ | 匹配字符串的开始(在集合[]里表示"非")的意思 |
| $ | 匹配字符串的结束 |
| {n} | 重复n次 |
| {,n} | 重复小于n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
| * | 重复零次或更多次,等价于{0,} |
| + | 重复一次或更多次,等价于{1,} |
| ? | 重复零次或一次,等价于{0,1} |
| {n,m}? | 重复n到m次,但尽可能少重复 |
| {n,}? | 重复n次以上,但尽可能少重复 |
| *? | 重复任意次,但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| […] | 字符类,匹配所包含的任意一个字符 注1 : 连字符-如果出现在字符串中同表示字符范围描述(A-Z);如果如果出现在首位则仅作为普通字符 注2 : 特殊字符仅有反斜线保持特殊含义 .用于转义字符. 其它特殊字符如*,+,?,等均作为普通字符匹配 注3 : 脱字符^如果出现在首位则表示匹配不包含其中的任意字符;如栗出现在字符串中间就仅作为普通字符匹配 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aou] | 匹配除了aou这几个字母以外的任意字符如 f,g,h |
| \ | 1.将一个普通字符变成特殊字符,例知:\d表示匹配所有十进制数字 2.解除元字符的特殊功能,例.崇示匹配点号本身 3.引用序号对应的子组所匹配的字符串 4.详见下方列举 举例:匹配2.4 2\.4 |
| \序号 | 1.引用序号对应的子组所匹配的字符串,子组的序号从1开始计算 2.如果序号是以0开头,或者3个数字的长度度。那么不会被用于引用对应的子组,而是用于匹配八进制数字所表示的ASCII码值对应的字符 |
| \A | 匹配输入字符串的开始位置 |
| \Z | 匹配输入字符串的结束位置 |
| \b | 匹配单词的开始或结束 |
| \B | 匹配不是单词开头或结束的位置 |
| \d | 匹配数字 |
| \D | 匹配任意非数字的字符 |
| \s | 匹配任意的空白符 |
| \S | 匹配任意不是空白符的字符如:1,* ,) |
| \w | 匹配字母或数字或下划线或汉字 |
| \W | 匹配任意不是字母,数字,下划线,汉字的字符,如 +,-,* |
示例
def day5_re_findall():
# 贪婪模式 从开头匹配到结尾
example_str = """addddnmaaam2252.5
999n9999mN
"""
# *贪婪模式 *?非贪婪
# pattern = re.compile('a(.*)m') # 贪婪 ['dddddmaaa']
# pattern = re.compile('a(.*?)m') # 非贪婪['ddddd', 'aa']
# 转义字符 \ 匹配 2.5
# pattern = re.compile('2.5') # ['225', '2.5']
# pattern = re.compile('2\.5') # ['2.5']
# 匹配除了换行符之外的所有 .
# pattern = re.compile('a(.*)n',re.I) # 忽略大小写 ['dddd']
# pattern = re.compile('a(.*)n',re.S) # 忽略换行 ['ddddnmaaam2252.5\n 999']
# pattern = re.compile('a(.*)n',re.I|re.S) # 忽略大小写 且忽略换行 ['ddddnmaaam2252.5\n 999n9999m']
#中括号的使用
example_str = '2239982'
pattern = re.compile('[123]') # ['2', '2', '3', '2']
pattern = re.compile('[7-9]') # ['9', '9', '8']
# findall 方法 结果是列表
result = pattern.findall(example_str)
print(result)
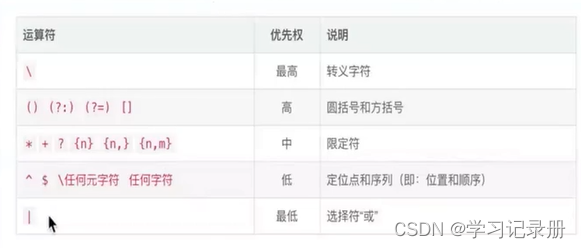
优先级
函数
# match 从头开始匹配 匹配一次
# search 从任意位置匹配 匹配一次
# findall 查找符合正则的内容
# sub 替换
# split 分割
def day5_re_fun_show():
example_str = 'abc123'
pattern = re.compile('\d+')
# match 从头开始匹配 匹配一次
result = pattern.match(example_str) # None
# search 从任意位置匹配 匹配一次
result = pattern.search(example_str) # match='123'
# findall 查找符合正则的内容
result = pattern.findall(example_str) # ['123']
# sub 替换
result = pattern.sub('@',example_str) # abc@
# split 分割
result = pattern.split(example_str) # ['abc', '']